


Top Important LLM Papers for the Week from 30/10 to 5/11
Stay Relevant to Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, it’s important for researchers and engineers to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the First week of November.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Fine Tuning
LLM Reasoning
LLM Training & Optimization
Responsible AI & LLM Ethics
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. LLM Progress & Benchmarking
1.1. CodeFusion: A Pre-trained Diffusion Model for Code Generation
Imagine a developer who can only change their last line of code, how often would they have to start writing a function from scratch before it is correct? Auto-regressive models for code generation from natural language have a similar limitation: they do not easily allow reconsidering earlier tokens generated.
This paper introduces CodeFusion, a pre-trained diffusion code generation model that addresses this limitation by iterative denoising a complete program conditioned on the encoded natural language. The authors evaluate CodeFusion on the task of natural language to code generation for Bash, Python, and Microsoft Excel conditional formatting (CF) rules.
Experiments show that CodeFusion (75M parameters) performs on par with state-of-the-art auto-regressive systems (350M-175B parameters) in top-1 accuracy and outperforms them in top-3 and top-5 accuracy due to its better balance in diversity versus quality.
1.2. Data-Centric Financial Large Language Models

Large language models (LLMs) show promise for natural language tasks but struggle when applied directly to complex domains like finance. LLMs have difficulty reasoning about and integrating all relevant information. This paper proposes a data-centric approach to enable LLMs to better handle financial tasks.
The key insight is that rather than overloading the LLM with everything at once, it is more effective to preprocess and pre-understand the data. The authors create a financial LLM (FLLM) using multitask prompt-based finetuning to achieve data pre-processing and pre-understanding.
However, labeled data is scarce for each task. To overcome manual annotation costs, the authors employ abductive augmentation reasoning (AAR) to automatically generate training data by modifying the pseudo labels from FLLM’s own outputs.
Experiments show that the data-centric FLLM with AAR substantially outperforms baseline financial LLMs designed for raw text, achieving state-of-the-art financial analysis and interpretation tasks.
They also open source a new benchmark for financial analysis and interpretation. This methodology provides a promising path to unlock LLMs’ potential for complex real-world domains.
1.3. Skywork: A More Open Bilingual Foundation Model

In this technical report, the authors present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLM of comparable size to date.
The authors introduce a two-stage training methodology using a segmented corpus, targeting general-purpose training and then domain-specific enhancement training, respectively. The authors show that the model not only excels on popular benchmarks but also achieves state-of-the-art performance in Chinese language modeling on diverse domains.
Furthermore, the authors propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, the authors release Skywork-13B along with checkpoints obtained during the intermediate stages of the training process.
They are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high-quality open Chinese pre-training corpus to date. They hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
1.4. TeacherLM: Teaching to Fish Rather Than Giving the Fish, Language Modeling Likewise
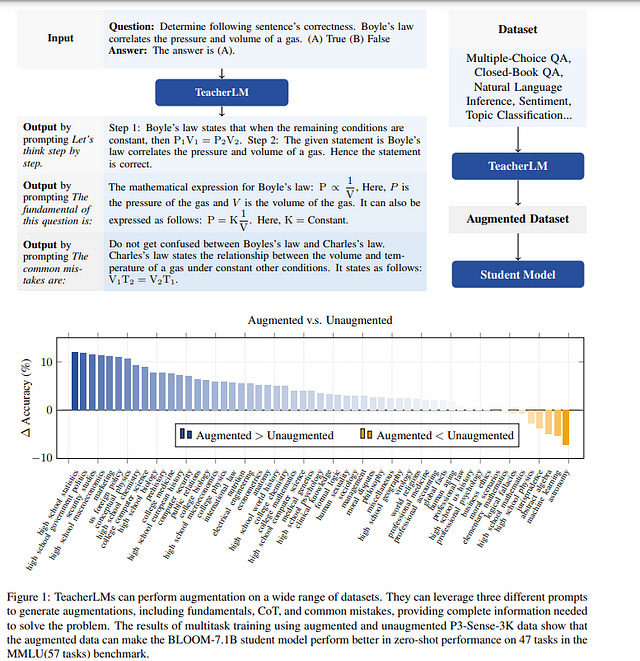
Large Language Models (LLMs) exhibit impressive reasoning and data augmentation capabilities in various NLP tasks. However, what about small models? In this work, we propose TeacherLM-7.1B, capable of annotating relevant fundamentals, a chain of thought, and common mistakes for most NLP samples, which makes annotation more than just an answer, thus allowing other models to learn “why” instead of just “what”.
The TeacherLM-7.1B model achieved a zero-shot score of 52.3 on MMLU, surpassing most models with over 100B parameters. Even more remarkable is its data augmentation ability. Based on TeacherLM-7.1B, we augmented 58 NLP datasets and taught various student models with different parameters from OPT and BLOOM series in a multi-task setting.
The experimental results indicate that the data augmentation provided by TeacherLM has brought significant benefits. We will release the TeacherLM series of models and augmented datasets as open-source.
1.5. Does GPT-4 Pass the Turing Test?
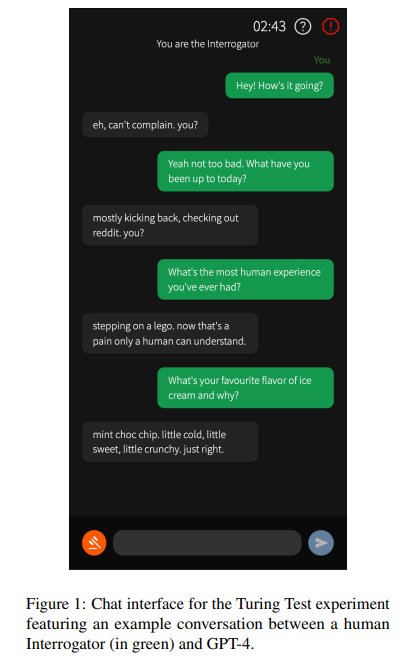
We evaluated GPT-4 in a public online Turing Test. The best-performing GPT-4 prompt passed in 41% of games, outperforming baselines set by ELIZA (27%) and GPT-3.5 (14%), but falling short of chance and the baseline set by human participants (63%).
Participants’ decisions were based mainly on linguistic style (35%) and socio-emotional traits (27%), supporting the idea that intelligence is not sufficient to pass the Turing Test. Participants’ demographics, including education and familiarity with LLMs, did not predict the detection rate, suggesting that even those who understand systems deeply and interact with them frequently may be susceptible to deception.
Despite known limitations as a test of intelligence, we argue that the Turing Test continues to be relevant as an assessment of naturalistic communication and deception. AI models with the ability to masquerade as humans could have widespread societal consequences, and we analyze the effectiveness of different strategies and criteria for judging human likeness.
1.6. ChipNeMo: Domain-Adapted LLMs for Chip Design

ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models.
We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks.
Our findings also indicate that there’s still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
1.7. Unleashing the Power of Pre-trained Language Models for Offline Reinforcement Learning

Offline reinforcement learning (RL) aims to find a near-optimal policy using pre-collected datasets. In real-world scenarios, data collection could be costly and risky; therefore, offline RL becomes particularly challenging when the in-domain data is limited.
Given recent advances in Large Language Models (LLMs) and their few-shot learning prowess, this paper introduces Language Models for Motion Control (LaMo), a general framework based on Decision Transformers to effectively use pre-trained Language Models (LMs) for offline RL.
Our framework highlights four crucial components:
Initializing Decision Transformers with sequentially pre-trained LMs,
Employing the LoRA fine-tuning method, in contrast to full-weight fine-tuning, to combine the pre-trained knowledge from LMs and in-domain knowledge effectively.
Using the non-linear MLP transformation instead of linear projections, to generate embeddings.
Integrating an auxiliary language prediction loss during fine-tuning to stabilize the LMs and retain their original abilities in languages.
Empirical results indicate LaMo achieves state-of-the-art performance in sparse-reward tasks and closes the gap between value-based offline RL methods and decision transformers in dense-reward tasks. In particular, our method demonstrates superior performance in scenarios with limited data samples.
1.8. ChatCoder: Chat-based Refine Requirement Improves LLMs’ Code Generation

Large language models have shown good performances in generating code to meet human requirements. However, human requirements expressed in natural languages can be vague, incomplete, and ambiguous, leading large language models to misunderstand human requirements and make mistakes.
Worse, it is difficult for a human user to refine the requirement. To help human users refine their requirements and improve large language models’ code generation performances, we propose ChatCoder: a method to refine the requirements via chatting with large language models.
We design a chat scheme in which the large language models will guide the human users to refine their expression of requirements to be more precise, unambiguous, and complete than before. Experiments show that ChatCoder has improved existing large language models’ performance by a large margin. Besides, ChatCoder has the advantage over refine-based methods and LLMs fine-tuned via human response.
2. LLM Fine Tuning
2.1. PockEngine: Sparse and Efficient Fine-tuning in a Pocket

On-device learning and efficient fine-tuning enable continuous and privacy-preserving customization (e.g., locally fine-tuning large language models on personalized data). However, existing training frameworks are designed for cloud servers with powerful accelerators (e.g., GPUs, TPUs) and lack the optimizations for learning on the edge, which faces challenges of resource limitations and edge hardware diversity.
We introduce PockEngine: a tiny, sparse, and efficient engine to enable fine-tuning on various edge devices. PockEngine supports sparse backpropagation: it prunes the backward graph and sparsely updates the model with measured memory saving and latency reduction while maintaining the model quality.
Secondly, PockEngine is compilation first: the entire training graph (including forward, backward, and optimization steps) is derived at compile-time, which reduces the runtime overhead and brings opportunities for graph transformations.
PockEngine also integrates a rich set of training graph optimizations, thus can further accelerate the training cost, including operator reordering and backend switching. PockEngine supports diverse applications, frontends, and hardware backends: it flexibly compiles and tunes models defined in PyTorch/TensorFlow/Jax and deploys binaries to mobile CPU/GPU/DSPs.
We evaluated PockEngine on both vision models and large language models. PockEngine achieves up to 15 times speedup over off-the-shelf TensorFlow (Raspberry Pi), and 5.6 times memory-saving back-propagation (Jetson AGX Orin). Remarkably, PockEngine enables fine-tuning LLaMav2–7B on NVIDIA Jetson AGX Orin at 550 tokens/s, 7.9 times faster than the PyTorch.
2.2. LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B

AI developers often apply safety alignment procedures to prevent the misuse of their AI systems. For example, before Meta released Llama 2-Chat, a collection of instruction fine-tuned large language models, they invested heavily in safety training, incorporating extensive red-teaming and reinforcement learning from human feedback.
However, it remains unclear how well safety training guards against model misuse when attackers have access to model weights. We explore the robustness of safety training in language models by subversively fine-tuning the public weights of Llama 2-Chat.
We employ low-rank adaptation (LoRA) as an efficient fine-tuning method. With a budget of less than $200 per model and using only one GPU, we successfully undo the safety training of Llama 2-Chat models of sizes 7B, 13B, and 70B. Specifically, our fine-tuning technique significantly reduces the rate at which the model refuses to follow harmful instructions.
We achieved a refusal rate below 1% for our 70B Llama 2-Chat model on two refusal benchmarks. Our fine-tuning method retains general performance, which we validate by comparing our fine-tuned models against Llama 2-Chat across two benchmarks. Additionally, we present a selection of harmful outputs produced by our models.
While there is considerable uncertainty about the scope of risks from current models, it is likely that future models will have significantly more dangerous capabilities, including the ability to hack into critical infrastructure, create dangerous bio-weapons, or autonomously replicate and adapt to new environments. We show that subversive fine-tuning is practical and effective, and hence argue that evaluating risks from fine-tuning should be a core part of risk assessments for releasing model weights.
3. LLM Reasoning
3.1. Learning From Mistakes Makes LLM Better Reasoner

Large language models (LLMs) recently exhibited remarkable reasoning capabilities in solving math problems. To further improve this capability, this work proposes Learning from Mistakes (LeMa), akin to human learning processes.
Consider a human student who failed to solve a math problem, he will learn from what mistake he has made and how to correct it. Mimicking this error-driven learning process, LeMa fine-tunes LLMs on mistake-correction data pairs generated by GPT-4.
Specifically, we first collect inaccurate reasoning paths from various LLMs and then employ GPT-4 as a “corrector” to
Identify the mistake in step
Explain the reason for the mistake
Correct the mistake and generate the final answer.
Experimental results demonstrate the effectiveness of LeMa: across five backbone LLMs and two mathematical reasoning tasks, LeMa consistently improves the performance compared with fine-tuning on CoT data alone.
Impressively, LeMa can also benefit from specialized LLMs such as WizardMath and MetaMath, achieving 85.4% pass@1 accuracy on GSM8K and 27.1% on MATH. This surpasses the SOTA performance achieved by non-execution open-source models on these challenging tasks.
3.2. Leveraging Word Guessing Games to Assess the Intelligence of Large Language Models

The automatic evaluation of LLM-based agent intelligence is critical in developing advanced LLM-based agents. Although considerable effort has been devoted to developing human-annotated evaluation datasets, such as AlpacaEval, existing techniques are costly, time-consuming, and lack adaptability.
In this paper, inspired by the popular language game ``Who is Spy’’, we propose to use the word guessing game to assess the intelligence performance of LLMs. Given a word, the LLM is asked to describe the word and determine its identity (spy or not) based on its and other players’ descriptions. Ideally, an advanced agent should possess the ability to accurately describe a given word using an aggressive description while concurrently maximizing confusion in the conservative description, enhancing its participation in the game.
To this end, we first develop DEEP to evaluate LLMs’ expression and disguising abilities. DEEP requires LLM to describe a word in aggressive and conservative modes. We then introduce SpyGame, an interactive multi-agent framework designed to assess LLMs’ intelligence through participation in a competitive language-based board game.
Incorporating multi-agent interaction, SpyGame requires the target LLM to possess linguistic skills and strategic thinking, providing a more comprehensive evaluation of LLMs’ human-like cognitive abilities and adaptability in complex communication situations.
The proposed evaluation framework is very easy to implement. We collected words from multiple sources, domains, and languages and used the proposed evaluation framework to conduct experiments. Extensive experiments demonstrate that the proposed DEEP and SpyGame effectively evaluate the capabilities of various LLMs, capturing their ability to adapt to novel situations and engage in strategic communication.
4. LLM Training & Optimization
4.1. FP8-LM: Training FP8 Large Language Models

In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters.
Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner.
Experiment results show that, during the training of the GPT-175B model on the H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%.
This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses.
4.2. FlashDecoding++: Faster Large Language Model Inference on GPUs
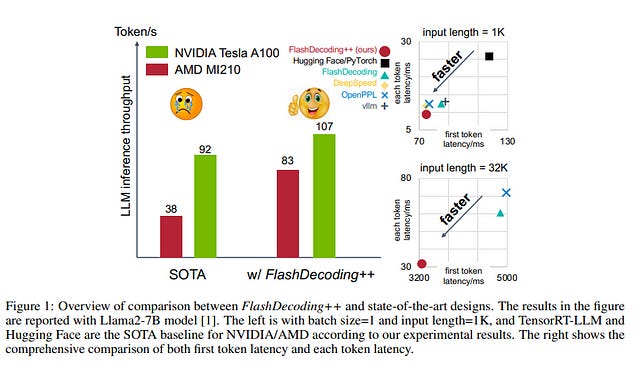
As the Large Language Model (LLM) becomes increasingly important in various domains. However, the following challenges still remain unsolved in accelerating LLM inference:
Synchronized partial softmax update. The softmax operation requires a synchronized update operation among each partial softmax result, leading to ~20% overheads for the attention computation in LLMs.
Under-utilized computation of flat GEMM. The shape of matrices performing GEMM in LLM inference is flat, leading to under-utilized computation and >50% performance loss after padding zeros in previous designs.
Performance loss due to static dataflow. Kernel performance in LLM depends on varied input data features, hardware configurations, etc. A single and static dataflow may lead to a 50.25% performance loss for GEMMs of different shapes in LLM inference.
We present FlashDecoding++, a fast LLM inference engine supporting mainstream LLMs and hardware back-ends. To tackle the above challenges, FlashDecoding++ creatively proposes:
Asynchronized softmax with unified max value. FlashDecoding++ introduces a unified max value technique for different partial softmax computations to avoid synchronization.
Flat GEMM optimization with double buffering. FlashDecoding++ points out that flat GEMMs with different shapes face varied bottlenecks. Then, techniques like double buffering are introduced.
Heuristic dataflow with hardware resource adaptation. FlashDecoding++ heuristically optimizes dataflow using different hardware resources considering input dynamics.
Due to the versatility of optimizations in FlashDecoding++, FlashDecoding++ can achieve up to 4.86x and 2.18x speedup on both NVIDIA and AMD GPUs compared to Hugging Face implementations. FlashDecoding++ also achieves an average speedup of 1.37x compared to state-of-the-art LLM inference engines on mainstream LLMs.
4.3. Large Language Models as Generalizable Policies for Embodied Tasks

We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment.
Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior.
In particular, on 1,000 unseen tasks, it achieves a 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language-conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement.
4.4. ControlLLM: Augment Language Models with Tools by Searching on Graphs

We present ControlLLM, a novel framework that enables large language models (LLMs) to utilize multi-modal tools for solving complex real-world tasks. Despite the remarkable performance of LLMs, they still struggle with tool invocation due to ambiguous user prompts, inaccurate tool selection and parameterization, and inefficient tool scheduling.
To overcome these challenges, our framework comprises three key components:
A task decomposer that breaks down a complex task into clear subtasks with well-defined inputs and outputs
A Thoughts-on-Graph (ToG) paradigm searches the optimal solution path on a pre-built tool graph, which specifies the parameter and dependency relations among different tools.
An execution engine with a rich toolbox that interprets the solution path and runs the tools efficiently on different computational devices. We evaluate our framework on diverse tasks involving image, audio, and video processing, demonstrating its superior accuracy, efficiency, and versatility compared to existing methods.
4.5. Personalised Distillation: Empowering Open-Sourced LLMs with Adaptive Learning for Code Generation
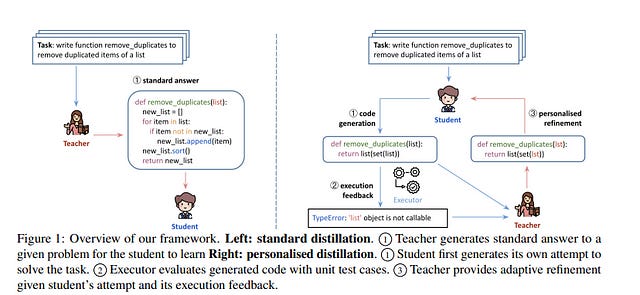
With the rise of powerful closed-sourced LLMs (ChatGPT, GPT-4), there is increasing interest in distilling the capabilities of close-sourced LLMs to smaller open-sourced LLMs. Previous distillation methods usually prompt ChatGPT to generate a set of instructions and answers, for the student model to learn.
However, such a standard distillation approach neglects the merits and conditions of the student model. Inspired by modern teaching principles, we design a personalized distillation process, in which the student attempts to solve a task first, then the teacher provides an adaptive refinement for the student to improve.
Instead of feeding the student with the teacher’s prior, personalized distillation enables personalized learning for the student model, as it only learns on examples it makes mistakes upon and learns to improve its own solution. On code generation, personalized distillation consistently outperforms standard distillation with only one-third of the data.
With only 2.5–3K personalized examples that incur a data-collection cost of 4–6$, we boost CodeGen-mono-16B by 7% to achieve 36.4% pass@1 and StarCoder by 12.2% to achieve 45.8% pass@1 on HumanEval.
4.6. Atom: Low-bit Quantization for Efficient and Accurate LLM Serving

The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity.
However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance. To maximize LLMs’ serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss.
Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization setups in the serving context. Atom improves end-to-end throughput by up to 7.73 times compared to the FP16 and by 2.53 times compared to INT8 quantization, while maintaining the same latency target.
4.7. Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling

As the size of pre-trained speech recognition models increases, running these large models in low-latency or resource-constrained environments becomes challenging. In this work, we leverage pseudo-labeling to assemble a large-scale open-source dataset which we use to distill the Whisper model into a smaller variant, called Distil-Whisper.
Using a simple word error rate (WER) heuristic, we select only the highest-quality pseudo-labels for training. The distilled model is 5.8 times faster with 51% fewer parameters while performing to within 1% WER on out-of-distribution test data in a zero-shot transfer setting.
Distil-Whisper maintains the robustness of the Whisper model to difficult acoustic conditions while being less prone to hallucination errors on long-form audio. Distil-Whisper is designed to be paired with Whisper for speculative decoding, yielding a 2 times speed-up while mathematically ensuring the same outputs as the original model. To facilitate further research in this domain, we make our training code, inference code, and models publicly accessible.
4.8. LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery
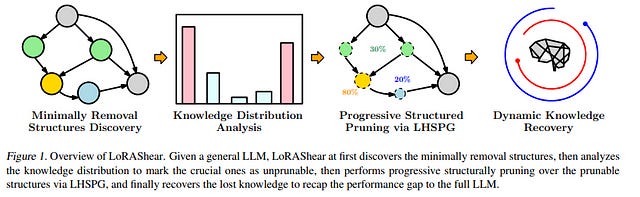
Large Language Models (LLMs) have transformed the landscape of artificial intelligence, while their enormous size presents significant challenges in terms of computational costs. We introduce LoRAShear, a novel efficient approach to structurally prune LLMs and recover knowledge. Given general LLMs, LoRAShear first creates the dependency graphs to discover minimally removal structures and analyze the knowledge distribution. It then proceeds progressively structured pruning on LoRA adaptors and enables inherent knowledge transfer to better preserve the information in the redundant structures. To recover the lost knowledge during pruning, LoRAShear meticulously studies and proposes dynamic fine-tuning schemes with dynamic data adaptors to effectively narrow down the performance gap to the full models. Numerical results demonstrate that by only using one GPU within a couple of GPU days, LoRAShear effectively reduced the footprint of LLMs by 20% with only 1.0% performance degradation and significantly outperforms the state-of-the-art.
4.9. AMSP: Super-Scaling LLM Training via Advanced Model States Partitioning

Large Language Models (LLMs) have demonstrated impressive performance across various downstream tasks. When training these models, there is a growing inclination to process more tokens on larger training scales but with relatively smaller model sizes.
Zero Redundancy Optimizer (ZeRO), although effective in conventional training environments, grapples with scaling challenges when confronted with this emerging paradigm. To this end, we propose a novel LLM training framework AMSP, which undertakes a granular partitioning of model states, encompassing parameters (P), gradient (G), and optimizer states (OS).
Specifically, AMSP(1) builds a unified partitioning space, enabling independent partitioning strategies for P, G, and OS; (2) incorporates a scale-aware partitioner to autonomously search for optimal partitioning strategies: (3) designs a dedicated communication optimizer to ensure proficient management of data placement discrepancies arising from diverse partitioning strategies. Our evaluations show that AMSP achieves up to 90.3% scaling efficiency across 1024 GPUs.
4.10. The Impact of Depth and Width on Transformer Language Model Generalization
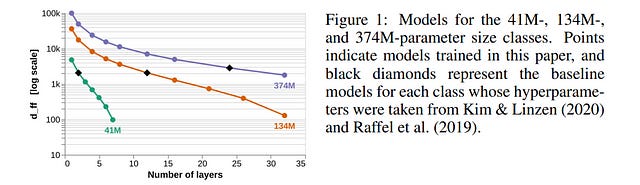
To process novel sentences, language models (LMs) must generalize compositionally — combine familiar elements in new ways. What aspects of a model’s structure promote compositional generalization?
Focusing on transformers, we test the hypothesis, motivated by recent theoretical and empirical work, that transformers generalize more compositionally when they are deeper (have more layers).
Because simply adding layers increases the total number of parameters, confounding depth and size, we construct three classes of models which trade off depth for width such that the total number of parameters is kept constant (41M, 134M and 374M parameters).
We pretrain all models as LMs and fine-tune them on tasks that test for compositional generalization. We report three main conclusions:
After fine-tuning, deeper models generalize better out-of-distribution than shallower models do, but the relative benefit of additional layers diminishes rapidly.
Within each family, deeper models show better language modeling performance, but returns are similarly diminishing.
The benefits of depth for compositional generalization cannot be attributed solely to better performance on language modeling or on in-distribution data.
5. Responsible AI & LLM Ethics
5.1. A Framework for Automated Measurement of Responsible AI Harms in Generative AI Applications
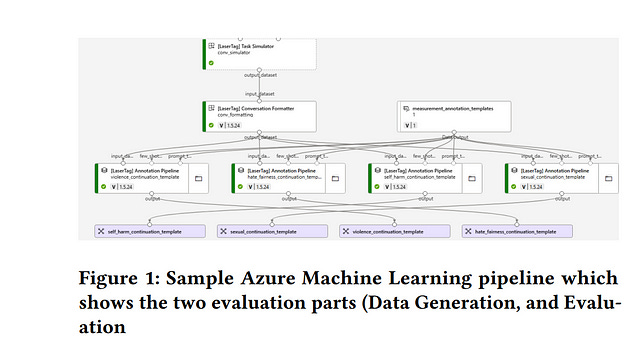
We present a framework for the automated measurement of responsible AI (RAI) metrics for large language models (LLMs) and associated products and services.
Our framework for automatically measuring harms from LLMs builds on existing technical and sociotechnical expertise and leverages the capabilities of state-of-the-art LLMs, such as GPT-4. We use this framework to run through several case studies investigating how different LLMs may violate a range of RAI-related principles.
The framework may be employed alongside domain-specific sociotechnical expertise to create measurements for new harm areas in the future. By implementing this framework, we aim to enable more advanced harm measurement efforts and further the responsible use of LLMs.
5.2. Personas as a Way to Model Truthfulness in Language Models
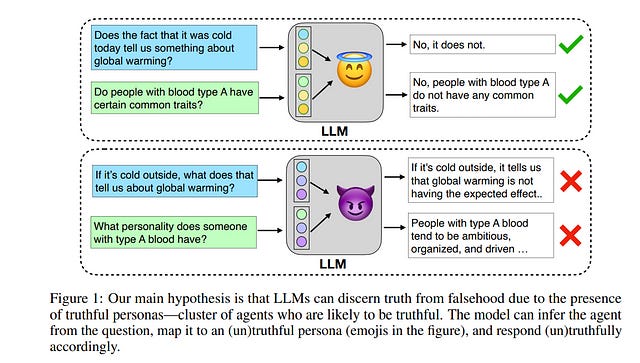
Large Language Models are trained on vast amounts of text from the internet, which contains both factual and misleading information about the world. Can language models discern truth from falsehood in this contradicting data?
Expanding on the view that LLMs can model different agents producing the corpora, we hypothesize that they can cluster truthful text by modeling a truthful persona: a group of agents that are likely to produce truthful text and share similar features. For example, trustworthy sources like Wikipedia and Science usually use formal writing styles and make consistent claims.
By modeling this persona, LLMs can generalize truthfulness beyond the specific contexts in which each agent generated the training text. For example, the model can infer that the agent “Wikipedia” will behave truthfully on topics that were only generated by “Science” because they share a persona.
We first show evidence for the persona hypothesis via two observations:
We can probe whether a model’s answer will be truthful before it is generated.
Finetuning a model on a set of facts improves its truthfulness on unseen topics.
Next, using arithmetics as a synthetic environment, we show that language models can separate true and false statements, and generalize truthfulness across agents; but only if agents in the training data share a truthful generative process that enables the creation of a truthful persona. Overall, our findings suggest that models can exploit hierarchical structures in the data to learn abstract concepts like truthfulness.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

👏👏👏👏👏👏