


Top Important LLM Papers for the Week from 25/03 to 31/03
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Fifth Week of March 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
LLM Optimization & Quantization
LLM Ethics & Safety
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. Towards a World-English Language Model for On-Device Virtual Assistants
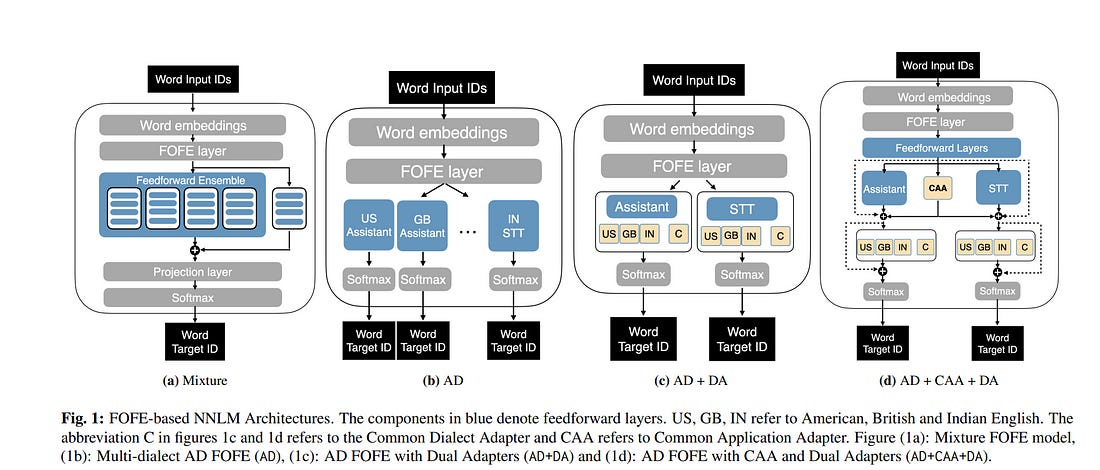
Neural Network Language Models (NNLMs) for Virtual Assistants (VAs) are generally language-, region-, and in some cases, device-dependent, which increases the effort to scale and maintain them.
Combining NNLMs for one or more of the categories is one way to improve scalability. In this work, we combine regional variants of English to build a ``World English’’ NNLM for on-device VAs.
In particular, we investigate the application of adapter bottlenecks to model dialect-specific characteristics in our existing production NNLMs {and enhance the multi-dialect baselines}.
We find that adapter modules are more effective in modeling dialects than specializing in entire sub-networks. Based on this insight and leveraging the design of our production models, we introduce a new architecture for World English NNLM that meets the accuracy, latency, and memory constraints of our single-dialect models.
1.2. RakutenAI-7B: Extending Large Language Models for Japanese

We introduce RakutenAI-7B, a Japanese-oriented large language model suite that performs best on the Japanese LM Harness benchmarks among the open 7B models.
Along with the foundation model, we release instruction- and chat-tuned models, RakutenAI-7B-instruct and RakutenAI-7B-chat respectively, under the Apache 2.0 license.
1.3. BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text

Models such as GPT-4 and Med-PaLM 2 have demonstrated impressive performance on a wide variety of biomedical NLP tasks. However, these models have hundreds of billions of parameters, are computationally expensive to run, require users to send their input data over the internet, and are trained on unknown data sources.
Can smaller, more targeted models compete? To address this question, we build and release BioMedLM, a 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles.
When fine-tuned, BioMedLM can produce strong multiple-choice biomedical question-answering results competitive with much larger models, such as achieving a score of 57.3% on MedMCQA (dev) and 69.0% on the MMLU Medical Genetics exam.
BioMedLM can also be fine-tuned to produce useful answers to patient questions on medical topics. This demonstrates that smaller models can potentially serve as transparent, privacy-preserving, economical, and environmentally friendly foundations for particular NLP applications, such as biomedicine.
1.4. Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models

In this work, we introduce Mini-Gemini, a simple and effective framework enhancing multi-modality Vision Language Models (VLMs). Despite the advancements in VLMs facilitating basic visual dialog and reasoning, a performance gap persists compared to advanced models like GPT-4 and Gemini.
We try to narrow the gap by mining the potential of VLMs for better performance and any-to-any workflow from three aspects, i.e., high-resolution visual tokens, high-quality data, and VLM-guided generation. To enhance visual tokens, we propose to utilize an additional visual encoder for high-resolution refinement without increasing the visual token count.
We further construct a high-quality dataset that promotes precise image comprehension and reasoning-based generation, expanding the operational scope of current VLMs. In general, Mini-Gemini further mines the potential of VLMs and empowers current frameworks with image understanding, reasoning, and generation simultaneously.
Mini-Gemini supports a series of dense and MoE Large Language Models (LLMs) from 2B to 34 B. It is demonstrated to achieve leading performance in several zero-shot benchmarks and even surpasses the developed private models.
1.5. AllHands: Ask Me Anything on Large-scale Verbatim Feedback via Large Language Models

Verbatim feedback constitutes a valuable repository of user experiences, opinions, and requirements essential for software development. Effectively and efficiently extracting valuable insights from such data poses a challenging task.
This paper introduces Allhands, an innovative analytic framework designed for large-scale feedback analysis through a natural language interface, leveraging large language models (LLMs).
Allhands adheres to a conventional feedback analytic workflow, initially conducting classification and topic modeling on the feedback to convert them into a structurally augmented format, incorporating LLMs to enhance accuracy, robustness, generalization, and user-friendliness.
Subsequently, an LLM agent is employed to interpret users’ diverse questions in natural language on feedback, translating them into Python code for execution, and delivering comprehensive multi-modal responses, including text, code, tables, and images.
We evaluate Allhands across three diverse feedback datasets. The experiments demonstrate that Allhands achieves superior efficacy at all stages of analysis, including classification and topic modeling, eventually providing users with an ``ask me anything’’ experience with comprehensive, correct, and human-readable responses.
To the best of our knowledge, Allhands stands as the first comprehensive feedback analysis framework that supports diverse and customized requirements for insight extraction through a natural language interface.
2. LLM Reasoning
2.1. Can large language models explore in context?
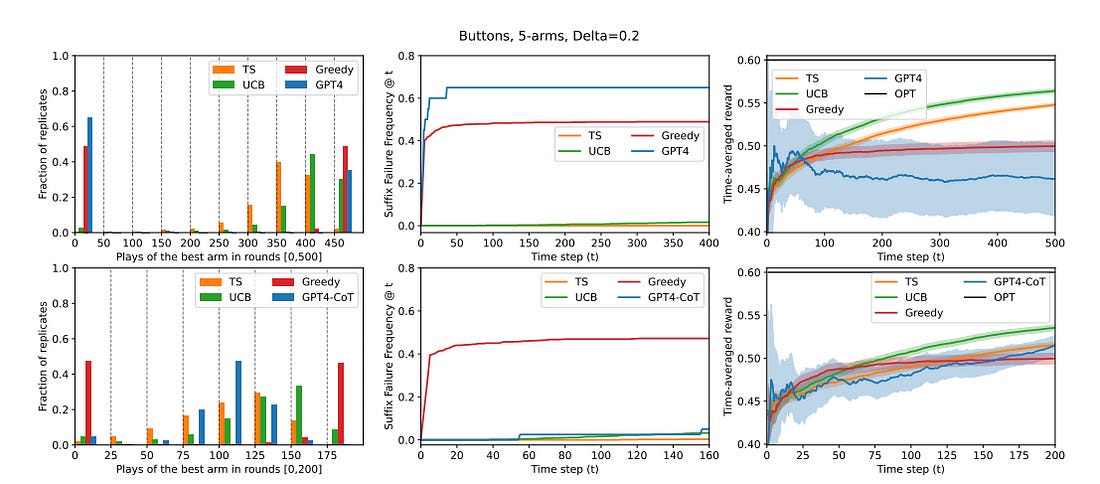
We investigate the extent to which contemporary Large Language Models (LLMs) can engage in exploration, a core capability in reinforcement learning and decision-making. We focus on the native performance of existing LLMs, without training interventions.
We deploy LLMs as agents in simple multi-armed bandit environments, specifying the environment description and interaction history entirely in context, i.e., within the LLM prompt.
We experiment with GPT-3.5, GPT-4, and Llama2, using a variety of prompt designs, and find that the models do not robustly engage in exploration without substantial interventions:
i) Across all of our experiments, only one configuration resulted in satisfactory exploratory behavior: GPT-4 with chain-of-thought reasoning and an externally summarized interaction history, presented as sufficient statistics.
ii) All other configurations did not result in robust exploratory behavior, including those with chain-of-thought reasoning but unsummarized history.
Although these findings can be interpreted positively, they suggest that external summarization — which may not be possible in more complex settings — is important for obtaining desirable behavior from LLM agents. We conclude that non-trivial algorithmic interventions, such as fine-tuning or dataset curation, may be required to empower LLM-based decision-making agents in complex settings.
3. LLM Training, Evaluation & Inference
3.1. LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement

Pretrained large language models (LLMs) are currently state-of-the-art for solving most natural language processing tasks. While many real-world applications still require fine-tuning to reach satisfactory performance levels, many of them are in the low-data regime, making fine-tuning challenging.
To address this, we propose LLM2LLM, a targeted and iterative data augmentation strategy that uses a teacher LLM to enhance a small seed dataset by augmenting additional data that can be used for fine-tuning a specific task.
LLM2LLM (1) fine-tunes a baseline student LLM on the initial seed data, (2) evaluates and extracts data points that the model gets wrong, and (3) uses a teacher LLM to generate synthetic data based on these incorrect data points, which are then added back into the training data.
This approach amplifies the signal from incorrectly predicted data points by the LLM during training and reintegrates them into the dataset to focus on more challenging examples for the LLM. Our results show that LLM2LLM significantly enhances the performance of LLMs in the low-data regime, outperforming both traditional fine-tuning and other data augmentation baselines.
LLM2LLM reduces the dependence on labor-intensive data curation and paves the way for more scalable and performant LLM solutions, allowing us to tackle data-constrained domains and tasks. We achieve improvements up to 24.2% on the GSM8K dataset, 32.6% on CaseHOLD, 32.0% on SNIPS, 52.6% on TREC, and 39.8% on SST-2 over regular fine-tuning in the low-data regime using a LLaMA2–7B student model.
3.2. FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
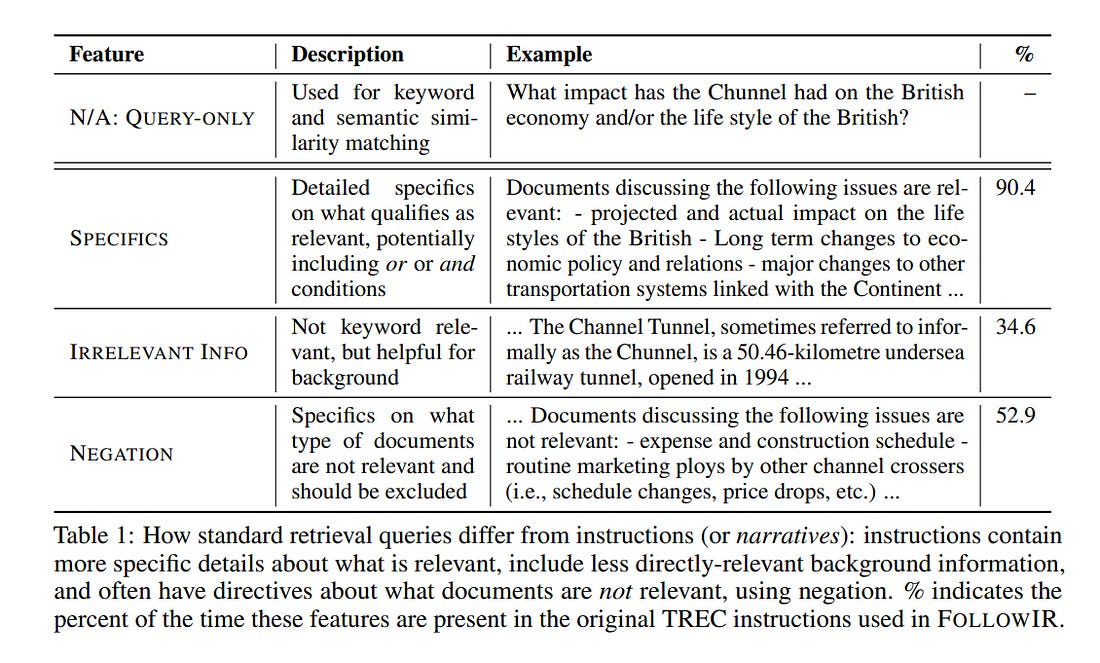
Modern Large Language Models (LLMs) are capable of following long and complex instructions that enable a diverse amount of user tasks. However, despite Information Retrieval (IR) models using LLMs as the backbone of their architectures, nearly all of them still only take queries as input, with no instructions.
For the handful of recent models that do take instructions, it’s unclear how they use them. We introduce our dataset FollowIR, which contains a rigorous instruction evaluation benchmark, as well as a training set for helping IR models, learn to better follow real-world instructions.
FollowIR builds off the long history of the TREC conferences: as TREC provides human annotators with instructions (also known as narratives) to determine document relevance, so should IR models be able to understand and decide relevance based on these detailed instructions.
Our evaluation benchmark starts with three deeply judged TREC collections and alters the annotator instructions, re-annotating relevant documents. Through this process, we can measure how well IR models follow instructions, through a new pairwise evaluation framework.
Our results indicate that existing retrieval models fail to correctly use instructions, using them for basic keywords and struggling to understand long-form information. However, we show that IR models can learn to follow complex instructions: our new FollowIR-7B model has significant improvements (over 13%) after fine-tuning our training set.
3.3. Long-form factuality in large language models

Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model’s long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics.
We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method that we call Search-Augmented Factuality Evaluator (SAFE).
SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results.
Furthermore, we propose extending the F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user’s preferred response length (recall).
Empirically, we demonstrate that LLM agents can achieve superhuman rating performance — on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time.
At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form actuality.
3.4. LLM Agent Operating System

The integration and deployment of large language model (LLM)-based intelligent agents have been fraught with challenges that compromise their efficiency and efficacy. Among these issues are sub-optimal scheduling and resource allocation of agent requests over the LLM, the difficulties in maintaining context during interactions between agent and LLM, and the complexities inherent in integrating heterogeneous agents with different capabilities and specializations.
The rapid increase of agent quantity and complexity further exacerbate these issues, often leading to bottlenecks and sub-optimal utilization of resources. Inspired by these challenges, this paper presents AIOS, an LLM agent operating system, which embeds large language models into operating systems (OS).
Specifically, AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, and maintain access control for agents. We present the architecture of such an operating system, outline the core challenges it aims to resolve, and provide the basic design and implementation of the AIOS.
Our experiments on concurrent execution of multiple agents demonstrate the reliability and efficiency of our AIOS modules. Through this, we aim to not only improve the performance and efficiency of LLM agents but also to pioneer better development and deployment of the AIOS ecosystem in the future.
4. LLM Optimization & Quantization
4.1. sDPO: Don’t Use Your Data All at Once
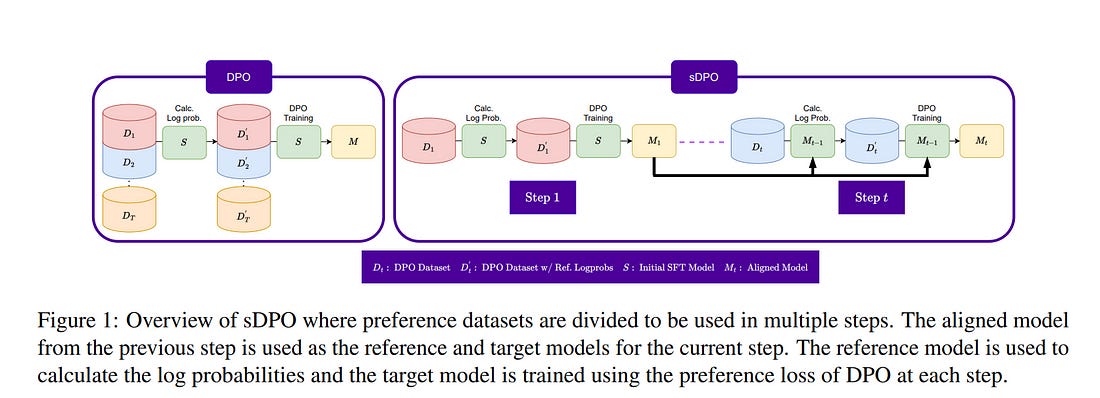
As the development of large language models (LLM) progresses, aligning them with human preferences has become increasingly important. We propose stepwise DPO (sDPO), an extension of the recently popularized direct preference optimization (DPO) for alignment tuning.
This approach involves dividing the available preference datasets and utilizing them in a stepwise manner, rather than employing it all at once. We demonstrate that this method facilitates the use of more precisely aligned reference models within the DPO training framework.
Furthermore, sDPO trains the final model to be more performant, even outperforming other popular LLMs with more parameters.
5. LLM Ethics & Safety
5.1. Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression

Compressing high-capability Large Language Models (LLMs) has emerged as a favored strategy for resource-efficient inferences. While state-of-the-art (SoTA) compression methods boast impressive advancements in preserving benign task performance, the potential risks of compression in terms of safety and trustworthiness have been largely neglected.
This study conducts the first, thorough evaluation of three (3) leading LLMs using five (5) SoTA compression techniques across eight (8) trustworthiness dimensions. Our experiments highlight the intricate interplay between compression and trustworthiness, revealing some interesting patterns. We find that quantization is currently a more effective approach than pruning in achieving efficiency and trustworthiness simultaneously.
For instance, a 4-bit quantized model retains the trustworthiness of its original counterpart, but model pruning significantly degrades trustworthiness, even at 50% sparsity.
Moreover, employing quantization within a moderate bit range could unexpectedly improve certain trustworthiness dimensions such as ethics and fairness. Conversely, extreme quantization to very low bit levels (3 bits) tends to significantly reduce trustworthiness.
This increased risk cannot be uncovered by looking at benign performance alone, in turn, mandating comprehensive trustworthiness evaluation in practice. These findings culminate in practical recommendations for simultaneously achieving high utility, efficiency, and trustworthiness in LLMs.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
