


Top Important LLMs Papers for the Week from 27/05 to 02/06
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fifth Week of May 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Training, Evaluation & Inference
LLM Quantization & Alignment
Attention Models
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. Aya 23: Open Weight Releases to Further Multilingual Progress

This technical report introduces Aya 23, a family of multilingual language models. Aya 23 builds on the recent release of the Aya model focusing on pairing a highly performant pre-trained model with the recently released Aya collection (Singh et al., 2024).
The result is a powerful multilingual large language model serving 23 languages, expanding state-of-the-art language modeling capabilities to approximately half of the world’s population. The Aya model covered 101 languages whereas the Aya 23 is an experiment in depth vs breadth, exploring the impact of allocating more capacity to fewer languages that are included during pre-training.
Aya 23 outperforms both previous massively multilingual models like Aya 101 for the languages it covers, as well as widely used models like Gemma, Mistral, and Mixtral on an extensive range of discriminative and generative tasks. We release the open weights for both the 8B and 35B models as part of our continued commitment to expanding access to multilingual progress.
1.2. Denoising LM: Pushing the Limits of Error Correction Models for Speech Recognition
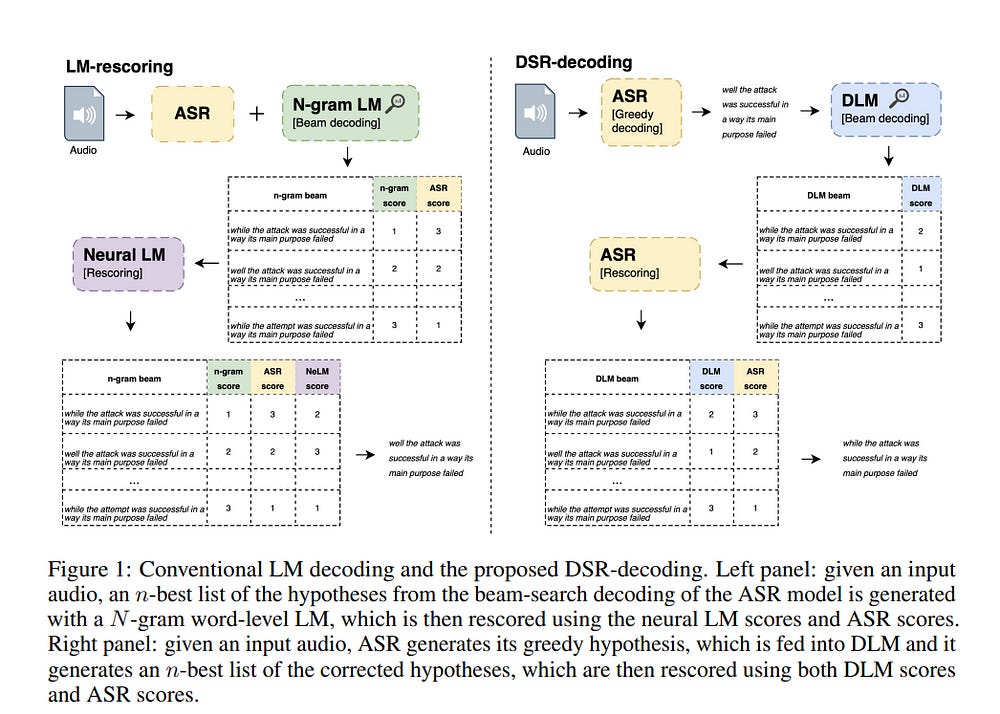
Language models (LMs) have long been used to improve the results of automatic speech recognition (ASR) systems, but they are unaware of the errors that ASR systems make.
Error correction models are designed to fix ASR errors, however, they showed little improvement over traditional LMs mainly due to the lack of supervised training data.
In this paper, we present Denoising LM (DLM), which is a scaled error correction model trained with vast amounts of synthetic data, significantly exceeding prior attempts meanwhile achieving new state-of-the-art ASR performance. We use text-to-speech (TTS) systems to synthesize audio, which is fed into an ASR system to produce noisy hypotheses, which are then paired with the original texts to train the DLM.
DLM has several key ingredients: (i) up-scaled model and data; (ii) usage of multi-speaker TTS systems; (iii) combination of multiple noise augmentation strategies; and (iv) new decoding techniques.
With a Transformer-CTC ASR, DLM achieves a 1.5% word error rate (WER) on test-clean and 3.3% WER on test-other on Librispeech, which to our knowledge are the best-reported numbers in the setting where no external audio data are used and even match self-supervised methods which use external audio data.
Furthermore, a single DLM applies to different ASRs and greatly surpasses the performance of conventional LM-based beam-search rescoring. These results indicate that properly investigated error correction models have the potential to replace conventional LMs, holding the key to a new level of accuracy in ASR systems.
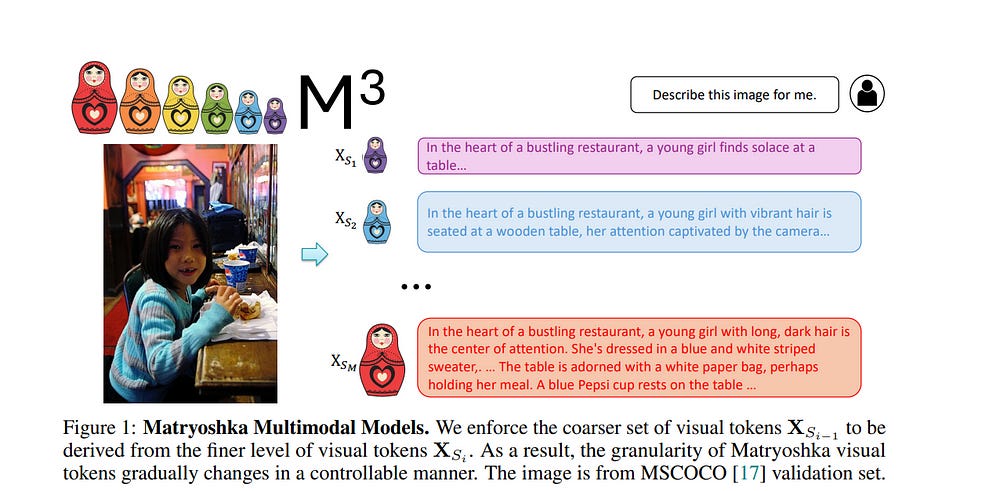
1.3. Matryoshka Multimodal Models
Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM).
However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency. While token pruning/merging methods do exist, they produce a single-length output for each image and do not afford flexibility in trading off information density v.s. efficiency.
Inspired by the concept of Matryoshka Dolls, we propose M3: Matryoshka Multimodal Models, which learns to represent visual content as nested sets of visual tokens that capture information across multiple coarse-to-fine granularities.
Our approach offers several unique benefits for LMMs:
(1) One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image based on the anticipated complexity or simplicity of the content.
(2) M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens.
(3) Our approach provides a foundation to explore the best trade-off between performance and visual token length at the sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.
1.4. Jina CLIP: Your CLIP Model Is Also Your Text Retriever

Contrastive Language-Image Pretraining (CLIP) is widely used to train models to align images and texts in a common embedding space by mapping them to fixed-sized vectors.
These models are key to multimodal information retrieval and related tasks. However, CLIP models generally underperform in text-only tasks compared to specialized text models. This creates inefficiencies for information retrieval systems that keep separate embeddings and models for text-only and multimodal tasks.
We propose a novel, multi-task contrastive training method to address this issue, which we use to train the Jina-clip-v1 model to achieve state-of-the-art performance on both text-image and text-text retrieval tasks.
1.5. Zamba: A Compact 7B SSM Hybrid Model

In this technical report, we present Zamba, a novel 7B SSM-transformer hybrid model that achieves competitive performance against leading open-weight models at a comparable scale.
Zamba is trained on 1T tokens from openly available datasets and is the best non-transformer model at this scale. Zamba pioneers a unique architecture combining a Mamba backbone with a single shared attention module, thus obtaining the benefits of attention at minimal parameter cost.
Due to its architecture, Zamba is significantly faster at inference than comparable transformer models and requires substantially less memory for the generation of long sequences.
Zamba is pretrained in two phases: the first phase is based on existing web datasets, while the second one consists of annealing the model over high-quality instruct and synthetic datasets, and is characterized by a rapid learning rate decay. We open-source the weights and all checkpoints for Zamba, through both phase 1 and the annealing phases.
1.6. Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models

The rapid development of large language and vision models (LLVMs) has been driven by advances in visual instruction tuning. Recently, open-source LLVMs have curated high-quality visual instruction tuning datasets and utilized additional vision encoders or multiple computer vision models in order to narrow the performance gap with powerful closed-source LLVMs.
These advancements are attributed to multifaceted information required for diverse capabilities, including fundamental image understanding, real-world knowledge about common-sense and non-object concepts (e.g., charts, diagrams, symbols, signs, and math problems), and step-by-step procedures for solving complex questions.
Drawing from the multifaceted information, we present a new efficient LLVM, Mamba-based traversal of rationales (Meteor), which leverages multifaceted rationale to enhance understanding and answering capabilities.
To embed lengthy rationales containing abundant information, we employ the Mamba architecture, which is capable of processing sequential data with linear time complexity. We introduce a new concept of traversal of rationale that facilitates efficient embedding of rationale. Subsequently, the backbone multimodal language model (MLM) is trained to generate answers with the aid of rationale.
Through these steps, Meteor achieves significant improvements in vision language performances across multiple evaluation benchmarks requiring diverse capabilities, without scaling up the model size or employing additional vision encoders and computer vision models.
1.7. DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories

How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs.
To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances.
DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions.
DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies).
DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database).
Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa).
Our experiments reveal these LLMs’ coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%.
We also analyze LLMs’ failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs’ predictions have been released.
1.8. Yuan 2.0-M32: Mixture of Experts with Attention Router
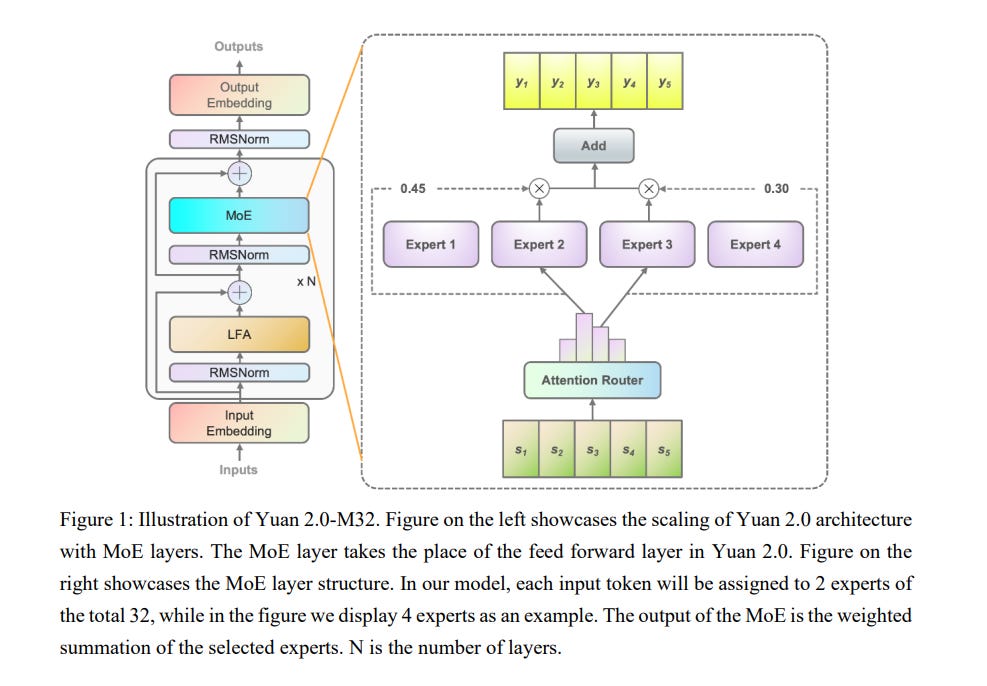
Yuan 2.0-M32, with a similar base architecture as Yuan-2.0 2B, uses a mixture-of-experts architecture with 32 experts of which 2 experts are active.
A new router network, Attention Router, is proposed and adopted for a more efficient selection of experts, which boosts the accuracy by 3.8% compared to the model with a classical router network.
Yuan 2.0-M32 is trained with 2000B tokens from scratch, and the training computation consumption is only 9.25% of a dense model at the same parameter scale.
Yuan 2.0-M32 demonstrates competitive capability in coding, math, and various domains of expertise, with only 3.7B active parameters of 40B in total, and 7.4 GFlops forward computation per token, both of which are only 1/19 of Llama3–70B.
Yuan 2.0-M32 surpass Llama3–70B on the MATH and ARC-Challenge benchmark, with an accuracy of 55.89 and 95.8 respectively. The models and source codes of Yuan 2.0-M32 are released on GitHub.
1.9. AutoCoder: Enhancing Code Large Language Model with AIEV-Instruct

We introduce AutoCoder, the first Large Language Model to surpass GPT-4 Turbo (April 2024) and GPT-4o in pass@1 on the Human Eval benchmark test (90.9% vs. 90.2%).
In addition, AutoCoder offers a more versatile code interpreter compared to GPT-4 Turbo and GPT-4o. Its code interpreter can install external packages instead of limiting to built-in packages.
AutoCoder’s training data is a multi-turn dialogue dataset created by a system combining agent interaction and external code execution verification, a method we term \textsc{AIEV-Instruct} (Instruction Tuning with Agent-Interaction and Execution-Verified).
Compared to previous large-scale code dataset generation methods, AIEV-Instruct reduces dependence on proprietary large models and provides execution-validated code datasets.
1.10. LLMs achieve adult human performance on higher-order theory of mind tasks
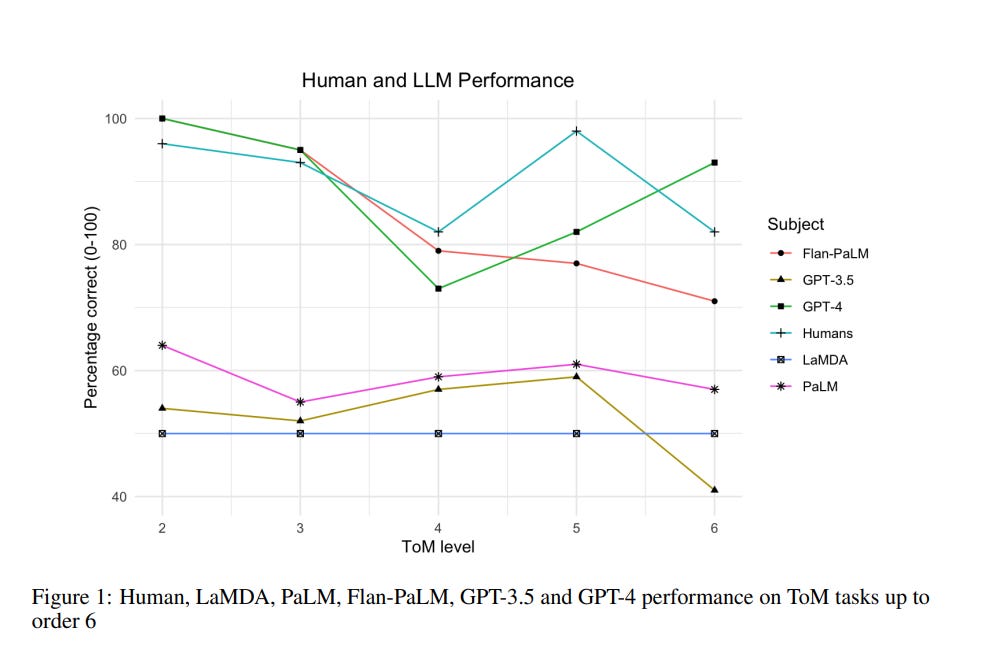
This paper examines the extent to which large language models (LLMs) have developed the higher-order theory of mind (ToM); the human ability to reason about multiple mental and emotional states in a recursive manner (e.g. I think that you believe that she knows).
This paper builds on prior work by introducing a handwritten test suite — Multi-Order Theory of Mind Q&A — and using it to compare the performance of five LLMs to a newly gathered adult human benchmark. We find that GPT-4 and Flan-PaLM reach adult-level and near adult-level performance on ToM tasks overall, and that GPT-4 exceeds adult performance on 6th-order inferences.
Our results suggest that there is an interplay between model size and finetuning for the realization of ToM abilities and that the best-performing LLMs have developed a generalized capacity for ToM. Given the role that higher-order ToM plays in a wide range of cooperative and competitive human behaviors, these findings have significant implications for user-facing LLM applications.
1.11. Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach

Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human effort.
This manual process has some limitations similar to those encountered in supervised learning, e.g., the crowd-sourced selection of data is costly and time-consuming, preventing scaling the dataset size. In this work, we consider the problem of automatic curation of high-quality datasets for self-supervised pre-training.
We posit that such datasets should be large, diverse, and balanced, and propose a clustering-based approach for building ones satisfying all these criteria. Our method involves successive and hierarchical applications of k-means on a large and diverse data repository to obtain clusters that distribute uniformly among data concepts, followed by a hierarchical, balanced sampling step from these clusters.
Extensive experiments on three different data domains including web-based images, satellite images, and text show that features trained on our automatically curated datasets outperform those trained on uncurated data while being on par or better than ones trained on manually curated data.
1.12. LLaMA-NAS: Efficient Neural Architecture Search for Large Language Models

The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis, and other tasks have been extraordinary which has prompted their extensive adoption.
Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2–7B using one-shot NAS.
In particular, we fine-tune LLaMA2–7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2–7B network is unnecessarily large and complex.
More specifically, we demonstrate a 1.5x reduction in model size and a 1.3x speedup in throughput for certain tasks with a negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques.
Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs that can be used on less expensive and more readily available hardware platforms.
1.13. MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
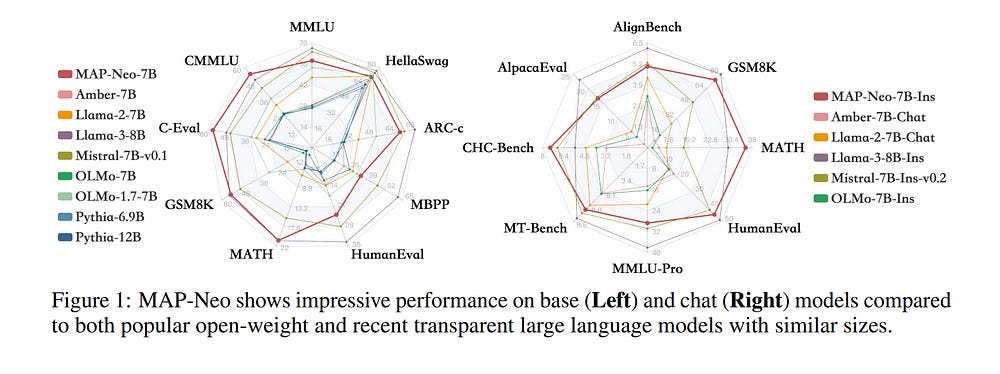
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details.
Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model’s weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed.
To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases, and risks.
However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens.
Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided.
Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
1.14. Data Mixing Made Efficient: A Bivariate Scaling Law for Language Model Pretraining
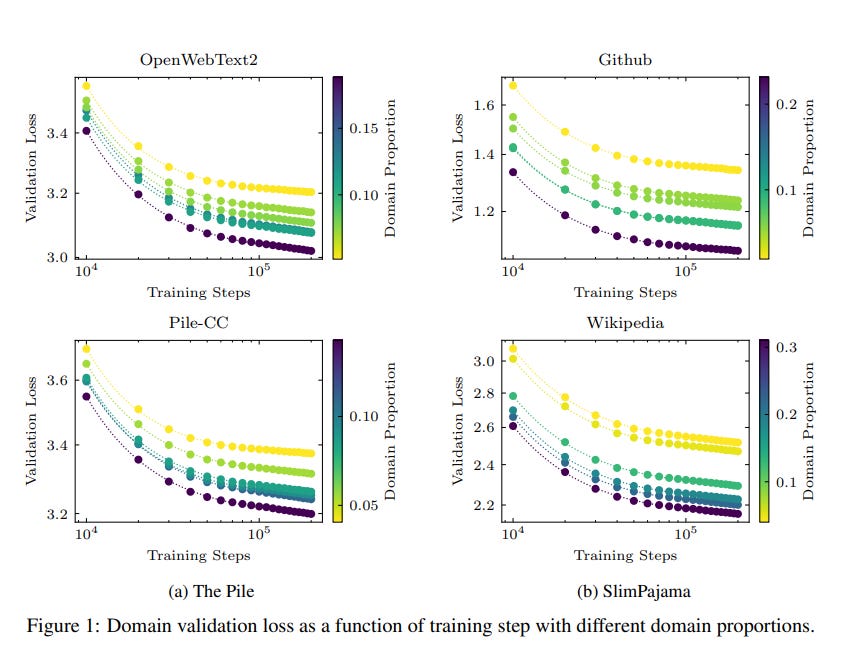
Large language models exhibit exceptional generalization capabilities, primarily attributed to the utilization of diversely sourced data. However, conventional practices in integrating this diverse data heavily rely on heuristic schemes, lacking theoretical guidance.
This research tackles these limitations by investigating strategies based on low-cost proxies for data mixtures, with the aim of streamlining data curation to enhance training efficiency. Specifically, we propose a unified scaling law, termed BiMix, which accurately models the bivariate scaling behaviors of both data quantity and mixing proportions.
We conduct systematic experiments and provide empirical evidence for the predictive power and fundamental principles of BiMix. Notably, our findings reveal that entropy-driven training-free data mixtures can achieve comparable or even better performance than more resource-intensive methods. We hope that our quantitative insights can shed light on further judicious research and development in cost-effective language modeling.
1.15. Nearest Neighbor Speculative Decoding for LLM Generation and Attribution
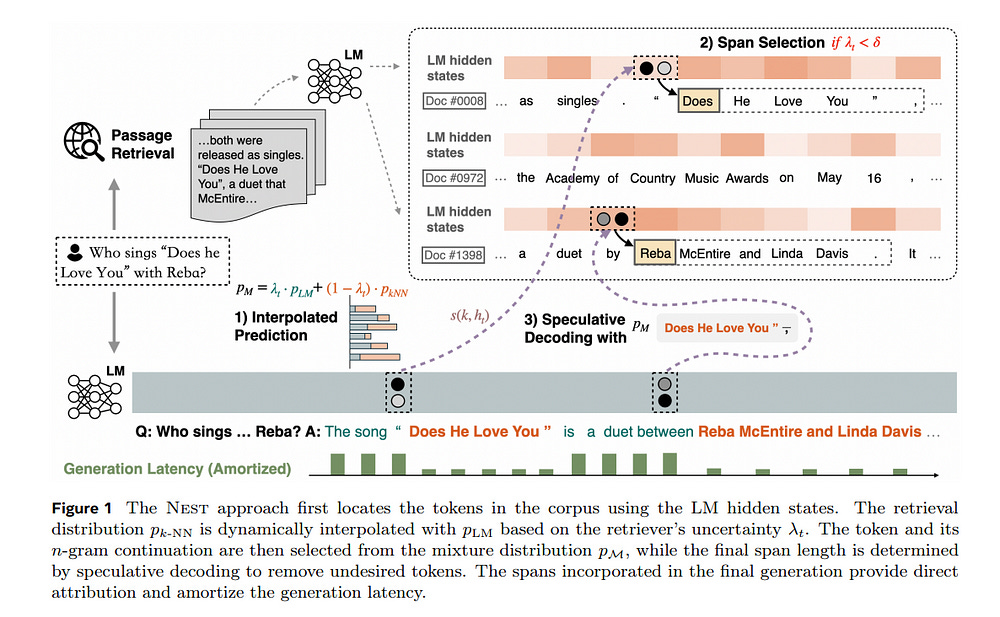
Large language models (LLMs) often hallucinate and lack the ability to provide attribution for their generations. Semi-parametric LMs, such as kNN-LM, approach these limitations by refining the output of an LM for a given prompt using its nearest neighbor matches in a non-parametric data store.
However, these models often exhibit slow inference speeds and produce non-fluent texts. In this paper, we introduce Nearest Neighbor Speculative Decoding (NEST), a novel semi-parametric language modeling approach that is capable of incorporating real-world text spans of arbitrary length into the LM generations and providing attribution to their sources.
NEST performs token-level retrieval at each inference step to compute a semi-parametric mixture distribution and identify promising span continuations in a corpus.
It then uses an approximate speculative decoding procedure that accepts a prefix of the retrieved span or generates a new token. NEST significantly enhances the generation quality and attribution rate of the base LM across a variety of knowledge-intensive tasks, surpassing the conventional kNN-LM method and performing competitively with in-context retrieval augmentation.
In addition, NEST substantially improves the generation speed, achieving a 1.8x speedup in inference time when applied to Llama-2-Chat 70B.
2. LLM Training, Evaluation & Inference
2.1. Parrot: Efficient Serving of LLM-based Applications with Semantic Variable

The rise of large language models (LLMs) has enabled LLM-based applications (a.k.a. AI agents or co-pilots), a new software paradigm that combines the strength of LLM and conventional software.
Diverse LLM applications from different tenants could design complex workflows using multiple LLM requests to accomplish one task. However, they have to use the over-simplified request-level API provided by today’s public LLM services, losing essential application-level information.
Public LLM services have to blindly optimize individual LLM requests, leading to sub-optimal end-to-end performance of LLM applications. This paper introduces Parrot, an LLM service system that focuses on the end-to-end experience of LLM-based applications. Parrot proposes a Semantic Variable, a unified abstraction to expose application-level knowledge to public LLM services.
A Semantic Variable annotates an input/output variable in the prompt of a request and creates the data pipeline when connecting multiple LLM requests, providing a natural way to program LLM applications. Exposing Semantic Variables to the public LLM service allows it to perform conventional data flow analysis to uncover the correlation across multiple LLM requests.
This correlation opens a brand-new optimization space for the end-to-end performance of LLM-based applications. Extensive evaluations demonstrate that Parrot can achieve up to an order-of-magnitude improvement for popular and practical use cases of LLM applications.
2.2. VeLoRA: Memory Efficient Training using Rank-1 Sub-Token Projections
Large language models (LLMs) have recently emerged as powerful tools for tackling many language-processing tasks. Despite their success, training and fine-tuning these models is still far too computationally and memory intensive.
In this paper, we identify and characterize the important components needed for effective model convergence using gradient descent. In doing so we find that the intermediate activations used to implement backpropagation can be excessively compressed without incurring any degradation in performance.
This result leads us to a cheap and memory-efficient algorithm for both fine-tuning and pre-training LLMs. The proposed algorithm simply divides the tokens up into smaller sub-tokens before projecting them onto a fixed 1-dimensional subspace during the forward pass.
These features are then coarsely reconstructed during the backward pass to implement the update rules. We confirm the effectiveness of our algorithm as being complimentary to many state-of-the-art PEFT methods on the VTAB-1k fine-tuning benchmark.
Furthermore, we outperform QLoRA for fine-tuning LLaMA and show competitive performance against other memory-efficient pre-training methods on the large-scale C4 dataset.
2.3. NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models

Decoder-only large language model (LLM)--based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval.
In this work, we introduce the NV-Embed model with a variety of architectural designs and training procedures to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility.
For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last <EOS> token embedding from LLMs. To enhance representation learning, we remove the causal attention mask of LLMs during contrastive training.
For model training, we introduce a two-stage contrastive instruction-tuning method. It first applies contrastive training with instructions on retrieval datasets, utilizing in-batch negatives and curated hard negative examples. At stage 2, it blends various non-retrieval datasets into instruction tuning, which not only enhances non-retrieval task accuracy but also improves retrieval performance.
Combining these techniques, our NV-Embed model, using only publicly available data, has achieved a record-high score of 69.32, ranking №1 on the Massive Text Embedding Benchmark (MTEB) (as of May 24, 2024), with 56 tasks, encompassing retrieval, reranking, classification, clustering, and semantic textual similarity tasks. Notably, our model also attains the highest score of 59.36 on 15 retrieval tasks in the MTEB benchmark (also known as BEIR).
3. LLM Fine-Tuning
3.1. Trans-LoRA: towards data-free Transferable Parameter Efficient Finetuning
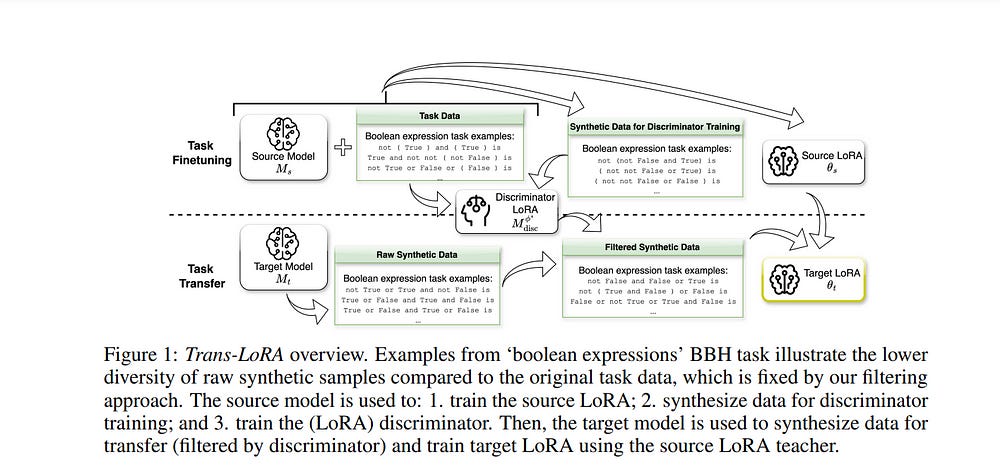
Low-rank adapters (LoRA) and their variants are popular parameter-efficient fine-tuning (PEFT) techniques that closely match full model fine-tune performance while requiring only a small number of additional parameters.
These additional LoRA parameters are specific to the base model being adapted. When the base model needs to be deprecated and replaced with a new one, all the associated LoRA modules need to be re-trained. Such re-training requires access to the data used to train the LoRA for the original base model.
This is especially problematic for commercial cloud applications where the LoRA modules and the base models are hosted by service providers who may not be allowed to host proprietary client task data. To address this challenge, we propose Trans-LoRA — a novel method for lossless, nearly data-free transfer of LoRAs across base models.
Our approach relies on synthetic data to transfer LoRA modules. Using large language models, we design a synthetic data generator to approximate the data-generating process of the observed task data subset—training on the resulting synthetic dataset transfers LoRA modules to new models.
We show the effectiveness of our approach using both LLama and Gemma model families. Our approach achieves lossless (mostly improved) LoRA transfer between models within and across different base model families, and even between different PEFT methods, on a wide variety of tasks.
4. LLM Quantization & Alignment
4.1. Xwin-LM: Strong and Scalable Alignment Practice for LLMs
In this work, we present Xwin-LM, a comprehensive suite of alignment methodologies for large language models (LLMs). This suite encompasses several key techniques, including supervised finetuning (SFT), reward modeling (RM), rejection sampling finetuning (RS), and direct preference optimization (DPO).
The key components are as follows:
Xwin-LM-SFT, models initially finetuned with high-quality instruction data.
Xwin-Pair, a large-scale, multi-turn preference dataset meticulously annotated using GPT-4
Xwin-RM, reward models trained on Xwin-Pair, developed at scales of 7B, 13B, and 70B parameters
Xwin-Set is a multiwise preference dataset in which each prompt is linked to 64 unique responses generated by Xwin-LM-SFT and scored by Xwin-RM.
Xwin-LM-RS, models finetuned with the highest-scoring responses from Xwin-Set.
Xwin-LM-DPO, models are further optimized on Xwin-Set using the DPO algorithm.
Our evaluations on AlpacaEval and MT-bench demonstrate consistent and significant improvements across the pipeline, demonstrating the strength and scalability of Xwin-LM.
4.2. Self-Exploring Language Models: Active Preference Elicitation for Online Alignment

Preference optimization, particularly through Reinforcement Learning from Human Feedback (RLHF), has achieved significant success in aligning Large Language Models (LLMs) to adhere to human intentions. Unlike offline alignment with a fixed dataset, online feedback collection from humans or AI on model generations typically leads to more capable reward models and better-aligned LLMs through an iterative process.
However, achieving a globally accurate reward model requires systematic exploration to generate diverse responses that span the vast space of natural language. Random sampling from standard reward-maximizing LLMs alone is insufficient to fulfill this requirement.
To address this issue, we propose a bilevel objective optimistically biased towards potentially high-reward responses to actively explore out-of-distribution regions.
By solving the inner-level problem with the reparameterized reward function, the resulting algorithm, named Self-Exploring Language Models (SELM), eliminates the need for a separate RM and iteratively updates the LLM with a straightforward objective.
Compared to Direct Preference Optimization (DPO), the SELM objective reduces indiscriminate favor of unseen extrapolations and enhances exploration efficiency.
Our experimental results demonstrate that when finetuned on Zephyr-7B-SFT and Llama-3–8B-Instruct models, SELM significantly boosts the performance on instruction-following benchmarks such as MT-Bench and AlpacaEval 2.0, as well as various standard academic benchmarks in different settings.
4.3. Offline Regularised Reinforcement Learning for Large Language Models Alignment
The dominant framework for the alignment of large language models (LLM), whether through reinforcement learning from human feedback or direct preference optimization, is to learn from preference data.
This involves building datasets where each element is a quadruplet composed of a prompt, two independent responses (completions of the prompt), and a human preference between the two independent responses, yielding a preferred and a dis-preferred response. Such data is typically scarce and expensive to collect.
On the other hand, single-trajectory datasets where each element is a triplet composed of a prompt, a response, and human feedback is naturally more abundant. The canonical element of such datasets is for instance an LLM’s response to a user’s prompt followed by a user’s feedback such as a thumbs-up/down.
Consequently, in this work, we propose DRO, or Direct Reward Optimisation, as a framework and associated algorithms that do not require pairwise preferences. DRO uses a simple mean-squared objective that can be implemented in various ways.
We validate our findings empirically, using T5 encoder-decoder language models, and show DRO’s performance over selected baselines such as Kahneman-Tversky Optimization (KTO). Thus, we confirm that DRO is a simple and empirically compelling method for single-trajectory policy optimization.
5. LLM Reasoning
5.1. Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization

We study whether transformers can learn to implicitly reason over parametric knowledge, a skill that even the most capable language models struggle with.
Focusing on two representative reasoning types, composition, and comparison, we consistently find that transformers can learn implicit reasoning, but only through grokking, i.e., extended training far beyond overfitting.
The levels of generalization also vary across reasoning types: when faced with out-of-distribution examples, transformers fail to systematically generalize for composition but succeed for comparison. We delve into the model’s internals throughout training, conducting analytical experiments that reveal:
The mechanism behind grokking, such as the formation of the generalizing circuit and its relation to the relative efficiency of generalizing and memorizing circuits.
The connection between systematicity and the configuration of the generalizing circuit. Our findings guide data and training setup to better induce implicit reasoning and suggest potential improvements to the transformer architecture, such as encouraging cross-layer knowledge sharing.
Furthermore, we demonstrate that for a challenging reasoning task with a large search space, GPT-4-Turbo and Gemini-1.5-Pro based on non-parametric memory fail badly regardless of prompting styles or retrieval augmentation, while a fully grokked transformer can achieve near-perfect accuracy, showcasing the power of parametric memory for complex reasoning.
6. Attention Models
6.1. Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training

LLMs are computationally expensive to pre-train due to their large scale. Model growth emerges as a promising approach by leveraging smaller models to accelerate the training of larger ones. However, the viability of these model growth methods in an efficient LLM pre-training remains underexplored.
This work identifies three critical obstacles:
Lack of comprehensive evaluation
Untested viability for scaling
Lack of empirical guidelines.
To tackle O1, we summarize existing approaches into four atomic growth operators and systematically evaluate them in a standardized LLM pre-training setting.
Our findings reveal that a depthwise stacking operator, called G_{stack}, exhibits remarkable acceleration in training, leading to decreased loss and improved overall performance on eight standard NLP benchmarks compared to strong baselines.
Motivated by these promising results, we conduct extensive experiments to delve deeper into G_{stack} to address O2 and O3. For O2 (untested scalability), our study shows that G_{stack} is scalable and consistently performs well, with experiments with up to 7B LLMs after growth and pre-training LLMs with 750B tokens.
For example, compared to a conventionally trained 7B model using 300B tokens, our G_{stack} model converges to the same loss with 194B tokens, resulting in a 54.6\% speedup.
We further address O3 (lack of empirical guidelines) by formalizing guidelines to determine growth timing and growth factor for G_{stack}, making it practical in general LLM pre-training. We also provide in-depth discussions and comprehensive ablation studies of G_{stack}.
6.2. Transformers Can Do Arithmetic with the Right Embeddings
A good initialization of deep learning models is essential since it can help them converge better and faster. However, pretraining large models is unaffordable for many researchers, which makes a desired prediction for initial parameters more necessary nowadays.
Graph HyperNetworks (GHNs), one approach to predicting model parameters, have recently shown strong performance in initializing large vision models. Unfortunately, predicting parameters of very wide networks relies on copying small chunks of parameters multiple times and requires an extremely large number of parameters to support full prediction, which greatly hinders its adoption in practice.
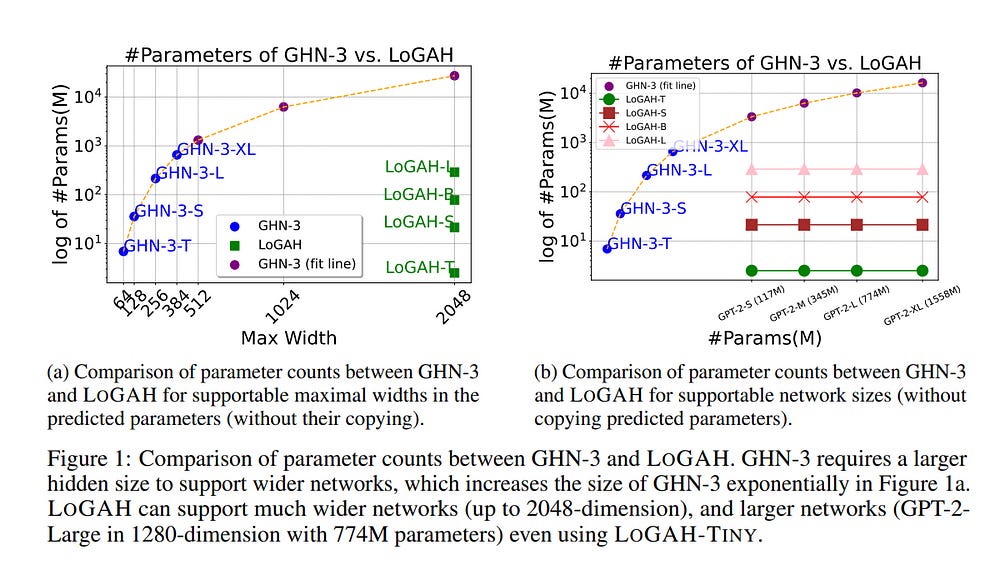
To address this limitation, we propose LoGAH (Low-rank GrAph Hypernetworks), a GHN with a low-rank parameter decoder that expands to significantly wider networks without requiring an excessive increase of parameters as in previous attempts.
LoGAH allows us to predict the parameters of 774 million large neural networks in a memory-efficient manner. We show that vision and language models (i.e., ViT and GPT-2) initialized with LoGAH achieve better performance than those initialized randomly or using existing hypernetworks.
Furthermore, we show promising transfer learning results w.r.t. training LoGAH on small datasets and using the predicted parameters to initialize for larger tasks.
6.3. LoGAH: Predicting 774-Million-Parameter Transformers using Graph HyperNetworks with 1/100 Parameters
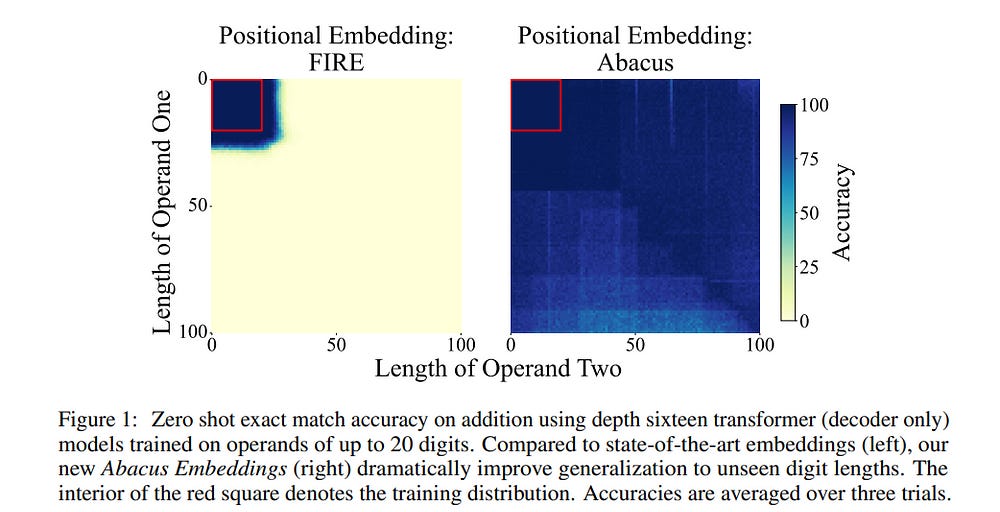
The poor performance of transformers on arithmetic tasks seems to stem in large part from their inability to keep track of the exact position of each digit inside a large span of digits.
We mend this problem by adding an embedding to each digit that encodes its position relative to the start of the number. In addition to the boost these embeddings provide on their own, we show that this fix enables architectural modifications such as input injection and recurrent layers to improve performance even further.
With positions resolved, we can study the logical extrapolation ability of transformers. Can they solve arithmetic problems that are larger and more complex than those in their training data?
We find that by training on only 20-digit numbers with a single GPU for one day, we can reach state-of-the-art performance, achieving up to 99% accuracy on 100-digit addition problems.
Finally, we show that these gains in numeracy also unlock improvements in other multi-step reasoning tasks including sorting and multiplication.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
