


Top Important LLM Papers for the Week from 01/04 to 07/04
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the First Week of April 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
LLM Optimization & Quantization
LLM Ethics & Safety
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. Jamba: A Hybrid Transformer-Mamba Language Model

We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable.
This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU.
Built on a large scale, Jamba provides high throughput and a small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations.
Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large-scale modeling.
We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
1.2. RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis

We present RALL-E, a robust language modeling method for text-to-speech (TTS) synthesis. While previous work based on large language models (LLMs) shows impressive performance on zero-shot TTS, such methods often suffer from poor robustness, such as unstable prosody (weird pitch and rhythm/duration) and a high word error rate (WER), due to the autoregressive prediction style of language models.
The core idea behind RALL-E is chain-of-thought (CoT) prompting, which decomposes the task into simpler steps to enhance the robustness of LLM-based TTS. To accomplish this idea, RALL-E first predicts prosody features (pitch and duration) of the input text and uses them as intermediate conditions to predict speech tokens in a CoT style.
Second, RALL-E utilizes the predicted duration prompt to guide the computing of self-attention weights in Transformer to enforce the model to focus on the corresponding phonemes and prosody features when predicting speech tokens.
Results of comprehensive objective and subjective evaluations demonstrate that, compared to a powerful baseline method VALL-E, RALL-E significantly improves the WER of zero-shot TTS from 6.3% (without reranking) and 2.1% (with reranking) to 2.8% and 1.0%, respectively. Furthermore, we demonstrate that RALL-E correctly synthesizes sentences that are hard for VALL-E and reduces the error rate from 68% to 4%.
1.3. Gecko: Versatile Text Embeddings Distilled from Large Language Models
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM.
Next, we further refine the data quality by retrieving a set of candidate passages for each query and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko.
On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
1.4. MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection

Recent advances in deep learning have mainly relied on Transformers due to their data dependency and ability to learn at scale. The attention module in these architectures, however, exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling.
Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are either data independent or fail to allow inter- and intra-dimension communication.
Recently, State Space Models (SSMs), and more specifically Selective State Space Models, with efficient hardware-aware implementation, have shown promising potential for long sequence modeling. Motivated by the success of SSMs, we present MambaMixer, a new architecture with data-dependent weights that uses a dual selection mechanism across tokens and channels, called Selective Token and Channel Mixer.
MambaMixer connects selective mixers using a weighted averaging mechanism, allowing layers to have direct access to early features. As a proof of concept, we design Vision MambaMixer (ViM2) and Time Series MambaMixer (TSM2) architectures based on the MambaMixer block and explore their performance in various vision and time series forecasting tasks.
Our results underline the importance of selective mixing across both tokens and channels. In ImageNet classification, object detection, and semantic segmentation tasks, ViM2 achieves competitive performance with well-established vision models and outperforms SSM-based vision models.
In time series forecasting, TSM2 achieves outstanding performance compared to state-of-the-art methods while demonstrating significantly improved computational cost. These results show that while Transformers, cross-channel attention, and MLPs are sufficient for good performance in time series forecasting, neither is necessary.
1.5. WavLLM: Towards Robust and Adaptive Speech Large Language Model

The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly concerning generalizing across varied contexts and executing complex auditory tasks.
In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker’s identity.
Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage.
We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, and ER, and also apply it to specialized datasets like the Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set.
Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using the CoT approach. Furthermore, our model completes Gaokao tasks without specialized training.
1.6. ST-LLM: Large Language Models Are Effective Temporal Learners

Large Language Models (LLMs) have showcased impressive capabilities in text comprehension and generation, prompting research efforts towards video LLMs to facilitate human-AI interaction at the video level. However, how to effectively encode and understand videos in video-based dialogue systems remains to be solved.
In this paper, we investigate a straightforward yet unexplored question: Can we feed all spatial-temporal tokens into the LLM, thus delegating the task of video sequence modeling to the LLMs?
Surprisingly, this simple approach yields significant improvements in video understanding. Based upon this, we propose ST-LLM, an effective video-LLM baseline with Spatial-Temporal sequence modeling inside LLM.
Furthermore, to address the overhead and stability issues introduced by uncompressed video tokens within LLMs, we develop a dynamic masking strategy with tailor-made training objectives. For particularly long videos, we have also designed a global-local input module to balance efficiency and effectiveness.
Consequently, we harness LLM for proficient spatial-temporal modeling, while upholding efficiency and stability. Extensive experimental results attest to the effectiveness of our method. Through a more concise model and training pipeline, ST-LLM establishes a new state-of-the-art result on VideoChatGPT-Bench and MVBench.
1.7. Are large language models superhuman chemists?

Large language models (LLMs) have gained widespread interest due to their ability to process human language and perform tasks on which they have not been explicitly trained. This is relevant for the chemical sciences, which face the problem of small and diverse datasets that are frequently in the form of text.
LLMs have shown promise in addressing these issues and are increasingly being harnessed to predict chemical properties, optimize reactions, and even design and conduct experiments autonomously. However, we still have only a very limited systematic understanding of the chemical reasoning capabilities of LLMs, which would be required to improve models and mitigate potential harm.
Here, we introduce “ChemBench,” an automated framework designed to rigorously evaluate the chemical knowledge and reasoning abilities of state-of-the-art LLMs against the expertise of human chemists. We curated more than 7,000 question-answer pairs for a wide array of subfields of the chemical sciences, evaluated leading open and closed-source LLMs, and found that the best models outperformed the best human chemists in our study on average.
The models, however, struggle with some chemical reasoning tasks that are easy for human experts and provide overconfident, misleading predictions, such as about chemicals’ safety profiles. These findings underscore the dual reality that, although LLMs demonstrate remarkable proficiency in chemical tasks, further research is critical to enhancing their safety and utility in chemical sciences.
Our findings also indicate a need for adaptations to chemistry curricula and highlight the importance of continuing to develop evaluation frameworks to improve safe and useful LLMs.
1.8. Long-context LLMs Struggle with Long In-context Learning

Large Language Models (LLMs) have made significant strides in handling long sequences exceeding 32K tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their abilities in more nuanced, real-world scenarios.
This study introduces a specialized benchmark (LIConBench) focusing on long in-context learning within the realm of extreme-label classification. We meticulously selected six datasets with a label range spanning 28 to 174 classes covering different input (few-shot demonstration) lengths from 2K to 50K. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions.
We evaluate 13 long-context LLMs on our benchmarks. We find that the long-context LLMs perform relatively well under the token length of 20K and the performance benefits from utilizing the long context window. However, after the context window exceeds 20K, most LLMs except GPT-4 will dip dramatically.
This suggests a notable gap in current LLM capabilities for processing and understanding long, context-rich sequences. Further analysis revealed a tendency among models to favor predictions for labels presented toward the end of the sequence.
Their ability to reason over multiple pieces in the long sequence is yet to be improved. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LIConBench could serve as a more realistic evaluation for future long-context LLMs.
1.9. LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model
We train a suite of multimodal foundation models (MMFM) using the popular LLaVA framework with the recently released Gemma family of large language models (LLMs). Of particular interest is the 2B parameter Gemma model, which provides opportunities to construct capable small-scale MMFMs.
In line with findings from other papers in this space, we test the effect of ablating three design features: pretraining the connector, utilizing a more powerful image backbone, and increasing the size of the language backbone. The resulting models, which we call LLaVA-Gemma, exhibit moderate performance on an array of evaluations but fail to improve past the current comparably sized SOTA models.
A closer analysis of performance shows mixed effects; skipping pretraining tends to reduce performance, larger vision models sometimes improve performance, and increasing language model size has inconsistent effects. We publicly release training recipes, code, and weights for our models for the LLaVA-Gemma models.
1.10. Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order

Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development.
However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained in English, Finnish, Hindi, Japanese, Vietnamese, and code.
Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence.
Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations.
1.11. Poro 34B and the Blessing of Multilinguality
The pretraining of state-of-the-art large language models now requires trillions of words of text, which is orders of magnitude more than available for the vast majority of languages.
While including text in more than one language is an obvious way to acquire more pretraining data, multilingualism is often seen as a curse, and most model training efforts continue to focus near-exclusively on individual large languages.
We believe that multilingualism can be a blessing and that it should be possible to substantially improve the capabilities of monolingual models for small languages through multilingual training.
In this study, we introduce Poro 34B, a 34 billion parameter model trained for 1 trillion tokens of Finnish, English, and programming languages, and demonstrate that a multilingual training approach can produce a model that not only substantially advances over the capabilities of existing models for Finnish, but also excels in translation and is competitive in its class in generating English and programming languages.
1.12. Octopus v2: On-device language model for super agent

Language models have shown effectiveness in a variety of software applications, particularly in tasks related to automatic workflow. These models possess the crucial ability to call functions, which is essential in creating AI agents.
Despite the high performance of large-scale language models in cloud environments, they are often associated with concerns over privacy and cost. Current on-device models for function calling face issues with latency and accuracy.
Our research presents a new method that empowers an on-device model with 2 billion parameters to surpass the performance of GPT-4 in both accuracy and latency and decrease the context length by 95%.
When compared to Llama-7B with a RAG-based function calling mechanism, our method enhances latency by 35-fold. This method reduces the latency to levels deemed suitable for deployment across a variety of edge devices in production environments, aligning with the performance requisites for real-world applications.
1.13. LLM-ABR: Designing Adaptive Bitrate Algorithms via Large Language Models

We present LLM-ABR, the first system that utilizes the generative capabilities of large language models (LLMs) to autonomously design adaptive bitrate (ABR) algorithms tailored for diverse network characteristics.
Operating within a reinforcement learning framework, LLM-ABR empowers LLMs to design key components such as states and neural network architectures.
We evaluate LLM-ABR across diverse network settings, including broadband, satellite, 4G, and 5G. LLM-ABR consistently outperforms default ABR algorithms.
1.14. ReALM: Reference Resolution As Language Modeling

Reference resolution is an important problem, one that is essential to understanding and successfully handling contexts of different kinds. This context includes both previous turns and context that pertains to non-conversational entities, such as entities on the user’s screen or those running in the background.
While LLMs are extremely powerful for a variety of tasks, their use in reference resolution, particularly for non-conversational entities, remains underutilized.
This paper demonstrates how LLMs can be used to create an extremely effective system to resolve references of various types, by showing how reference resolution can be converted into a language modeling problem, despite involving forms of entities like those on screen that are not traditionally conducive to being reduced to a text-only modality.
We demonstrate large improvements over an existing system with similar functionality across different types of references, with our smallest model obtaining absolute gains of over 5% for on-screen references. We also benchmark against GPT-3.5 and GPT-4, with our smallest model achieving performance comparable to that of GPT-4, and our larger models substantially outperforming it.
1.15. Localizing Paragraph Memorization in Language Models
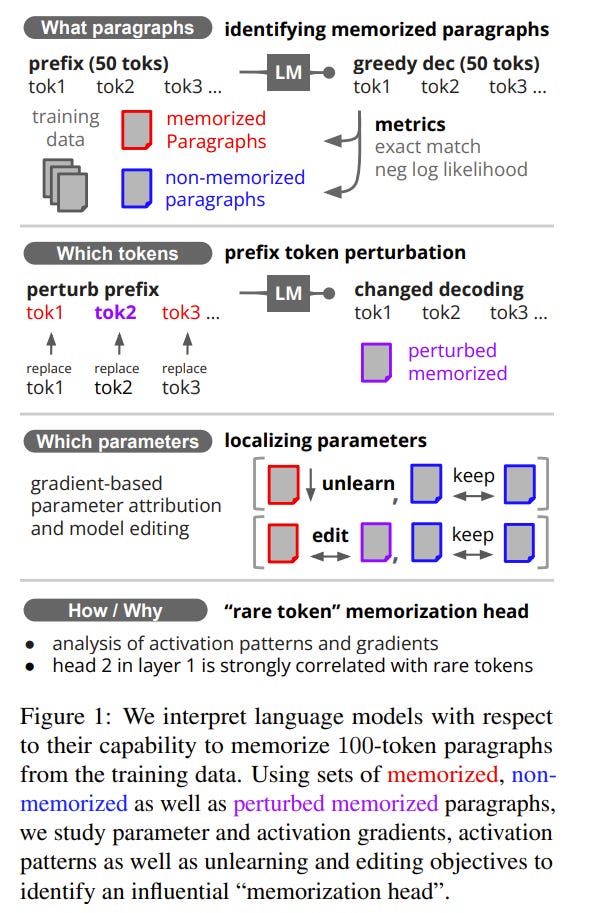
Can we localize the weights and mechanisms used by a language model to memorize and recite entire paragraphs of its training data? In this paper, we show that while memorization is spread across multiple layers and model components, gradients of memorized paragraphs have a distinguishable spatial pattern, being larger in lower model layers than gradients of non-memorized examples.
Moreover, the memorized examples can be unlearned by fine-tuning only the high-gradient weights. We localize a low-layer attention head that appears to be especially involved in paragraph memorization.
This head predominantly focuses its attention on distinctive, rare tokens that are least frequent in a corpus-level unigram distribution. Next, we study how localized memorization is across the tokens in the prefix by perturbing tokens and measuring the caused change in the decoding.
A few distinctive tokens early in a prefix can often corrupt the entire continuation. Overall, memorized continuations are not only harder to unlearn, but also to corrupt than non-memorized ones.
2. LLM Reasoning
2.1. Advancing LLM Reasoning Generalists with Preference Trees

We introduce Eurus, a suite of large language models (LLMs) optimized for reasoning. Finetuned from Mistral-7B and CodeLlama-70B, Eurus models achieve state-of-the-art results among open-source models on a diverse set of benchmarks covering mathematics, code generation, and logical reasoning problems.
Notably, Eurus-70B beats GPT-3.5 Turbo in reasoning through comprehensive benchmarking across 12 tests covering five tasks and achieves a 33.3% pass@1 accuracy on LeetCode and 32.6% on TheoremQA, two challenging benchmarks, substantially outperforming existing open-source models by margins more than 13.3%.
The strong performance of Eurus can be primarily attributed to UltraInteract, our newly curated large-scale, high-quality alignment dataset specifically designed for complex reasoning tasks. UltraInteract can be used in both supervised fine-tuning and preference learning.
Each instruction includes a preference tree consisting of
Reasoning chains with diverse planning strategies in a unified format.
Multi-turn interaction trajectories with the environment and the critique
Pairwise data to facilitate preference learning. UltraInteract allows us to conduct an in-depth exploration of preference learning for reasoning tasks.
Our investigation reveals that some well-established preference learning algorithms may be less suitable for reasoning tasks compared to their effectiveness in general conversations. Inspired by this, we derive a novel reward modeling objective which, together with UltraInteract, leads to a strong reward model.
2.2 Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
Algorithmic reasoning refers to the ability to understand the complex patterns behind the problem and decompose them into a sequence of reasoning steps toward the solution.
Such nature of algorithmic reasoning makes it a challenge for large language models (LLMs), even though they have demonstrated promising performance in other reasoning tasks.
Within this context, some recent studies use programming languages (e.g., Python) to express the necessary logic for solving a given instance/question (e.g., Program-of-Thought) as inspired by their strict and precise syntaxes. However, it is non-trivial to write an executable code that expresses the correct logic on the fly within a single inference call.
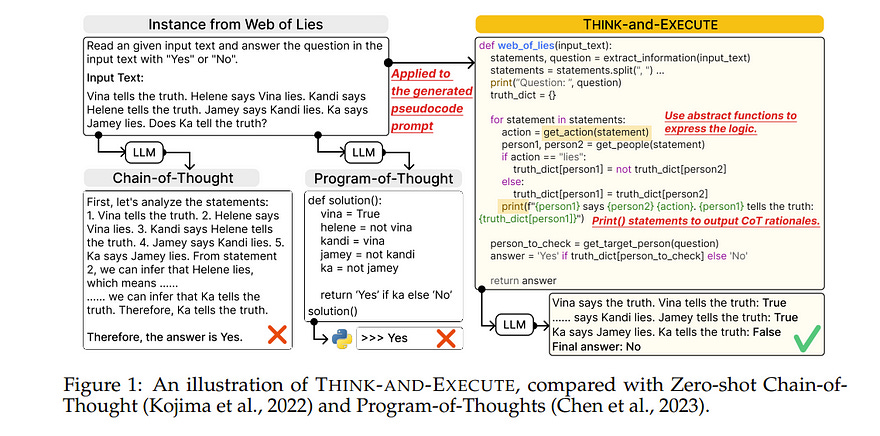
Also, the code generated specifically for an instance cannot be reused for others, even if they are from the same task and might require identical logic to solve. This paper presents Think-and-Execute, a novel framework that decomposes the reasoning process of language models into two steps.
In Think, we discover a task-level logic that is shared across all instances for solving a given task and then express the logic with pseudocode
In Execute, we further tailor the generated pseudocode to each instance and simulate the execution of the code. With extensive experiments on seven algorithmic reasoning tasks, we demonstrate the effectiveness of Think-and-Execute.
Our approach better improves LMs’ reasoning compared to several strong baselines performing instance-specific reasoning (e.g., CoT and PoT), suggesting the helpfulness of discovering task-level logic. Also, we show that compared to natural language, pseudocode can better guide the reasoning of LMs, even though they are trained to follow natural language instructions.
3. LLM Training, Evaluation & Inference
3.1. Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs

The Large Language Model (LLM) is widely employed for tasks such as intelligent assistants, text summarization, translation, and multi-modality on mobile phones. However, the current methods for on-device LLM deployment maintain slow inference speed, which causes poor user experience.
To facilitate high-efficiency LLM deployment on device GPUs, we propose four optimization techniques:
A symbolic expression-based approach to support dynamic shape model inference
Operator optimizations and execution priority setting to enhance inference speed and reduce phone lagging
An FP4 quantization method termed M0E4 to reduce dequantization overhead
A sub-tensor-based technique to eliminate the need for copying KV cache after LLM inference.
Furthermore, we implement these methods in our mobile inference engine, Transformer-Lite, which is compatible with both Qualcomm and MTK processors. We evaluated Transformer-Lite’s performance using LLMs with varied architectures and parameters ranging from 2B to 14B.
Specifically, we achieved prefill and decoding speeds of 121 token/s and 14 token/s for ChatGLM2 6B, and 330 token/s and 30 token/s for smaller Gemma 2B, respectively. Compared with CPU-based FastLLM and GPU-based MLC-LLM, our engine attains over 10x speedup for the prefill speed and 2~3x speedup for the decoding speed.
3.2. Noise-Aware Training of Layout-Aware Language Models
A visually rich document (VRD) utilizes visual features along with linguistic cues to disseminate information. Training a custom extractor that identifies named entities from a document requires a large number of instances of the target document type annotated at textual and visual modalities.
This is an expensive bottleneck in enterprise scenarios, where we want to train custom extractors for thousands of different document types in a scalable way. Pre-training an extractor model on unlabeled instances of the target document type, followed by a fine-tuning step on human-labeled instances does not work in these scenarios, as it surpasses the maximum allowable training time allocated for the extractor.
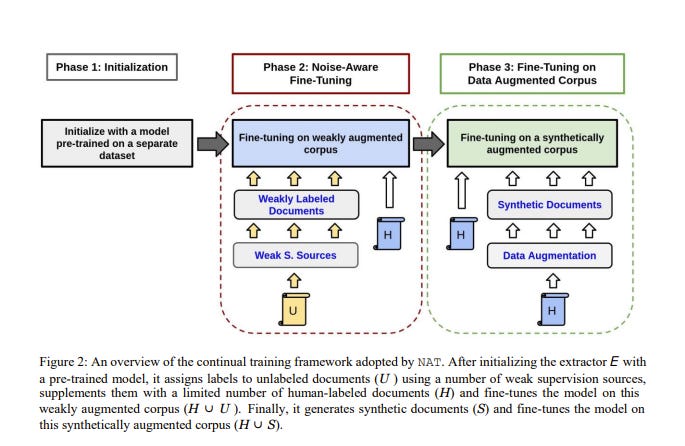
We address this scenario by proposing a Noise-Aware Training method or NAT in this paper. Instead of acquiring expensive human-labeled documents, NAT utilizes weakly labeled documents to train an extractor in a scalable way.
To avoid degradation in the model’s quality due to noisy, weakly labeled samples, NAT estimates the confidence of each training sample and incorporates it as an uncertainty measure during training. We train multiple state-of-the-art extractor models using NAT.
Experiments on a number of publicly available and in-house datasets show that NAT-trained models are not only robust in performance — they outperform a transfer-learning baseline by up to 6% in terms of macro-F1 score, but it is also more label-efficient — they reduce the amount of human effort required to obtain comparable performance by up to 73%.
3.3. Training LLMs over Neurally Compressed Text

In this paper, we explore the idea of training large language models (LLMs) over highly compressed text. While standard subword tokenizers compress text by a small factor, neural text compressors can achieve much higher rates of compression.
If it were possible to train LLMs directly over neurally compressed text, this would confer advantages in training and serving efficiency, as well as easier handling of long text spans.
The main obstacle to this goal is that strong compression tends to produce opaque outputs that are not well-suited for learning. In particular, we find that text naively compressed via Arithmetic Coding is not readily learnable by LLMs.
To overcome this, we propose Equal-Info Windows, a novel compression technique whereby text is segmented into blocks that each compress to the same bit length. Using this method, we demonstrate effective learning over neurally compressed text that improves with scale and outperforms byte-level baselines by a wide margin on perplexity and inference speed benchmarks.
While our method delivers worse perplexity than subword tokenizers for models trained with the same parameter count, it has the benefit of shorter sequence lengths. Shorter sequence lengths require fewer autoregressive generation steps and reduce latency.
Finally, we provide extensive analysis of the properties that contribute to learnability and offer concrete suggestions for how to further improve the performance of high-compression tokenizers.
3.4. CodeEditorBench: Evaluating Code Editing Capability of Large Language Models

Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching.
Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks.
Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities.
We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4. LLM Finetuning
4.1. ReFT: Representation Finetuning for Language Models
Parameter-efficient fine-tuning (PEFT) methods seek to adapt large models via updates to a small number of weights. However, much prior interpretability work has shown that representations encode rich semantic information, suggesting that editing representations might be a more powerful alternative.
Here, we pursue this hypothesis by developing a family of Representation Finetuning (ReFT) methods. ReFT methods operate on a frozen base model and learn task-specific interventions on hidden representations.
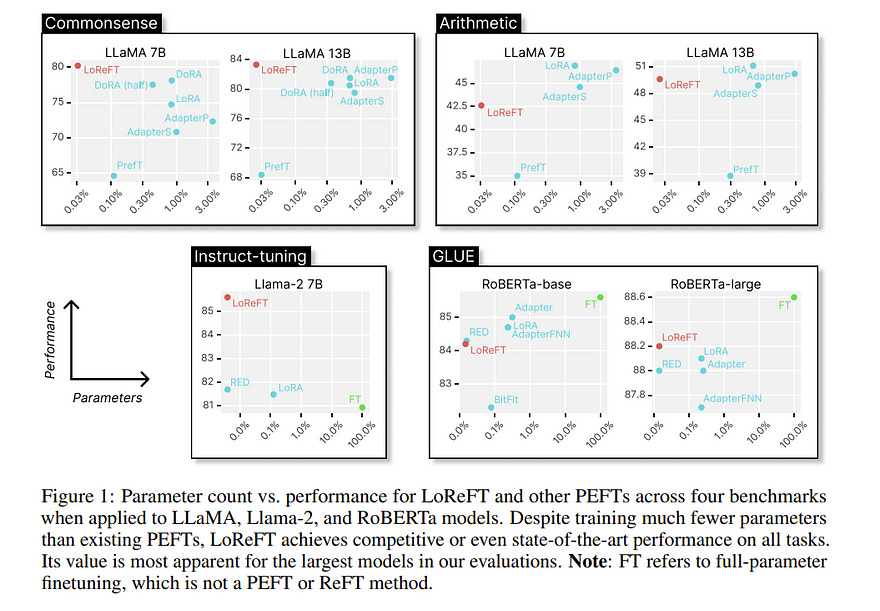
We define a strong instance of the ReFT family, Low-rank Linear Subspace ReFT (LoReFT). LoReFT is a drop-in replacement for existing PEFTs and learns interventions that are 10x-50x more parameter-efficient than prior state-of-the-art PEFTs.
We showcase LoReFT on eight commonsense reasoning tasks, four arithmetic reasoning tasks, Alpaca-Eval v1.0, and GLUE. In all these evaluations, LoReFT delivers the best balance of efficiency and performance and almost always outperforms state-of-the-art PEFTs.
5. LLM Optimization & Quantization
5.1. DiJiang: Efficient Large Language Models through Compact Kernelization

To reduce the computational load of Transformers, research on linear attention has gained significant momentum. However, the improvement strategies for attention mechanisms typically necessitate extensive retraining, which is impractical for large language models with a vast array of parameters.
In this paper, we present DiJiang, a novel Frequency Domain Kernelization approach that enables the transformation of a pre-trained vanilla Transformer into a linear complexity model with little training costs. The proposed approach theoretically offers superior approximation efficiency by employing a weighted Quasi-Monte Carlo method for sampling. To further reduce the training computational complexity, our kernelization is based on Discrete Cosine Transform (DCT) operations.
Extensive experiments demonstrate that the proposed method achieves comparable performance to the original Transformer but with significantly reduced training costs and much faster inference speeds. Our DiJiang-7B achieves comparable performance with LLaMA2–7B on various benchmarks while requiring only about 1/50 training cost.
5.2. Mixture-of-Depths: Dynamically allocating compute in transformer-based language models

Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimizing the allocation along the sequence for different layers across the model depth.
Our method enforces a total compute budget by capping the number of tokens (k) that can participate in the self-attention and MLP computations at a given layer. The tokens to be processed are determined by the network using a top-k routing mechanism. Since k is defined a priori, this simple procedure uses a static computation graph with known tensor sizes, unlike other conditional computation techniques.
Nevertheless, since the identities of the k tokens are fluid, this method can expend FLOPs non-uniformly across the time and model depth dimensions. Thus, compute expenditure is entirely predictable in total, but dynamic and context-sensitive at the token level.
Not only do models trained in this way learn to allocate compute dynamically, they do so efficiently. These models match baseline performance for equivalent FLOPS and wall-clock times to train but require a fraction of the FLOPs per forward pass, and can be upwards of 50\% faster to step during post-training sampling.
6. LLM Ethics & Safety
6.1. Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks?

Various jailbreak attacks have been proposed to red-team Large Language Models (LLMs) and revealed the vulnerable safeguards of LLMs. Besides, some methods are not limited to the textual modality and extend the jailbreak attack to Multimodal Large Language Models (MLLMs) by perturbing the visual input.
However, the absence of a universal evaluation benchmark complicates the performance reproduction and fair comparison. Besides, there is a lack of comprehensive evaluation of closed-source state-of-the-art (SOTA) models, especially MLLMs, such as GPT-4V. To address these issues, this work first builds a comprehensive jailbreak evaluation dataset with 1445 harmful questions covering 11 different safety policies.
Based on this dataset, extensive red-teaming experiments are conducted on 11 different LLMs and MLLMs, including both SOTA proprietary models and open-source models. We then conduct a deep analysis of the evaluated results and find that
GPT4 and GPT-4V demonstrate better robustness against jailbreak attacks compared to open-source LLMs and MLLMs.
Llama2 and Qwen-VL-Chat are more robust compared to other open-source models.
The transferability of visual jailbreak methods is relatively limited compared to textual jailbreak methods.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
