What is LLMOps and How to Get Started With It?

LLMOps is primarily focused on enhancing operational capabilities and establishing the necessary infrastructure for refining existing foundational models and seamlessly integrating these optimized models into products.
Although LLMOps may not seem groundbreaking to most observers within the MLOps community, it serves as a specialized subset within the broader MLOps domain. A more specific definition can elucidate the intricate requirements involved in fine-tuning and deploying these models effectively.
Foundational models, such as GPT-3 with its massive 175 billion parameters, demand substantial amounts of data and compute resources for training. While fine-tuning these models may not require the same scale of data or computational power, it remains a significant task that necessitates robust infrastructure capable of parallel processing and handling large datasets.
This article delves into essential resources to help initiate your journey into LLMOps, providing valuable insights and guidance for getting started effectively.

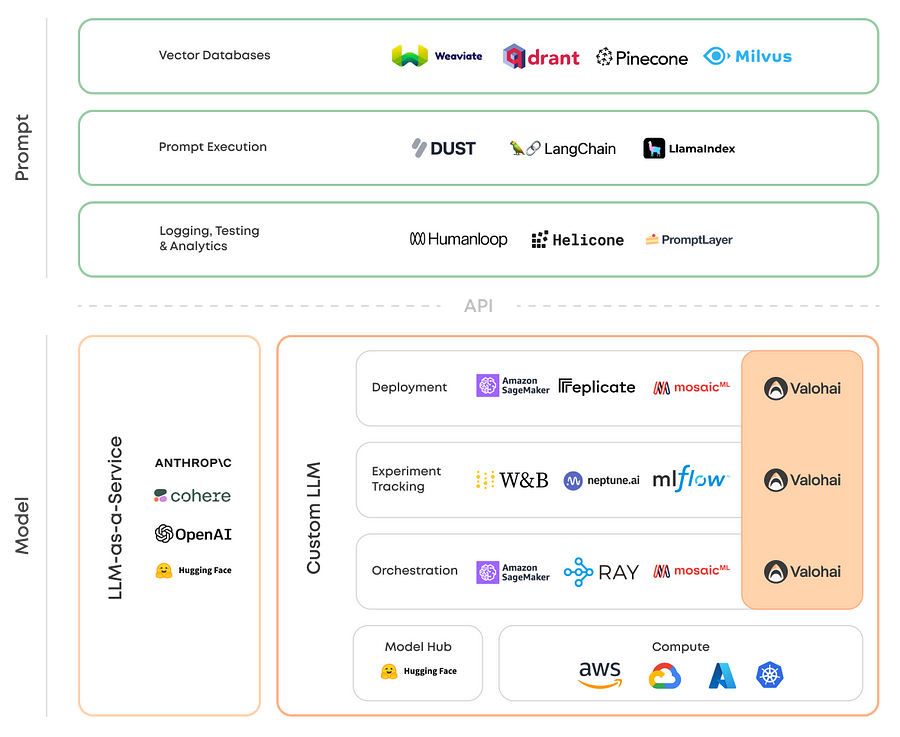
LLMOps consists of two parts:
1. Large Language Models
LLM-as-a-Service is where a vendor offers the LLM as an API on their infrastructure. This is how primarily closed-source models are delivered.
Custom LLM stack is a broader category of tools necessary for fine-tuning and deploying proprietary solutions built on top of open-source models.
2. Prompt Engineering tools: enable in-context learning instead of fine-tuning at lower costs and without using sensitive data.
Vector Databases retrieve contextually relevant information for certain prompts.
Prompt Execution enables optimizing and improving the model output based on managing prompt templates to building chain-like sequences of relevant prompts.
Prompt Logging, Testing, and Analytics … Let’s just say it’s an emerging space that has no categories yet.