
Top Important LLM Papers for the Week from 22/04 to 28/04
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Fourth Week of April 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
LLM Optimization & Quantization
LLM Ethics & Safety
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone

We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data.
The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
1.2. How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements:
Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model — InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs.
Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448 times48 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input.
High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, and document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks.
We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks.
1.3. Multi-Head Mixture-of-Experts

Sparse Mixtures of Experts (SMoE) scales model capacity without significant increases in training and inference costs, but exhibit the following two issues:
Low expert activation, where only a small subset of experts are activated for optimization.
Lacking fine-grained analytical capabilities for multiple semantic concepts within individual tokens. We propose a Multi-Head Mixture-of-Experts (MH-MoE), which employs a multi-head mechanism to split each token into multiple sub-tokens.
These sub-tokens are then assigned to and processed by a diverse set of experts in parallel and seamlessly reintegrated into the original token form. The multi-head mechanism enables the model to collectively attend to information from various representation spaces within different experts, while significantly enhancing expert activation, thus deepening context understanding and alleviating overfitting.
Moreover, our MH-MoE is straightforward to implement and decouples from other SMoE optimization methods, making it easy to integrate with other SMoE models for enhanced performance. Extensive experimental results across three tasks: English-focused language modeling, Multi-lingual language modeling, and Masked multi-modality modeling tasks, demonstrate the effectiveness of MH-MoE.
1.4. Pegasus-v1 Technical Report
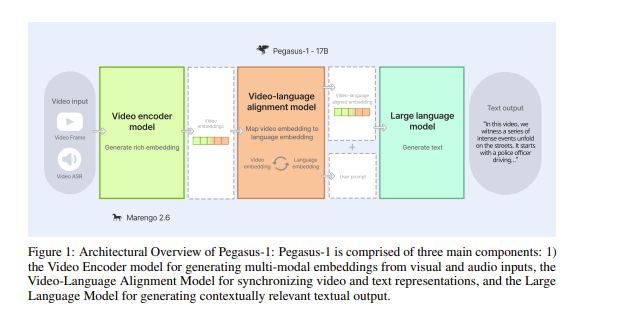
This technical report introduces Pegasus-1, a multimodal language model specialized in video content understanding and interaction through natural language.
Pegasus-1 is designed to address the unique challenges posed by video data, such as interpreting spatiotemporal information, to offer nuanced video content comprehension across various lengths.
This technical report overviews Pegasus-1’s architecture, training strategies, and performance in benchmarks on video conversation, zero-shot video question answering, and video summarization. We also explore the qualitative characteristics of Pegasus-1, demonstrating its capabilities as well as its limitations, to provide readers with a balanced view of its current state and its future direction.
1.5. LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency
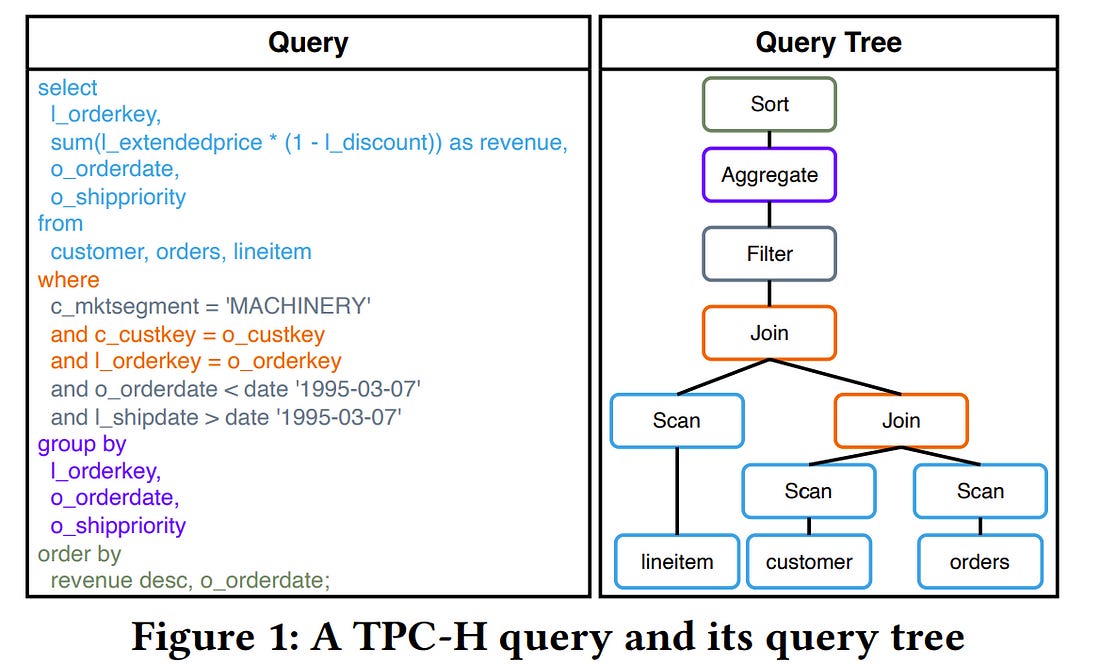
Query rewrite, which aims to generate more efficient queries by altering a SQL query’s structure without changing the query result, has been an important research problem. To maintain equivalence between the rewritten query and the original one during rewriting, traditional query rewrite methods always rewrite the queries following certain rewrite rules. However, some problems remain.
Firstly, existing methods of finding the optimal choice or sequence of rewrite rules are still limited and the process always costs a lot of resources. Methods involving discovering new rewrite rules typically require complicated proofs of structural logic or extensive user interactions.
Secondly, current query rewrite methods usually rely highly on DBMS cost estimators which are often not accurate. In this paper, we address these problems by proposing a novel method of query rewrite named LLM-R2, adopting a large language model (LLM) to propose possible rewrite rules for a database rewrite system.
To further improve the inference ability of LLM in recommending rewrite rules, we train a contrastive model by curriculum to learn query representations and select effective query demonstrations for the LLM. Experimental results have shown that our method can significantly improve the query execution efficiency and outperform the baseline methods. In addition, our method enjoys high robustness across different datasets.
1.6. AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation
Web automation is a significant technique that accomplishes complicated web tasks by automating common web actions, enhancing operational efficiency, and reducing the need for manual intervention.
Traditional methods, such as wrappers, suffer from limited adaptability and scalability when faced with a new website. On the other hand, generative agents empowered by large language models (LLMs) exhibit poor performance and reusability in open-world scenarios.
In this work, we introduce a crawler generation task for vertical information web pages and the paradigm of combining LLMs with crawlers, which helps crawlers handle diverse and changing web environments more efficiently.
We propose AutoCrawler, a two-stage framework that leverages the hierarchical structure of HTML for progressive understanding. Through top-down and step-back operations, AutoCrawler can learn from erroneous actions and continuously prune HTML for better action generation. We conduct comprehensive experiments with multiple LLMs and demonstrate the effectiveness of our framework.
1.7. FlowMind: Automatic Workflow Generation with LLMs

The rapidly evolving field of Robotic Process Automation (RPA) has made significant strides in automating repetitive processes, yet its effectiveness diminishes in scenarios requiring spontaneous or unpredictable tasks demanded by users.
This paper introduces a novel approach, FlowMind, leveraging the capabilities of Large Language Models (LLMs) such as Generative Pretrained Transformer (GPT), to address this limitation and create an automatic workflow generation system.
In FlowMind, we propose a generic prompt recipe for a lecture that helps ground LLM reasoning with reliable Application Programming Interfaces (APIs). With this, FlowMind not only mitigates the common issue of hallucinations in LLMs but also eliminates direct interaction between LLMs and proprietary data or code, thus ensuring the integrity and confidentiality of information — a cornerstone in financial services.
FlowMind further simplifies user interaction by presenting high-level descriptions of auto-generated workflows, enabling users to inspect and provide feedback effectively. We also introduce NCEN-QA, a new dataset in finance for benchmarking question-answering tasks from N-CEN reports on funds.
We used NCEN-QA to evaluate the performance of workflows generated by FlowMind against baseline and ablation variants of FlowMind. We demonstrate the success of FlowMind, the importance of each component in the proposed lecture recipe, and the effectiveness of user interaction and feedback in FlowMind.
1.8. A Multimodal Automated Interpretability Agent

This paper describes MAIA, a Multimodal Automated Interpretability Agent. MAIA is a system that uses neural models to automate neural model understanding tasks like feature interpretation and failure mode discovery. It equips a pre-trained vision-language model with a set of tools that support iterative experimentation on subcomponents of other models to explain their behavior.
These include tools commonly used by human interpretability researchers: for synthesizing and editing inputs, computing maximally activating exemplars from real-world datasets, and summarizing and describing experimental results.
Interpretability experiments proposed by MAIA compose these tools to describe and explain system behavior. We evaluate applications of MAIA to computer vision models. We first characterize MAIA’s ability to describe (neuron-level) features in learned representations of images.
Across several trained models and a novel dataset of synthetic vision neurons with paired ground-truth descriptions, MAIA produces descriptions comparable to those generated by expert human experimenters. We then show that MAIA can aid in two additional interpretability tasks: reducing sensitivity to spurious features, and automatically identifying inputs likely to be misclassified.
1.9. OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework

The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model.
OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring 2times fewer pre-training tokens.
Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations.
We also release code to convert models to the MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors.
1.10. Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models

We introduce Groma, a Multimodal Large Language Model (MLLM) with grounded and fine-grained visual perception ability. Beyond holistic image understanding, Groma is adept at region-level tasks such as region captioning and visual grounding.
Such capabilities are built upon a localized visual tokenization mechanism, where an image input is decomposed into regions of interest and subsequently encoded into region tokens. By integrating region tokens into user instructions and model responses, we seamlessly enable Groma to understand user-specified region inputs and ground its textual output to images.
Besides, to enhance the grounded chat ability of Groma, we curate a visually grounded instruction dataset by leveraging the powerful GPT-4V and visual prompting techniques.
Compared with MLLMs that rely on the language model or external module for localization, Groma consistently demonstrates superior performances in standard referring and grounding benchmarks, highlighting the advantages of embedding localization into image tokenization.
2. LLM Reasoning
2.1. Make Your LLM Fully Utilize the Context

While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information.
Based on this intuition, our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle. Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires:
Fine-grained information awareness on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens)
The integration and reasoning of information from two or more short segments.
Through applying this information-intensive training on Mistral-7B, we present FILM-7B (FILl-in-the-Middle). To thoroughly assess the ability of FILM-7B to utilize long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval).
The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window. Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU).
2.2. SnapKV: LLM Knows What You are Looking for Before Generation

Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency.
To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation.
Meanwhile, this robust pattern can be obtained from an `observation’ window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences.
Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets.
Moreover, SnapKV can process up to 380K context tokens on a single A100–80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV’s potential for practical applications.
3. LLM Training, Evaluation & Inference
3.1. The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions

Today’s LLMs are susceptible to prompt injections, jailbreaks, and other attacks that allow adversaries to overwrite a model’s original instructions with their malicious prompts.
In this work, we argue that one of the primary vulnerabilities underlying these attacks is that LLMs often consider system prompts (e.g., text from an application developer) to be the same priority as text from untrusted users and third parties.
To address this, we propose an instruction hierarchy that explicitly defines how models should behave when instructions of different priorities conflict. We then propose a data generation method to demonstrate this hierarchical instruction in the following behavior, which teaches LLMs to selectively ignore lower-privileged instructions.
We apply this method to GPT-3.5, showing that it drastically increases robustness — even for attack types not seen during training — while imposing minimal degradations on standard capabilities.
3.2. List Items One by One: A New Data Source and Learning Paradigm for Multimodal LLMs

Set-of-Mark (SoM) Prompting unleashes the visual grounding capability of GPT-4V, by enabling the model to associate visual objects with tags inserted on the image. These tags, marked with alphanumerics, can be indexed via text tokens for easy reference.
Despite the extraordinary performance from GPT-4V, we observe that other Multimodal Large Language Models (MLLMs) struggle to understand these visual tags. To promote the learning of SoM prompting for open-source models, we propose a new learning paradigm: “list items one by one,” which asks the model to enumerate and describe all visual tags placed on the image following the alphanumeric orders of tags.
By integrating our curated dataset with other visual instruction tuning datasets, we can equip existing MLLMs with the SoM prompting ability. Furthermore, we evaluate our finetuned SoM models on five MLLM benchmarks.
We find that this new dataset, even in a relatively small size (10k-30k images with tags), significantly enhances visual reasoning capabilities and reduces hallucinations for MLLMs.
Perhaps surprisingly, these improvements persist even when the visual tags are omitted from input images during inference. This suggests the potential of “list items one by one” as a new paradigm for training MLLMs, which strengthens the object-text alignment through the use of visual tags in the training stage. Finally, we conduct analyses by probing trained models to understand the working mechanism of SoM.
4. LLM Optimization & Quantization
4.1. How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study

Meta’s LLaMA family has become one of the most powerful open-source Large Language Model (LLM) series. Notably, LLaMA3 models have recently been released and achieve impressive performance across various with super-large scale pre-training on over 15T tokens of data.
Given the wide application of low-bit quantization for LLMs in resource-limited scenarios, we explore LLaMA3’s capabilities when quantized to low bit-width. This exploration holds the potential to unveil new insights and challenges for low-bit quantization of LLaMA3 and other forthcoming LLMs, especially in addressing performance degradation problems that suffer in LLM compression.
Specifically, we evaluate the 10 existing post-training quantization and LoRA-finetuning methods of LLaMA3 on 1–8 bits and diverse datasets to comprehensively reveal LLaMA3’s low-bit quantization performance. Our experiment results indicate that LLaMA3 still suffers non-negligent degradation in these scenarios, especially in ultra-low bit-width.
This highlights the significant performance gap under low bit-width that needs to be bridged in future developments. We expect that this empirical study will prove valuable in advancing future models, pushing the LLMs to lower bit-width with higher accuracy for being practical.
4.2. XC-Cache: Cross-Attending to Cached Context for Efficient LLM Inference

In-context learning (ICL) approaches typically leverage prompting to condition decoder-only language model generation on reference information.
Just-in-time processing of a context is inefficient due to the quadratic cost of self-attention operations, and caching is desirable. However, caching transformer states can easily require almost as much space as the model parameters.
When the right context isn’t known in advance, caching ICL can be challenging. This work addresses these limitations by introducing models that, inspired by the encoder-decoder architecture, use cross-attention to condition generation on reference text without the prompt.
More precisely, we leverage pre-trained decoder-only models and only train a small number of added layers. We use Question-Answering (QA) as a testbed to evaluate the ability of our models to perform conditional generation and observe that they outperform ICL, are comparable to fine-tuned prompted LLMs, and drastically reduce the space footprint relative to standard KV caching by two orders of magnitude.
5. Transformer & Attention Models
5.1. Transformers Can Represent $n$-gram Language Models

Plenty of existing work has analyzed the abilities of the transformer architecture by describing its representational capacity with formal models of computation.
However, the focus so far has been on analyzing the architecture in terms of language acceptance. We contend that this is an ill-suited problem in the study of language models (LMs), which are definitionally probability distributions over strings. In this paper, we focus on the relationship between transformer LMs and n-gram LMs, a simple and historically relevant class of language models.
We show that transformer LMs using the hard or sparse attention mechanisms can exactly represent any n-gram LM, giving us a concrete lower bound on their probabilistic representational capacity. This provides a first step towards understanding the mechanisms that transformer LMs can use to represent probability distributions over strings.
5.2. BASS: Batched Attention-optimized Speculative Sampling
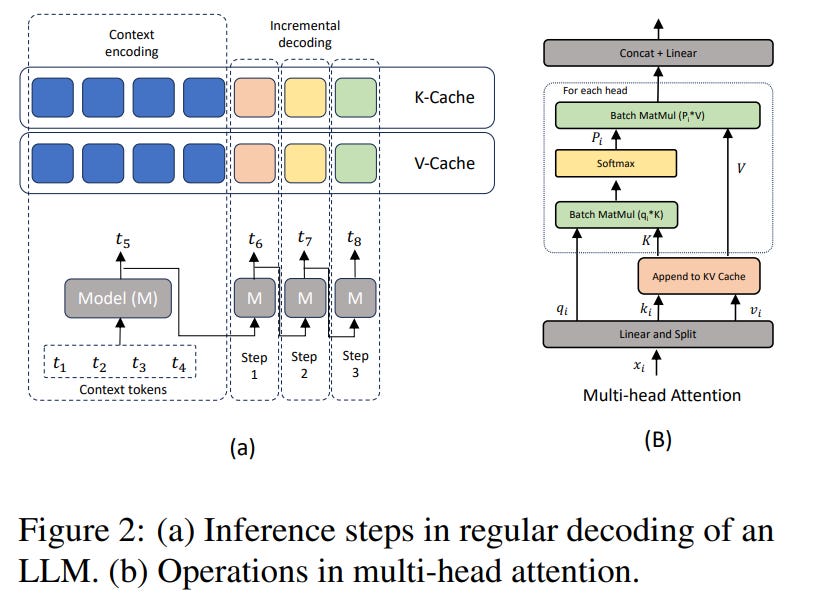
Speculative decoding has emerged as a powerful method to improve latency and throughput in hosting large language models. However, most existing implementations focus on generating a single sequence.
Real-world generative AI applications often require multiple responses and how to perform speculative decoding in a batched setting while preserving its latency benefits poses non-trivial challenges. This paper describes a system of batched speculative decoding that sets a new state-of-the-art in multi-sequence generation latency and that demonstrates superior GPU utilization as well as the quality of generations within a time budget.
For example, for a 7.8B-size model on a single A100 GPU and with a batch size of 8, each sequence is generated at an average speed of 5.8ms per token, the overall throughput being 1.1K tokens per second. These results represent state-of-the-art latency and a 2.15X speed-up over-optimized regular decoding.
Within a time budget that regular decoding does not finish, our system can generate sequences with HumanEval Pass@First of 43% and Pass@All of 61%, far exceeding what’s feasible with single-sequence speculative decoding.
Our peak GPU utilization during decoding reaches as high as 15.8%, more than 3X the highest of that of regular decoding and around 10X of single-sequence speculative decoding.
5.3. Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
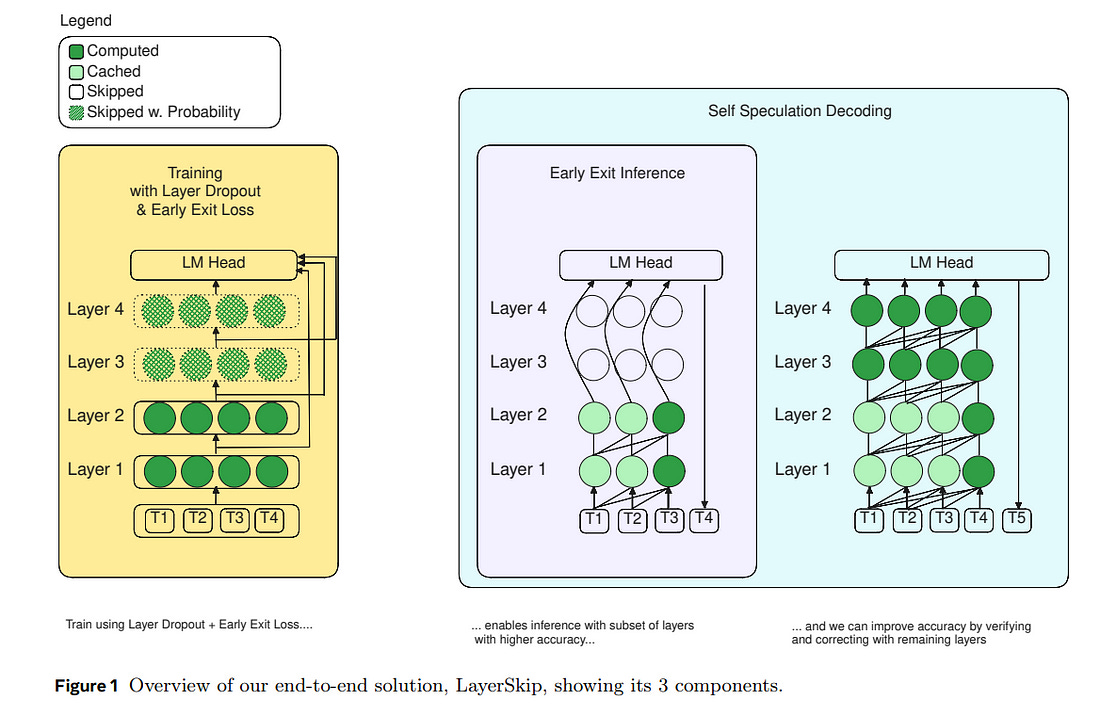
We present LayerSkip, an end-to-end solution to speed up the inference of large language models (LLMs). First, during training, we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit.
Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model.
Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared computing and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domains, and finetuning on specific tasks.
We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on the TOPv2 semantic parsing task.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
