
Visual Guide to LLM Preference Tuning With RLHF & PPO
Aligning LLMs: Understanding Reward Models and PPO in RLHF

Large Language Models (LLMs), despite their power, often produce outputs that are not fully aligned with human values or intent. To address this, a critical technique known as Reinforcement Learning from Human Feedback (RLHF) is used to fine-tune their behavior.
This visual guide demystifies the RLHF process, breaking down the complex pipeline into understandable stages. We will explore the journey from initial Supervised Fine-Tuning (SFT) to the core of RLHF: training a reward model to understand human preferences and then optimizing the LLM’s policy using Proximal Policy Optimization (PPO).
Through clear diagrams and step-by-step explanations, this article provides a solid foundation for understanding how we are making AI models safer, more helpful, and more aligned with us.

Get All My Books, One Button Away With 40% Off

I have created a bundle for my books and roadmaps, so you can buy everything with just one button and for 40% less than the original price. The bundle features 8 eBooks, including:
1. Introduction to RLHF
Large Language Models (LLMs), while trained on vast datasets and capable of producing fluent text, often generate responses that don’t fully align with human expectations — they can reflect biases, include factual mistakes, or overlook subtle user preferences.
Since the data the LLM is trained on might contain these problems. Although a lot of preprocessing and filtering is applied to the training dataset, it is ultimately difficult to control billions of tokens and ensure that they are free of problems.
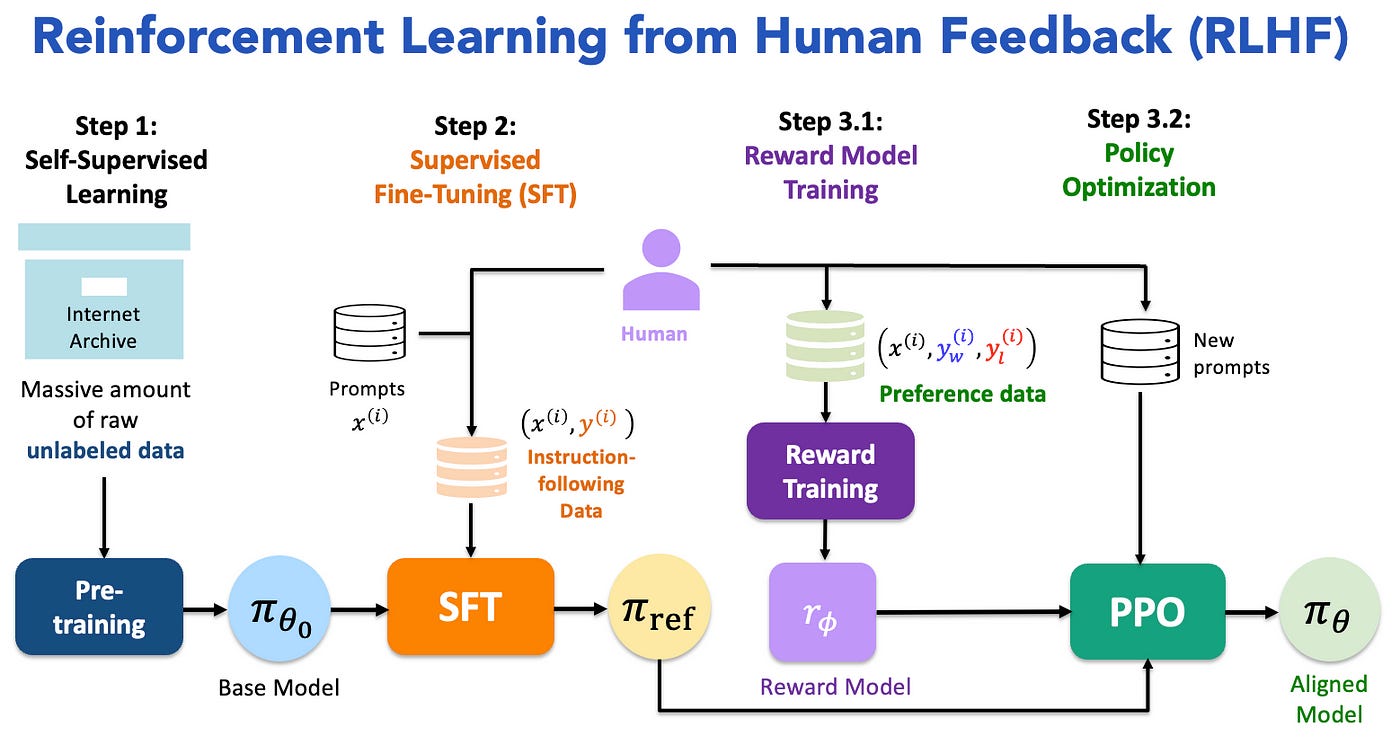
To address this, post-training methods such as Supervised Fine-Tuning (SFT) with labeled instruction-following data and Reinforcement Learning from Human Feedback (RLHF) using preference comparisons (e.g., preferred vs. less preferred responses) are employed to better align model behavior with human intent. These methods are typically applied as a post-training step. These three steps are visualized in Figure 1.

RLHF has been a leading method, combining SFT with reinforcement learning to optimize LLMs based on human feedback. The standard LLM training pipeline consists of three main phases, as shown in Figure 2:
Step 1: Self-Supervised Pre-Training: Train the large language model (LLM) on vast, unlabeled text data to understand basic language structure.
Step 2: Supervised Fine-Tuning (SFT): The pre-trained language model is fine-tuned using high-quality data specifically relevant to the target tasks, a process that can be seen as a form of instruction tuning.
Step 3: Reinforcement Learning with Human Feedback (RLHF)
Step 3.1: Reward Model Training — The SFT model generates pairs of answers for given prompts. Human labelers express preferences between these pairs. A reward model is then trained to predict these preferences.
Step 3.2: Policy Optimization — The learned reward function provides feedback to further refine the language model, typically utilizing Proximal Policy Optimization (PPO) or Direct Preference Optimization (DPO) from Reinforcement Learning.
2. Reward Model Training
The reward model is a separate model trained to act as a proxy for human judgment. Its primary purpose is to evaluate a generated piece of text (a “response”) in the context of a given “prompt” and output a single numerical score, or “reward.” This score represents how much a human would likely prefer that response.
The process of training the reward model begins with the careful construction of a preference dataset, which serves to translate subjective human judgment into a signal the machine can learn from.
This is not accomplished by asking people to rate responses on a numerical scale (e.g., 1–10), as such absolute scores are often inconsistent across different people and even for the same person over time. Instead, the process relies on a more robust and scalable method: direct comparison.
Here’s how it works:
First, for a given input prompt, the supervised fine-tuned (SFT) model generates two or more different responses

Next, human labelers are then presented with the prompt and this pair of potential answers. Their task is to evaluate both responses based on a comprehensive set of guidelines — which often include criteria like helpfulness, safety, tone, and factual accuracy — and select the one they prefer. This single choice, “Response A is better than Response B,” is a powerful and reliable data point. This entire process is repeated across thousands or even tens of thousands of diverse prompts to build a robust dataset that captures a wide range of human preferences.

The format of a preference dataset is shown below:

In RLHF, the preference dataset is used to train a reward model that scores potential answers, essentially learning to anticipate human preferences. This method enables the model to incorporate human judgments about the quality of answers across different question types and domains.
Keep reading with a 7-day free trial
Subscribe to To Data & Beyond to keep reading this post and get 7 days of free access to the full post archives.