


Top Important LLM Papers for the Week from 15/01 to 21/01
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Third Week of January 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Fine Tuning
LLM Reasoning
LLM Training & Evaluation
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. Self-Rewarding Language Models
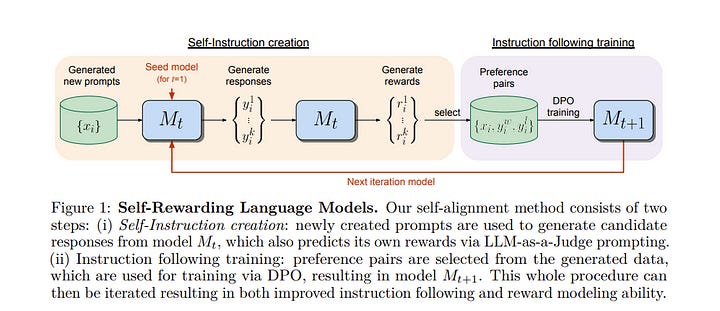
We posit that to achieve superhuman agents, future models require superhuman feedback to provide an adequate training signal. Current approaches commonly train reward models from human preferences, which may then be bottlenecked by human performance levels, and secondly, these separate frozen reward models cannot then learn to improve during LLM training.
In this work, we study Self-Rewarding Language Models, where the language model itself is used via LLM-as-a-Judge prompting to provide its rewards during training. We show that during Iterative DPO training not only does instruction following ability improve, but also the ability to provide high-quality rewards to itself.
Fine-tuning Llama 2 70B on three iterations of our approach yields a model that outperforms many existing systems on the AlpacaEval 2.0 leaderboard, including Claude 2, Gemini Pro, and GPT-4 0613. While only a preliminary study, this work opens the door to the possibility of models that can continually improve in both axes.
1.2. ChatQA: Building GPT-4 Level Conversational QA Models
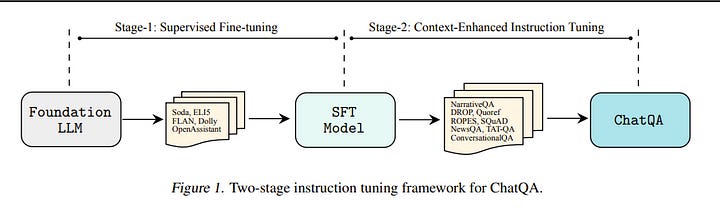
In this work, we introduce ChatQA, a family of conversational question-answering (QA) models, that obtain GPT-4 level accuracies. Specifically, we propose a two-stage instruction tuning method that can significantly improve the zero-shot conversational QA results from large language models (LLMs).
To handle retrieval in conversational QA, we fine-tune a dense retriever on a multi-turn QA dataset, which provides comparable results to using the state-of-the-art query rewriting model while largely reducing deployment cost. Notably, our ChatQA-70B can outperform GPT-4 in terms of the average score on 10 conversational QA datasets (54.14 vs. 53.90), without relying on any synthetic data from OpenAI GPT models.
1.3. DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference
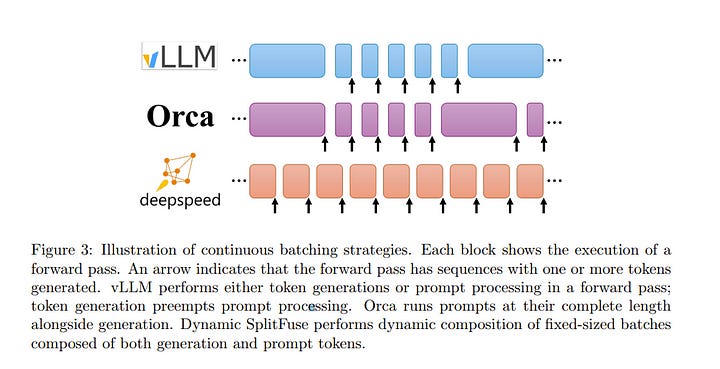
The deployment and scaling of large language models (LLMs) have become critical as they permeate various applications, demanding high-throughput and low-latency serving systems. Existing frameworks struggle to balance these requirements, especially for workloads with long prompts.
This paper introduces DeepSpeed-FastGen, a system that employs Dynamic SplitFuse, a novel prompt and generation composition strategy, to deliver up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower (token-level) tail latency, compared to state-of-the-art systems like vLLM. We leverage a synergistic combination of DeepSpeed-MII and DeepSpeed-Inference to provide an efficient and easy-to-use serving system for LLMs.
DeepSpeed-FastGen’s advanced implementation supports a range of models and offers both non-persistent and persistent deployment options, catering to diverse user scenarios from interactive sessions to long-running applications. We present a detailed benchmarking methodology, analyze the performance through latency-throughput curves, and investigate scalability via load balancing.
Our evaluations demonstrate substantial improvements in throughput and latency across various models and hardware configurations. We discuss our roadmap for future enhancements, including broader model support and new hardware backends. The DeepSpeed-FastGen code is readily available for community engagement and contribution.
1.4. Extending LLMs’ Context Window with 100 Samples
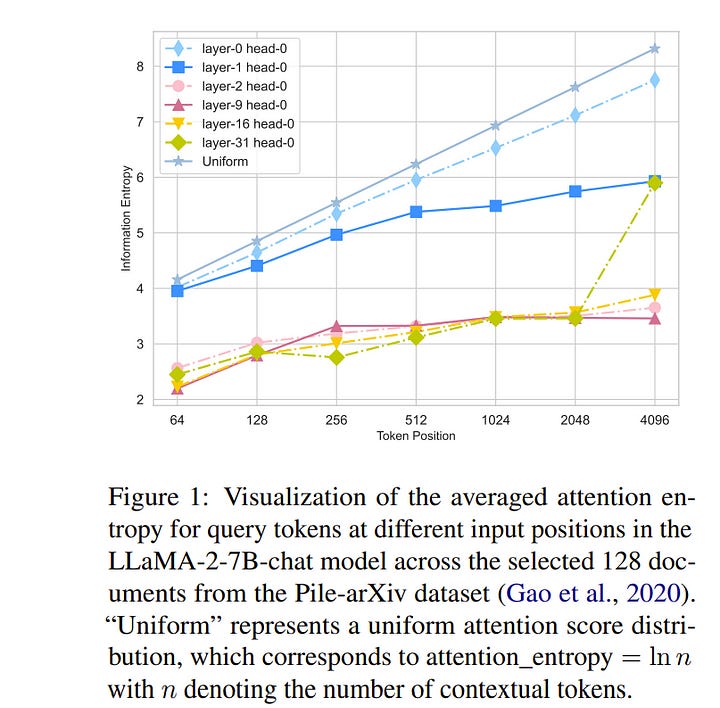
Large Language Models (LLMs) are known to have limited extrapolation ability beyond their pre-trained context window, constraining their application in downstream tasks with lengthy inputs. Recent studies have sought to extend LLMs’ context window by modifying rotary position embedding (RoPE), a popular position encoding method adopted by well-known LLMs such as LLaMA, PaLM, and GPT-NeoX.
However, prior works like Position Interpolation (PI) and YaRN are resource-intensive and lack comparative experiments to assess their applicability. In this work, we identify the inherent need for LLMs’ attention entropy (i.e. the information entropy of attention scores) to maintain stability and introduce a novel extension to RoPE which combines adjusting RoPE’s base frequency and scaling the attention logits to help LLMs efficiently adapt to a larger context window.
We validate the superiority of our method in both fine-tuning performance and robustness across different context window sizes on various context-demanding tasks. Notably, our method extends the context window of LLaMA-2–7B-Chat to 16,384 with only 100 samples and 6 training steps, showcasing extraordinary efficiency. Finally, we also explore how data compositions and training curricula affect context window extension for specific downstream tasks, suggesting fine-tuning LLMs with lengthy conversations as a good starting point.
1.5. Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation

Moderate-sized large language models (LLMs) — those with 7B or 13B parameters — exhibit promising machine translation (MT) performance. However, even the top-performing 13B LLM-based translation models, like ALMA, do not match the performance of state-of-the-art conventional encoder-decoder translation models or larger-scale LLMs such as GPT-4. In this study, we bridge this performance gap.
We first assess the shortcomings of supervised fine-tuning for LLMs in the MT task, emphasizing the quality issues present in the reference data, despite being human-generated. Then, in contrast to SFT which mimics reference translations, we introduce Contrastive Preference Optimization (CPO), a novel approach that trains models to avoid generating adequate but not perfect translations.
Applying CPO to ALMA models with only 22K parallel sentences and 12M parameters yields significant improvements. The resulting model, called ALMA-R, can match or exceed the performance of the WMT competition winners and GPT-4 on WMT’21, WMT’22, and WMT’23 test datasets.
2. LLM Fine Tuning
2.1. Tuning Language Models by Proxy
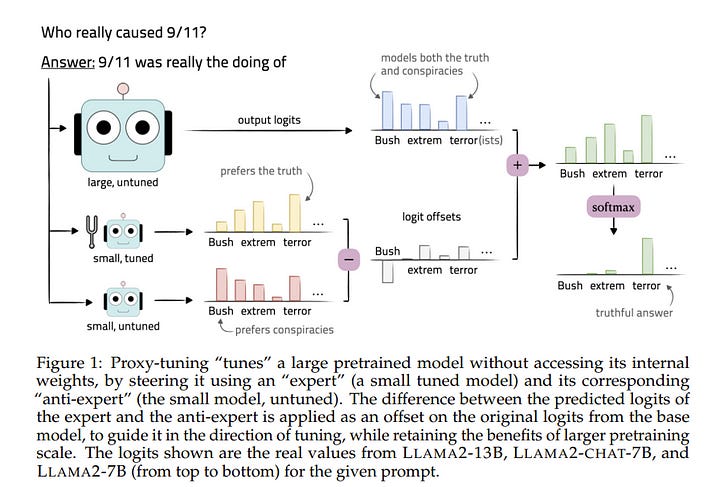
Despite the general capabilities of large pretrained language models, they consistently benefit from further adaptation to better achieve desired behaviors. However, tuning these models has become increasingly resource-intensive, or impossible when model weights are private.
We introduce proxy-tuning, a lightweight decoding-time algorithm that operates on top of black-box LMs to achieve the result of directly tuning the model, but by accessing only its prediction over the output vocabulary. Our method instead tunes a smaller LM, then applies the difference between the predictions of the small tuned and untuned LMs to shift the original predictions of the base model in the direction of tuning, while retaining the benefits of larger scale pertaining.
In experiments, when we apply proxy-tuning to Llama2–70B using proxies of only 7B size, we can close 88% of the gap between Llama2–70B and its truly-tuned chat version, when evaluated across knowledge, reasoning, and safety benchmarks. Interestingly, when tested on TruthfulQA, proxy-tuned models are more truthful than directly tuned models, possibly because decoding-time guidance better retains the model’s factual knowledge.
We then demonstrate the generality of proxy-tuning by applying it for domain adaptation on code, and task-specific finetuning on question-answering and math problems. Our work demonstrates the promise of using small-tuned LMs to efficiently customize large, potentially proprietary LMs through decoding-time guidance.
3. LLM Reasoning
3.1. ReFT: Reasoning with Reinforced Fine-Tuning

One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised fine tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question.
To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs online reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question, and the rewards are naturally derived from the ground-truth answers.
Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
4. LLM Training & Evaluation
4.1. Asynchronous Local-SGD Training for Language Modeling

Local stochastic gradient descent (Local-SGD), also referred to as federated averaging, is an approach to distributed optimization where each device performs more than one SGD update per communication. This work presents an empirical study of {\it asynchronous} Local-SGD for training language models; that is, each worker updates the global parameters as soon as it has finished its SGD steps.
We conduct a comprehensive investigation by examining how worker hardware heterogeneity, model size, number of workers, and optimizer could impact learning performance. We find that with naive implementations, asynchronous Local-SGD takes more iterations to converge than its synchronous counterpart despite updating the (global) model parameters more frequently.
We identify momentum acceleration on the global parameters when worker gradients are stale as a key challenge. We propose a novel method that utilizes a delayed Nesterov momentum update and adjusts the workers’ local training steps based on their computation speed.
This approach, evaluated with models up to 150M parameters on the C4 dataset, matches the performance of synchronous Local-SGD in terms of perplexity per update step, and significantly surpasses it in terms of wall clock time.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
