


Top Important LLMs Papers for the Week from 10/06 to 16/06
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Second Week of June 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization & Alignment
LLM Prompt Engineering & Fine-Tuning
LLM Reasoning
Attention Models
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. LLM Progress & Benchmarking
1.1. Mixture-of-Agents Enhances Large Language Model Capabilities

Recent advances in large language models (LLMs) demonstrate substantial capabilities in natural language understanding and generation tasks. With the growing number of LLMs, how to harness the collective expertise of multiple LLMs is an exciting open direction.
Toward this goal, we propose a new approach that leverages the collective strengths of multiple LLMs through a Mixture-of-Agents (MoA) methodology. In our approach, we construct a layered MoA architecture wherein each layer comprises multiple LLM agents.
Each agent takes all the outputs from agents in the previous layer as auxiliary information in generating its response. MoA models achieve state-of-art performance on AlpacaEval 2.0, MT-Bench, and FLASK, surpassing GPT-4 Omni.
For example, our MoA using only open-source LLMs is the leader of AlpacaEval 2.0 by a substantial gap, achieving a score of 65.1% compared to 57.5% by GPT-4 Omni.
1.2. WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild

We introduce WildBench, an automated evaluation framework designed to benchmark large language models (LLMs) using challenging, real-world user queries. WildBench consists of 1,024 tasks carefully selected from over one million human-chatbot conversation logs.
For automated evaluation with WildBench, we have developed two metrics, WB-Reward and WB-Score, which are computable using advanced LLMs such as GPT-4-turbo.
WildBench evaluation uses task-specific checklists to evaluate model outputs systematically and provides structured explanations that justify the scores and comparisons, resulting in more reliable and interpretable automatic judgments.
WB-Reward employs fine-grained pairwise comparisons between model responses, generating five potential outcomes: much better, slightly better, slightly worse, much worse, or a tie. Unlike previous evaluations that employed a single baseline model, we selected three baseline models at varying performance levels to ensure a comprehensive pairwise evaluation.
Additionally, we propose a simple method to mitigate length bias, by converting outcomes of ``slightly better/worse’’ to ``tie’’ if the winner response exceeds the loser one by more than K characters. WB-Score evaluates the quality of model outputs individually, making it a fast and cost-efficient evaluation metric.
WildBench results demonstrate a strong correlation with the human-voted Elo ratings from Chatbot Arena on hard tasks. Specifically, WB-Reward achieves a Pearson correlation of 0.98 with top-ranking models. Additionally, WB-Score reaches 0.95, surpassing both ArenaHard’s 0.91 and AlpacaEval2.0’s 0.89 for length-controlled win rates, as well as 0.87 for regular win rates.
1.3. NATURAL PLAN: Benchmarking LLMs on Natural Language Planning

We introduce NATURAL PLAN, a realistic planning benchmark in a natural language containing 3 key tasks: Trip Planning, Meeting Planning, and Calendar Scheduling.
We focus our evaluation on the planning capabilities of LLMs with full information on the task, by providing outputs from tools such as Google Flights, Google Maps, and Google Calendar as contexts for the models. This eliminates the need for a tool-use environment for evaluating LLMs on Planning.
We observe that NATURAL PLAN is a challenging benchmark for state-of-the-art models. For example, in Trip Planning, GPT-4 and Gemini 1.5 Pro could only achieve 31.1% and 34.8% solve rates respectively.
We find that model performance drops drastically as the complexity of the problem increases: all models perform below 5% when there are 10 cities, highlighting a significant gap in planning in natural language for SoTA LLMs.
We also conduct extensive ablation studies on NATURAL PLAN to further shed light on the (in)effectiveness of approaches such as self-correction, few-shot generalization, and in-context planning with long-contexts on improving LLM planning.
1.4. Tx-LLM: A Large Language Model for Therapeutics

Developing therapeutics is a lengthy and expensive process that requires the satisfaction of many different criteria, and AI models capable of expediting the process would be invaluable.
However, the majority of current AI approaches address only a narrowly defined set of tasks, often circumscribed within a particular domain. To bridge this gap, we introduce Tx-LLM, a generalist large language model (LLM) fine-tuned from PaLM-2 which encodes knowledge about diverse therapeutic modalities.
Tx-LLM is trained using a collection of 709 datasets that target 66 tasks spanning various stages of the drug discovery pipeline. Using a single set of weights, Tx-LLM simultaneously processes a wide variety of chemical or biological entities(small molecules, proteins, nucleic acids, cell lines, diseases) interleaved with free-text, allowing it to predict a broad range of associated properties, achieving competitive with state-of-the-art (SOTA) performance on 43 out of 66 tasks and exceeding SOTA on 22.
Among these, Tx-LLM is particularly powerful and exceeds best-in-class performance on average for tasks combining molecular SMILES representations with text such as cell line names or disease names, likely due to context learned during pretraining.
We observe evidence of positive transfer between tasks with diverse drug types (e.g., tasks involving small molecules and tasks involving proteins), and we study the impact of model size, domain finetuning, and prompting strategies on performance.
We believe Tx-LLM represents an important step towards LLMs encoding biochemical knowledge and could have a future role as an end-to-end tool across the drug discovery development pipeline.
1.5. Towards a Personal Health Large Language Model

In health, most large language model (LLM) research has focused on clinical tasks. However, mobile and wearable devices, which are rarely integrated into such tasks, provide rich, longitudinal data for personal health monitoring.
Here we present the Personal Health Large Language Model (PH-LLM), fine-tuned from Gemini for understanding and reasoning over numerical time-series personal health data. We created and curated three datasets that tested:
The production of personalized insights and recommendations from sleep patterns, physical activity, and physiological responses.
Expert domain knowledge
Prediction of self-reported sleep outcomes.
For the first task, we designed 857 case studies in collaboration with domain experts to assess real-world scenarios in sleep and fitness. Through comprehensive evaluation of domain-specific rubrics, we observed that Gemini Ultra 1.0 and PH-LLM are not statistically different from expert performance in fitness and, while experts remain superior for sleep, fine-tuning PH-LLM provided significant improvements in using relevant domain knowledge and personalizing information for sleep insights.
We evaluated PH-LLM domain knowledge using multiple-choice sleep medicine and fitness examinations. PH-LLM achieved 79% on sleep and 88% on fitness, exceeding average scores from a sample of human experts.
Finally, we trained PH-LLM to predict self-reported sleep quality outcomes from textual and multimodal encoding representations of wearable data and demonstrated that multimodal encoding is required to match the performance of specialized discriminative models.
Although further development and evaluation are necessary for the safety-critical personal health domain, these results demonstrate both the broad knowledge and capabilities of Gemini models and the benefit of contextualizing physiological data for personal health applications as done with PH-LLM.
1.6. Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B

This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex mathematical reasoning tasks.
Addressing the challenges of accuracy and reliability in LLMs, particularly in strategic and mathematical reasoning, MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs.
The algorithm constructs a Monte Carlo search tree through iterative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance.
Extensive experiments demonstrate MCTSr’s efficacy in solving Olympiad-level mathematical problems, significantly improving success rates across multiple datasets, including GSM8K, GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and OlympiadBench.
The study advances the application of LLMs in complex reasoning tasks and sets a foundation for future AI integration, enhancing decision-making accuracy and reliability in LLM-driven applications.
1.7. MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering

Large language models (LLM) have achieved impressive performance on medical question-answering benchmarks. However, high benchmark accuracy does not imply that the performance generalizes to real-world clinical settings.
Medical question-answering benchmarks rely on assumptions consistent with quantifying LLM performance but that may not hold in the open world of the clinic. Yet LLMs learn broad knowledge that can help the LLM generalize to practical conditions regardless of unrealistic assumptions in celebrated benchmarks.
We seek to quantify how well LLM medical question-answering benchmark performance generalizes when benchmark assumptions are violated. Specifically, we present an adversarial method that we call MedFuzz (for medical fuzzing).
MedFuzz attempts to modify benchmark questions in ways aimed at confounding the LLM. We demonstrate the approach by targeting strong assumptions about patient characteristics presented in the MedQA benchmark. Successful “attacks” modify a benchmark item in ways that would be unlikely to fool a medical expert but nonetheless “trick” the LLM into changing from a correct to an incorrect answer.
Further, we present a permutation test technique that can ensure a successful attack is statistically significant. We show how to use performance on a “MedFuzzed” benchmark, as well as individual successful attacks. The methods show promise in providing insights into the ability of an LLM to operate robustly in more realistic settings.
1.8. mOSCAR: A Large-scale Multilingual and Multimodal Document-level Corpus

Multimodal Large Language Models (mLLMs) are trained on a large amount of text-image data. While most mLLMs are trained on caption-like data only, Alayrac et al. [2022] showed that additionally training them on interleaved sequences of text and images can lead to the emergence of in-context learning capabilities.
However, the dataset they used, M3W, is not public and is only in English. There have been attempts to reproduce their results but the released datasets are English-only. In contrast, current multilingual and multimodal datasets are either composed of caption-like only or medium-scale or fully private data.
This limits mLLM research for the 7,000 other languages spoken in the world. We therefore introduce mOSCAR, to the best of our knowledge the first large-scale multilingual and multimodal document corpus crawled from the web.
It covers 163 languages, 315M documents, 214B tokens, and 1.2B images. We carefully conduct a set of filtering and evaluation steps to make sure mOSCAR is sufficiently safe, diverse, and of good quality.
We additionally train two types of multilingual models to prove the benefits of mOSCAR: (1) a model trained on a subset of mOSCAR and captioning data and (2) a model trained on captioning data only.
The model additionally trained on mOSCAR shows a strong boost in few-shot learning performance across various multilingual image-text tasks and benchmarks, confirming previous findings for English-only mLLMs.
1.9. Are We Done with MMLU?

Maybe not. We identify and analyze errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs.
For example, we find that 57% of the analyzed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects.
Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU’s error-ridden questions to enhance its future utility and reliability as a benchmark.
1.10. CS-Bench: A Comprehensive Benchmark for Large Language Models Towards Computer Science Mastery

Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society.
However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field.
To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning.
Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning.
Further cross-capability experiments show a high correlation between LLMs’ capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields.
Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs’ diverse reasoning capabilities.
1.11. Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling

Efficiently modeling sequences with infinite context length has been a long-standing problem. Past works suffer from either the quadratic computation complexity or the limited extrapolation ability on length generalization.
In this work, we present Samba, a simple hybrid architecture that layer-wise combines Mamba, a selective State Space Model (SSM), with Sliding Window Attention (SWA). Samba selectively compresses a given sequence into recurrent hidden states while still maintaining the ability to precisely recall memories with the attention mechanism.
We scale Samba up to 3.8B parameters with 3.2T training tokens and show that Samba substantially outperforms the state-of-the-art models based on pure attention or SSMs on a wide range of benchmarks.
When trained on 4K length sequences, Samba can be efficiently extrapolated to 256K context length with perfect memory recall and show improved token predictions up to 1M context length.
As a linear-time sequence model, Samba enjoys a 3.73x higher throughput compared to Transformers with grouped-query attention when processing user prompts of 128K length, and 3.64x speedup when generating 64K tokens with unlimited streaming.
1.12. Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?

Predictable behavior from scaling advanced AI systems is an extremely desirable property. Although well-established literature exists on how pretraining performance scales, the literature on how particular downstream capabilities scale is significantly muddier.
In this work, we take a step back and ask: why has predicting specific downstream capabilities with scale remained elusive? While many factors are certainly responsible, we identify a new factor that makes modeling scaling behavior on widely used multiple-choice question-answering benchmarks challenging.
Using five model families and twelve well-established multiple-choice benchmarks, we show that downstream performance is computed from negative log likelihoods via a sequence of transformations that progressively degrade the statistical relationship between performance and scale.
We then reveal the mechanism causing this degradation: downstream metrics require comparing the correct choice against a small number of specific incorrect choices, meaning accurately predicting downstream capabilities requires predicting not just how probability mass concentrates on the correct choice with scale, but also how probability mass fluctuates on specific incorrect choices with scale.
We empirically study how probability mass on the correct choice co-varies with probability mass on incorrect choices with increasing compute, suggesting that scaling laws for incorrect choices might be achievable.
Our work also explains why pretraining scaling laws are commonly regarded as more predictable than downstream capabilities and contribute towards establishing scaling-predictable evaluations of frontier AI models.
1.13. Beyond LLaVA-HD: Diving into High-Resolution Large Multimodal Models

Seeing clearly with high resolution is a foundation of Large Multimodal Models (LMMs), which have been proven to be vital for visual perception and reasoning.
Existing works usually employ a straightforward resolution upscaling method, where the image consists of global and local branches, with the latter being the sliced image patches but resized to the same resolution as the former.
This means that higher resolution requires more local patches, resulting in exorbitant computational expenses, and meanwhile, the dominance of local image tokens may diminish the global context.
In this paper, we dive into the problems and propose a new framework as well as an elaborate optimization strategy. Specifically, we extract contextual information from the global view using a mixture of adapters, based on the observation that different adapters excel at different tasks.
About local patches, learnable query embeddings are introduced to reduce image tokens, the most important tokens accounting for the user question will be further selected by a similarity-based selector. Our empirical results demonstrate a `less is more’ pattern, where utilizing fewer but more informative local image tokens leads to improved performance.
Besides, a significant challenge lies in the training strategy, as simultaneous end-to-end training of the global mining block and local compression block does not yield optimal results.
We thus advocate for an alternating training way, ensuring balanced learning between global and local aspects. Finally, we also introduce a challenging dataset with high requirements for image detail, enhancing the training of the local compression layer.
The proposed method termed LMM with Sophisticated Tasks, Local image compression, and Mixture of Global Experts (SliME), achieves leading performance across various benchmarks with only 2 million training data.
2. LLM Training, Evaluation & Inference
2.1. GenAI Arena: An Open Evaluation Platform for Generative Models

Generative AI has made remarkable strides to revolutionize fields such as image and video generation. These advancements are driven by innovative algorithms, architecture, and data.
However, the rapid proliferation of generative models has highlighted a critical gap: the absence of trustworthy evaluation metrics. Current automatic assessments such as FID, CLIP, FVD, etc often fail to capture the nuanced quality and user satisfaction associated with generative outputs.
This paper proposes an open platform GenAI-Arena to evaluate different image and video generative models, where users can actively participate in evaluating these models. By leveraging collective user feedback and votes, GenAI-Arena aims to provide a more democratic and accurate measure of model performance.
It covers three arenas text-to-image generation, text-to-video generation, and image editing respectively. Currently, we cover a total of 27 open-source generative models. GenAI-Arena has been operating for four months, amassing over 6000 votes from the community. We describe our platform, analyze the data, and explain the statistical methods for ranking the models.
To further promote the research in building model-based evaluation metrics, we release a cleaned version of our preference data for the three tasks, namely GenAI-Bench. We prompt the existing multi-modal models like Gemini, and GPT-4o to mimic human voting. We compute the correlation between model voting with human voting to understand their judging abilities.
Our results show existing multimodal models are still lagging in assessing the generated visual content, even the best model GPT-4o only achieves a Pearson correlation of 0.22 in the quality subscore and behaves like random guessing in others.
2.2. CRAG — Comprehensive RAG Benchmark

Retrieval-augmented generation (RAG) has recently emerged as a promising solution to alleviate the Large Language Model (LLM) deficiency in lack of knowledge.
Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question-answering benchmark of 4,409 question-answer pairs, and mock APIs to simulate web and Knowledge Graph (KG) search.
CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds.
Our evaluation of this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve <=34% accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% of questions without any hallucination.
CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions.
The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracting thousands of participants and submissions within the first 50 days of the competition. We commit to maintaining CRAG to serve research communities in advancing RAG solutions and general QA solutions.
2.3. McEval: Massively Multilingual Code Evaluation

Code large language models (LLMs) have shown remarkable advances in code understanding, completion, and generation tasks. Programming benchmarks, comprised of a selection of code challenges and corresponding test cases, serve as a standard to evaluate the capability of different LLMs in such tasks.
However, most existing benchmarks primarily focus on Python and are still restricted to a limited number of languages, where other languages are translated from the Python samples (e.g. MultiPL-E) degrading the data diversity.
To further facilitate the research of code LLMs, we propose a massively multilingual code benchmark covering 40 programming languages (McEval) with 16K test samples, which substantially pushes the limits of code LLMs in multilingual scenarios.
The benchmark contains challenging code completion, understanding, and generation evaluation tasks with finely curated massively multilingual instruction corpora McEval-Instruct. In addition, we introduce an effective multilingual coder mCoder trained on McEval-Instruct to support multilingual programming language generation.
Extensive experimental results on McEval show that there is still a difficult journey between open-source models and closed-source LLMs (e.g. GPT-series models) in numerous languages.
2.4. Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models

In this technical report, we introduce the training methodologies implemented in the development of Skywork-MoE, a high-performance mixture-of-experts (MoE) large language model (LLM) with 146 billion parameters and 16 experts.
It is initialized from the pre-existing dense checkpoints of our Skywork-13B model. We explore the comparative effectiveness of upcycling versus training from scratch initializations. Our findings suggest that the choice between these two approaches should consider both the performance of the existing dense checkpoints and the MoE training budget.
We highlight two innovative techniques: gating logit normalization, which improves export diversification, and adaptive auxiliary loss coefficients, allowing for layer-specific adjustment of auxiliary loss coefficients. Our experimental results validate the effectiveness of these methods.
Leveraging these techniques and insights, we trained our upcycled Skywork-MoE on a condensed subset of our SkyPile corpus. The evaluation results demonstrate that our model delivers strong performance across a wide range of benchmarks.
2.5. Large Language Model Confidence Estimation via Black-Box Access
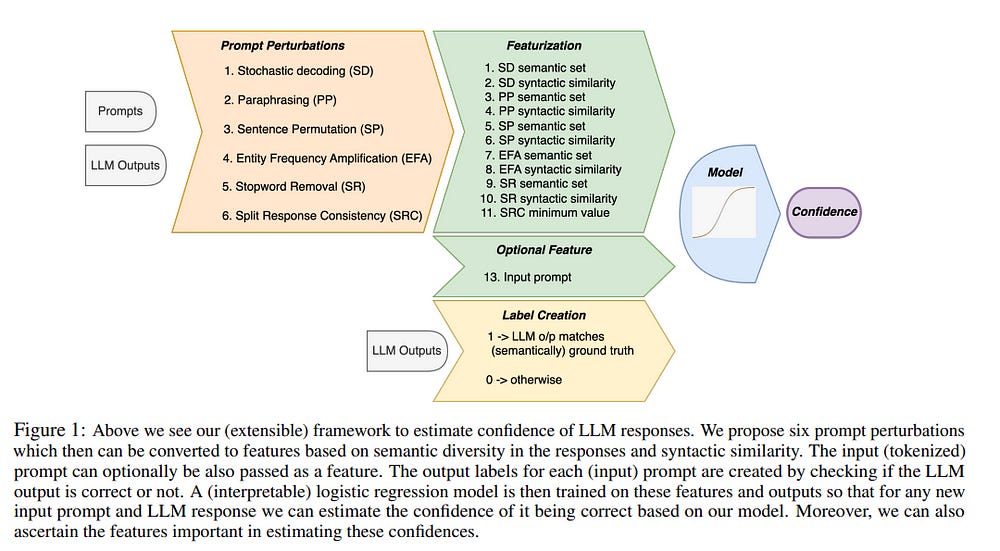
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them.
We propose a simple and extensible framework where we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating the confidence of flan-ul2, llama-13b, and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA, and Natural Questions by even over 10% (on AUROC) in some cases.
Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
2.6. PowerInfer-2: Fast Large Language Model Inference on a Smartphone

This paper introduces PowerInfer-2, a framework designed for high-speed inference of Large Language Models (LLMs) on smartphones, particularly effective for models whose sizes exceed the device’s memory capacity.
The key insight of PowerInfer-2 is to utilize the heterogeneous computation, memory, and I/O resources in smartphones by decomposing traditional matrix computations into fine-grained neuron cluster computations.
Specifically, PowerInfer-2 features a polymorphic neuron engine that adapts computational strategies for various stages of LLM inference. Additionally, it introduces segmented neuron caching and fine-grained neuron-cluster-level pipelining, which effectively minimize and conceal the overhead caused by I/O operations.
The implementation and evaluation of PowerInfer-2 demonstrate its capability to support a wide array of LLM models on two smartphones, achieving up to a 29.2x speed increase compared with state-of-the-art frameworks.
Notably, PowerInfer-2 is the first system to serve the TurboSparse-Mixtral-47B model with a generation rate of 11.68 tokens per second on a smartphone. For models that fit entirely within the memory, PowerInfer-2 can achieve approximately a 40% reduction in memory usage while maintaining inference speeds comparable to llama.cpp and MLC-LLM.
2.7. Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach

The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model.
Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues.
Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources.
Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestion can greatly increase the waiting time for GPUs.
To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are twofold. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction.
By leveraging this feature, C4 can rapidly identify faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection.
Second, the predictable communication model of collective communication, involving a few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion.
C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.
3. LLM Quantization & Alignment
3.1. Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing

High-quality instruction data is critical for aligning large language models (LLMs). Although some models, such as Llama-3-Instruct, have open weights, their alignment data remain private, which hinders the democratization of AI.
High human labor costs and a limited, predefined scope for prompting prevent existing open-source data creation methods from scaling effectively, potentially limiting the diversity and quality of public alignment datasets.
Is it possible to synthesize high-quality instruction data at scale by extracting it directly from an aligned LLM? We present a self-synthesis method for generating large-scale alignment data named Magpie. Our key observation is that aligned LLMs like Llama-3-Instruct can generate a user query when we input only the left-side templates up to the position reserved for user messages, thanks to their auto-regressive nature.
We use this method to prompt Llama-3-Instruct and generate 4 million instructions along with their corresponding responses. We perform a comprehensive analysis of the extracted data and select 300K high-quality instances.
To compare Magpie data with other public instruction datasets, we fine-tune Llama-3–8B-Base with each dataset and evaluate the performance of the fine-tuned models.
Our results indicate that in some tasks, models fine-tuned with Magpie perform comparably to the official Llama-3–8B-Instruct, despite the latter being enhanced with 10 million data points through supervised fine-tuning (SFT) and subsequent feedback learning.
We also show that using Magpie solely for SFT can surpass the performance of previous public datasets utilized for both SFT and preference optimization, such as direct preference optimization with UltraFeedback. This advantage is evident on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
3.2. ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization

Large language models (LLMs) have shown impressive performance on language tasks but face challenges when deployed on resource-constrained devices due to their extensive parameters and reliance on dense multiplications, resulting in high memory demands and latency bottlenecks.
Shift-and-add reparameterization offers a promising solution by replacing costly multiplications with hardware-friendly primitives in both the attention and multi-layer perceptron (MLP) layers of an LLM. However, current reparameterization techniques require training from scratch or full parameter fine-tuning to restore accuracy, which is resource-intensive for LLMs.
To address this, we propose accelerating pretrained LLMs through post-training shift-and-add reparameterization, creating efficient multiplication-free models, dubbed ShiftAddLLM. Specifically, we quantize each weight matrix into binary matrices paired with group-wise scaling factors.
The associated multiplications are reparameterized into:
Shifts between activations and scaling factors
Queries and adds according to the binary matrices. To reduce accuracy loss, we present a multi-objective optimization method to minimize both weight and output activation reparameterization errors.
Additionally, based on varying sensitivity across layers to reparameterization, we develop an automated bit allocation strategy to further reduce memory usage and latency.
Experiments on five LLM families and eight tasks consistently validate the effectiveness of ShiftAddLLM, achieving average perplexity improvements of 5.6 and 22.7 points at comparable or lower latency compared to the most competitive quantized LLMs at 3 and 2 bits, respectively, and more than 80% memory and energy reductions over the original LLMs.
3.3. Discovering Preference Optimization Algorithms with and for Large Language Models

Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs. Typically, preference optimization is approached as an offline supervised learning task using manually crafted convex loss functions.
While these methods are based on theoretical insights, they are inherently constrained by human creativity, so the large search space of possible loss functions remains under-explored.
We address this by performing LLM-driven objective discovery to automatically discover new state-of-the-art preference optimization algorithms without (expert) human intervention.
Specifically, we iteratively prompt an LLM to propose and implement new preference optimization loss functions based on previously evaluated performance metrics.
This process leads to the discovery of previously unknown and performant preference optimization algorithms. The best performing of these we call Discovered Preference Optimization (DiscoPOP), a novel algorithm that adaptively blends logistic and exponential losses. Experiments demonstrate the state-of-the-art performance of DiscoPOP and its successful transfer to held-out tasks.
3.4. Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters

Exploiting activation sparsity is a promising approach to significantly accelerating the inference process of large language models (LLMs) without compromising performance.
However, activation sparsity is determined by activation functions, and commonly used ones like SwiGLU and GeGLU exhibit limited sparsity. Simply replacing these functions with ReLU fails to achieve sufficient sparsity. Moreover, inadequate training data can further increase the risk of performance degradation.
To address these challenges, we propose a novel dReLU function, which is designed to improve LLM activation sparsity, along with a high-quality training data mixture ratio to facilitate effective sparsification. Additionally, we leverage sparse activation patterns within the Feed-Forward Network (FFN) experts of Mixture-of-Experts (MoE) models to further boost efficiency.
By applying our neuron sparsification method to the Mistral and Mixtral models, only 2.5 billion and 4.3 billion parameters are activated per inference iteration, respectively, while achieving even more powerful model performance.
Evaluation results demonstrate that this sparsity achieves a 2–5x decoding speedup. Remarkably, on mobile phones, our TurboSparse-Mixtral-47B achieves an inference speed of 11 tokens per second.
4. LLM Prompt Engineering & Fine-Tuning
4.1. The Prompt Report: A Systematic Survey of Prompting Techniques

Generative Artificial Intelligence (GenAI) systems are being increasingly deployed across all parts of industry and research settings. Developers and end users interact with these systems through the use of prompting or prompt engineering.
While prompting is a widespread and highly researched concept, there exists conflicting terminology and a poor ontological understanding of what constitutes a prompt due to the area’s nascency. This paper establishes a structured understanding of prompts, by assembling a taxonomy of prompting techniques and analyzing their use.
We present a comprehensive vocabulary of 33 vocabulary terms, a taxonomy of 58 text-only prompting techniques, and 40 techniques for other modalities. We further present a meta-analysis of the entire literature on natural language prefix-prompting.
4.2. Large Language Model Unlearning via Embedding-Corrupted Prompts

Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a large language model should not know is important for ensuring alignment and thus safe use.
However, accurately and efficiently unlearning knowledge from an LLM remains challenging due to the potential collateral damage caused by the fuzzy boundary between retention and forgetting, and the large computational requirements for optimization across state-of-the-art models with hundreds of billions of parameters.
In this work, we present Embedding-COrrupted (ECO) Prompts, a lightweight unlearning framework for large language models to address both the challenges of knowledge entanglement and unlearning efficiency. Instead of relying on the LLM itself to unlearn, we enforce an unlearned state during inference by employing a prompt classifier to identify and safeguard prompts to forget.
We learn corruptions added to prompt embeddings via zeroth order optimization toward the unlearning objective offline and corrupt prompts flagged by the classifier during inference. We find that these embedding-corrupted prompts not only lead to desirable outputs that satisfy the unlearning objective but also closely approximate the output from a model that has never been trained on the data intended for forgetting.
Through extensive experiments on unlearning, we demonstrate the superiority of our method in achieving promising unlearning at nearly zero side effects in general domains and domains closely related to the unlearned ones. Additionally, we highlight the scalability of our method to 100 LLMs, ranging from 0.5B to 236B parameters, incurring no additional cost as the number of parameters increases.
5. LLM Reasoning
5.1. Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning

Language agents perform complex tasks by using tools to execute each step precisely. However, most existing agents are based on proprietary models or designed to target specific tasks, such as mathematics or multi-hop question answering.
We introduce Husky, a holistic, open-source language agent that learns to reason over a unified action space to address a diverse set of complex tasks involving numerical, tabular, and knowledge-based reasoning.
Husky iterates between two stages:
Generating the next action to take toward solving a given task
Executing the action using expert models and updating the current solution state.
We identify a thorough ontology of actions for addressing complex tasks and curate high-quality data to train expert models for executing these actions. Our experiments show that Husky outperforms prior language agents across 14 evaluation datasets.
Moreover, we introduce HuskyQA, a new evaluation set that stress tests language agents for mixed-tool reasoning, with a focus on retrieving missing knowledge and performing numerical reasoning. Despite using 7B models, Husky matches or even exceeds frontier LMs such as GPT-4 on these tasks, showcasing the efficacy of our holistic approach in addressing complex reasoning problems.
5.2. Improve Mathematical Reasoning in Language Models by Automated Process Supervision
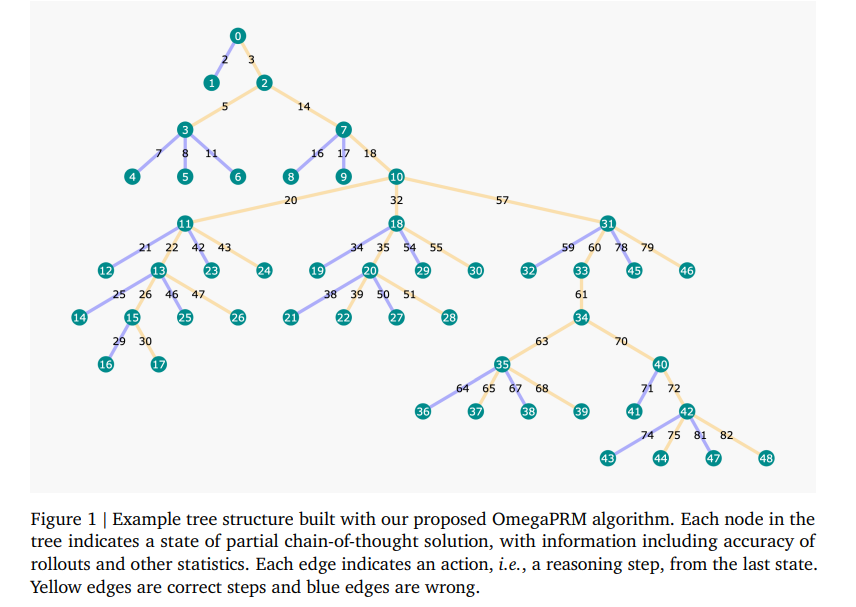
Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs).
Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs.
However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process.
To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique.
In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named OmegaPRM for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality.
As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction-tuned Gemini Pro model’s math reasoning performance, achieving a 69.4\% success rate on the MATH benchmark, a 36\% relative improvement from the 51\% base model performance.
Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
5.3. Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning

Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks.
However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios.
The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks.
5.4. Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models
Humans draw to facilitate reasoning: we draw auxiliary lines when solving geometry problems; we mark and circle when reasoning on maps; we use sketches to amplify our ideas and relieve our limited-capacity working memory.
However, such actions are missing in current multimodal language models (LMs). Current chain-of-thought and tool-use paradigms only use text as intermediate reasoning steps. In this work, we introduce Sketchpad, a framework that gives multimodal LMs a visual sketchpad and tools to draw on the sketchpad.
The LM conducts planning and reasoning according to the visual artifacts it has drawn. Different from prior work, which uses text-to-image models to enable LMs to draw, Sketchpad enables LMs to draw with lines, boxes, marks, etc., which is closer to human sketching and better facilitates reasoning.
Sketchpad can also use specialist vision models during the sketching process (e.g., draw bounding boxes with object detection models, draw masks with segmentation models), to further enhance visual perception and reasoning. We experiment with a wide range of math tasks (including geometry, functions, graphs, and chess) and complex visual reasoning tasks.
Sketchpad substantially improves performance on all tasks over strong base models with no sketching, yielding an average gain of 12.7% on math tasks, and 8.6% on vision tasks. GPT-4o with Sketchpad sets a new state of the art on all tasks, including V*Bench (80.3%), BLINK spatial reasoning (83.9%), and visual correspondence (80.8%).
6. Attention Models
6.1. TextGrad: Automatic “Differentiation” via Text

AI is undergoing a paradigm shift, with breakthroughs achieved by systems orchestrating multiple large language models (LLMs) and other complex components. As a result, developing principled and automated optimization methods for compound AI systems is one of the most important new challenges.
Neural networks faced a similar challenge in their early days until backpropagation and automatic differentiation transformed the field by making optimization turn-key. Inspired by this, we introduce TextGrad, a powerful framework performing automatic ``differentiation’’ via text. TextGrad backpropagates textual feedback provided by LLMs to improve individual components of a compound AI system.
In our framework, LLMs provide rich, general, natural language suggestions to optimize variables in computation graphs, ranging from code snippets to molecular structures. TextGrad follows PyTorch’s syntax and abstraction and is flexible and easy to use.
It works out-of-the-box for a variety of tasks, where the users only provide the objective function without tuning components or prompts of the framework. We showcase TextGrad’s effectiveness and generality across a diverse range of applications, from question-answering and molecule optimization to radiotherapy treatment planning.
Without modifying the framework, TextGrad improves the zero-shot accuracy of GPT-4o in Google-Proof Question Answering from 51% to 55%, yields a 20% relative performance gain in optimizing LeetCode-Hard coding problem solutions, improves prompts for reasoning, designs new druglike small molecules with desirable in silico binding, and designs radiation oncology treatment plans with high specificity. TextGrad lays a foundation to accelerate the development of the next generation of AI systems.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
