


Top Important LLMs Papers for the Week from 13/05 to 19/05
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Third Week of May 2024. The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
Attention Models
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. SUTRA: Scalable Multilingual Language Model Architecture
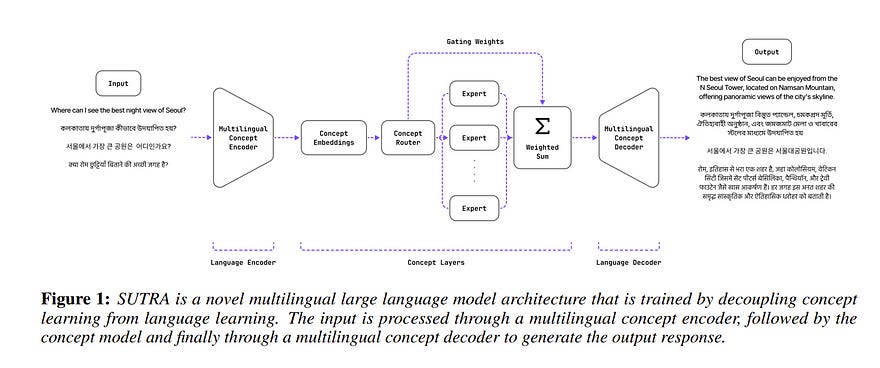
In this paper, we introduce SUTRA, a multilingual Large Language Model architecture capable of understanding, reasoning, and generating text in over 50 languages.
SUTRA’s design uniquely decouples core conceptual understanding from language-specific processing, which facilitates scalable and efficient multilingual alignment and learning. Employing a Mixture of Experts framework both in language and concept processing, SUTRA demonstrates both computational efficiency and responsiveness.
Through extensive evaluations, SUTRA is demonstrated to surpass existing models like GPT-3.5, and Llama2 by 20–30% on leading Massive Multitask Language Understanding (MMLU) benchmarks for multilingual tasks.
SUTRA models are also online LLMs that can use knowledge from the internet to provide hallucination-free, factual, and up-to-date responses while retaining their multilingual capabilities.
Furthermore, we explore the broader implications of its architecture for the future of multilingual AI, highlighting its potential to democratize access to AI technology globally and to improve the equity and utility of AI in regions with predominantly non-English languages.
Our findings suggest that SUTRA not only fills pivotal gaps in multilingual model capabilities but also establishes a new benchmark for operational efficiency and scalability in AI applications.
1.2. MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels

Recent breakthroughs in large models have highlighted the critical significance of data scale, labels, and models. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels.
This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks, and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next-generation information access systems with large language models.
MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains.
As the first dataset that meets large, real, and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research.
1.3. Chameleon: Mixed-Modal Early-Fusion Foundation Models

We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence.
We outline a stable training approach from inception, an alignment recipe, and an architectural parameterization tailored for the early-fusion, token-based, mixed-modal setting. The models are evaluated on a comprehensive range of tasks, including visual question answering, image captioning, text generation, image generation, and long-form mixed modal generation.
Chameleon demonstrates broad and general capabilities, including state-of-the-art performance in image captioning tasks, outperforms Llama-2 in text-only tasks while being competitive with models such as Mixtral 8x7B and Gemini-Pro, and performs non-trivial image generation, all in a single model.
It also matches or exceeds the performance of much larger models, including Gemini Pro and GPT-4V, according to human judgments on a new long-form mixed-modal generation evaluation, where either the prompt or outputs contain mixed sequences of both images and text. Chameleon marks a significant step forward in a unified modeling of full multimodal documents.
1.4. SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts

Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. However, training, serving, and maintaining monolithic LLMs at scale remains relatively inexpensive and challenging. The disproportionate increase in the compute-to-memory ratio of modern AI accelerators has created a memory wall, necessitating new methods to deploy AI.
Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware:
With fused operations, smaller models have higher operational intensity, which makes high utilization more challenging to achieve.
Hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them.
In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters.
We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) — a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM.
A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline.
We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
1.5. Large Language Models as Planning Domain Generators
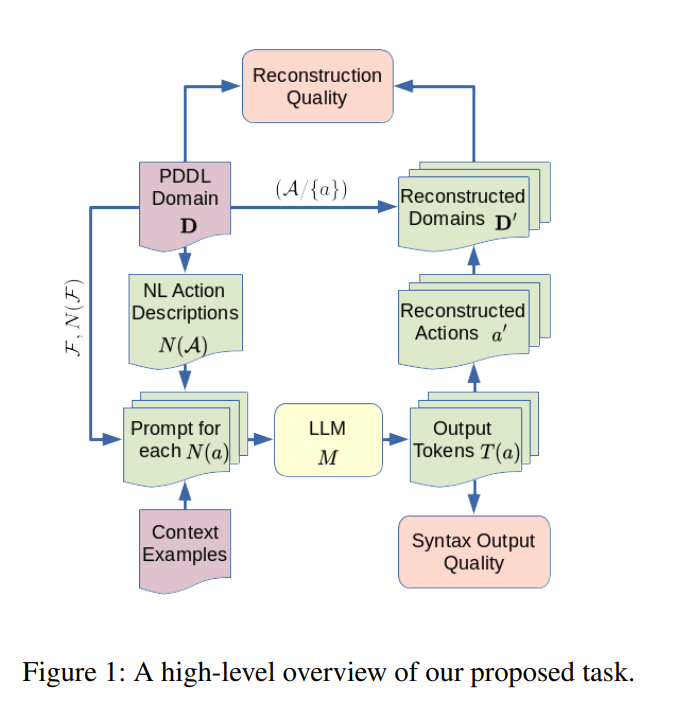
Developing domain models is one of the few remaining places that require manual human labor in AI planning. Thus, to make planning more accessible, it is desirable to automate the process of domain model generation.
To this end, we investigate if large language models (LLMs) can be used to generate planning domain models from simple textual descriptions. Specifically, we introduce a framework for automated evaluation of LLM-generated domains by comparing the sets of plans for domain instances.
Finally, we perform an empirical analysis of 7 large language models, including coding and chat models across 9 different planning domains, and under three classes of natural language domain descriptions.
Our results indicate that LLMs, particularly those with high parameter counts, exhibit a moderate level of proficiency in generating correct planning domains from natural language descriptions.
1.6. SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remain largely unclear.
In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement.
Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering tasks, scoring over 80% on both safety and helpfulness metrics.
Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLM to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack's success significantly.
1.7. Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training
In this report, we introduce Piccolo2, an embedding model that surpasses other models in the comprehensive evaluation over 6 tasks on the CMTEB benchmark, setting a new state-of-the-art.
Piccolo2 primarily leverages an efficient multi-task hybrid loss training approach, effectively harnessing textual data and labels from diverse downstream tasks.
In addition, Piccolo2 scales up the embedding dimension and uses MRL training to support more flexible vector dimensions.
1.8. SpeechVerse: A Large-scale Generalizable Audio Language Model

Large language models (LLMs) have shown incredible proficiency in performing tasks that require a semantic understanding of natural language instructions.
Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation.
We, therefore, develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training.
The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions.
We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks.
Furthermore, we evaluate the model’s capability for generalized instruction followed by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
2. LLM Fine-Tunning
2.1. LoRA Learns Less and Forgets Less
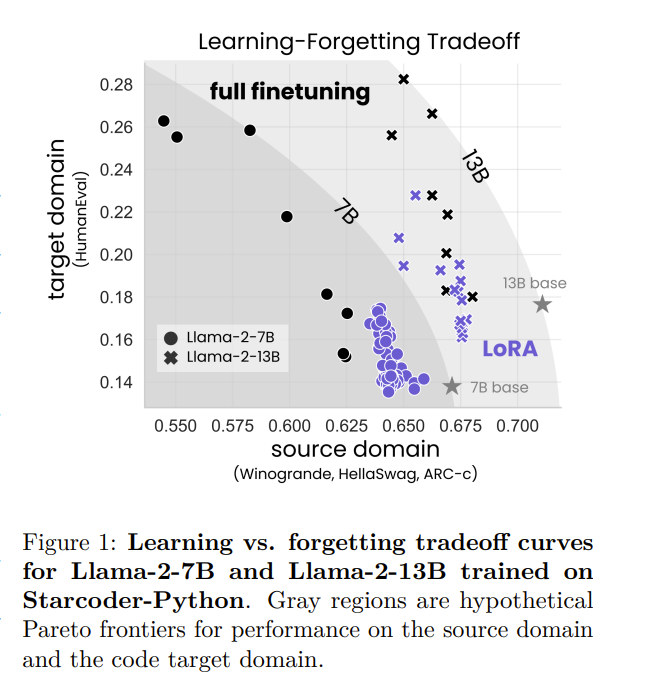
Low-Rank Adaptation (LoRA) is a widely used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low-rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics.
We consider both the instruction finetuning (approx100K prompt-response pairs) and continued pretraining (approx10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full fine-tuning.
Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model’s performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations.
We show that full finetuning learns perturbations with a rank that is 10–100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
3. LLM Training, Evaluation & Inference
3.1. RLHF Workflow: From Reward Modeling to Online RLHF

We present the workflow of Online Iterative Reinforcement Learning from Human Feedback (RLHF) in this technical report, which is widely reported to outperform its offline counterpart by a large margin in the recent large language model (LLM) literature.
However, existing open-source RLHF projects are still largely confined to the offline learning setting. In this technical report, we aim to fill in this gap and provide a detailed recipe that is easy to reproduce for online iterative RLHF.
In particular, since online human feedback is usually infeasible for open-source communities with limited resources, we start by constructing preference models using a diverse set of open-source datasets and use the constructed proxy preference model to approximate human feedback.
Then, we discuss the theoretical insights and algorithmic principles behind online iterative RLHF, followed by a detailed practical implementation. Our trained LLM, SFR-Iterative-DPO-LLaMA-3–8B-R, achieves impressive performance on LLM chatbot benchmarks, including AlpacaEval-2, Arena-Hard, and MT-Bench, as well as other academic benchmarks such as HumanEval and TruthfulQA.
We have shown that supervised fine-tuning (SFT) and iterative RLHF can obtain state-of-the-art performance with fully open-source datasets. Further, we have made our models, curated datasets, and comprehensive step-by-step code guidebooks publicly available.
3.2. Plot2Code: A Comprehensive Benchmark for Evaluating Multi-modal Large Language Models in Code Generation from Scientific Plots

The remarkable progress of Multi-modal Large Language Models (MLLMs) has attracted significant attention due to their superior performance in visual contexts. However, their capabilities in turning visual figures into executable code, have not been evaluated thoroughly.
To address this, we introduce Plot2Code, a comprehensive visual coding benchmark designed for a fair and in-depth assessment of MLLMs. We carefully collect 132 manually selected high-quality matplotlib plots across six plot types from publicly available matplotlib galleries. For each plot, we carefully offer its source code and descriptive instruction summarized by GPT-4.
This approach enables Plot2Code to extensively evaluate MLLMs’ code capabilities across various input modalities. Furthermore, we propose three automatic evaluation metrics, including code pass rate, text-match ratio, and GPT-4V overall rating, for a fine-grained assessment of the output code and rendered images.
Instead of simply judging pass or fail, we employ GPT-4V to make an overall judgment between the generated and reference images, which has been shown to be consistent with human evaluation.
The evaluation results, which include analyses of 14 MLLMs such as the proprietary GPT-4V, Gemini-Pro, and the open-sourced Mini-Gemini, highlight the substantial challenges presented by Plot2Code.
With Plot2Code, we reveal that most existing MLLMs struggle with visual coding for text-dense plots, heavily relying on textual instruction. We hope that the evaluation results from Plot2Code on visual coding will guide the future development of MLLMs.
3.3. Understanding the performance gap between online and offline alignment algorithms

Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, the rising popularity of offline alignment algorithms challenges the need for on-policy sampling in RLHF.
Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes of the performance discrepancy through a series of carefully designed experimental ablations.
We show empirically that hypotheses such as offline data coverage and data quality by themselves cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime, the policies trained by online algorithms are good at generations while worse at pairwise classification.
This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks.
Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment and hints at certain fundamental challenges of offline alignment algorithms.
4. Transformers & Attention Models
4.1. Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory
Increasing the size of a Transformer model does not always lead to enhanced performance. This phenomenon cannot be explained by the empirical scaling laws.
Furthermore, improved generalization ability occurs as the model memorizes the training samples. We present a theoretical framework that sheds light on the memorization process and performance dynamics of transformer-based language models.
We model the behavior of Transformers with associative memories using Hopfield networks, such that each transformer block effectively conducts an approximate nearest-neighbor search. Based on this, we design an energy function analogous to that in the modern continuous Hopfield network which provides an insightful explanation for the attention mechanism. Using the majorization-minimization technique, we construct a global energy function that captures the layered architecture of the Transformer.
Under specific conditions, we show that the minimum achievable cross-entropy loss is bounded from below by a constant approximately equal to 1. We substantiate our theoretical results by conducting experiments with GPT-2 on various data sizes, as well as training vanilla Transformers on a dataset of 2M tokens.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
