


Top Important LLM Papers for the Week from 9/10 to 15/10
Stay Relevant to Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, it’s important for researchers and engineers to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the second week of October.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. The final sections discuss papers related to training LLMs safely and ensuring their behavior remains beneficial.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Reasoning
Text Generation & Summarization
LLM Progress & Benchmarking
LLM Fine Tuning
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. LLM Reasoning
1.1. Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
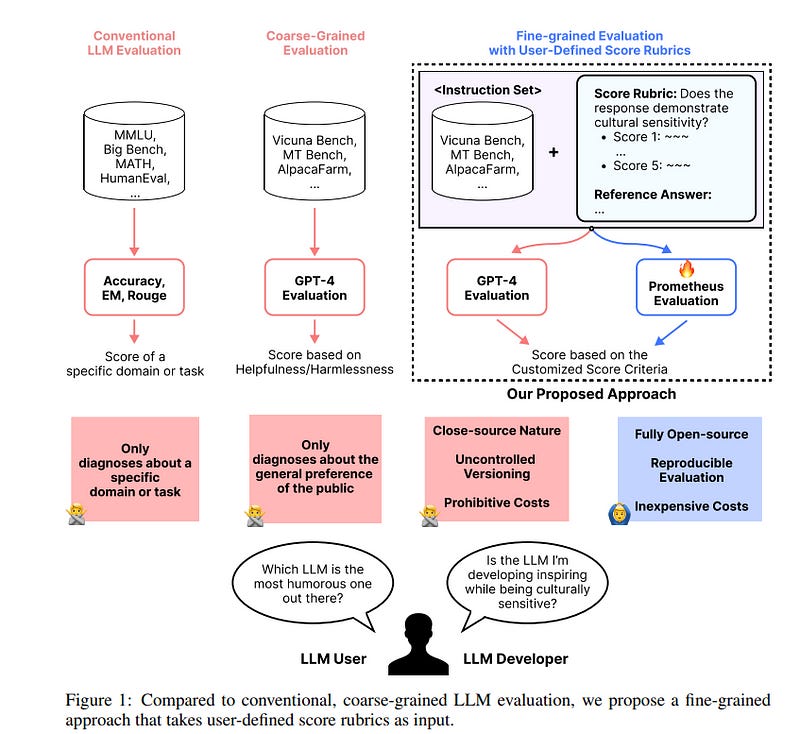
Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g., child-readability), using proprietary LLMs as an evaluator is unreliable due to the closed-source nature, uncontrolled versioning, and prohibitive costs.
In this work, authors propose Prometheus, a fully open-source LLM that is on par with GPT-4’s evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are accompanied. They first construct the Feedback Collection, a new dataset that consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4.
Using the Feedback Collection, they train Prometheus, a 13B evaluator LLM that can assess any given long-form text based on a customized score rubric provided by the user.
Experimental results show that Prometheus scores a Pearson correlation of 0.897 with human evaluators when evaluating 45 customized score rubrics, which is on par with GPT-4 (0.882), and greatly outperforms ChatGPT (0.392). Furthermore, measuring correlation with GPT-4 with 1222 customized score rubrics across four benchmarks (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval) shows similar trends, bolstering Prometheus’s capability as an evaluator LLM.
Lastly, Prometheus achieves the highest accuracy on two human preference benchmarks (HHH Alignment & MT Bench Human Judgment) compared to open-sourced reward models explicitly trained on human preference datasets, highlighting its potential as a universal reward model.
2. Text Generation & Summarization
2.1. EIPE-text: Evaluation-Guided Iterative Plan Extraction for Long-Form Narrative Text Generation
Plan-and-write is a common hierarchical approach in long-form narrative text generation, which first creates a plan to guide the narrative writing. Following this approach, several studies rely on simply prompting large language models for planning, which often yields suboptimal results.
In this paper, authors propose a new framework called Evaluation-guided Iterative Plan Extraction for long-form narrative text generation (EIPE-text), which extracts plans from the corpus of narratives and utilizes the extracted plans to construct a better planner.
EIPE-text has three stages: plan extraction, learning, and inference. In the plan extraction stage, it iteratively extracts and improves plans from the narrative corpus and constructs a plan corpus. They propose a question-answer (QA) based evaluation mechanism to automatically evaluate the plans and generate detailed plan refinement instructions to guide the iterative improvement.
In the learning stage, they build a better planner by fine-tuning with the plan corpus or in-context learning with examples in the plan corpus. Finally, we leverage a hierarchical approach to generate long-form narratives. We evaluate the effectiveness of EIPE-text in the domains of novels and storytelling.
Both GPT-4-based evaluations and human evaluations demonstrate that our method can generate more coherent and relevant long-form narratives. Our code will be released in the future.
2.2. The Consensus Game: Language Model Generation via Equilibrium Search

When applied to question answering and other text generation tasks, language models (LMs) may be queried generatively (by sampling answers from their output distribution) or discriminatively (by using them to score or rank a set of candidate outputs). These procedures sometimes yield very different predictions.
How do we reconcile mutually incompatible scoring procedures to obtain coherent LM predictions? We introduce a new, training-free, game-theoretic procedure for language model decoding.
The approach casts language model decoding as a regularized imperfect-information sequential signaling game — which we term the CONSENSUS GAME — in which a GENERATOR seeks to communicate an abstract correctness parameter using natural language sentences to a DISCRIMINATOR.
They develop computational procedures for finding approximate equilibria of this game, resulting in a decoding algorithm we call EQUILIBRIUM-RANKING. Applied to a large number of tasks (including reading comprehension, commonsense reasoning, mathematical problem-solving, and dialog), EQUILIBRIUM-RANKING consistently, and sometimes substantially, improves performance over existing LM decoding procedures — on multiple benchmarks, they observe that applying EQUILIBRIUM-RANKING to LLaMA-7B outperforms the much larger LLaMA-65B and PaLM-540B models.
These results highlight the promise of game-theoretic tools for addressing fundamental challenges of truthfulness and consistency in LMs.
3. LLM Progress & Benchmarking
3.1. Lemur: Harmonizing Natural Language and Code for Language Agents

This paper introduces Lemur and Lemur-Chat, openly accessible language models optimized for both natural language and coding capabilities to serve as the backbone of versatile language agents.
The evolution from language chat models to functional language agents demands that models not only master human interaction, reasoning, and planning but also ensure grounding in the relevant environments. This calls for a harmonious blend of language and coding capabilities in the models.
Lemur and Lemur-Chat proposed to address this necessity, demonstrating balanced proficiencies in both domains, unlike existing open-source models that tend to specialize in either. Through meticulous pre-training using a code-intensive corpus and instruction fine-tuning on text and code data, our models achieve state-of-the-art averaged performance across diverse text and coding benchmarks among open-source models.
Comprehensive experiments demonstrate Lemur’s superiority over existing open-source models and its proficiency across various agent tasks involving human communication, tool usage, and interaction under fully- and partially- observable environments.
The harmonization between natural and programming languages enables Lemur-Chat to significantly narrow the gap with proprietary models on agent abilities, providing key insights into developing advanced open-source agents adept at reasoning, planning, and operating seamlessly across environments.
3.2. Table-GPT: Table-tuned GPT for Diverse Table Tasks

Language models, such as GPT-3.5 and ChatGPT, demonstrate remarkable abilities to follow diverse human instructions and perform a wide range of tasks. However, when probing language models using a range of basic table-understanding tasks, we observe that today’s language models are still sub-optimal in many table-related tasks, likely because they are pre-trained predominantly on one-dimensional natural-language texts, whereas relational tables are two-dimensional objects.
In this work, authors propose a new “table-tuning” paradigm, where we continue to train/fine-tune language models like GPT-3.5 and ChatGPT, using diverse table tasks synthesized from real tables as training data, with the goal of enhancing language models’ ability to understand tables and perform table tasks.
They show that the resulting Table-GPT models demonstrate (1) better table-understanding capabilities, by consistently outperforming the vanilla GPT-3.5 and ChatGPT, on a wide range of table tasks, including holdout unseen tasks, and (2) strong generalizability, in its ability to respond to diverse human instructions to perform new table-tasks, in a manner similar to GPT-3.5 and ChatGPT.
3.3. A Zero-Shot Language Agent for Computer Control with Structured Reflection

Large language models (LLMs) have shown increasing capacity for planning and executing a high-level goal in a live computer environment (e.g. MiniWoB++). To perform a task, recent works often require a model to learn from trace examples of the task via either supervised learning or few/many-shot prompting.
Without these trace examples, it remains a challenge how an agent can autonomously learn and improve its control on a computer, which limits the ability of an agent to perform a new task. We approach this problem with a zero-shot agent that requires no given expert traces.
Our agent plans for executable actions on a partially observed environment, and iteratively progresses a task by identifying and learning from its mistakes via self-reflection and structured thought management. On the easy tasks of MiniWoB++, we show that our zero-shot agent often outperforms recent SoTAs, with more efficient reasoning.
For tasks with more complexity, our reflective agent performs on par with prior best models, even though previous works had the advantage of accessing expert traces or additional screen information.
3.4. Toward Joint Language Modeling for Speech Units and Text

Speech and text are two major forms of human language. The research community has been focusing on mapping speech to text or vice versa for many years. However, in the field of language modeling, very little effort has been made to model them jointly. In light of this, we explore joint language modeling for speech units and text. Specifically, we compare different speech tokenizers to transform continuous speech signals into discrete units and use different methods to construct mixed speech-text data.
We introduce automatic metrics to evaluate how well the joint LM mixes speech and text. We also fine-tune the LM on downstream spoken language understanding (SLU) tasks with different modalities (speech or text) and test its performance to assess the model’s learning of shared representations. Our results show that by mixing speech units and text with our proposed mixing techniques, the joint LM improves over a speech-only baseline on SLU tasks and shows zero-shot cross-modal transferability.
4. LLM Fine Tuning
4.1. LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models
Quantization is an indispensable technique for serving Large Language Models (LLMs) and has recently found its way into LoRA fine-tuning. In this work, we focus on the scenario where quantization and LoRA fine-tuning are applied together on a pre-trained model.
In such cases, it is common to observe a consistent gap in the performance on downstream tasks between full fine-tuning and quantization plus the LoRA fine-tuning approach. In response, we propose LoftQ (LoRA-Fine-Tuning-aware Quantization), a novel quantization framework that simultaneously quantizes an LLM and finds a proper low-rank initialization for LoRA fine-tuning.
Such an initialization alleviates the discrepancy between the quantized and full-precision model and significantly improves the generalization in downstream tasks. We evaluate our method on natural language understanding, question answering, summarization, and natural language generation tasks.
Experiments show that our method is highly effective and outperforms existing quantization methods, especially in the challenging 2-bit and 2/4-bit mixed precision regimes. We will release our code.
Thanks for sharing youssef