


Top Important LLMs Papers for the Week from 03/06 to 09/06
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of June 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization & Alignment
Attention Models
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization & Optimization
LLM Alignment & RLHF
LLM Reasoning
Attention Models
1. LLM Progress & Benchmarking
1.1. To Believe or Not to Believe Your LLM
We explore uncertainty quantification in large language models (LLMs), to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers).
In particular, we derive an information-theoretic metric that allows us to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses.
Such quantification, for instance, allows to detection of hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected.
We conduct a series of experiments that demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
1.2. Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
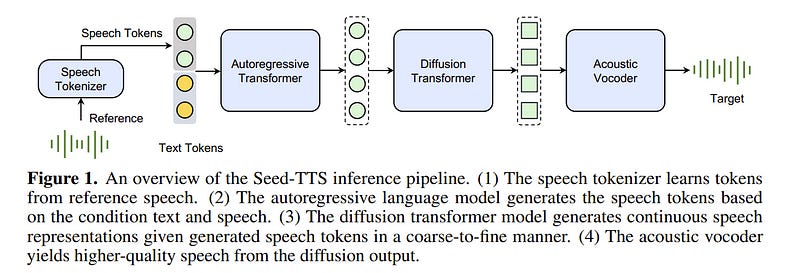
We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech.
Seed-TTS serves as a foundation model for speech generation and excels in speech-in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics.
Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability.
We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named Seed-TTS_DiT, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, Seed-TTS_DiT does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing.
We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing.
1.3. Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration

Mobile device operation tasks are increasingly becoming a popular multi-modal AI application scenario. Current Multi-modal Large Language Models (MLLMs), constrained by their training data, lack the capability to function effectively as operation assistants.
Instead, MLLM-based agents, which enhance capabilities through tool invocation, are gradually being applied to this scenario. However, the two major navigation challenges in mobile device operation tasks, task progress navigation, and focus content navigation are significantly complicated under the single-agent architecture of existing work.
This is due to the overly long token sequences and the interleaved text-image data format, which limit performance. To address these navigation challenges effectively, we propose Mobile-Agent-v2, a multi-agent architecture for mobile device operation assistance.
The architecture comprises three agents: a planning agent, a decision agent, and a reflection agent. The planning agent generates task progress, making the navigation of history operations more efficient. To retain focus content, we designed a memory unit that updates with task progress. Additionally, to correct erroneous operations, the reflection agent observes the outcomes of each operation and handles any mistakes accordingly.
Experimental results indicate that Mobile-Agent-v2 achieves over a 30% improvement in task completion compared to the single-agent architecture of Mobile-Agent.
1.4. PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM

Layout generation is the keystone in achieving automated graphic design, requiring arranging the position and size of various multi-modal design elements in a visually pleasing and constraint-following manner. Previous approaches are either inefficient for large-scale applications or lack flexibility for varying design requirements.
Our research introduces a unified framework for automated graphic layout generation, leveraging the multi-modal large language model (MLLM) to accommodate diverse design tasks. In contrast, our data-driven method employs structured text (JSON format) and visual instruction tuning to generate layouts under specific visual and textual constraints, including user-defined natural language specifications.
We conducted extensive experiments and achieved state-of-the-art (SOTA) performance on public multi-modal layout generation benchmarks, demonstrating the effectiveness of our method.
Moreover, recognizing existing datasets’ limitations in capturing the complexity of real-world graphic designs, we propose two new datasets for much more challenging tasks (user-constrained generation and complicated poster), further validating our model’s utility in real-life settings. Marking by its superior accessibility and adaptability, this approach further automates large-scale graphic design tasks.
2. LLM Training, Evaluation & Inference
2.1. MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark

In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains.
However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities.
This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU.
Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4–5% in MMLU to just 2% in MMLU-Pro.
Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.
3. LLM Quantization & Optimization
3.1. 4-bit Shampoo for Memory-Efficient Network Training
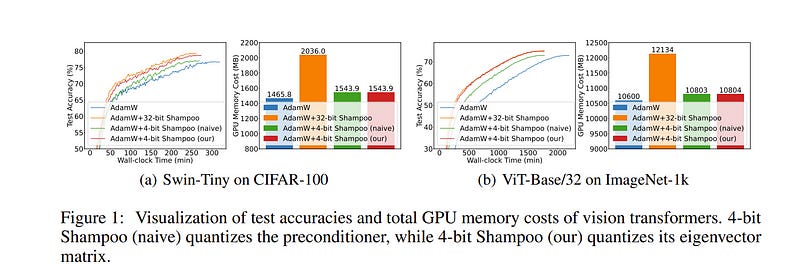
Second-order optimizers, maintaining a matrix termed a preconditioner, are superior to first-order optimizers in both theory and practice. The states forming the preconditioner and its inverse root restrict the maximum size of models trained by second-order optimizers.
To address this, compressing 32-bit optimizer states to lower bandwidths has shown promise in reducing memory usage. However, current approaches only pertain to first-order optimizers. In this paper, we propose the first 4-bit second-order optimizers, exemplified by 4-bit Shampoo, maintaining performance similar to that of 32-bit ones.
We show that quantizing the eigenvector matrix of the preconditioner in 4-bit Shampoo is remarkably better than quantizing the preconditioner itself both theoretically and experimentally. By rectifying the orthogonality of the quantized eigenvector matrix, we enhance the approximation of the preconditioner’s eigenvector matrix, which also benefits the computation of its inverse 4-th root.
Besides, we find that linear square quantization slightly outperforms dynamic tree quantization when quantizing second-order optimizer states. Evaluation on various networks for image classification demonstrates that our 4-bit Shampoo achieves comparable test accuracy to its 32-bit counterpart while being more memory-efficient. The source code will be made available.
3.2. PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
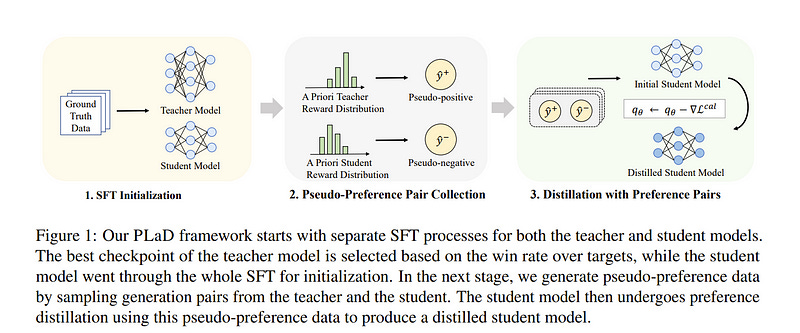
Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models.
However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs.
Then, PLaD leverages a ranking loss to re-calibrate a student’s estimation of sequence likelihood, which steers the student’s focus towards understanding the relative quality of outputs instead of simply imitating the teacher.
PLaD bypasses the need for access to teacher LLM’s internal states, tackles the student’s expressivity limitations, and mitigates the student's miscalibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
3.3. Self-Improving Robust Preference Optimization

Both online and offline RLHF methods such as PPO and DPO have been extremely successful in aligning AI with human preferences. Despite their success, the existing methods suffer from a fundamental problem in that their optimal solution is highly task-dependent (i.e., not robust to out-of-distribution (OOD) tasks).
Here we address this challenge by proposing Self-Improving Robust Preference Optimization SRPO, a practical and mathematically principled offline RLHF framework that is completely robust to the changes in the task. The key idea of SRPO is to cast the problem of learning from human preferences as a self-improvement process, which can be mathematically expressed in terms of a min-max objective that aims at joint optimization of self-improvement policy and the generative policy in an adversarial fashion.
The solution for this optimization problem is independent of the training task and thus it is robust to its changes. We then show that this objective can be re-expressed in the form of a non-adversarial offline loss which can be optimized using standard supervised optimization techniques at scale without any need for reward model and online inference.
We show the effectiveness of SRPO in terms of AI win rate (WR) against human (GOLD) completions. In particular, when SRPO is evaluated on the OOD XSUM dataset, it outperforms the celebrated DPO by a clear margin of 15% after 5 self-revisions, achieving WR of 90%.
3.4. μLO: Compute-Efficient Meta-Generalization of Learned Optimizers

Learned optimizers (LOs) can significantly reduce the wall-clock training time of neural networks, substantially reducing training costs. However, they often suffer from poor meta-generalization, especially when training networks are larger than those seen during meta-training.
To address this, we use the recently proposed Maximal Update Parametrization (muP), which allows zero-shot generalization of optimizer hyperparameters from smaller to larger models. We extend muP theory to learned optimizers, treating the meta-training problem as finding the learned optimizer under muP.
Our evaluation shows that LOs meta-trained with muP substantially improve meta-generalization as compared to LOs trained under standard parametrization (SP). Notably, when applied to large-width models, our best muLO, trained for 103 GPU hours, matches or exceeds the performance of VeLO, the largest publicly available learned optimizer, meta-trained with 4000 TPU months of computing.
Moreover, muLOs demonstrate better generalization than their SP counterparts to deeper networks and to much longer training horizons (25 times longer) than those seen during meta-training.
3.5. Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms
Reinforcement Learning from Human Feedback (RLHF) has been crucial to the recent success of Large Language Models (LLMs), however, it is often a complex and brittle process. In the classical RLHF framework, a reward model is first trained to represent human preferences, which is in turn used by an online reinforcement learning (RL) algorithm to optimize the LLM.
A prominent issue with such methods is reward over-optimization or reward hacking, where performance, as measured by the learned proxy reward model, increases, but true quality plateaus or even deteriorates. Direct Alignment Algorithms (DDAs) like Direct Preference Optimization have emerged as alternatives to the classical RLHF pipeline by circumventing the reward modeling phase.
However, although DAAs do not use a separate proxy reward model, they still commonly deteriorate from over-optimization. While the so-called reward hacking phenomenon is not well-defined for DAAs, we still uncover similar trends: at higher KL budgets, DAA algorithms exhibit similar degradation patterns to their classic RLHF counterparts.
In particular, we find that DAA methods deteriorate not only across a wide range of KL budgets but also often before even a single epoch of the dataset is completed. Through extensive empirical experimentation, this work formulates and formalizes the reward over-optimization or hacking problem for DAAs and explores its consequences across objectives, training regimes, and model scales.
4. LLM Alignment & RLHF
4.1. Show, Don’t Tell: Aligning Language Models with Demonstrated Feedback

Language models are aligned to emulate the collective voice of many, resulting in outputs that align with no one in particular. Steering LLMs away from generic output is possible through supervised finetuning or RLHF, but requires prohibitively large datasets for new ad-hoc tasks.
We argue that it is instead possible to align an LLM to a specific setting by leveraging a very small number (<10) of demonstrations as feedback. Our method, Demonstration ITerated Task Optimization (DITTO), directly aligns language model outputs to a user’s demonstrated behaviors.
Derived using ideas from online imitation learning, DITTO cheaply generates online comparison data by treating users’ demonstrations as preferred over output from the LLM and its intermediate checkpoints. We evaluate DITTO’s ability to learn fine-grained style and task alignment across domains such as news articles, emails, and blog posts.
Additionally, we conduct a user study soliciting a range of demonstrations from participants (N=16). Across our benchmarks and user study, we find that win rates for DITTO outperform few-shot prompting, supervised fine-tuning, and other self-play methods by an average of 19% points. DITTO offers a novel method for effective customization of LLMs by using demonstrations as feedback.
5. LLM Reasoning
5.1. Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
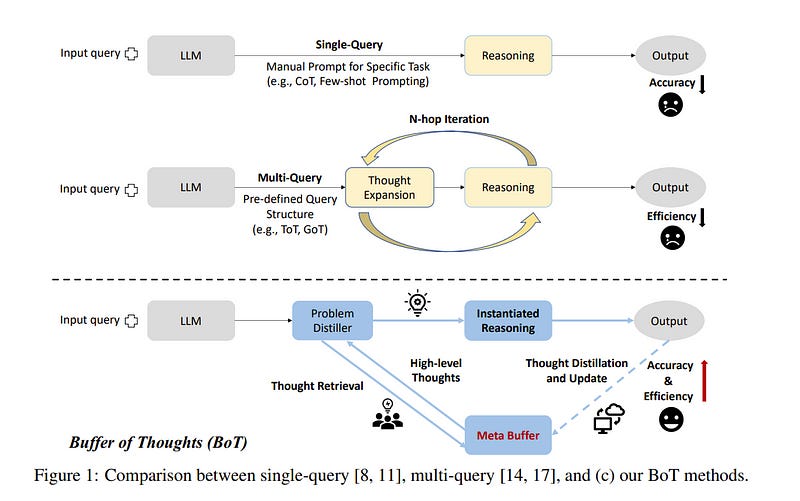
We introduce Buffer of Thoughts (BoT), a novel and versatile thought-augmented reasoning approach for enhancing the accuracy, efficiency, and robustness of large language models (LLMs).
Specifically, we propose a meta-buffer to store a series of informative high-level thoughts, namely thought-template, distilled from the problem-solving processes across various tasks. Then for each problem, we retrieve a relevant thought template and adaptively instantiate it with specific reasoning structures to conduct efficient reasoning.
To guarantee scalability and stability, we further propose a buffer manager to dynamically update the meta-buffer, thus enhancing the capacity of the meta-buffer as more tasks are solved.
We conduct extensive experiments on 10 challenging reasoning-intensive tasks, and achieve significant performance improvements over previous SOTA methods: 11% on Game of 24, 20% on Geometric Shapes, and 51% on Checkmate-in-One.
Further analysis demonstrates the superior generalization ability and model robustness of our BoT while requiring only 12% of the cost of multi-query prompting methods (e.g., tree/graph of thoughts) on average. Notably, we find that our Llama3–8B+BoT has the potential to surpass the Llama3–70B model.
6. Attention Models
6.1. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality

While Transformers have been the main architecture behind deep learning’s success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Transformers at small to medium scale.
These families of models are actually closely related and develop a rich framework of theoretical connections between SSMs and variants of attention, connected through various decompositions of a well-studied class of structured semiseparable matrices.
Our state space duality (SSD) framework allows us to design a new architecture (Mamba-2) whose core layer is a refinement of Mamba’s selective SSM that is 2–8X faster while continuing to be competitive with Transformers on language modeling.
6.2. Block Transformer: Global-to-Local Language Modeling for Fast Inference

This paper presents the Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention.
To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference.
We notice that these costs stem from applying self-attention in the global context, therefore we isolate the expensive bottlenecks of global modeling to lower layers and apply fast local modeling in upper layers.
To mitigate the remaining costs in the lower layers, we aggregate input tokens into fixed-size blocks and then apply self-attention at this coarse level. Context information is aggregated into a single embedding to enable upper layers to decode the next block of tokens, without global attention.
The upper layers can fully utilize the computing hardware to maximize inference throughput without global attention bottlenecks. By leveraging global and local modules, the Block Transformer architecture demonstrates 10–20x gains in inference throughput compared to vanilla transformers with equivalent perplexity.
Our work introduces a new approach to optimize language model inference through a novel application of global-to-local modeling.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
