


Top Important LLM Papers for the Week from 18/03 to 24/03
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Fourth Week of March 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
LLM Fine-Tuning
LLM Optimization & Quantization
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. RAFT: Adapting Language Model to Domain-Specific RAG

Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning.
However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model’s ability to answer questions in an “open-book” in-domain settings.
In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don’t help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question.
This coupled with RAFT’s chain-of-thought-style response helps improve the model’s ability to reason. In domain-specific RAG, RAFT consistently improves the model’s performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG.
1.2. Larimar: Large Language Models with Episodic Memory Control
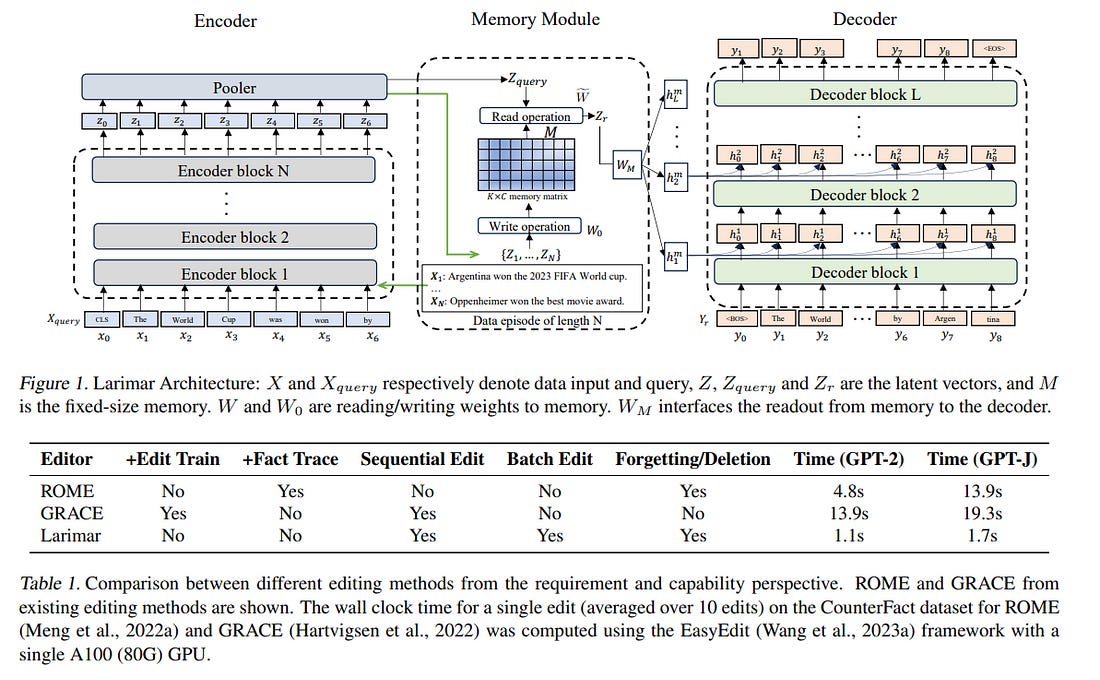
Efficient and accurate updating of knowledge stored in Large Language Models (LLMs) is one of the most pressing research challenges today. This paper presents Larimar — a novel, brain-inspired architecture for enhancing LLMs with a distributed episodic memory.
Larimar’s memory allows for dynamic, one-shot updates of knowledge without the need for computationally expensive re-training or fine-tuning. Experimental results on multiple fact editing benchmarks demonstrate that Larimar attains accuracy comparable to most competitive baselines, even in the challenging sequential editing setup, but also excels in speed — yielding speed-ups of 4–10x depending on the base LLM — as well as flexibility due to the proposed architecture being simple, LLM-agnostic, and hence general.
We further provide mechanisms for selective fact forgetting and input context length generalization with Larimar and show their effectiveness.
1.3. Recourse for reclamation: Chatting with generative language models

Researchers and developers increasingly rely on toxicity scoring to moderate generative language model outputs, in settings such as customer service, information retrieval, and content generation.
However, toxicity scoring may render pertinent information inaccessible, rigidify or “value-lock” cultural norms, and prevent language reclamation processes, particularly for marginalized people.
In this work, we extend the concept of algorithmic recourse to generative language models: we provide users with a novel mechanism to achieve their desired prediction by dynamically setting thresholds for toxicity filtering. Users thereby exercise increased agency relative to interactions with the baseline system.
A pilot study (n = 30) supports the potential of our proposed recourse mechanism, indicating improvements in usability compared to fixed-threshold toxicity-filtering of model outputs.
Future work should explore the intersection of toxicity scoring, model controllability, user agency, and language reclamation processes — particularly the bias that many communities encounter when interacting with generative language models.
1.4. TnT-LLM: Text Mining at Scale with Large Language Models

Transforming unstructured text into structured and meaningful forms, organized by useful category labels, is a fundamental step in text mining for downstream analysis and application.
However, most existing methods for producing label taxonomies and building text-based label classifiers still rely heavily on domain expertise and manual curation, making the process expensive and time-consuming.
This is particularly challenging when the label space is under-specified and large-scale data annotations are unavailable. In this paper, we address these challenges with Large Language Models (LLMs), whose prompt-based interface facilitates the induction and use of large-scale pseudo labels.
We propose TnT-LLM, a two-phase framework that employs LLMs to automate the process of end-to-end label generation and assignment with minimal human effort for any given use case.
In the first phase, we introduce a zero-shot, multi-stage reasoning approach that enables LLMs to produce and refine a label taxonomy iteratively.
In the second phase, LLMs are used as data labelers that yield training samples so that lightweight supervised classifiers can be reliably built, deployed and served at scale. We apply TnT-LLM to the analysis of user intent and conversational domain for Bing Copilot (formerly Bing Chat), an open-domain chat-based search engine.
Extensive experiments using both human and automatic evaluation metrics demonstrate that TnT-LLM generates more accurate and relevant label taxonomies when compared against state-of-the-art baselines, and achieves a favorable balance between accuracy and efficiency for classification at scale.
We also share our practical experiences and insights on the challenges and opportunities of using LLMs for large-scale text mining in real-world applications.
1.5. Towards 3D Molecule-Text Interpretation in Language Models
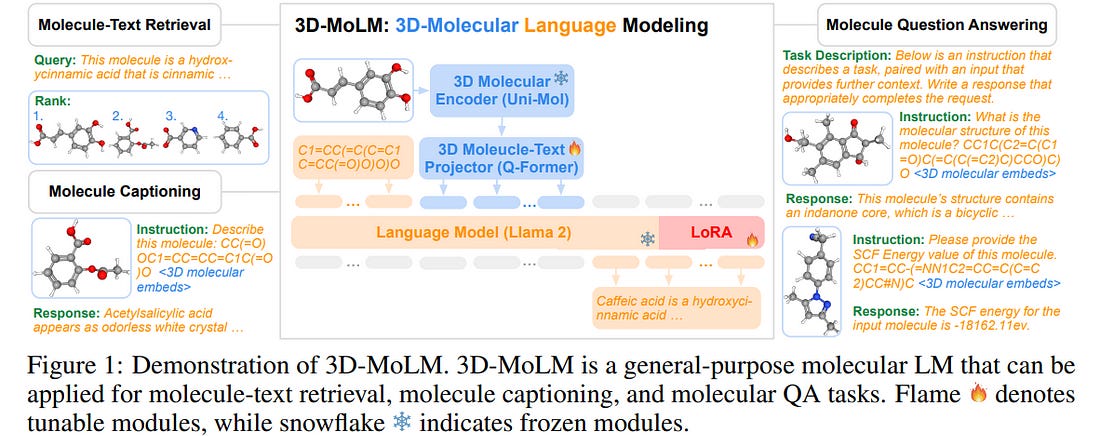
Language Models (LMs) have greatly influenced diverse domains. However, their inherent limitation in comprehending 3D molecular structures has considerably constrained their potential in the biomolecular domain. To bridge this gap, we focus on 3D molecule-text interpretation, and propose 3D-MoLM: 3D-Molecular Language Modeling.
Specifically, 3D-MoLM enables an LM to interpret and analyze 3D molecules by equipping the LM with a 3D molecular encoder. This integration is achieved by a 3D molecule-text projector, bridging the 3D molecular encoder’s representation space and the LM’s input space.
Moreover, to enhance 3D-MoLM’s ability of cross-modal molecular understanding and instruction following, we meticulously curated a 3D molecule-centric instruction tuning dataset — 3D-MoIT.
Through 3D molecule-text alignment and 3D molecule-centric instruction tuning, 3D-MoLM establishes an integration of a 3D molecular encoder and LM.
It significantly surpasses existing baselines on downstream tasks, including molecule-text retrieval, molecule captioning, and more challenging open-text molecular QA tasks, especially focusing on 3D-dependent properties.
1.6. Recurrent Drafter for Fast Speculative Decoding in Large Language Models

In this paper, we introduce an improved approach to speculative decoding aimed at enhancing the efficiency of serving large language models. Our method capitalizes on the strengths of two established techniques: the classic two-model speculative decoding approach, and the more recent single-model approach, Medusa.
Drawing inspiration from Medusa, our approach adopts a single-model strategy for speculative decoding. However, our method distinguishes itself by employing a single, lightweight draft head with a recurrent dependency design, akin to the small, draft model used in classic speculative decoding, but without the complexities of the full transformer architecture.
And because of the recurrent dependency, we can use beam search to swiftly filter out undesired candidates with the draft head. The outcome is a method that combines the simplicity of single-model design and avoids the need to create a data-dependent tree attention structure only for inference in Medusa.
We empirically demonstrate the effectiveness of the proposed method on several popular open-source language models, along with a comprehensive analysis of the trade-offs involved in adopting this approach.
2. LLM Reasoning
2.1. MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?

The remarkable progress of Multi-modal Large Language Models (MLLMs) has garnered unparalleled attention, due to their superior performance in visual contexts.
However, their capabilities in visual math problem-solving remain insufficiently evaluated and understood. We investigate current benchmarks to incorporate excessive visual content within textual questions, which potentially assist MLLMs in deducing answers without truly interpreting the input diagrams.
To this end, we introduce MathVerse, an all-around visual math benchmark designed for an equitable and in-depth evaluation of MLLMs. We meticulously collect 2,612 high-quality, multi-subject math problems with diagrams from publicly available sources.
Each problem is then transformed by human annotators into six distinct versions, each offering varying degrees of information content in multi-modality, contributing to 15K test samples in total. This approach allows MathVerse to comprehensively assess whether and how much MLLMs can truly understand the visual diagrams for mathematical reasoning.
In addition, we propose a Chain-of-Thought (CoT) evaluation strategy for a fine-grained assessment of the output answers. Rather than naively judging True or False, we employ GPT-4(V) to adaptively extract crucial reasoning steps, and then score each step with detailed error analysis, which can reveal the intermediate CoT reasoning quality by MLLMs. We hope the MathVerse benchmark may provide unique insights to guide the future development of MLLMs.
2.2. Chart-based Reasoning: Transferring Capabilities from LLMs to VLMs

Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of large-language models (LLMs) have seen numerous improvements.
We propose a technique to transfer capabilities from LLMs to VLMs. On the recently introduced ChartQA, our method obtains state-of-the-art performance when applied on the PaLI3–5B VLM by chen2023pali3, while also enabling much better performance on PlotQA and FigureQA.
We first improve the chart representation by continuing the pre-training stage using an improved version of the chart-to-table translation task by liu2023deplot. We then propose constructing a 20x larger dataset than the original training set.
To improve general reasoning capabilities and improve numerical operations, we synthesize reasoning traces using the table representation of charts. Lastly, our model is fine-tuned using the multitask loss introduced by hsieh2023distilling.
Our variant ChartPaLI-5B outperforms even 10x larger models such as PaLIX-55B without using an upstream OCR system while keeping inference time constant compared to the PaLI3–5B baseline. When rationales are further refined with a simple program-of-thought prompt chen2023program, our model outperforms the recently introduced Gemini Ultra and GPT-4V.
3. LLM Training, Evaluation & Inference
3.1. Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference

In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the foundation model for many downstream tasks, current MLLMs are composed of the well-known Transformer network, which has a less efficient quadratic computation complexity.
To improve the efficiency of such basic models, we propose Cobra, a linear computational complexity MLLM. Specifically, Cobra integrates the efficient Mamba language model into the visual modality. Moreover, we explore and study various modal fusion schemes to create an effective multi-modal Mamba.
Extensive experiments demonstrate that:
Cobra achieves extremely competitive performance with current computationally efficient state-of-the-art methods, e.g., LLaVA-Phi, TinyLLaVA, and MobileVLM v2, and has faster speed due to Cobra’s linear sequential modeling.
Interestingly, the results of closed-set challenging prediction benchmarks show that Cobra performs well in overcoming visual illusions and spatial relationship judgments.
Notably, Cobra even achieves comparable performance to LLaVA with about 43% of the number of parameters. We will make all codes of Cobra open-source and hope that the proposed method can facilitate future research on complexity problems in MLLM.
3.2. RewardBench: Evaluating Reward Models for Language Modeling

Reward models (RMs) are at the crux of successful RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on the evaluation of those reward models.
Evaluating reward models presents an opportunity to understand the opaque technologies used for the alignment of language models and which values are embedded in them.
To date, very few descriptors of capabilities, training methods, or open-source reward models exist. In this paper, we present RewardBench, a benchmark dataset and code-base for evaluation, to enhance the scientific understanding of reward models.
The RewardBench dataset is a collection of prompt-win-lose trios spanning chat, reasoning, and safety, to benchmark how reward models perform on challenging, structured, and out-of-distribution queries. We created specific comparison datasets for RMs that have subtle, but verifiable reasons (e.g. bugs, incorrect facts) why one answer should be preferred to another.
On the RewardBench leaderboard, we evaluate reward models trained with a variety of methods, such as the direct MLE training of classifiers and the implicit reward modeling of Direct Preference Optimization (DPO), and on a spectrum of datasets.
We present many findings on the propensity for refusals, reasoning limitations, and instruction following shortcomings of various reward models toward a better understanding of the RLHF process.
4. LLM Fine-Tuning
4.1. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
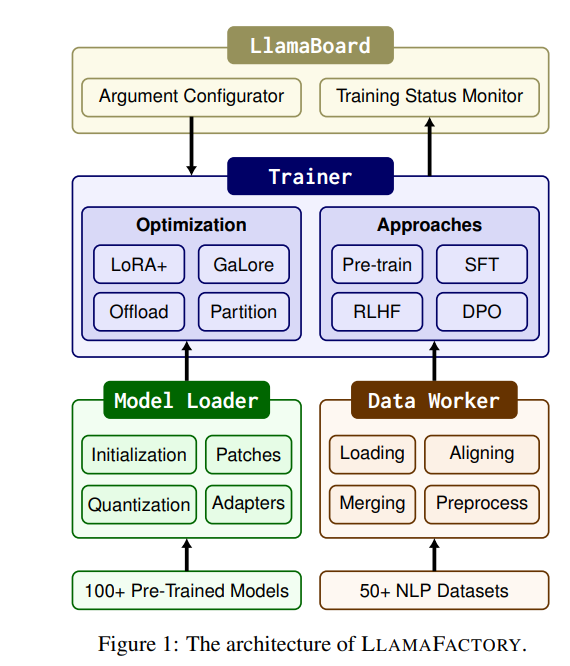
Efficient fine-tuning is vital for adapting large language models (LLMs) to downstream tasks. However, it requires non-trivial efforts to implement these methods on different models.
We present LlamaFactory, a unified framework that integrates a suite of cutting-edge efficient training methods. It allows users to flexibly customize the fine-tuning of 100+ LLMs without the need for coding through the built-in web UI LlamaBoard.
We empirically validate the efficiency and effectiveness of our framework on language modeling and text generation tasks.
5. LLM Optimization & Quantization
5.1. PERL: Parameter Efficient Reinforcement Learning from Human Feedback

Reinforcement Learning from Human Feedback (RLHF) has proven to be a strong method to align Pretrained Large Language Models (LLMs) with human preferences. But training models with RLHF is computationally expensive, and an overall complex process.
In this work, we study RLHF where the underlying models are trained using the parameter-efficient method of Low-Rank Adaptation (LoRA) introduced by Hu et al.
We investigate the setup of “Parameter Efficient Reinforcement Learning” (PERL), in which we perform reward model training and reinforcement learning using LoRA. We compare PERL to conventional fine-tuning (full-tuning) across various configurations for 7 benchmarks, including 2 novel datasets, of reward modeling and reinforcement learning.
We find that PERL performs on par with the conventional RLHF setting, while training faster, and with less memory. This enables the high performance of RLHF while reducing the computational burden that limits its adoption as an alignment technique for Large Language Models. We also release 2 novel thumbs-up/down preference datasets: “Taskmaster Coffee”, and “Taskmaster Ticketing” to promote research around RLHF.
5.2. LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression

This paper focuses on task-agnostic prompt compression for better generalizability and efficiency. Considering the redundancy in natural language, existing approaches compress prompts by removing tokens or lexical units according to their information entropy obtained from a causal language model such as LLaMa-7B.
The challenge is that information entropy may be a suboptimal compression metric: (i) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression; (ii) it is not aligned with the prompt compression objective.
To address these issues, we propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information, and meantime, introduce an extractive text compression dataset.
We formulate prompt compression as a token classification problem to guarantee the faithfulness of the compressed prompt to the original one and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context.
Our approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa-large and mBERT.
We evaluate our method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs.
Additionally, our model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x.
6. LLM Regulations & Ethics
6.1. Alignment Studio: Aligning Large Language Models to Particular Contextual Regulations

The alignment of large language models is usually done by model providers to add or control behaviors that are common or universally understood across use cases and contexts.
In contrast, in this article, we present an approach and architecture that empowers application developers to tune a model to their particular values, social norms, laws, and other regulations, and orchestrate between potentially conflicting requirements in context.
We lay out three main components of such an Alignment Studio architecture: Framers, Instructors, and Auditors which work in concert to control the behavior of a language model.
We illustrate this approach with a running example of aligning a company’s internal-facing enterprise chatbot to its business conduct guidelines.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
