


Top Important Python Questions for Data Science Interviews [Data Cleaning and Preprocessing]

Proficiency in Python is a cornerstone skill for data science and machine learning. Data science interviews often delve into not just the practical coding aspects but also the conceptual understanding of Python’s features and functionalities.
This blog post aims to explore and elucidate key Python questions related to data preprocessing and data clearing. Starting from how to detect missing data and handle them. After that, we will discuss data transformation and feature engineering. In addition to that, we will also cover how to detect outliers and handle them and more.
Join us in this insightful expedition where we decipher Python’s prowess in the context of data science, unveiling the methodologies that elevate your proficiency and deepen your understanding of the data preprocessing and cleansing domain.

Table of Contents:
Handling Missing Data Questions:
How do you identify and handle missing values in a Pandas DataFrame?
What is imputation, and why might it be useful in dealing with missing data?
2. Data Transformation Questions:
How can you encode categorical variables in a Pandas DataFrame?
What is one-hot encoding, and when would you use it in data preprocessing?
3. Removing Duplicates Questions:
How do you identify and remove duplicate rows from a DataFrame?
Can you explain the difference between the
duplicated()anddrop_duplicates()methods in Pandas?
4. Data Scaling and Normalization Questions:
Discuss the importance of feature scaling in machine learning.
Explain the difference between min-max scaling and z-score normalization.
5. Handling Outliers Questions:
What are outliers, and why might they impact machine learning models?
Describe different methods for detecting outliers in a dataset in Python
How can you handle outliers in a continuous numerical variable in Python?
6. Feature Engineering Questions:
Provide examples of feature engineering techniques in Python you might apply to improve model performance.
7. Data Transformation Pipelines Questions:
Discuss the benefits of using tools like scikit-learn
Pipelinefor data preprocessing.How do you handle categorical and numerical features differently in a pipeline?
8. Dealing with Skewed Data Questions:
How can you transform skewed data to make it more suitable for modeling?
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Handling Missing Data Questions
1.1. How do you identify and handle missing values in a Pandas DataFrame?
Answer:
Identifying and handling missing values is a crucial step in the data cleaning and preprocessing process. In Pandas, you can use various methods to identify and deal with missing values. Here’s a guide on how to do it:
Identifying Missing Values:
1. isnull() and notnull() Methods: The isnull() method returns a DataFrame of the same shape as the input, with True where a null value is present and False otherwise. The notnull() method is the opposite, returning True where a value is not null and False otherwise.
df.isnull() # Returns a DataFrame of True/False values indicating the presence of missing values.
df.notnull() # Returns a DataFrame of True/False values indicating non-missing values.2. info() Method: The info() method provides a concise summary of the DataFrame, including the count of non-null values for each column. You can quickly identify columns with missing values.
df.info()3. describe() Method: The describe() method provides summary statistics for each column, including the count of non-null values. It can help identify missing values by comparing the count to the total number of rows.
df.describe()Handling Missing Values:
Dropping Missing Values: Use the
dropna()method to remove rows or columns with missing values.
df.dropna() # Removes rows with any missing values.
df.dropna(axis=1) # Removes columns with any missing values.2. Filling Missing Values: Use the fillna() method to fill missing values with a specific value or a calculated one (e.g., mean, median).
df.fillna(value) # Fills missing values with a specific value.
df.fillna(df.mean()) # Fills missing values with the mean of each column.3. Interpolation: Use the interpolate() method to perform linear interpolation to fill missing values.
df.interpolate() # Performs linear interpolation to fill missing values.4. Imputation: Imputation involves replacing missing values with estimated values based on the remaining data. Libraries like scikit-learn provide imputation techniques.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Other strategies: median, most_frequent
df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Remember to choose the appropriate method based on the nature of your data and the impact of missing values on your analysis or machine learning models. The choice often depends on the dataset, the proportion of missing values, and the specific requirements of your analysis or modeling task.
1.2. What is imputation, why might it be useful in dealing with missing data, and how to do missing data imputation in Python?
Answer:
Imputation is the process of filling in missing values in a dataset with estimated or predicted values based on the available information. The goal is to provide a complete and usable dataset for analysis or modeling. Missing data can occur for various reasons, such as data collection errors, equipment malfunctions, or survey non-responses.
Why Imputation is Useful:
Preservation of Data Integrity: Imputation allows for the retention of observations with missing values, preserving the overall structure of the dataset.
Prevention of Information Loss: Discarding incomplete rows can lead to a significant loss of information, especially if the missing values are not randomly distributed.
Improved Model Performance: Machine learning models often require complete datasets for training. Imputation enables the use of more data, potentially improving model performance.
Reduced Bias in Analysis: Removing observations with missing values may introduce bias, especially if the missingness is related to the outcome variable or other factors.
Compatibility with Analysis Techniques: Some statistical and machine learning methods assume complete data. Imputation makes these techniques applicable to datasets with missing values.
Missing Data Imputation in Python:
In Python, the Pandas library provides several methods for missing data imputation. Here’s an overview of some common approaches:
Dropping Missing Values: The simplest approach is to drop rows or columns with missing values using the
dropna()method.
df.dropna() # Drops rows with any missing values
df.dropna(axis=1) # Drops columns with any missing values2. Filling Missing Values: Use the fillna() method to fill missing values with a specific value or a calculated one (e.g., mean, median).
df.fillna(value) # Fills missing values with a specific value
df.fillna(df.mean()) # Fills missing values with the mean of each column3. Imputation with Scikit-Learn: Scikit-Learn provides the SimpleImputer class for imputing missing values. It supports various strategies, such as mean, median, most frequent, or constant.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean')
df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)4. Time Series Interpolation: For time series data, you can use the interpolate() method to perform linear interpolation for missing values.
df.interpolate() # Performs linear interpolation to fill missing values in time series data5. Advanced Imputation Techniques: Techniques like k-nearest neighbors (KNN) imputation or multiple imputation (using libraries like fancyimpute or impyute) can be employed for more sophisticated imputation strategies.
from fancyimpute import KNN
df_imputed = pd.DataFrame(KNN(k=3).fit_transform(df), columns=df.columns)Remember to choose the appropriate method based on the nature of your data and the specific requirements of your analysis or modeling task. Careful consideration and validation of the imputation technique are crucial to ensuring the integrity of the results.
2. Data Transformation Questions
2.1. How can you encode categorical variables in a Pandas DataFrame?
Answer:
Encoding categorical variables is an important step in preparing data for machine learning models, as many algorithms require numerical input. Pandas provides several methods for encoding categorical variables. Here are two common techniques: Label Encoding and One-Hot Encoding.
1. Label Encoding:
Label Encoding involves converting each category in a column to a numerical label. It is suitable when the categories have an ordinal relationship.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Sample DataFrame with a categorical column 'Category'
data = {'Category': ['A', 'B', 'A', 'C', 'B']}
df = pd.DataFrame(data)
# Initialize the LabelEncoder
label_encoder = LabelEncoder()
# Apply LabelEncoder to the 'Category' column
df['Category_LabelEncoded'] = label_encoder.fit_transform(df['Category'])
# Display the DataFrame
print(df)In this example, the ‘Category’ column is encoded with numerical labels in a new column ‘Category_LabelEncoded’. Keep in mind that Label Encoding implies an ordinal relationship between the categories, which might not always be appropriate.
2. One-Hot Encoding:
One-Hot Encoding creates binary columns for each category, where each column represents the presence or absence of a category. It is suitable for nominal categorical variables without an ordinal relationship.
# Use the pandas get_dummies() function for One-Hot Encoding
df_onehot = pd.get_dummies(df, columns=['Category'], prefix='Category')
# Display the DataFrame with One-Hot Encoded columns
print(df_onehot)In this example, the ‘Category’ column is One-Hot Encoded, creating new binary columns for each category (‘Category_A’, ‘Category_B’, ‘Category_C’). Each row will have a 1 in the column corresponding to its category and 0 in the others.
Tips and Considerations:
Nominal vs. Ordinal Variables: Consider the nature of your categorical variables. Nominal variables, where categories have no inherent order, are often better suited for One-Hot Encoding. Ordinal variables, where there’s a meaningful order, may be appropriate for Label Encoding.
Pandas Categorical Data Type: If your DataFrame contains a column with the Pandas categorical data type, you can directly access the categorical codes. For instance:
df['Category_LabelEncoded'] = df['Category'].astype('category').cat.codesSparse Matrix for One-Hot Encoding: When dealing with a large number of categories, One-Hot Encoding can result in a sparse matrix with many zero values. Some machine learning libraries can efficiently handle sparse matrices, saving memory.
Choose the encoding method based on the characteristics of your data and the requirements of your machine-learning model. It’s essential to understand the implications of each encoding technique and how it may impact your model’s performance.
2.2. What is one-hot encoding, and when would you use it in data preprocessing?
Answer:
One-hot encoding is a technique used in data preprocessing to convert categorical variables into a binary matrix, where each category becomes a binary column. It is particularly useful for nominal categorical variables, where categories have no inherent order or ranking. The term “one-hot” refers to the creation of binary columns, where only one column has a value of 1 (hot) to represent the presence of a particular category.
Here’s an example to illustrate the concept:
Consider a DataFrame with a categorical column “Color” containing three categories: Red, Blue, and Green.

Applying One-Hot Encoding to the “Color” column would result in a new DataFrame with binary columns for each category:
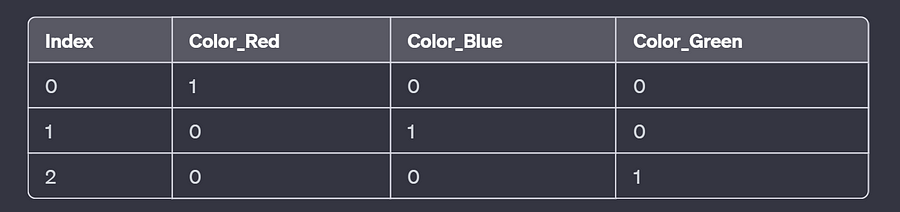
Here, each row represents an observation, and the binary columns indicate the presence (1) or absence (0) of a specific color.
When to Use One-Hot Encoding:
Nominal Categorical Variables: One-hot encoding is especially suitable for nominal categorical variables, where categories have no inherent order or ranking. Examples include country names, colors, or types of fruits.
Machine Learning Models: Many machine learning algorithms, especially those based on numerical computations, require numerical input. One-hot encoding is a way to represent categorical information in a format suitable for these algorithms.
Avoiding Ordinal Misinterpretation: Using One-Hot Encoding for nominal variables helps avoid misinterpretation of ordinal relationships. Label Encoding, another encoding technique, may inadvertently introduce a misleading ordinal relationship between categories.
Preventing Biases: One-Hot Encoding helps prevent biases that may arise from introducing numerical labels for categorical variables. The binary representation ensures that each category is treated independently.
Handling Sparse Data: When dealing with a large number of categories, One-Hot Encoding can result in a sparse matrix with many zero values. Some machine learning libraries and algorithms can efficiently handle sparse matrices, saving memory.
While One-Hot Encoding is a powerful technique, it’s essential to be mindful of potential challenges, such as the introduction of multicollinearity when highly correlated columns are created. In such cases, feature engineering techniques like dropping one of the columns or using dimensionality reduction may be necessary. Additionally, the choice of encoding depends on the specific characteristics of the data and the requirements of the machine-learning model.
3. Removing Duplicates Questions
3.1. How do you identify and remove duplicate rows from a DataFrame in Python?
Answer:
Identifying and removing duplicate rows from a DataFrame is a common data cleaning task in Python, and Pandas provides convenient methods to achieve this. Here’s how you can do it:
Identifying Duplicate Rows:
You can use the duplicated() method to identify duplicate rows in a DataFrame. The method returns a boolean Series where each entry indicates whether the row is a duplicate of a previous row.
import pandas as pd
# Create a sample DataFrame with duplicate rows
data = {'Column1': [1, 2, 2, 3, 4, 4],
'Column2': ['A', 'B', 'B', 'C', 'D', 'D']}
df = pd.DataFrame(data)
# Identify duplicate rows
duplicate_mask = df.duplicated()
# Display the DataFrame with a new column indicating duplicates
df['IsDuplicate'] = duplicate_mask
print(df)In this example, the duplicated() method identifies duplicate rows, and a new column 'IsDuplicate' is added to the DataFrame to mark whether a row is a duplicate.
Removing Duplicate Rows:
Once you have identified duplicate rows using the duplicated() method, you can use the drop_duplicates() method to remove them.
# Remove duplicate rows and create a new DataFrame
df_no_duplicates = df.drop_duplicates()
# Display the DataFrame without duplicates
print(df_no_duplicates)The drop_duplicates() method returns a new DataFrame with duplicate rows removed. If you want to modify the existing DataFrame in place, you can use the inplace=True parameter:
# Remove duplicates in-place
df.drop_duplicates(inplace=True)
# Display the DataFrame after removing duplicates
print(df)Considerations:
Subset of Columns: You can use the
subsetparameter in bothduplicated()anddrop_duplicates()to consider only a subset of columns when identifying and removing duplicates.
# Consider duplicates based on 'Column1'
df_no_duplicates = df.drop_duplicates(subset=['Column1'])2. Keep Last Occurrence: By default, drop_duplicates() keeps the first occurrence of a duplicated row and removes subsequent occurrences. You can change this behavior using the keep parameter.
# Keep the last occurrence and remove previous occurrences
df_no_duplicates = df.drop_duplicates(keep='last')3. Ignoring Index: If the index of the DataFrame is causing duplicates, you can reset the index before using duplicated() or drop_duplicates().
df.reset_index(drop=True, inplace=True)Identifying and removing duplicate rows is crucial for maintaining data quality, especially when preparing data for analysis or machine learning.
3.2. Can you explain the difference between the duplicated() and drop_duplicates() methods in Pandas?
Answer:
The duplicated() method is used to identify duplicate rows, and drop_duplicates() is used to create a DataFrame without those duplicates. They are often used together to first identify and then handle duplicate rows in a DataFrame.
Key Differences:
Output:
duplicated()returns a boolean Series indicating whether each row is a duplicate.drop_duplicates()returns a new DataFrame with duplicate rows removed.
2. Modification of DataFrame:
duplicated()does not modify the original DataFrame; it provides information about duplicates.drop_duplicates()can either return a new DataFrame or modify the original DataFrame in place, depending on the use of theinplaceparameter.
3. Handling Duplicates:
duplicated()is often used in combination with boolean indexing or other operations to handle duplicate rows selectively.drop_duplicates()is used when the goal is to create a DataFrame without duplicate rows.
4. Parameters: Both methods accept parameters such as subset and keep, allowing you to customize the behavior based on specific columns or criteria.
4. Data Scaling and Normalization Questions
4.1. Discuss the importance of feature scaling in machine learning.
Answer:
Feature scaling is a crucial step in the preprocessing of data for machine learning models. It involves transforming the features of a dataset to a standardized range. The main goal of feature scaling is to bring all features to a similar scale to prevent certain features from dominating the learning process, especially in algorithms that are sensitive to the scale of input features. Here are several reasons why feature scaling is important in machine learning:
Mitigating Scale Sensitivity: Many machine learning algorithms are sensitive to the scale of input features. For example, distance-based algorithms like k-nearest neighbors (KNN) or clustering algorithms may give more weight to features with larger scales. Feature scaling helps ensure that all features contribute equally to the model’s learning process.
Improving Convergence in Optimization Algorithms: Gradient-based optimization algorithms, such as those used in linear regression or neural networks, converge faster when features are on a similar scale. This can lead to quicker model training and reduced computation time.
Enhancing Model Performance: Feature scaling can improve the overall performance and accuracy of machine learning models. Standardizing the range of features makes it easier for models to identify patterns and relationships within the data.
Promoting Better Comparisons: Scaling features allows for a more meaningful comparison between them. Without scaling, it can be challenging to interpret the importance of different features when they have different scales.
Ensuring Robustness to Outliers: Feature scaling can make models more robust to outliers. Outliers can disproportionately affect models that are not scale-invariant, leading to suboptimal performance. Scaling helps mitigate the impact of outliers on the model.
Facilitating Interpretability: When features are on the same scale, it becomes easier to interpret the coefficients or weights assigned to each feature in linear models. This aids in understanding the contribution of each feature to the model’s predictions.
Enabling Certain Algorithms: Some algorithms, such as support vector machines (SVM) and principal component analysis (PCA), rely on the concept of distances or variances. Scaling is essential for these algorithms to function effectively.
Common methods of feature scaling include:
Min-Max Scaling (Normalization): Scales feature to a specific range (commonly [0, 1]).
Standardization (Z-score Normalization): Transforms features to have a mean of 0 and a standard deviation of 1.
Robust Scaling: Similar to standardization but less sensitive to outliers.
When applying feature scaling, it’s important to note that the choice of method depends on the characteristics of the data and the requirements of the specific machine learning algorithm being used.
4.2. Explain the difference between min-max scaling and z-score normalization in Python
Answer:
In Python, both Min-Max Scaling and Z-Score Normalization can be easily implemented using libraries such as NumPy or scikit-learn. Let’s explore the implementation of each method using a simple example:
Min-Max Scaling (Normalization) with scikit-learn:
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# Sample data
data = np.array([[1.0, 2.0],
[2.0, 3.0],
[3.0, 4.0]])
# Create MinMaxScaler instance
min_max_scaler = MinMaxScaler()
# Fit and transform the data
data_minmax_scaled = min_max_scaler.fit_transform(data)
print("Original Data:")
print(data)
print("\nMin-Max Scaled Data:")
print(data_minmax_scaled)Z-Score Normalization (Standardization) with scikit-learn:
from sklearn.preprocessing import StandardScaler
# Create StandardScaler instance
z_score_scaler = StandardScaler()
# Fit and transform the data
data_zscore_scaled = z_score_scaler.fit_transform(data)
print("Original Data:")
print(data)
print("\nZ-Score Scaled Data:")
print(data_zscore_scaled)In both cases, the fit_transform method is used to calculate the scaling parameters (e.g., min and max values for Min-Max Scaling, mean and standard deviation for Z-Score Normalization) and apply the scaling transformation to the data.
Key Differences:
Library Usage:
Min-Max Scaling: Utilizes
MinMaxScalerfrom scikit-learn.Z-Score Normalization: Utilizes
StandardScalerfrom scikit-learn.
2. Scaling Range:
Min-Max Scaling: Scales values to a specific range, commonly [0, 1].
Z-Score Normalization: Centers values around zero and scales them based on the standard deviation, resulting in a range that can include negative and positive values.
3. Sensitivity to Outliers:
Min-Max Scaling: Can be sensitive to outliers.
Z-Score Normalization: Less sensitive to outliers.
4. Implementation:
Both methods are straightforward to implement using scikit-learn, and they follow a similar pattern of creating a scaler instance, fitting it to the data, and transforming the data.
Choose the appropriate scaling method based on the characteristics of your data and the requirements of your machine-learning model. In some cases, it may be beneficial to try both scaling methods and observe the impact on the model’s performance.
5. Handling Outliers Questions
5.1. What are outliers, and why might they impact machine learning models?
Answer:
Outliers are data points that significantly differ from the rest of the observations in a dataset. They are values that lie far from the central tendency of a distribution. Outliers can occur in one or both tails of a distribution and may be the result of errors in data collection, natural variability, or extreme conditions.
Here are some characteristics of outliers:
Unusual Values: Outliers are observations that deviate markedly from other observations in the dataset.
Impact on Summary Statistics: Outliers can heavily influence summary statistics, such as the mean and standard deviation, leading to potentially misleading interpretations of the data.
Visualization: Outliers are often visually apparent when data is plotted on a graph, such as a box plot or scatter plot, where they appear as points far from the main cluster.
Reasons Outliers Might Impact Machine Learning Models:
Model Performance: Outliers can significantly impact the performance of machine learning models, particularly those sensitive to variations in the input data. Algorithms like linear regression or k-nearest neighbors can be strongly influenced by outliers, leading to suboptimal model performance.
Mean and Variance Sensitivity: Algorithms that rely on the mean and variance of the data, such as distance-based algorithms, can be sensitive to outliers. Outliers can disproportionately affect these measures, leading to biased or unreliable results.
Skewing Distributions: Outliers can distort the distribution of the data, making it non-normally distributed. Some models assume normality and the presence of outliers can violate this assumption.
Increased Model Complexity: Outliers can introduce noise into the training process, leading to overfitting. Models may attempt to fit the outliers, resulting in increased complexity and reduced generalization to new data.
Robustness of Models: Outliers can impact the robustness of models, making them less effective in handling real-world data. Robust models are less influenced by extreme values.
Data Preprocessing: Outliers often require special consideration during data preprocessing. Ignoring or mishandling outliers can lead to biased models or inaccurate predictions.
Methods for Handling Outliers:
Identification:
Use visualizations, such as box plots or scatter plots, to identify outliers.
Statistical methods, such as the IQR (Interquartile Range) or z-scores, can help detect outliers.
2. Treatment:
Depending on the context, outliers can be removed, transformed, or imputed.
Robust techniques, such as median-based methods, are less sensitive to outliers.
3. Model Selection: Choose models that are inherently robust to outliers, such as tree-based models (Random Forests, Decision Trees) or robust regression techniques.
Handling outliers requires a thoughtful approach that considers the characteristics of the data, the impact on the chosen machine learning algorithm, and the overall goals of the analysis.
5.2. Describe different methods for detecting outliers in a dataset in Python
Answer:
Detecting outliers in a dataset is an important step in data preprocessing. Here are several methods for detecting outliers in a dataset using Python:
1. Visual Inspection: Box Plots: Use box plots to visually identify outliers. Seaborn and Matplotlib are commonly used for creating box plots.
import seaborn as sns
import matplotlib.pyplot as plt
# Assuming 'data' is your DataFrame
sns.boxplot(data=data)
plt.show()2. Statistical Methods:
Z-Score: Calculate the z-scores of the data points and identify those with a z-score beyond a certain threshold (commonly 3).
from scipy.stats import zscore
z_scores = zscore(data)
outliers = (z_scores > 3) | (z_scores < -3)IQR (Interquartile Range): Identify outliers based on the interquartile range.
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
outliers = ((data < (Q1 - 1.5 * IQR)) | (data > (Q3 + 1.5 * IQR)))3. Distance-Based Methods: DBSCAN (Density-Based Spatial Clustering of Applications with Noise): A clustering algorithm that identifies outliers as points that do not belong to any cluster.
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=3, min_samples=2)
outliers = (dbscan.fit_predict(data) == -1)4. Isolation Forest: An ensemble learning method based on decision trees, where outliers are identified as instances that are easier to isolate.
from sklearn.ensemble import IsolationForest
isolation_forest = IsolationForest(contamination=0.05)
outliers = isolation_forest.fit_predict(data) == -15. Local Outlier Factor (LOF): Measures the local density deviation of a data point with respect to its neighbors, identifying points with significantly lower density.
from sklearn.neighbors import LocalOutlierFactor
lof = LocalOutlierFactor(n_neighbors=20, contamination=0.05)
outliers = lof.fit_predict(data) == -16. Visualizing Residuals: For regression problems, plot the residuals to identify data points with large errors.
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X, y)
residuals = y - model.predict(X)
outliers = (residuals > 3 * residuals.std()) | (residuals < -3 * residuals.std())7. Histograms and Kernel Density Estimation (KDE): Visualize the distribution of the data and identify points in the tails of the distribution.
sns.histplot(data, kde=True)
plt.show()Choose the method(s) that best suit your dataset and the characteristics of the outliers you are trying to identify. It’s often a good practice to use a combination of methods for a comprehensive outlier detection strategy.
5.3. How can you handle outliers in a continuous numerical variable in Python?
Answer:
Handling outliers in a continuous numerical variable involves several strategies, including detection, transformation, or removal. Here are some common approaches using Python:
Visual Inspection: Begin by visually inspecting the distribution of the variable using histograms or box plots to identify the presence of outliers.
import seaborn as sns
import matplotlib.pyplot as plt
# Assuming 'data' is your DataFrame and 'column_name' is the variable of interest
sns.boxplot(x=data['column_name'])
plt.show()2. Statistical Methods: Use statistical methods, such as Z-Score or IQR, to identify and filter out outliers.
from scipy.stats import zscore
z_scores = zscore(data['column_name'])
outliers = (z_scores > 3) | (z_scores < -3)
# Filter out outliers
data_no_outliers = data[~outliers]
python
Copy code
Q1 = data['column_name'].quantile(0.25)
Q3 = data['column_name'].quantile(0.75)
IQR = Q3 - Q1
outliers = ((data['column_name'] < (Q1–1.5 * IQR)) | (data['column_name'] > (Q3 + 1.5 * IQR)))
# Filter out outliers
data_no_outliers = data[~outliers]3. Winsorizing: Replace extreme values with values closer to the mean or median.
from scipy.stats.mstats import winsorize
data['column_name'] = winsorize(data['column_name'], limits=[0.05, 0.05])4. Transformation: Apply mathematical transformations to the variable, such as log transformation, to mitigate the impact of extreme values.
import numpy as np
data['column_name'] = np.log1p(data['column_name'])5. Clipping: Clip extreme values to a specified range.
lower_limit = data['column_name'].quantile(0.05)
upper_limit = data['column_name'].quantile(0.95)
data['column_name'] = data['column_name'].clip(lower=lower_limit, upper=upper_limit)6. Robust Scaling: Use robust scaling, which is less sensitive to outliers, to scale the variable.
from sklearn.preprocessing import RobustScaler
robust_scaler = RobustScaler()
data['column_name_scaled'] = robust_scaler.fit_transform(data[['column_name']])7. Remove Outliers: In extreme cases, you may decide to remove data points identified as outliers.
data = data[~outliers]Choose the method that best suits your data and the requirements of your analysis. It’s often advisable to carefully evaluate the impact of outlier handling on your analysis or model performance and document the steps taken.
6. Feature Engineering Questions
6.1. Provide examples of feature engineering techniques in Python you might apply to improve model performance.
Answer:
Feature engineering involves creating new features or modifying existing ones to improve the performance of machine learning models. Here are some common feature engineering techniques in Python:
Handling Missing Values: Impute missing values using techniques such as mean, median, or advanced imputation methods like K-Nearest Neighbors (KNN).
from sklearn.impute import SimpleImputer
# Assuming 'data' is your DataFrame
imputer = SimpleImputer(strategy='mean')
data['feature'] = imputer.fit_transform(data[['feature']])2. Creating Interaction Terms: Combine two or more features to capture their interaction.
data['interaction_feature'] = data['feature1'] * data['feature2']3. Polynomial Features: Introduce polynomial features to capture non-linear relationships.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
data_poly = poly.fit_transform(data[['feature']])4. Logarithmic Transformation: Apply a logarithmic transformation to handle skewed distributions.
import numpy as np
data['log_feature'] = np.log1p(data['feature'])5. Binning/Discretization: Convert continuous features into discrete bins.
data['bin_feature'] = pd.cut(data['feature'], bins=5, labels=False)6. Encoding Categorical Variables: Convert categorical variables into numerical format using techniques like one-hot encoding or label encoding.
# One-Hot Encoding
data_encoded = pd.get_dummies(data, columns=['categorical_feature'])
# Label Encoding
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
data['encoded_feature'] = label_encoder.fit_transform(data['categorical_feature'])7. Time-Based Features: Extract information from date/time features, such as day of the week, month, or time differences.
data['day_of_week'] = data['timestamp'].dt.dayofweek8. Target Encoding: Encode categorical variables based on the mean of the target variable.
mean_target = data.groupby('categorical_feature')['target'].mean()
data['target_encoded'] = data['categorical_feature'].map(mean_target)9. Feature Scaling: Scale numerical features to a similar range to prevent dominance by certain features.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data[['numerical_feature']])10. Feature Aggregation: Aggregate information over groups using methods such as mean, sum, or count.
aggregated_data = data.groupby('group_feature')['numeric_feature'].mean().reset_index()11. Text Feature Processing: Convert text data into numerical features using techniques like TF-IDF or word embeddings.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
text_features = tfidf_vectorizer.fit_transform(data['text_feature'])Feature engineering should be tailored to the specific characteristics of the dataset and the requirements of the machine learning model. Experimenting with different techniques and understanding the domain can lead to improved model performance.
7. Data Transformation Pipelines Questions
7.1. Discuss the benefits of using tools like scikit-learn Pipeline for data preprocessing.
Answer:
Using tools like scikit-learn’s Pipeline for data preprocessing offers several benefits, contributing to cleaner, more efficient, and reproducible machine learning workflows. Here are some of the key advantages:
Organization and Readability:
Modular Structure: Pipelines allow you to organize your data preprocessing steps in a modular and readable way. Each step in the pipeline is explicit, making it easier for others (or your future self) to understand the workflow.
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
# Example pipeline
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('classifier', RandomForestClassifier())
])2. Consistent Parameter Application:
Parameter Setting: Pipelines help ensure that the same set of parameters is applied consistently across all preprocessing steps. This reduces the risk of errors due to inconsistent parameter tuning.
# Specify parameters for each step in the pipeline
parameters = {
'imputer__strategy': ['mean', 'median'],
'classifier__n_estimators': [50, 100, 200]
}3. Avoiding Data Leakage:
Fit and Transform: Pipelines automatically take care of fitting and transforming the data at each step, helping to avoid data leakage. This ensures that transformations are learned from the training data and applied consistently to the validation or test data.
4. Grid Search and Cross-Validation:
Grid Search Integration: Pipelines seamlessly integrate with scikit-learn’s grid search (
GridSearchCV) and cross-validation (cross_val_score) tools. This simplifies hyperparameter tuning and model evaluation.
from sklearn.model_selection import GridSearchCV
# Example grid search with pipeline
param_grid = {
'imputer__strategy': ['mean', 'median'],
'classifier__n_estimators': [50, 100, 200]
}
grid_search = GridSearchCV(pipeline, param_grid, cv=5)5. Reproducibility:
Pipelines promote reproducibility by encapsulating the entire preprocessing workflow in a single object. This makes it easier to share and reproduce the entire data processing and modeling pipeline.
6. Integration with Feature Union:
Feature Union: Pipelines can be extended with
FeatureUnionto handle multiple feature extraction processes in parallel. This is particularly useful when dealing with datasets that require different preprocessing for different subsets of features.
7. Code Efficiency:
Code Efficiency: Pipelines reduce the need for boilerplate code, making it more concise and efficient. This is especially beneficial when working with large or complex datasets.
8. Easier Model Deployment:
Model Deployment: Having a single object (the pipeline) that encapsulates the entire preprocessing and modeling workflow simplifies the process of deploying machine learning models to production.
9. Compatibility with Other Libraries:
Integration with Other Libraries: Pipelines in scikit-learn are compatible with other libraries that follow the scikit-learn API, facilitating integration into larger machine learning workflows.
In summary, using tools like scikit-learn’s Pipeline for data preprocessing provides a more organized, readable, and reproducible approach to building machine learning workflows. It simplifies parameter tuning, avoids data leakage, and streamlines the process of building, evaluating, and deploying machine learning models.
7.2. How do you handle categorical and numerical features differently in a pipeline?
Answer:
Handling categorical and numerical features differently in a machine learning pipeline is a common practice because these types of features often require distinct preprocessing steps. Scikit-learn provides tools like ColumnTransformer to handle such scenarios efficiently. Here’s a step-by-step guide on how to handle categorical and numerical features differently in a pipeline:
Import Necessary Libraries:
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.ensemble import RandomForestClassifier2. Load Data: Load your dataset into a Pandas DataFrame.
# Assuming 'data' is your DataFrame
data = pd.read_csv('your_dataset.csv')3. Identify Categorical and Numerical Features: Identify which features are categorical and which are numerical.
categorical_features = ['categorical_feature1', 'categorical_feature2']
numerical_features = ['numerical_feature1', 'numerical_feature2']4. Create a ColumnTransformer: Use ColumnTransformer to specify different preprocessing steps for numerical and categorical features.
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numerical_features),
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)
])In this example: For numerical features, we use StandardScaler to standardize them. For categorical features, we use OneHotEncoder to perform one-hot encoding.
5. Build the Pipeline: Combine the preprocessing steps with a machine learning model in a pipeline.
pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', RandomForestClassifier())
])6. Fit and Predict: Fit the pipeline on your training data and use it for predictions.
X = data.drop('target', axis=1) # Assuming 'target' is the target variable
y = data['target']
pipeline.fit(X, y)
predictions = pipeline.predict(X)7. Grid Search with Pipeline: Integrate the pipeline with grid search for hyperparameter tuning.
from sklearn.model_selection import GridSearchCV
param_grid = {
'classifier__n_estimators': [50, 100, 200],
'classifier__max_depth': [None, 10, 20],
# Add other parameters for tuning
}
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(X, y)8. Dealing with Skewed Data Questions
8.1. How can you transform skewed data to make it more suitable for modeling?
Answer:
Transforming skewed data is a common preprocessing step in machine learning to make the distribution more symmetrical and improve the performance of certain models. The most commonly used technique is applying a logarithmic transformation. Here are the steps to transform skewed data:
Identify Skewed Features: Use visualizations like histograms or statistical measures like skewness to identify features with a skewed distribution.
import seaborn as sns
import matplotlib.pyplot as plt
# Assuming 'data' is your DataFrame
sns.histplot(data['skewed_feature'], kde=True)
plt.show()
# Check skewness
skewness = data['skewed_feature'].skew()2. Apply Logarithmic Transformation: For positively skewed data, use the logarithmic transformation.
import numpy as np
# Assuming 'data' is your DataFrame and 'skewed_feature' is the feature to be transformed
data['log_skewed_feature'] = np.log1p(data['skewed_feature'])For negatively skewed data, consider other transformations like square root.
data['sqrt_skewed_feature'] = np.sqrt(data['skewed_feature'])Ensure that the values in the feature are greater than zero before applying the logarithmic transformation.
3. Compare Distributions: Visualize the transformed feature to compare its distribution with the original.
sns.histplot(data['log_skewed_feature'], kde=True)
plt.show()4. Check Skewness After Transformation: Verify that the transformed feature has a reduced skewness.
transformed_skewness = data['log_skewed_feature'].skew()5. Consider Box-Cox Transformation: The Box-Cox transformation is a more general method that can handle both positively and negatively skewed data. It includes a parameter (λ) that is optimized for each feature.
from scipy.stats import boxcox
# Assuming 'data' is your DataFrame
data['boxcox_skewed_feature'], _ = boxcox(data['skewed_feature'])6. Evaluate Impact on Model Performance:
Assess the impact of the transformed features on the performance of your machine learning model.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
