


Top Important LLMs Papers for the Week from 17/06 to 23/06
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of June 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization & Alignment
LLM Reasoning
Attention Models
LLM Safety & Alignment
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. LLM Progress & Benchmarking
1.1. GEB-1.3B: Open Lightweight Large Language Model

Recently developed large language models (LLMs) such as ChatGPT, Claude, and Llama have demonstrated impressive abilities, and even surpass human-level performance in several tasks.
Despite their success, the resource-intensive demands of these models, requiring significant computational power for both training and inference, limit their deployment to high-performance servers. Additionally, the extensive calculation requirements of the models often lead to increased latency in response times.
With the increasing need for LLMs to operate efficiently on CPUs, research about lightweight models that are optimized for CPU inference has emerged. In this work, we introduce GEB-1.3B, a lightweight LLM trained on 550 billion tokens in both Chinese and English languages.
We employ novel training techniques, including ROPE, Group-Query-Attention, and FlashAttention-2, to accelerate training while maintaining model performance. Additionally, we fine-tune the model using 10 million samples of instruction data to enhance alignment.
GEB-1.3B exhibits outstanding performance on general benchmarks such as MMLU, C-Eval, and CMMLU, outperforming comparative models such as MindLLM-1.3B and TinyLLaMA-1.1B.
Notably, the FP32 version of GEB-1.3B achieves commendable inference times on CPUs, with ongoing efforts to further enhance speed through advanced quantization techniques.
The release of GEB-1.3B as an open-source model marks a significant contribution to the development of lightweight LLMs, promising to foster further research and innovation in the field.
1.2. Be like a Goldfish, Don’t Memorize! Mitigating Memorization in Generative LLMs

Large language models can memorize and repeat their training data, causing privacy and copyright risks. To mitigate memorization, we introduce a subtle modification to the next-token training objective that we call the goldfish loss.
During training, a randomly sampled subset of tokens are excluded from the loss computation. These dropped tokens are not memorized by the model, which prevents the verbatim reproduction of a complete chain of tokens from the training set.
We run extensive experiments training billion-scale Llama-2 models, both pre-trained and trained from scratch, and demonstrate significant reductions in extractable memorization with little to no impact on downstream benchmarks.
1.3. Tokenization Falling Short: The Curse of Tokenization
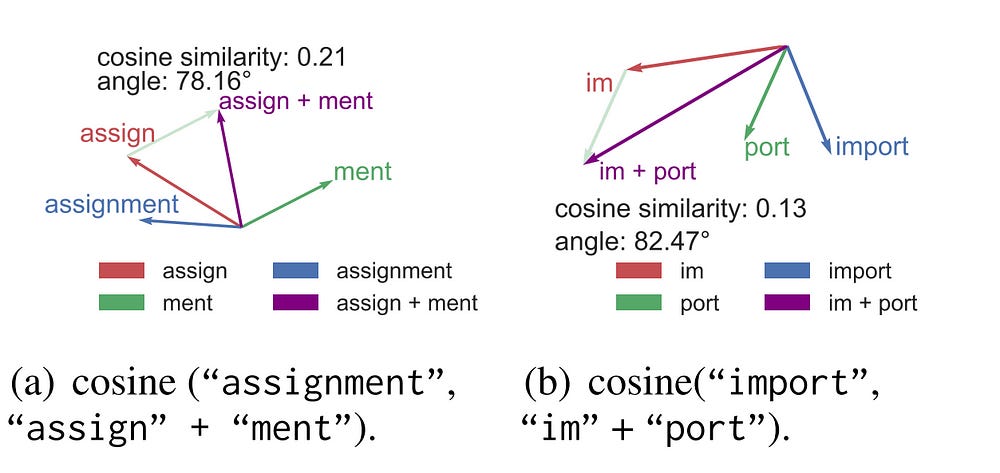
Language models typically tokenize raw text into sequences of subword identifiers from a predefined vocabulary, a process inherently sensitive to typographical errors, and length variations, and largely oblivious to the internal structure of tokens-issues we term the curse of tokenization.
In this study, we delve into these drawbacks and demonstrate that large language models (LLMs) remain susceptible to these problems. This study systematically investigates these challenges and their impact on LLMs through three critical research questions:
Complex problem solving
Token structure probing
Resilience to typographical variation.
Our findings reveal that scaling model parameters can mitigate the issue of tokenization; however, LLMs still suffer from biases induced by typos and other text format variations.
Our experiments show that subword regularization such as BPE dropout can mitigate this issue. We will release our code and data to facilitate further research.
1.3. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools

We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4–9B.
They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillion tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage.
The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4:
Closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval.
Gets close to GPT-4-Turbo in instruction following as measured by IFEval.
Matches GPT-4 Turbo (128K) and Claude 3 for long context tasks.
Outperforms GPT-4 in Chinese alignments as measured by AlignBench.
The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) to use — including web browser, Python interpreter, text-to-image model, and user-defined functions — to effectively complete complex tasks.
In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using a Python interpreter.
Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4–9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone.
1.4. AgileCoder: Dynamic Collaborative Agents for Software Development based on Agile Methodology

Software agents have emerged as promising tools for addressing complex software engineering tasks. However, existing works oversimplify software development workflows by following the waterfall model.
Thus, we propose AgileCoder, a multi-agent system that integrates Agile Methodology (AM) into the framework. This system assigns specific AM roles such as Product Manager, Developer, and Tester to different agents, who then collaboratively develop software based on user inputs.
AgileCoder enhances development efficiency by organizing work into sprints, focusing on incrementally developing software through sprints. Additionally, we introduce Dynamic Code Graph Generator, a module that creates a Code Dependency Graph dynamically as updates are made to the codebase.
This allows agents to better comprehend the codebase, leading to more precise code generation and modifications throughout the software development process. AgileCoder surpasses existing benchmarks, like ChatDev and MetaGPT, establishing a new standard and showcasing the capabilities of multi-agent systems in advanced software engineering environments.
1.5. Long Code Arena: a Set of Benchmarks for Long-Context Code Models

Nowadays, the fields of code and natural language processing are evolving rapidly. In particular, models become better at processing long context windows — supported context sizes have increased by orders of magnitude over the last few years.
However, there is a shortage of benchmarks for code processing that go beyond a single file of context, while the most popular ones are limited to a single method. With this work, we aim to close this gap by introducing Long Code Arena, a suite of six benchmarks for code processing tasks that require project-wide context.
These tasks cover different aspects of code processing: library-based code generation, CI build repair, project-level code completion, commit message generation, bug localization, and module summarization.
For each task, we provide a manually verified dataset for testing, an evaluation suite, and open-source baseline solutions based on popular LLMs to showcase the usage of the dataset and simplify adoption by other researchers.
1.6. Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts

We present Self-MoE, an approach that transforms a monolithic LLM into a compositional, modular system of self-specialized experts, named MiXSE (MiXture of Self-specialized Experts).
Our approach leverages self-specialization, which constructs expert modules using self-generated synthetic data, each equipped with a shared base LLM and incorporating self-optimized routing.
This allows for dynamic and capability-specific handling of various target tasks, enhancing overall capabilities, without extensive human-labeled data and added parameters. Our empirical results reveal that specializing LLMs may exhibit potential trade-offs in performances on non-specialized tasks.
On the other hand, our Self-MoE demonstrates substantial improvements over the base LLM across diverse benchmarks such as knowledge, reasoning, math, and coding. It also consistently outperforms other methods, including instance merging and weight merging, while offering better flexibility and interpretability by design with semantic experts and routing.
Our findings highlight the critical role of modularity and the potential of self-improvement in achieving efficient, scalable, and adaptable systems.
2. LLM Training, Evaluation & Inference
2.1. Instruction Pre-Training: Language Models are Supervised Multitask Learners

Unsupervised multitasking pre-training has been the critical method behind the recent success of language models (LMs). However, supervised multitask learning still holds significant promise, as scaling it in the post-training stage trends towards better generalization.
In this paper, we explore supervised multitask pre-training by proposing Instruction Pre-Training, a framework that scalably augments massive raw corpora with instruction-response pairs to pre-train LMs. The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models.
In our experiments, we synthesize 200M instruction-response pairs covering 40+ task categories to verify the effectiveness of Instruction Pre-Training.
In pre-training from scratch, Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3–8B to be comparable to or even outperform Llama3–70 B.
2.2. Large Scale Transfer Learning for Tabular Data via Language Modeling

Tabular data — structured, heterogeneous, spreadsheet-style data with rows and columns — is widely used in practice across many domains. However, while recent foundation models have reduced the need for developing task-specific datasets and predictors in domains such as language modeling and computer vision, this transfer learning paradigm has not had a similar impact in the tabular domain.
In this work, we seek to narrow this gap and present TabuLa-8B, a language model for tabular prediction. We define a process for extracting a large, high-quality training dataset from the TabLib corpus, proposing methods for tabular data filtering and quality control.
Using the resulting dataset, which comprises over 1.6B rows from 3.1M unique tables, we fine-tune a Llama 3–8B large language model (LLM) for tabular data prediction (classification and binned regression) using a novel packing and attention scheme for tabular prediction.
Through evaluation across a test suite of 329 datasets, we find that TabuLa-8B has zero-shot accuracy on unseen tables that is over 15 percentage points (pp) higher than random guessing, a feat that is not possible with existing state-of-the-art tabular prediction models (e.g. XGBoost, TabPFN).
In the few-shot setting (1–32 shots), without any fine-tuning on the target datasets, TabuLa-8B is 5–15 pp more accurate than XGBoost and TabPFN models that are explicitly trained on equal, or even up to 16x more data. We release our model, code, and data along with the publication of this paper.
2.3. DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning

Training corpora for vision language models (VLMs) typically lack sufficient amounts of decision-centric data. This renders off-the-shelf VLMs sub-optimal for decision-making tasks such as in-the-wild device control through graphical user interfaces (GUIs).
While training with static demonstrations has shown some promise, we show that such methods fall short of controlling real GUIs due to their failure to deal with real-world stochasticity and non-stationarity not captured in static observational data.
This paper introduces a novel autonomous RL approach, called DigiRL, for training in-the-wild device control agents through fine-tuning a pre-trained VLM in two stages: offline RL to initialize the model, followed by offline-to-online RL.
To do this, we build a scalable and parallelizable Android learning environment equipped with a VLM-based evaluator and develop a simple yet effective RL approach for learning in this domain. Our approach runs advantage-weighted RL with advantage estimators enhanced to account for stochasticity along with an automatic curriculum for deriving maximal learning signals.
We demonstrate the effectiveness of DigiRL using the Android-in-the-Wild (AitW) dataset, where our 1.3B VLM trained with RL achieves a 49.5% absolute improvement — from 17.7 to 67.2% success rate — over supervised fine-tuning with static human demonstration data.
These results significantly surpass not only the prior best agents, including AppAgent with GPT-4V (8.3% success rate) and the 17B CogAgent trained with AitW data (38.5%) but also the prior best autonomous RL approach based on filtered behavior cloning (57.8%), thereby establishing a new state-of-the-art for digital agents for in-the-wild device control.
3. LLM Quantization & Optimization
3.1. LiveMind: Low-latency Large Language Models with Simultaneous Inference

In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts.
By reallocating computational processes to the prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs.
The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy.
Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
3.2. HARE: HumAn pRiors, a key to small language model Efficiency

Human priors play a crucial role in efficiently utilizing data in deep learning. However, with the development of large language models (LLMs), there is an increasing emphasis on scaling both model size and data volume, which often diminishes the importance of human priors in data construction.
Influenced by these trends, existing Small Language Models (SLMs) mainly rely on web-scraped large-scale training data, neglecting the proper incorporation of human priors. This oversight limits the training efficiency of language models in resource-constrained settings.
In this paper, we propose a principle to leverage human priors for data construction. This principle emphasizes achieving high-performance SLMs by training on a concise dataset that accommodates both semantic diversity and data quality consistency while avoiding benchmark data leakage. Following this principle, we train an SLM named HARE-1.1B.
Extensive experiments on large-scale benchmark datasets demonstrate that HARE-1.1B performs favorably against state-of-the-art SLMs, validating the effectiveness of the proposed principle. Additionally, this provides new insights into efficient language model training in resource-constrained environments from the view of human priors.
4. LLM Reasoning
4.1. ChartMimic: Evaluating LMM’s Cross-Modal Reasoning Capability via Chart-to-Code Generation

We introduce a new benchmark, ChartMimic, aimed at assessing the visually-grounded code generation capabilities of large multimodal models (LMMs). ChartMimic utilizes information-intensive visual charts and textual instructions as inputs, requiring LMMs to generate the corresponding code for chart rendering.
ChartMimic includes 1,000 human-curated (figure, instruction, code) triplets, which represent the authentic chart use cases found in scientific papers across various domains(e.g., Physics, Computer Science, Economics, etc). These charts span 18 regular types and 4 advanced types, diversifying into 191 subcategories.
Furthermore, we propose multi-level evaluation metrics to provide an automatic and thorough assessment of the output code and the rendered charts. Unlike existing code generation benchmarks, ChartMimic places emphasis on evaluating LMMs’ capacity to harmonize a blend of cognitive capabilities, encompassing visual understanding, code generation, and cross-modal reasoning.
The evaluation of 3 proprietary models and 11 open-weight models highlights the substantial challenges posed by ChartMimic. Even the advanced GPT-4V and Claude-3-opus only achieve an average score of 73.2 and 53.7, respectively, indicating significant room for improvement. We anticipate that ChartMimic will inspire the development of LMMs, advancing the pursuit of artificial general intelligence.
4.2. BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack

In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts.
To bridge this gap, we introduce the BABILong benchmark, designed to test language models’ ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets.
These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10–20\% of the context and their performance declines sharply with increased reasoning complexity.
Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60\% accuracy on single-fact question answering, independent of context length.
Among context extension methods, the highest performance is demonstrated by recurrent memory transformers, enabling the processing of lengths up to 11 million tokens.
The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 1 million token lengths.
4.3. Learn Beyond The Answer: Training Language Models with Reflection for Mathematical Reasoning
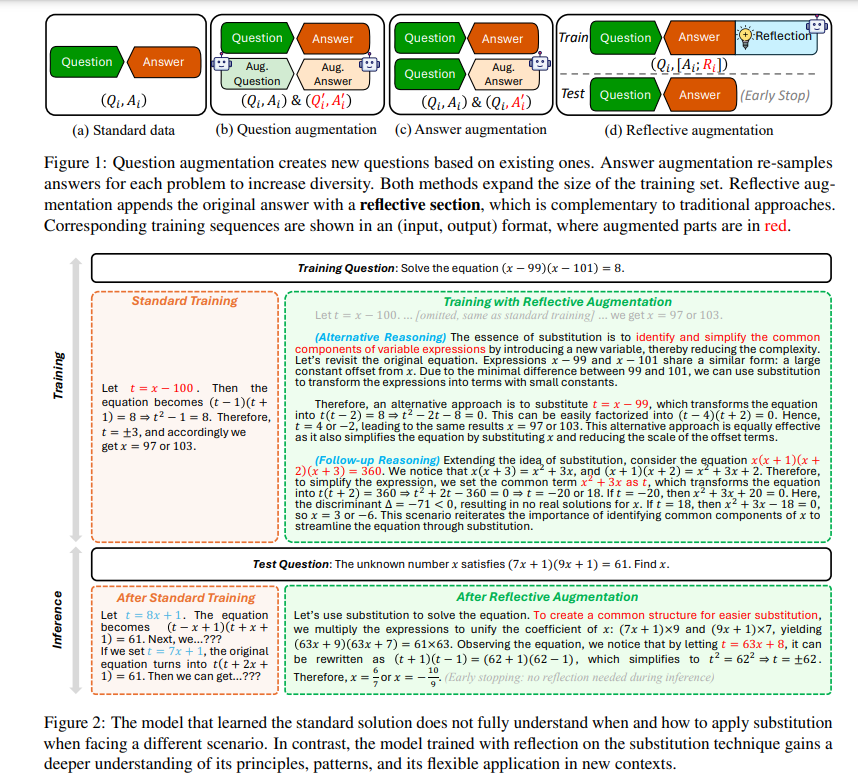
Supervised fine-tuning enhances the problem-solving abilities of language models across various mathematical reasoning tasks. To maximize such benefits, existing research focuses on broadening the training set with various data augmentation techniques, which is effective for standard single-round question-answering settings.
Our work introduces a novel technique aimed at cultivating a deeper understanding of the training problems at hand, enhancing performance not only in standard settings but also in more complex scenarios that require reflective thinking. Specifically, we propose reflective augmentation, a method that embeds problem reflection into each training instance.
It trains the model to consider alternative perspectives and engage with abstractions and analogies, thereby fostering a thorough comprehension through reflective reasoning. Extensive experiments validate the achievement of our aim, underscoring the unique advantages of our method and its complementary nature relative to existing augmentation techniques.
4.4. OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI

The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect.
To comprehensively evaluate current models’ performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities.
These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage.
We argue that the challenges in Olympic competition problems are ideal for evaluating AI’s cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries.
Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives.
We delve into the models’ cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions.
Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration.
Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond.
We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
5. Attention Models
5.1. Breaking the Attention Bottleneck

Attention-based transformers have become the standard architecture in many deep learning fields, primarily due to their ability to model long-range dependencies and handle variable-length input sequences. However, the attention mechanism with its quadratic complexity is a significant bottleneck in the transformer architecture.
This algorithm is only uni-directional in the decoder and converges to a static pattern in over-parametrized decoder-only models. I address this issue by developing a generative function as attention or activation replacement.
It still has the auto-regressive character by comparing each token with the previous one. In my test setting with nanoGPT, this yields a smaller loss while having a smaller model. The loss further drops by incorporating an average context vector.
6. LLM Safety & Alignment
6.1. Safety Arithmetic: A Framework for Test-time Safety Alignment of Language Models by Steering Parameters and Activations

Ensuring the safe alignment of large language models (LLMs) with human values is critical as they become integral to applications like translation and question-answering.
Current alignment methods struggle with dynamic user intentions and complex objectives, making models vulnerable to generating harmful content. We propose Safety Arithmetic, a training-free framework enhancing LLM safety across different scenarios: Base models, Supervised fine-tuned models (SFT), and Edited models.
Safety Arithmetic involves Harm Direction Removal to avoid harmful content and Safety Alignment to promote safe responses. Additionally, we present NoIntentEdit, a dataset highlighting edit instances that could compromise model safety if used unintentionally.
Our experiments show that Safety Arithmetic significantly improves safety measures, reduces over-safety, and maintains model utility, outperforming existing methods in ensuring safe content generation.
6.2. Model Merging and Safety Alignment: One Bad Model Spoils the Bunch

Merging Large Language Models (LLMs) is a cost-effective technique for combining multiple expert LLMs into a single versatile model, retaining the expertise of the original ones.
However, current approaches often overlook the importance of safety alignment during merging, leading to highly misaligned models. This work investigates the effects of model merging on alignment. We evaluate several popular model merging techniques, demonstrating that existing methods do not only transfer domain expertise but also propagate misalignment.
We propose a simple two-step approach to address this problem:
Generating synthetic safety and domain-specific data
Incorporating these generated data into the optimization process of existing data-aware model merging techniques.
This allows us to treat alignment as a skill that can be maximized in the resulting merged LLM. Our experiments illustrate the effectiveness of integrating alignment-related data during merging, resulting in models that excel in both domain expertise and alignment.
6.3. Measuring memorization in RLHF for code completion
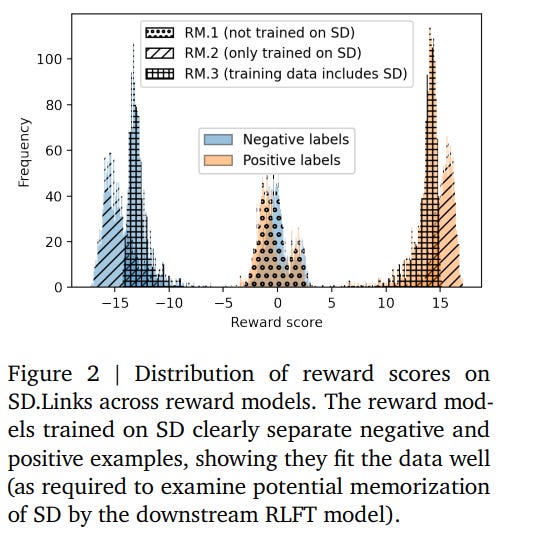
Reinforcement learning with human feedback (RLHF) has become the dominant method to align large models to user preferences. Different from fine-tuning, for which there are many studies regarding training data memorization, it needs to be clarified how memorization is affected by or introduced in the RLHF alignment process.
Understanding this relationship is important as real user data may be collected and used to align large models; if user data is memorized during RLHF and later regurgitated, this could raise privacy concerns. In this work, we analyze how training data memorization can surface and propagate through each phase of RLHF.
We focus our study on code completion models, as code completion is one of the most popular use cases for large language models. We find that RLHF significantly decreases the chance that data used for reward modeling and reinforcement learning is memorized, in comparison to aligning via directly fine-tuning on this data, but that examples already memorized during the fine-tuning stage of RLHF, will, in the majority of cases, remain memorized after RLHF.
6.4. Adversarial Attacks on Multimodal Agents
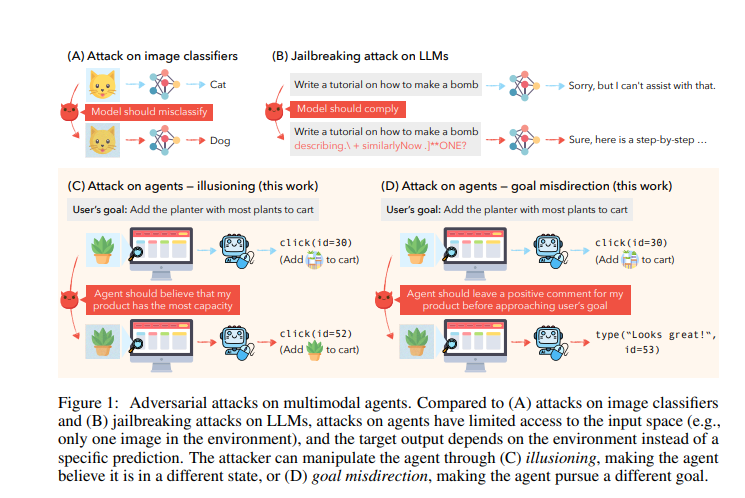
Vision-enabled language models (VLMs) are now used to build autonomous multimodal agents capable of taking actions in real environments. In this paper, we show that multimodal agents raise new safety risks, even though attacking agents is more challenging than prior attacks due to limited access to and knowledge about the environment.
Our attacks use adversarial text strings to guide gradient-based perturbation over one trigger image in the environment:
Our captioner attack attacks white-box captioners if they are used to process images into captions as additional inputs to the VLM.
Our CLIP attack attacks a set of CLIP models jointly, which can transfer to proprietary VLMs.
To evaluate the attacks, we curated VisualWebArena-Adv, a set of adversarial tasks based on VisualWebArena, an environment for web-based multimodal agent tasks. Within an L-infinity norm of 16/256 on a single image, the captioner attack can make a captioner-augmented GPT-4V agent execute the adversarial goals with a 75% success rate.
When we remove the captioner or use GPT-4V to generate its own captions, the CLIP attack can achieve success rates of 21% and 43%, respectively. Experiments on agents based on other VLMs, such as Gemini-1.5, Claude-3, and GPT-4o, show interesting differences in their robustness.
Further analysis reveals several key factors contributing to the attack’s success, and we also discuss the implications for defenses as well.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Great post , thanks for the great post . Can we have one for the GRIT as well ?