


Top Important LLM Papers for the Week from 23/10 to 29/10
Stay Relevant to Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, it’s important for researchers and engineers to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Fourth week of October.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. LLM Progress & Benchmarking
1.1. Let’s Synthesize Step by Step: Iterative Dataset Synthesis with Large Language Models by Extrapolating Errors from Small Models

Data Synthesis is a promising way to train a small model with very little labeled data. One approach for data synthesis is to leverage the rich knowledge from large language models to synthesize pseudo-training examples for small models, making it possible to achieve both data and compute efficiency at the same time.
However, a key challenge in data synthesis is that the synthesized dataset often suffers from a large distributional discrepancy from the *real task* data distribution. Thus, in this paper, we propose *Synthesis Step by Step* (**S3**), a data synthesis framework that shrinks this distribution gap by iteratively extrapolating the errors made by a small model trained on the synthesized dataset on a small real-world validation dataset using a large language model.
Extensive experiments on multiple NLP tasks show that our approach improves the performance of a small model by reducing the gap between the synthetic dataset and the real data, resulting in significant improvement compared to several baselines: 9.48% improvement compared to ZeroGen and 2.73% compared to GoldGen, and at most 15.17% improvement compared to the small model trained on human-annotated data.
1.2. Teaching Language Models to Self-Improve through Interactive Demonstrations

The self-improving ability of large language models (LLMs), enabled by prompting them to analyze and revise their own outputs, has garnered significant interest in recent research. However, this ability has been shown to be absent and difficult to learn for smaller models, thus widening the performance gap between state-of-the-art LLMs and more cost-effective and faster ones.
To reduce this gap, we introduce TriPosT, a training algorithm that endows smaller models with such self-improvement ability, and show that our approach can improve an LLaMA-7b’s performance on math and reasoning tasks by up to 7.13%. In contrast to prior work, we achieve this by using the smaller model to interact with LLMs to collect feedback and improvements on its own generations.
We then replay this experience to train the small model. Our experiments on four math and reasoning datasets show that the interactive experience of learning from and correcting its own mistakes is crucial for small models to improve their performance.
1.3. SALMONN: Towards Generic Hearing Abilities for Large Language Models

Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music.
In this paper, we propose SALMONN, a speech-audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model.
SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning, etc.
SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, speech audio co-reasoning, etc.
The presence of the cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities of SALMONN. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities.
1.4. JudgeLM: Fine-tuned Large Language Models are Scalable Judges

Evaluating Large Language Models (LLMs) in open-ended scenarios is challenging because existing benchmarks and metrics can not measure them comprehensively. To address this problem, we propose to fine-tune LLMs as scalable judges (JudgeLM) to evaluate LLMs efficiently and effectively in open-ended benchmarks.
We first propose a comprehensive, large-scale, high-quality dataset containing task seeds, LLMs-generated answers, and GPT-4-generated judgments for fine-tuning high-performance judges, as well as a new benchmark for evaluating the judges. We train JudgeLM at different scales from 7B, 13B, to 33B parameters, and conduct a systematic analysis of its capabilities and behaviors.
We then analyze the key biases in fine-tuning LLM as a judge and consider them as position bias, knowledge bias, and format bias. To address these issues, JudgeLM introduces a bag of techniques including swap augmentation, reference support, and reference drop, which clearly enhance the judge’s performance.
JudgeLM obtains the state-of-the-art judge performance on both the existing PandaLM benchmark and our proposed new benchmark. Our JudgeLM is efficient and the JudgeLM-7B only needs 3 minutes to judge 5K samples with 8 A100 GPUs. JudgeLM obtains high agreement with the teacher judge, achieving an agreement exceeding 90% that even surpasses human-to-human agreement.
JudgeLM also demonstrates extended capabilities in being judges of the single answer, multimodal models, multiple answers, and multi-turn chat.
1.5. H2O Open Ecosystem for State-of-the-art Large Language Models

Large Language Models (LLMs) represent a revolution in AI. However, they also pose many significant risks, such as the presence of biased, private, copyrighted, or harmful text. For this reason, we need open, transparent, and safe solutions.
We introduce a complete open-source ecosystem for developing and testing LLMs. The goal of this project is to boost open alternatives to closed-source approaches. We release h2oGPT, a family of fine-tuned LLMs from 7 to 70 Billion parameters.
We also introduce H2O LLM Studio, a framework and no-code GUI designed for efficient fine-tuning, evaluation, and deployment of LLMs using the most recent state-of-the-art techniques. Our code and models are licensed under fully permissive Apache 2.0 licenses. We believe open-source language models help to boost AI development and make it more accessible and trustworthy.
1.6. InstructExcel: A Benchmark for Natural Language Instruction in Excel

With the evolution of Large Language Models (LLMs), we can solve increasingly more complex NLP tasks across various domains, including spreadsheets. This work investigates whether LLMs can generate code (Excel OfficeScripts, a TypeScript API for executing many tasks in Excel) that solves Excel-specific tasks provided via natural language user instructions.
To do so we introduce a new large-scale benchmark, InstructExcel, created by leveraging the ‘Automate’ feature in Excel to automatically generate OfficeScripts from users’ actions. Our benchmark includes over 10k samples covering 170+ Excel operations across 2,000 publicly available Excel spreadsheets.
Experiments across various zero-shot and few-shot settings show that InstructExcel is a hard benchmark for state-of-the-art models like GPT-4. We observe that (1) using GPT-4 over GPT-3.5, (2) providing more in-context examples, and (3) dynamic prompting can help improve performance on this benchmark.
1.7. Exploring the Boundaries of GPT-4 in Radiology
The recent success of general-domain large language models (LLMs) has significantly changed the natural language processing paradigm towards a unified foundation model across domains and applications. In this paper, we focus on assessing the performance of GPT-4, the most capable LLM so far, on the text-based applications for radiology reports, comparing against state-of-the-art (SOTA) radiology-specific models.
Exploring various prompting strategies, we evaluated GPT-4 on a diverse range of common radiology tasks and we found GPT-4 either outperforms or is on par with current SOTA radiology models. With zero-shot prompting, GPT-4 already obtains substantial gains (approx 10% absolute improvement) over radiology models in temporal sentence similarity classification (accuracy) and natural language inference (F_1). For tasks that require learning dataset-specific style or schema (e.g. findings summarisation), GPT-4 improves with example-based prompting and matches supervised SOTA.
Our extensive error analysis with a board-certified radiologist shows GPT-4 has a sufficient level of radiology knowledge with only occasional errors in complex contexts that require nuanced domain knowledge. For findings summarisation, GPT-4 outputs are found to be overall comparable with existing manually-written impressions.
1.8. Detecting Pretraining Data from Large Language Models
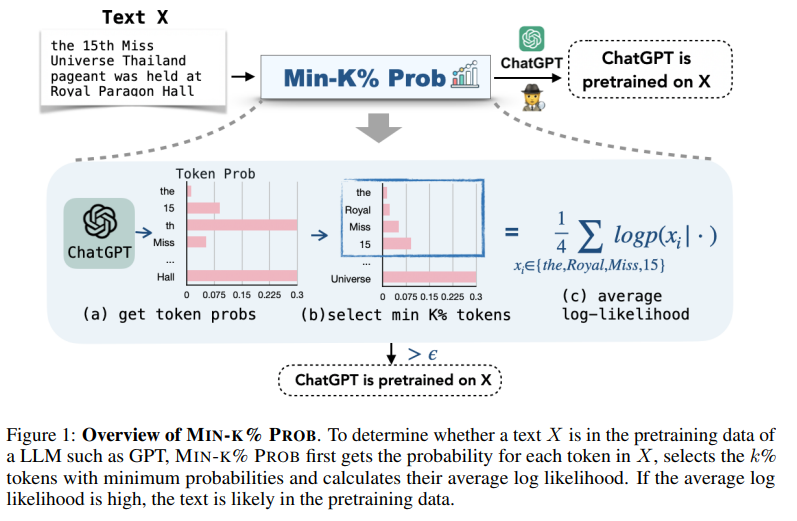
Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it is all but certain that it includes potentially problematic text such as copyrighted materials, personally identifiable information, and test data for widely reported reference benchmarks.
However, we currently have no way to know which data of these types is included or in what proportions. In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM without knowing the pretraining data, can we determine if the model was trained on the provided text?
To facilitate this study, we introduce a dynamic benchmark WIKIMIA that uses data created before and after model training to support gold truth detection. We also introduce a new detection method Min-K% Prob based on a simple hypothesis: an unseen example is likely to contain a few outlier words with low probabilities under the LLM, while a seen example is less likely to have words with such low probabilities.
Min-K% Prob can be applied without any knowledge about the pretraining corpus or any additional training, departing from previous detection methods that require training a reference model on data that is similar to the pretraining data.
Moreover, our experiments demonstrate that Min-K% Prob achieves a 7.4% improvement on WIKIMIA over these previous methods. We apply Min-K% Prob to two real-world scenarios, copyrighted book detection, and contaminated downstream example detection, and find it a consistently effective solution.
1.9. LightSpeed: Light and Fast Neural Light Fields on Mobile Devices

Real-time novel-view image synthesis on mobile devices is prohibitive due to the limited computational power and storage. Using volumetric rendering methods, such as NeRF and its derivatives, on mobile devices is not suitable due to the high computational cost of volumetric rendering.
On the other hand, recent advances in neural light field representations have shown promising real-time view synthesis results on mobile devices. Neural light field methods learn a direct mapping from a ray representation to the pixel color.
The current choice of ray representation is either stratified ray sampling or Pl\”{u}cker coordinates, overlooking the classic light slab (two-plane) representation, the preferred representation to interpolate between light field views.
In this work, we find that using the light slab representation is an efficient representation for learning a neural light field. More importantly, it is a lower-dimensional ray representation enabling us to learn the 4D ray space using feature grids which are significantly faster to train and render.
Although mostly designed for frontal views, we show that the light-slab representation can be further extended to non-frontal scenes using a divide-and-conquer strategy. Our method offers superior rendering quality compared to previous light field methods and achieves a significantly improved trade-off between rendering quality and speed.
1.10 ToolChain*: Efficient Action Space Navigation in Large Language Models with A* Search

Large language models (LLMs) have demonstrated powerful decision-making and planning capabilities in solving complicated real-world problems. LLM-based autonomous agents can interact with diverse tools (e.g., functional APIs) and generate solution plans that execute a series of API function calls in a step-by-step manner.
The multitude of candidate API function calls significantly expands the action space, amplifying the critical need for efficient action space navigation. However, existing methods either struggle with unidirectional exploration in expansive action spaces, trapped into a locally optimal solution, or suffer from exhaustively traversing all potential actions, causing inefficient navigation. To address these issues, we propose ToolChain*, an efficient tree search-based planning algorithm for LLM-based agents.
It formulates the entire action space as a decision tree, where each node represents a possible API function call involved in a solution plan. By incorporating the A* search algorithm with task-specific cost function design, it efficiently prunes high-cost branches that may involve incorrect actions, identifying the most low-cost valid path as the solution.
Extensive experiments on multiple tool-use and reasoning tasks demonstrate that ToolChain* efficiently balances exploration and exploitation within an expansive action space. It outperforms state-of-the-art baselines on planning and reasoning tasks by 3.1% and 3.5% on average while requiring 7.35x and 2.31x less time, respectively.
1.11. TD-MPC2: Scalable, Robust World Models for Continuous Control
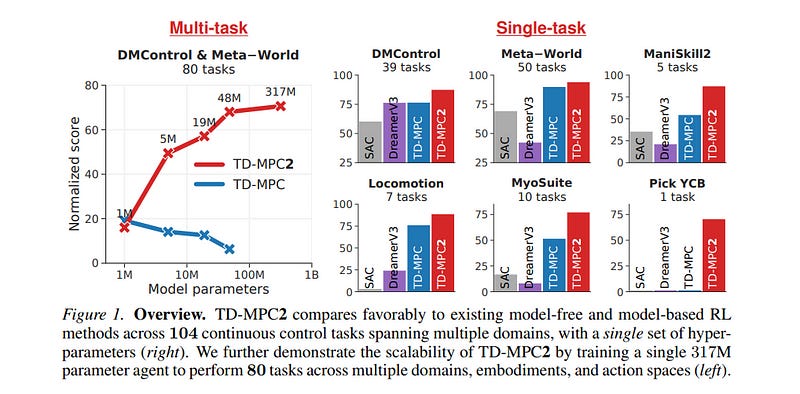
TD-MPC is a model-based reinforcement learning (RL) algorithm that performs local trajectory optimization in the latent space of a learned implicit (decoder-free) world model. In this work, we present TD-MPC2: a series of improvements to the TD-MPC algorithm.
We demonstrate that TD-MPC2 improves significantly over baselines across 104 online RL tasks spanning 4 diverse task domains, achieving consistently strong results with a single set of hyperparameters. We further show that agent capabilities increase with model and data size, and successfully train a single 317M parameter agent to perform 80 tasks across multiple task domains, embodiments, and action spaces. We conclude with an account of lessons, opportunities, and risks associated with large TD-MPC2 agents.
1.12. CLEX: Continuous Length Extrapolation for Large Language Models

Transformer-based Large Language Models (LLMs) are pioneering advances in many natural language processing tasks, however, their exceptional capabilities are restricted within the preset context window of Transformer. Position Embedding (PE) scaling methods, while effective in extending the context window to a specific length, demonstrate either notable limitations in their extrapolation abilities or sacrificing partial performance within the context window.
Length extrapolation methods, although theoretically capable of extending the context window beyond the training sequence length, often underperform in practical long-context applications. To address these challenges, we propose Continuous Length EXtrapolation (CLEX) for LLMs. We generalize the PE scaling approaches to model the continuous dynamics by ordinary differential equations over the length scaling factor, thereby overcoming the constraints of current PE scaling methods designed for specific lengths.
Moreover, by extending the dynamics to desired context lengths beyond the training sequence length, CLEX facilitates the length extrapolation with impressive performance in practical tasks. We demonstrate that CLEX can be seamlessly incorporated into LLMs equipped with Rotary Position Embedding, such as LLaMA and GPT-NeoX, with negligible impact on training and inference latency.
Experimental results reveal that CLEX can effectively extend the context window to over 4x or almost 8x training length, with no deterioration in performance. Furthermore, when evaluated on the practical LongBench benchmark, our model trained on a 4k length exhibits competitive performance against state-of-the-art open-source models trained on context lengths up to 32k.
1.13. Woodpecker: Hallucination Correction for Multimodal Large Language Models

Hallucination is a big shadow hanging over the rapidly evolving Multimodal Large Language Models (MLLMs), referring to the phenomenon that the generated text is inconsistent with the image content.
In order to mitigate hallucinations, existing studies mainly resort to an instruction-tuning manner that requires retraining the models with specific data. In this paper, we pave a different way, introducing a training-free method named Woodpecker.
Like a woodpecker heals trees, it picks out and corrects hallucinations from the generated text. Concretely, Woodpecker consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction.
Implemented in a post-remedy manner, Woodpecker can easily serve different MLLMs, while being interpretable by accessing intermediate outputs of the five stages. We evaluate Woodpecker both quantitatively and qualitatively and show the huge potential of this new paradigm. On the POPE benchmark, our method obtains a 30.66%/24.33% improvement in accuracy over the baseline MiniGPT-4/mPLUG-Owl.
2. LLM Fine Tuning
2.1. Tuna: Instruction Tuning using Feedback from Large Language Models

Instruction tuning of open-source large language models (LLMs) like LLaMA, using direct outputs from more powerful LLMs such as Instruct-GPT and GPT-4, has proven to be a cost-effective way to align model behaviors with human preferences. However, the instruction-tuned model has only seen one response per instruction, lacking the knowledge of potentially better responses.
In this paper, we propose finetuning an instruction-tuned LLM using our novel probabilistic ranking and contextual ranking approaches to increase the likelihood of generating better responses. Probabilistic ranking enables the instruction-tuned model to inherit the relative rankings of high-quality and low-quality responses from the teacher LLM.
On the other hand, learning with contextual ranking allows the model to refine its own response distribution using the contextual understanding ability of stronger LLMs. Furthermore, we apply probabilistic ranking and contextual ranking sequentially to the instruction-tuned LLM. The resulting model, which we call Tuna, consistently improves the performance on Super Natural Instructions (119 test tasks), LMentry (25 test tasks), and Vicuna QA, and can even obtain better results than several strong reinforcement learning baselines.
2.2. Ensemble-Instruct: Generating Instruction-Tuning Data with a Heterogeneous Mixture of LMs

Using in-context learning (ICL) for data generation, techniques such as Self-Instruct (Wang et al., 2023) or the follow-up Alpaca (Taori et al., 2023) can train strong conversational agents with only a small amount of human supervision. One limitation of these approaches is that they resort to very large language models (around 175B parameters) that are also proprietary and non-public.
Here we explore the application of such techniques to language models that are much smaller (around 10B — 40B parameters) and have permissive licenses. We find the Self-Instruct approach to be less effective at these sizes and propose new ICL methods that draw on two main ideas: (a) Categorization and simplification of the ICL templates to make prompt learning easier for the LM, and (b) Ensembling over multiple LM outputs to help select high-quality synthetic examples.
Our algorithm leverages the 175 Self-Instruct seed tasks and employs separate pipelines for instructions that require input and instructions that do not. Empirical investigations with different LMs show that:
Our proposed method yields higher-quality instruction tuning data than Self-Instruct.
It improves the performances of both vanilla and instruction-tuned LMs by significant margins.
Smaller instruction-tuned LMs generate more useful outputs than their larger un-tuned counterparts.
3. Text Generation & Summarization
3.1. Auto-Instruct: Automatic Instruction Generation and Ranking for Black-Box Language Models
Large language models (LLMs) can perform a wide range of tasks by following natural language instructions, without the necessity of task-specific fine-tuning. Unfortunately, the performance of LLMs is greatly influenced by the quality of these instructions, and manually writing effective instructions for each task is a laborious and subjective process.
In this paper, we introduce Auto-Instruct, a novel method to automatically improve the quality of instructions provided to LLMs. Our method leverages the inherent generative ability of LLMs to produce diverse candidate instructions for a given task and then ranks them using a scoring model trained on a variety of 575 existing NLP tasks.
In experiments on 118 out-of-domain tasks, Auto-Instruct surpasses both human-written instructions and existing baselines of LLM-generated instructions. Furthermore, our method exhibits notable generalizability even with other LLMs that are not incorporated into its training process.
4. Reinforcement Learning from Human Feedback (RLHF)
4.1. Contrastive Prefence Learning: Learning from Human Feedback without RL

Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for aligning models with human intent. Typically RLHF algorithms operate in two phases: first, use human preferences to learn a reward function, and second, align the model by optimizing the learned reward via reinforcement learning (RL).
This paradigm assumes that human preferences are distributed according to reward, but recent work suggests that they instead follow regret under the user’s optimal policy. Thus, learning a reward function from feedback is not only based on a flawed assumption of human preference, but also leads to unwieldy optimization challenges that stem from policy gradients or bootstrapping in the RL phase.
Because of these optimization challenges, contemporary RLHF methods restrict themselves to contextual bandit settings (e.g., as in large language models) or limit observation dimensionality (e.g., state-based robotics). We overcome these limitations by introducing a new family of algorithms for optimizing behavior from human feedback using the regret-based model of human preferences.
Using the principle of maximum entropy, we derive Contrastive Preference Learning (CPL), an algorithm for learning optimal policies from preferences without learning reward functions, circumventing the need for RL. CPL is fully off-policy, uses only a simple contrastive objective, and can be applied to arbitrary MDPs. This enables CPL to elegantly scale to high-dimensional and sequential RLHF problems while being simpler than prior methods.
5. LLM Reasoning
5.1. Democratizing Reasoning Ability: Tailored Learning from Large Language Model

Large language models (LLMs) exhibit impressive emergent abilities in natural language processing, but their democratization is hindered due to huge computation requirements and closed-source nature. Recent research on advancing open-source smaller LMs by distilling knowledge from black-box LLMs has obtained promising results in the instruction-following ability.
However, the reasoning ability which is more challenging to foster, is relatively rarely explored. In this paper, we propose a tailored learning approach to distill such reasoning ability to smaller LMs to facilitate the democratization of the exclusive reasoning ability. In contrast to merely employing LLM as a data annotator, we exploit the potential of LLM as a reasoning teacher by building an interactive multi-round learning paradigm.
This paradigm enables the student to expose its deficiencies to the black-box teacher who then can provide customized training data in return. Further, to exploit the reasoning potential of the smaller LM, we propose self-reflection learning to motivate the student to learn from self-made mistakes.
The learning from self-reflection and LLM are all tailored to the student’s learning status, thanks to the seamless integration with the multi-round learning paradigm. Comprehensive experiments and analysis on mathematical and commonsense reasoning tasks demonstrate the effectiveness of our method.
5.2. Towards Understanding Sycophancy in Language Models

Reinforcement learning from human feedback (RLHF) is a popular technique for training high-quality AI assistants. However, RLHF may also encourage model responses that match user beliefs over truthful responses, a behavior known as sycophancy. We investigate the prevalence of sycophancy in RLHF-trained models and whether human preference judgments are responsible.
We first demonstrate that five state-of-the-art AI assistants consistently exhibit sycophantic behavior across four varied free-form text-generation tasks. To understand if human preferences drive this broadly observed behavior of RLHF models, we analyze existing human preference data. We find that when a response matches a user’s views, it is more likely to be preferred. Moreover, both humans and preference models (PMs) prefer convincingly written sycophantic responses over correct ones a negligible fraction of the time.
Optimizing model outputs against PMs also sometimes sacrifices truthfulness in favor of sycophancy. Overall, our results indicate that sycophancy is a general behavior of RLHF models, likely driven in part by human preference judgments favoring sycophantic responses.
6. LLM Training & Evaluation
6.1. Branch-Solve-Merge Improves Large Language Model Evaluation and Generation

Large Language Models (LLMs) are frequently used for multi-faceted language generation and evaluation tasks that involve satisfying intricate user constraints or taking into account multiple aspects and criteria. However, their performance can fall short, due to the model’s lack of coherence and inability to plan and decompose the problem.
We propose Branch-Solve-Merge (BSM), a Large Language Model program (Schlag et al., 2023) for tackling such challenging natural language tasks. It consists of branch, solve, and merge modules that are parameterized with specific prompts to the base LLM. These three modules plan a decomposition of the task into multiple parallel sub-tasks, independently solve them, and fuse the solutions to the sub-tasks. We apply our method to the tasks of LLM response evaluation and constrained text generation and evaluate its effectiveness with multiple LLMs, including Vicuna, LLaMA-2-chat, and GPT-4.
BSM improves the evaluation correctness and consistency for each LLM by enhancing human-LLM agreement by up to 26%, reducing the length and pairwise position biases by up to 50%, and allowing LLaMA-2-chat to match or outperform GPT-4 on most domains. On the constraint story generation task, BSM improves the coherence of the stories while also improving constraint satisfaction by 12%.
6.2. Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
Large language models (LLMs) with hundreds of billions of parameters have sparked a new wave of exciting AI applications. However, they are computationally expensive at inference time. Sparsity is a natural approach to reduce this cost, but existing methods either require costly retraining, have to forgo LLM’s in-context learning ability, or do not yield wall-clock time speedup on modern hardware.
We hypothesize that contextual sparsity, which are small, input-dependent sets of attention heads and MLP parameters that yield approximately the same output as the dense model for a given input, can address these issues. We show that contextual sparsity exists, that it can be accurately predicted, and that we can exploit it to speed up LLM inference in wall-clock time without compromising LLM’s quality or in-context learning ability.
Based on these insights, we propose Deja Vu, a system that uses a low-cost algorithm to predict contextual sparsity on the fly given inputs to each layer, along with an asynchronous and hardware-aware implementation that speeds up LLM inference. We validate that DejaVu can reduce the inference latency of OPT-175B by over 2X compared to the state-of-the-art FasterTransformer, and over 6X compared to the widely used Hugging Face implementation, without compromising model quality.
6.3. TRAMS: Training-free Memory Selection for Long-range Language Modeling
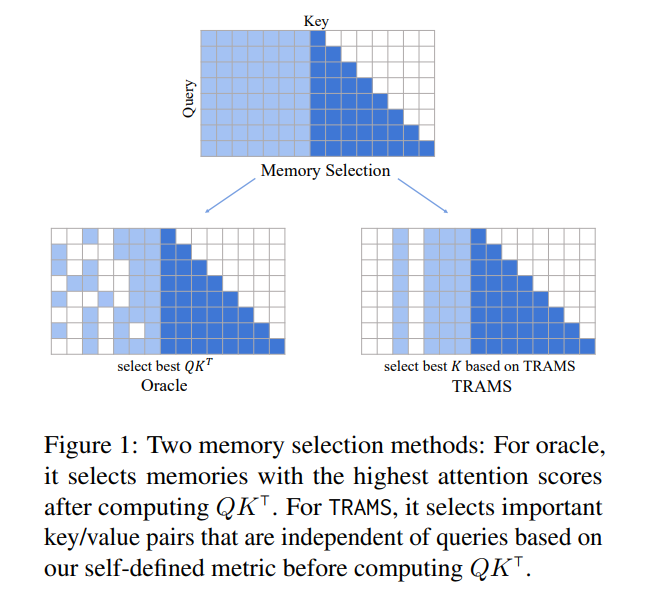
The Transformer architecture is crucial for numerous AI models, but it still faces challenges in long-range language modeling. Though several specific transformer architectures have been designed to tackle issues of long-range dependencies, existing methods like Transformer-XL are plagued by a high percentage of ineffective memories.
In this study, we present a plug-and-play strategy, known as TRAining-free Memory Selection (TRAMS), that selects tokens participating in attention calculation based on one simple metric. This strategy allows us to keep tokens that are likely to have a high attention score with the current queries and ignore the other ones.
We have tested our approach on the word-level benchmark (WikiText-103) and the character-level benchmark (enwik8), and the results indicate an improvement without having additional training or adding additional parameters.
6.4. KITAB: Evaluating LLMs on Constraint Satisfaction for Information Retrieval
We study the ability of state-of-the-art models to answer constraint satisfaction queries for information retrieval (e.g., ‘a list of ice cream shops in San Diego’). In the past, such queries were considered to be tasks that could only be solved via web searches or knowledge bases. More recently, large language models (LLMs) have demonstrated initial emergent abilities in this task.
However, many current retrieval benchmarks are either saturated or do not measure constraint satisfaction. Motivated by rising concerns around factual incorrectness and hallucinations of LLMs, we present KITAB, a new dataset for measuring constraint satisfaction abilities of language models. KITAB consists of book-related data across more than 600 authors and 13,000 queries and also offers an associated dynamic data collection and constraint verification approach for acquiring similar test data for other authors.
Our extended experiments on GPT4 and GPT3.5 characterize and decouple common failure modes across dimensions such as information popularity, constraint types, and context availability. Results show that in the absence of context, models exhibit severe limitations as measured by irrelevant information, factual errors, and incompleteness, many of which exacerbate as information popularity decreases.
While context availability mitigates irrelevant information, it is not helpful for satisfying constraints, or identifying fundamental barriers to constraint satisfaction. We open-source our contributions to foster further research on improving the constraint satisfaction abilities of future models.
7. LLM Ethical
7.1. Moral Foundations of Large Language Models
Moral foundations theory (MFT) is a psychological assessment tool that decomposes human moral reasoning into five factors, including care/harm, liberty/oppression, and sanctity/degradation (Graham et al., 2009). People vary in the weight they place on these dimensions when making moral decisions, in part due to their cultural upbringing and political ideology.
As large language models (LLMs) are trained on datasets collected from the internet, they may reflect the biases that are present in such corpora. This paper uses MFT as a lens to analyze whether popular LLMs have acquired a bias towards a particular set of moral values. We analyze known LLMs and find they exhibit particular moral foundations, and show how these relate to human moral foundations and political affiliations.
We also measure the consistency of these biases, or whether they vary strongly depending on the context of how the model is prompted. Finally, we show that we can adversarially select prompts that encourage the moral to exhibit a particular set of moral foundations and that this can affect the model’s behavior on downstream tasks. These findings help illustrate the potential risks and unintended consequences of LLMs assuming a particular moral stance.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Thanks alot