


Top Important LLMs Papers for the Week from 01/07 to 07/07
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the First Week of July 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Fine-Tuning
LLM Quantization & Alignment
LLM Reasoning
LLM Safety & Alignment
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. LLM Progress & Benchmarking
1.1. RaTEScore: A Metric for Radiology Report Generation

This paper introduces a novel, entity-aware metric called Radiological Report (Text) Evaluation (RaTEScore) to assess the quality of medical reports generated by AI models.
RaTEScore emphasizes crucial medical entities such as diagnostic outcomes and anatomical details and is robust against complex medical synonyms and sensitive to negation expressions. Technically, we developed a comprehensive medical NER dataset, RaTE-NER, and trained an NER model specifically for this purpose.
This model enables the decomposition of complex radiological reports into constituent medical entities. The metric itself is derived by comparing the similarity of entity embeddings, obtained from a language model, based on their types and relevance to clinical significance.
Our evaluations demonstrate that RaTEScore aligns more closely with human preference than existing metrics, validated both on established public benchmarks and our newly proposed RaTE-Eval benchmark.
1.2. HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale

The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs.
While pioneering approaches utilize PubMed’s large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise.
To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an ‘unblinded’ capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples.
Our validation demonstrates that:
PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track.
Manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods.
Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
1.3. Agentless: Demystifying LLM-based Software Engineering Agents

Recent advancements in large language models (LLMs) have significantly advanced the automation of software development tasks, including code synthesis, program repair, and test generation.
More recently, researchers and industry practitioners have developed various autonomous LLM agents to perform end-to-end software development tasks.
These agents are equipped with the ability to use tools, run commands, observe feedback from the environment, and plan for future actions. However, the complexity of these agent-based approaches, together with the limited abilities of current LLMs, raises the following question: Do we really have to employ complex autonomous software agents?
To attempt to answer this question, we build Agentless — an agentless approach to automatically solve software development problems.
Compared to the verbose and complex setup of agent-based approaches, Agentless employs a simplistic two-phase process of localization followed by repair, without letting the LLM decide future actions or operate with complex tools.
Our results on the popular SWE-bench Lite benchmark show that surprisingly the simplistic Agentless is able to achieve both the highest performance (27.33%) and lowest cost (\$0.34) compared with all existing open-source software agents!
Furthermore, we manually classified the problems in SWE-bench Lite and found problems with exact ground truth patches or insufficient/misleading issue descriptions.
As such, we construct SWE-bench Lite-S by excluding such problematic issues to perform a more rigorous evaluation and comparison. Our work highlights the current overlooked potential of a simple, interpretable technique in autonomous software development.
We hope Agentless will help reset the baseline, starting point, and horizon for autonomous software agents, and inspire future work along this crucial direction.
1.4. Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems
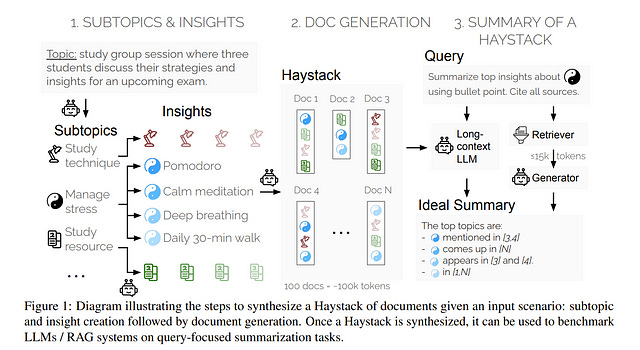
LLMs and RAG systems are now capable of handling millions of input tokens or more. However, evaluating the output quality of such systems on long-context tasks remains challenging, as tasks like Needle-in-a-Haystack lack complexity.
In this work, we argue that summarization can play a central role in such evaluation. We design a procedure to synthesize Haystacks of documents, ensuring that specific insights repeat across documents.
The “Summary of a Haystack” (SummHay) task then requires a system to process the Haystack and generate, given a query, a summary that identifies the relevant insights and precisely cites the source documents.
Since we have precise knowledge of what insights should appear in a haystack summary and what documents should be cited, we implement a highly reproducible automatic evaluation that can score summaries on two aspects — Coverage and Citation.
We generate Haystacks in two domains (conversation, and news), and perform a large-scale evaluation of 10 LLMs and corresponding 50 RAG systems.
Our findings indicate that SummHay is an open challenge for current systems, as even systems provided with an Oracle signal of document relevance lag our estimate of human performance (56\%) by 10+ points on a Joint Score. Without a retriever, long-context LLMs like GPT-4o and Claude 3 Opus score below 20% on SummHay.
We show that SummHay can also be used to study enterprise RAG systems and position bias in long-context models. We hope future systems can equal and surpass human performance on SummHay.
1.5. To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models

Large Language Models (LLMs) trained on extensive corpora inevitably retain sensitive data, such as personal privacy information and copyrighted material.
Recent advancements in knowledge unlearning involve updating LLM parameters to erase specific knowledge. However, current unlearning paradigms are mired in vague forgetting boundaries, often erasing knowledge indiscriminately.
In this work, we introduce KnowUnDo, a benchmark containing copyrighted content and user privacy domains to evaluate if the unlearning process inadvertently erases essential knowledge. Our findings indicate that existing unlearning methods often suffer from excessive unlearning.
To address this, we propose a simple yet effective method, MemFlex, which utilizes gradient information to precisely target and unlearn sensitive parameters. Experimental results show that MemFlex is superior to existing methods in both precise knowledge unlearning and general knowledge retaining of LLMs.
1.6. InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output

We present InternLM-XComposer-2.5 (IXC-2.5), a versatile large-vision language model that supports long-contextual input and output. IXC-2.5 excels in various text-image comprehension and composition applications, achieving GPT-4V level capabilities with merely a 7B LLM backend.
Trained with 24K interleaved image-text contexts, it can seamlessly extend to 96K long contexts via RoPE extrapolation. This long-context capability allows IXC-2.5 to excel in tasks requiring extensive input and output contexts.
Compared to its previous 2.0 version, InternLM-XComposer-2.5 features three major upgrades in vision-language comprehension:
Ultra-High Resolution Understanding
Fine-Grained Video Understanding
Multi-Turn Multi-Image Dialogue.
In addition to comprehension, IXC-2.5 extends to two compelling applications using extra LoRA parameters for text-image composition:
Crafting Webpages
Composing High-Quality Text-Image Articles.
IXC-2.5 has been evaluated on 28 benchmarks, outperforming existing open-source state-of-the-art models on 16 benchmarks. It also surpasses or competes closely with GPT-4V and Gemini Pro on 16 key tasks.
2. LLM Training, Evaluation & Inference
2.1. MMEvalPro: Calibrating Multimodal Benchmarks Towards Trustworthy and Efficient Evaluation

Large Multimodal Models (LMMs) exhibit impressive cross-modal understanding and reasoning abilities, often assessed through multiple-choice questions (MCQs) that include an image, a question, and several options.
However, many benchmarks used for such evaluations suffer from systematic biases. Remarkably, Large Language Models (LLMs) without any visual perception capabilities achieve non-trivial performance, undermining the credibility of these evaluations.
To address this issue while maintaining the efficiency of MCQ evaluations, we propose MMEvalPro, a benchmark designed to avoid Type-I errors through a trilogy evaluation pipeline and more rigorous metrics.
For each original question from existing benchmarks, human annotators augment it by creating one perception question and one knowledge anchor question through a meticulous annotation process.
MMEvalPro comprises 2,138 question triplets, totaling 6,414 distinct questions. Two-thirds of these questions are manually labeled by human experts, while the rest are sourced from existing benchmarks (MMMU, ScienceQA, and MathVista).
Compared with the existing benchmarks, our experiments with the latest LLMs and LMMs demonstrate that MMEvalPro is more challenging (the best LMM lags behind human performance by 31.73%, compared to an average gap of 8.03% in previous benchmarks) and more trustworthy (the best LLM trails the best LMM by 23.09%, whereas the gap for previous benchmarks is just 14.64%).
Our in-depth analysis explains the reason for the large performance gap and justifies the trustworthiness of evaluation, underscoring its significant potential for advancing future research.
2.2. MIRAI: Evaluating LLM Agents for Event Forecasting

Recent advancements in Large Language Models (LLMs) have empowered LLM agents to autonomously collect world information, over which to conduct reasoning to solve complex problems.
Given this capability, increasing interest has been put into employing LLM agents for predicting international events, which can influence decision-making and shape policy development on an international scale.
Despite such growing interest, there is a lack of a rigorous benchmark of LLM agents’ forecasting capability and reliability. To address this gap, we introduce MIRAI, a novel benchmark designed to systematically evaluate LLM agents as temporal forecasters in the context of international events. Our benchmark features an agentic environment with tools for accessing an extensive database of historical, structured events and textual news articles.
We refine the GDELT event database with careful cleaning and parsing to curate a series of relational prediction tasks with varying forecasting horizons, assessing LLM agents’ abilities from short-term to long-term forecasting. We further implement APIs to enable LLM agents to utilize different tools via a code-based interface.
In summary, MIRAI comprehensively evaluates the agents’ capabilities in three dimensions:
Autonomously source and integrate critical information from large global databases.
Write codes using domain-specific APIs and libraries for tool use
Jointly reason over historical knowledge from diverse formats and time to accurately predict future events.
Through comprehensive benchmarking, we aim to establish a reliable framework for assessing the capabilities of LLM agents in forecasting international events, thereby contributing to the development of more accurate and trustworthy models for international relations analysis.
3. LLM Fine-Tuning
3.1. Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
Parameter-efficient fine-tuning (PEFT) is crucial for customizing Large Language Models (LLMs) with constrained resources. Although there have been various PEFT methods for dense-architecture LLMs, PEFT for sparse-architecture LLMs is still underexplored.
In this work, we study the PEFT method for LLMs with the Mixture-of-Experts (MoE) architecture and the contents of this work are mainly threefold:
We investigated the dispersion degree of the activated experts in customized tasks and found that the routing distribution for a specific task tends to be highly concentrated, while the distribution of activated experts varies significantly across different tasks.
We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules; experimental results demonstrate that our method not only improves the tuning efficiency but also matches or even surpasses the performance of full-parameter fine-tuning.
We further analyze the impact of the MoE architecture on expert-specialized fine-tuning. We find that MoE models with finer-grained experts are more advantageous in selecting the combination of experts that are most relevant to downstream tasks, thereby enhancing both the training efficiency and effectiveness.
3.2. Show Less, Instruct More: Enriching Prompts with Definitions and Guidelines for Zero-Shot NER

Recently, several specialized instruction-tuned Large Language Models (LLMs) for Named Entity Recognition (NER) have emerged. Compared to traditional NER approaches, these models have strong generalization capabilities.
Existing LLMs mainly focus on zero-shot NER in out-of-domain distributions, being fine-tuned on an extensive number of entity classes that often highly or completely overlap with test sets.
In this work instead, we propose SLIMER, an approach designed to tackle never-seen-before-named entity tags by instructing the model on fewer examples, and by leveraging a prompt enriched with definitions and guidelines.
Experiments demonstrate that definitions and guidelines yield better performance, and faster and more robust learning, particularly when labeling unseen Named Entities.
Furthermore, SLIMER performs comparably to state-of-the-art approaches in out-of-domain zero-shot NER, while being trained on a reduced tag set.
4. LLM Quantization & Alignment
4.1. Direct Preference Knowledge Distillation for Large Language Models
In the field of large language models (LLMs), Knowledge Distillation (KD) is a critical technique for transferring capabilities from teacher models to student models.
However, existing KD methods face limitations and challenges in the distillation of LLMs, including efficiency and insufficient measurement capabilities of traditional KL divergence.
It is shown that LLMs can serve as an implicit reward function, which we define as a supplement to KL divergence. In this work, we propose Direct Preference Knowledge Distillation (DPKD) for LLMs. DPKD utilizes distribution divergence to represent the preference loss and implicit reward function.
We re-formulate KD of LLMs into two stages: first optimizing an objective consisting of implicit reward and reverse KL divergence and then improving the preference probability of teacher outputs over student outputs.
We conducted experiments and analysis on various datasets with LLM parameters ranging from 120M to 13B and demonstrated the broad applicability and effectiveness of our DPKD approach.
Meanwhile, we prove the value and effectiveness of the introduced implicit reward and output preference in KD through experiments and theoretical analysis. The DPKD method outperforms the baseline method in both output response precision and exact match percentage.
5. LLM Reasoning
5.1. We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?

Visual mathematical reasoning, as a fundamental visual reasoning ability, has received widespread attention from the Large Multimodal Models (LMMs) community.
Existing benchmarks, such as MathVista and MathVerse, focus more on result-oriented performance but neglect the underlying principles in knowledge acquisition and generalization.
Inspired by human-like mathematical reasoning, we introduce WE-MATH, the first benchmark specifically designed to explore problem-solving principles beyond end-to-end performance.
We meticulously collect and categorize 6.5K visual math problems, spanning 67 hierarchical knowledge concepts and five layers of knowledge granularity.
We decompose composite problems into sub-problems according to the required knowledge concepts and introduce a novel four-dimensional metric, namely Insufficient Knowledge (IK), Inadequate Generalization (IG), Complete Mastery (CM), and Rote Memorization (RM), to hierarchically assess inherent issues in LMMs’ reasoning process.
With WE-MATH, we conduct a thorough evaluation of existing LMMs in visual mathematical reasoning and reveal a negative correlation between solving steps and problem-specific performance. We confirm the IK issue of LMMs can be effectively improved via knowledge augmentation strategies.
More notably, the primary challenge of GPT-4o has significantly transitioned from IK to IG, establishing it as the first LMM advancing toward the knowledge generalization stage.
In contrast, other LMMs exhibit a marked inclination towards Rote Memorization — they correctly solve composite problems involving multiple knowledge concepts yet fail to answer sub-problems. We anticipate that WE-MATH will open new pathways for advancements in visual mathematical reasoning for LMMs.
5.2. Chain-of-Knowledge: Integrating Knowledge Reasoning into Large Language Models by Learning from Knowledge Graphs
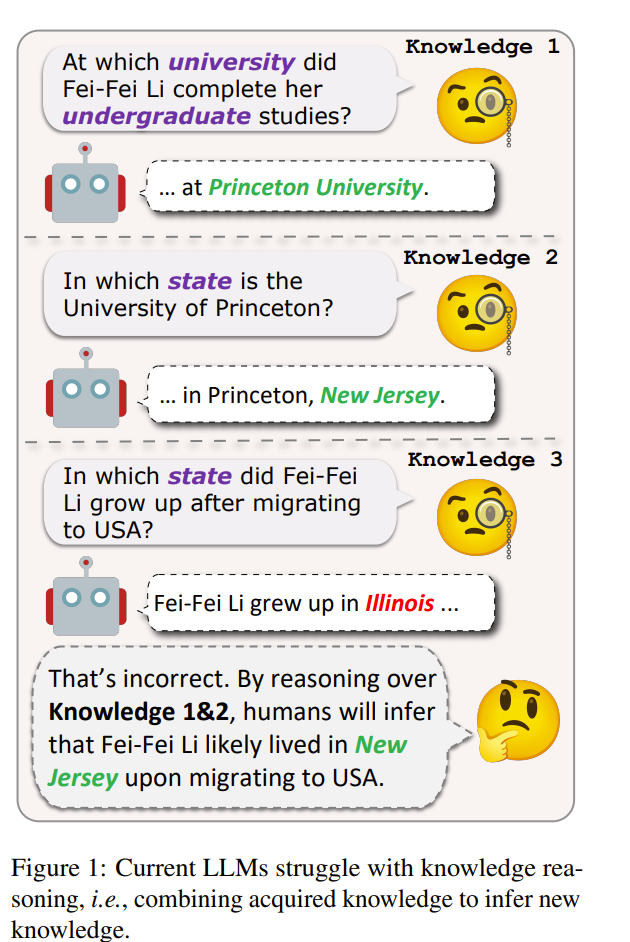
Large Language Models (LLMs) have exhibited impressive proficiency in various natural language processing (NLP) tasks, which involve increasingly complex reasoning.
Knowledge reasoning, a primary type of reasoning, aims at deriving new knowledge from existing one. While it has been widely studied in the context of knowledge graphs (KGs), knowledge reasoning in LLMs remains underexplored.
In this paper, we introduce Chain-of-Knowledge, a comprehensive framework for knowledge reasoning, including methodologies for both dataset construction and model learning. For dataset construction, we create KnowReason via rule mining on KGs.
For model learning, we observe rule overfitting induced by naive training. Hence, we enhance CoK with a trial-and-error mechanism that simulates the human process of internal knowledge exploration.
We conduct extensive experiments with KnowReason. Our results show the effectiveness of CoK in refining LLMs in not only knowledge reasoning but also general reasoning benchmarks.
5.3. Step-Controlled DPO: Leveraging Stepwise Error for Enhanced Mathematical Reasoning

Direct Preference Optimization (DPO) has proven effective at improving the performance of large language models (LLMs) on downstream tasks such as reasoning and alignment.
In this work, we propose Step-Controlled DPO (SCDPO), a method for automatically providing stepwise error supervision by creating negative samples of mathematical reasoning rationales that start making errors at a specified step. By applying these samples in DPO training,
SCDPO can better align the model to understand reasoning errors and output accurate reasoning steps. We apply SCDPO to both code-integrated and chain-of-thought solutions, empirically showing that it consistently improves the performance compared to naive DPO on three different SFT models, including one existing SFT model and two models we fine-tuned.
Qualitative analysis of the credit assignment of SCDPO and DPO demonstrates the effectiveness of SCDPO at identifying errors in mathematical solutions.
We then apply SCDPO to an InternLM2–20B model, resulting in a 20B model that achieves high scores of 88.5% on GSM8K and 58.1% on MATH, rivaling all other open-source LLMs, showing the great potential of our method.
6. LLM Safety & Alignment
6.1. Understanding Alignment in Multimodal LLMs: A Comprehensive Study

Preference alignment has become a crucial component in enhancing the performance of Large Language Models (LLMs), yet its impact in Multimodal Large Language Models (MLLMs) remains comparatively underexplored.
Similar to language models, MLLMs for image understanding tasks encounter challenges like hallucination. In MLLMs, hallucination can occur not only by stating incorrect facts but also by producing responses that are inconsistent with the image content.
A primary objective of alignment for MLLMs is to encourage these models to align responses more closely with image information. Recently, multiple works have introduced preference datasets for MLLMs and examined different alignment methods, including Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO).
However, due to variations in datasets, base model types, and alignment methods, it remains unclear which specific elements contribute most significantly to the reported improvements in these works. In this paper, we independently analyze each aspect of preference alignment in MLLMs.
We start by categorizing the alignment algorithms into two groups, offline (such as DPO), and online (such as online-DPO), and show that combining offline and online methods can improve the performance of the model in certain scenarios.
We review a variety of published multimodal preference datasets and discuss how the details of their construction impact model performance. Based on these insights, we introduce a novel way of creating multimodal preference data called Bias-Driven Hallucination Sampling (BDHS) that needs neither additional annotation nor external models and shows that it can achieve competitive performance to previously published alignment work for multimodal models across a range of benchmarks.
6.2. ProgressGym: Alignment with a Millennium of Moral Progress
Frontier AI systems, including large language models (LLMs), hold increasing influence over the epistemology of human users. Such influence can reinforce prevailing societal values, potentially contributing to the lock-in of misguided moral beliefs and, consequently, the perpetuation of problematic moral practices on a broad scale.
We introduce progress alignment as a technical solution to mitigate this imminent risk. Progress alignment algorithms learn to emulate the mechanics of human moral progress, thereby addressing the susceptibility of existing alignment methods to contemporary moral blindspots.
To empower research in progress alignment, we introduce ProgressGym, an experimental framework allowing the learning of moral progress mechanics from history, to facilitate future progress in real-world moral decisions.
Leveraging 9 centuries of historical text and 18 historical LLMs, ProgressGym enables the codification of real-world progress alignment challenges into concrete benchmarks. Specifically, we introduce three core challenges: tracking evolving values (PG-Follow), preemptively anticipating moral progress (PG-Predict), and regulating the feedback loop between human and AI value shifts (PG-Coevolve).
Alignment methods without a temporal dimension are inapplicable to these tasks. In response, we present lifelong and extrapolative algorithms as baseline methods of progress alignment and build an open leaderboard soliciting novel algorithms and challenges.
6.3. A False Sense of Safety: Unsafe Information Leakage in ‘Safe’ AI Responses

Large Language Models (LLMs) are vulnerable to jailbreaksx2013methods to elicit harmful or generally impermissible outputs. Safety measures are developed and assessed on their effectiveness at defending against jailbreak attacks, indicating a belief that safety is equivalent to robustness.
We assert that current defense mechanisms, such as output filters and alignment fine-tuning, are, and will remain, fundamentally insufficient for ensuring model safety.
These defenses fail to address risks arising from dual-intent queries and the ability to composite innocuous outputs to achieve harmful goals. To address this critical gap, we introduce an information-theoretic threat model called inferential adversaries which exploit impermissible information leakage from model outputs to achieve malicious goals.
We distinguish these from commonly studied security adversaries who only seek to force victim models to generate specific impermissible outputs. We demonstrate the feasibility of automating inferential adversaries through question decomposition and response aggregation.
To provide safety guarantees, we define an information censorship criterion for censorship mechanisms, bounding the leakage of impermissible information.
We propose a defense mechanism that ensures this bound and reveals an intrinsic safety-utility trade-off. Our work provides the first theoretically grounded understanding of the requirements for releasing safe LLMs and the utility costs involved.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
