


Top Important LLM Papers for the Week from 06/11 to 12/11
Stay Relevant to Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, it’s important for researchers and engineers to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Second week of November.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Fine Tuning
LLM Reasoning
LLM Training & Optimization
Responsible AI & LLM Ethics
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. LLM Progress & Benchmarking
1.1. PPTC Benchmark: Evaluating Large Language Models for PowerPoint Task Completion

Recent evaluations of Large Language Models (LLMs) have centered around testing their zero-shot/few-shot capabilities for basic natural language tasks and their ability to translate instructions into tool APIs.
However, the evaluation of LLMs utilizing complex tools to finish multi-turn, multi-modal instructions in a complex multi-modal environment has not been investigated. To address this gap, we introduce the PowerPoint Task Completion (PPTC) benchmark to assess LLMs’ ability to create and edit PPT files based on user instructions.
It contains 279 multi-turn sessions covering diverse topics and hundreds of instructions involving multi-modal operations. We also propose the PPTX-Match Evaluation System that evaluates if LLMs finish the instruction based on the prediction file rather than the label API sequence, thus it supports various LLM-generated API sequences.
The authors measure 3 closed LLMs and 6 open-source LLMs. The results show that GPT-4 outperforms other LLMs with 75.1\% accuracy in single-turn dialogue testing but faces challenges in completing entire sessions, achieving just 6\% session accuracy.
The authors find three main error causes in the benchmark: error accumulation in the multi-turn session, long PPT template processing, and multi-modality perception. These pose great challenges for future LLM and agent systems.
1.2. GPT4All: An Ecosystem of Open Source Compressed Language Models

Large language models (LLMs) have recently achieved human-level performance on a range of professional and academic benchmarks. The accessibility of these models has lagged behind their performance.
State-of-the-art LLMs require costly infrastructure; are only accessible via rate-limited, geo-locked, and censored web interfaces; and lack publicly available code and technical reports.
In this paper, the authors tell the story of GPT4All, a popular open-source repository that aims to democratize access to LLMs. They outline the technical details of the original GPT4All model family, as well as the evolution of the GPT4All project from a single model into a fully-fledged open-source ecosystem.
The authors hope that this paper acts as both a technical overview of the original GPT4All models as well as a case study on the subsequent growth of the GPT4All open-source ecosystem.
1.3. u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
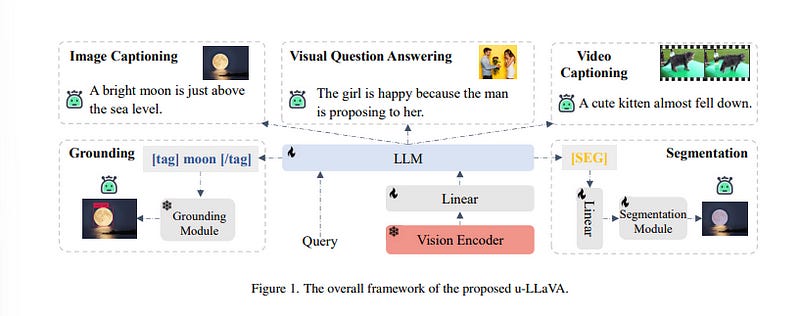
Recent advances such as LLaVA and Mini-GPT4 have successfully integrated visual information into LLMs, yielding inspiring outcomes and giving rise to a new generation of multi-modal LLMs, or MLLMs. Nevertheless, these methods struggle with hallucinations and the mutual interference between tasks.
To tackle these problems, the authors propose an efficient and accurate approach to adapt to downstream tasks by utilizing LLM as a bridge to connect multiple expert models, namely u-LLaVA. Firstly, they incorporate the modality alignment module and multi-task modules into LLM.
Then, they reorganize or rebuild multi-type public datasets to enable efficient modality alignment and instruction following. Finally, task-specific information is extracted from the trained LLM and provided to different modules for solving downstream tasks. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. They also release our model, the generated data, and the code base publicly available.
1.4. Ziya2: Data-centric Learning is All LLMs Need

Various large language models (LLMs) have been proposed in recent years, including closed- and open-source ones, continually setting new records on multiple benchmarks. However, the development of LLMs still faces several issues, such as the high cost of training models from scratch, and continual pre-training leading to catastrophic forgetting, etc.
Although many such issues are addressed along the line of research on LLMs, an important yet practical limitation is that many studies overly pursue enlarging model sizes without comprehensively analyzing and optimizing the use of pre-training data in their learning process, as well as the appropriate organization and leveraging of such data in training LLMs under cost-effective settings.
In this work, the authors propose Ziya2, a model with 13 billion parameters adopting LLaMA2 as the foundation model, and further pre-trained on 700 billion tokens, where they focus on pre-training techniques and use data-centric optimization to enhance the learning process of Ziya2 on different stages. Experiments show that Ziya2 significantly outperforms other models in multiple benchmarks, especially with promising results compared to representative open-source ones.
1.5. Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs

In human-written articles, we often leverage the subtleties of text style, such as bold and italics, to guide the attention of readers. These textual emphases are vital for the readers to grasp the conveyed information. When interacting with large language models (LLMs), we have a similar need — steering the model to pay closer attention to user-specified information, e.g., an instruction.
Existing methods, however, are constrained to process plain text and do not support such a mechanism. This motivated the authors to introduce the PASTA — Post-hoc Attention STeering Approach, a method that allows LLMs to read text with user-specified emphasis marks.
To this end, PASTA identifies a small subset of attention heads and applies precise attention reweighting on them, directing the model attention to user-specified parts. Like prompting, PASTA is applied at inference time and does not require changing any model parameters.
Experiments demonstrate that PASTA can substantially enhance an LLM’s ability to follow user instructions or integrate new knowledge from user inputs, leading to a significant performance improvement on a variety of tasks, e.g., an average accuracy improvement of 22% for LLAMA-7B.
1.6. Leveraging Large Language Models for Automated Proof Synthesis in Rust

Formal verification can provably guarantee the correctness of critical system software, but the high proof burden has long hindered its wide adoption. Recently, Large Language Models (LLMs) have shown success in code analysis and synthesis.
In this paper, the authors present a combination of LLMs and static analysis to synthesize invariants, assertions, and other proof structures for a Rust-based formal verification framework called Verus. In a few-shot setting, LLMs demonstrate impressive logical ability in generating postconditions and loop invariants, especially when analyzing short code snippets.
However, LLMs lack the ability to retain and propagate context information, a strength of traditional static analysis. Based on these observations, we developed a prototype based on OpenAI’s GPT-4 model.
Our prototype decomposes the verification task into multiple smaller ones, iteratively queries GPT-4, and combines its output with lightweight static analysis. We evaluated the prototype with a developer in the automation loop on 20 vector-manipulating programs. The results demonstrate that it significantly reduces human effort in writing entry-level proof code.
1.7. mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration

Multi-modal Large Language Models (MLLMs) have demonstrated impressive instruction abilities across various open-ended tasks. However, previous methods primarily focus on enhancing multi-modal capabilities.
In this work, we introduce a versatile multi-modal large language model, mPLUG-Owl2, which effectively leverages modality collaboration to improve performance in both text and multi-modal tasks. mPLUG-Owl2 utilizes a modularized network design, with the language decoder acting as a universal interface for managing different modalities.
Specifically, mPLUG-Owl2 incorporates shared functional modules to facilitate modality collaboration and introduces a modality-adaptive module that preserves modality-specific features. Extensive experiments reveal that mPLUG-Owl2 is capable of generalizing both text tasks and multi-modal tasks and achieving state-of-the-art performances with a single generic model.
Notably, mPLUG-Owl2 is the first MLLM model that demonstrates the modality collaboration phenomenon in both pure-text and multi-modal scenarios, setting a pioneering path in the development of future multi-modal foundation models.
1.8. Can LLMs Follow Simple Rules?

As Large Language Models (LLMs) are deployed with increasing real-world responsibilities, it is important to be able to specify and constrain the behavior of these systems in a reliable manner.
Model developers may wish to set explicit rules for the model, such as “do not generate abusive content”, but these may be circumvented by jailbreaking techniques. Evaluating how well LLMs follow developer-provided rules in the face of adversarial inputs typically requires manual review, which slows down monitoring and methods development.
To address this issue, we propose Rule-following Language Evaluation Scenarios (RuLES), a programmatic framework for measuring rule-following ability in LLMs. RuLES consists of 15 simple text scenarios in which the model is instructed to obey a set of rules in natural language while interacting with the human user.
Each scenario has a concise evaluation program to determine whether the model has broken any rules in a conversation. Through manual exploration of model behavior in our scenarios, we identify 6 categories of attack strategies and collect two suites of test cases: one consisting of unique conversations from manual testing and one that systematically implements strategies from the 6 categories.
Across various popular proprietary and open models such as GPT-4 and Llama 2, we find that all models are susceptible to a wide variety of adversarial hand-crafted user inputs, though GPT-4 is the best-performing model. Additionally, we evaluate open models under gradient-based attacks and find significant vulnerabilities. We propose RuLES as a challenging new setting for research into exploring and defending against both manual and automatic attacks on LLMs.
1.9. GENOME: GenerativE Neuro-symbOlic visual reasoning by growing and reusing ModulEs
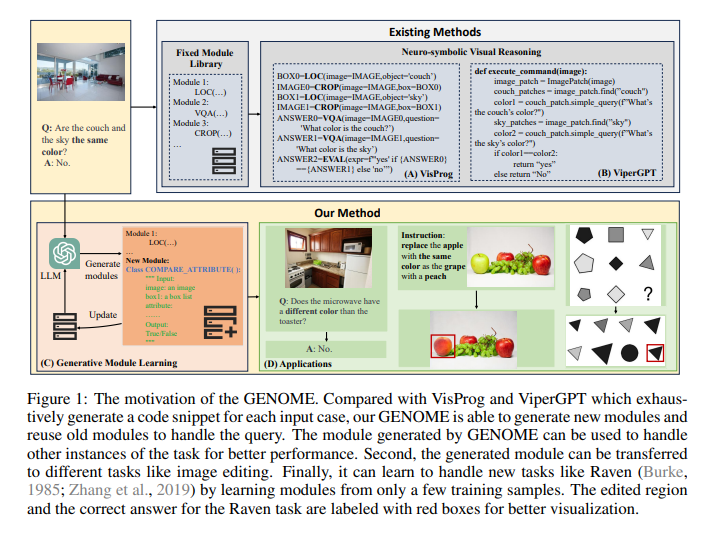
Recent works have shown that Large Language Models (LLMs) could empower traditional neuro-symbolic models via programming capabilities to translate language into module descriptions, thus achieving strong visual reasoning results while maintaining the model’s transparency and efficiency. However, these models usually exhaustively generate the entire code snippet given each new instance of a task, which is extremely ineffective.
We propose generative neuro-symbolic visual reasoning by growing and reusing modules. Specifically, our model consists of three unique stages, module initialization, module generation, and module execution. First, given a vision-language task, we adopt LLMs to examine whether we could reuse and grow over established modules to handle this new task. If not, we initialize a new module needed by the task and specify the inputs and outputs of this new module.
After that, the new module is created by querying LLMs to generate corresponding code snippets that match the requirements. In order to get a better sense of the new module’s ability, we treat few-shot training examples as test cases to see if our new module could pass these cases. If yes, the new module is added to the module library for future reuse. Finally, we evaluate the performance of our model on the testing set by executing the parsed programs with the newly made visual modules to get the results.
We find the proposed model possesses several advantages. First, it performs competitively on standard tasks like visual question answering and referring expression comprehension; Second, the modules learned from one task can be seamlessly transferred to new tasks; Last but not least, it is able to adapt to new visual reasoning tasks by observing a few training examples and reusing modules.
2. LLM Fine Tuning
2.1. MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning

Code LLMs have emerged as a specialized research field, with remarkable studies dedicated to enhancing the model’s coding capabilities through fine-tuning pre-trained models.
Previous fine-tuning approaches were typically tailored to specific downstream tasks or scenarios, which meant separate fine-tuning for each task, requiring extensive training resources and posing challenges in terms of deployment and maintenance.
Furthermore, these approaches failed to leverage the inherent interconnectedness among different code-related tasks. To overcome these limitations, we present a multi-task fine-tuning framework, MFTcoder, that enables simultaneous and parallel fine-tuning on multiple tasks. By incorporating various loss functions, we effectively address common challenges in multi-task learning, such as data imbalance, varying difficulty levels, and inconsistent convergence speeds.
Extensive experiments have conclusively demonstrated that our multi-task fine-tuning approach outperforms both individual fine-tuning on single tasks and fine-tuning on a mixed ensemble of tasks. Moreover, MFTcoder offers efficient training capabilities, including efficient data tokenization modes and PEFT fine-tuning, resulting in significantly improved speed compared to traditional fine-tuning methods.
MFTcoder seamlessly integrates with several mainstream open-source LLMs, such as CodeLLama and Qwen. Leveraging the CodeLLama foundation, our MFTcoder fine-tuned model, CodeFuse-CodeLLama-34B, achieves an impressive pass@1 score of 74.4\% on the HumaneEval benchmark, surpassing GPT-4 performance (67\%, zero-shot).
3. LLM Training & Optimization
3.1. S-LoRA: Serving Thousands of Concurrent LoRA Adapters

The “pretrain-then-finetune” paradigm is commonly adopted in the deployment of large language models. Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning method, is often employed to adapt a base model to a multitude of tasks, resulting in a substantial collection of LoRA adapters derived from one base model. We observe that this paradigm presents significant opportunities for batched inference during serving.
To capitalize on these opportunities, we present S-LoRA, a system designed for the scalable serving of many LoRA adapters. S-LoRA stores all adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes Unified Paging.
Unified Paging uses a unified memory pool to manage dynamic adapter weights with different ranks and KV cache tensors with varying sequence lengths. Additionally, S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation. Collectively, these features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead.
Compared to state-of-the-art libraries such as HuggingFace PEFT and vLLM (with naive support of LoRA serving), S-LoRA can improve the throughput by up to 4 times and increase the number of served adapters by several orders of magnitude. As a result, S-LoRA enables scalable serving of many task-specific fine-tuned models and offers the potential for large-scale customized fine-tuning services.
3.2. Levels of AGI: Operationalizing Progress on the Path to AGI

We propose a framework for classifying the capabilities and behavior of Artificial General Intelligence (AGI) models and their precursors. This framework introduces levels of AGI performance, generality, and autonomy.
It is our hope that this framework will be useful in an analogous way to the levels of autonomous driving, by providing a common language to compare models, assess risks, and measure progress along the path to AGI. To develop our framework, we analyze existing definitions of AGI and distill six principles that a useful ontology for AGI should satisfy.
These principles include focusing on capabilities rather than mechanisms; separately evaluating generality and performance; and defining stages along the path toward AGI, rather than focusing on the endpoint. With these principles in mind, we propose ‘Levels of AGI’ based on depth (performance) and breadth (generality) of capabilities, and reflect on how current systems fit into this ontology.
We discuss the challenging requirements for future benchmarks that quantify the behavior and capabilities of AGI models against these levels. Finally, we discuss how these levels of AGI interact with deployment considerations such as autonomy and risk, and emphasize the importance of carefully selecting Human-AI Interaction paradigms for responsible and safe deployment of highly capable AI systems.
3.3. Co-training and Co-distillation for Quality Improvement and Compression of Language Models

Knowledge Distillation (KD) compresses computationally expensive pre-trained language models (PLMs) by transferring their knowledge to smaller models, allowing their use in resource-constrained or real-time settings.
However, most smaller models fail to surpass the performance of the original larger model, resulting in sacrificing performance to improve inference speed. To address this issue, we propose Co-Training and Co-Distillation (CTCD), a novel framework that improves performance and inference speed together by co-training two models while mutually distilling knowledge.
The CTCD framework successfully achieves this based on two significant findings:
Distilling knowledge from the smaller model to the larger model during co-training improves the performance of the larger model.
The enhanced performance of the larger model further boosts the performance of the smaller model.
The CTCD framework shows promise as it can be combined with existing techniques like architecture design or data augmentation, replacing one-way KD methods, to achieve further performance improvement. Extensive ablation studies demonstrate the effectiveness of CTCD, and the small model distilled by CTCD outperforms the original larger model by a significant margin of 1.66 on the GLUE benchmark.
3.4. TEAL: Tokenize and Embed ALL for Multi-modal Large Language Models

Despite Multi-modal Large Language Models (MM-LLMs) have made exciting strides recently, they are still struggling to efficiently model the interactions among multi-modal inputs and the generation in non-textual modalities.
In this work, we propose TEAL (Tokenize and Embed ALl)}, an approach to treat the input from any modality as a token sequence and learn a joint embedding space for all modalities.
Specifically, for the input from any modality, TEAL first discretizes it into a token sequence with the off-the-shelf tokenizer and embeds the token sequence into a joint embedding space with a learnable embedding matrix. MM-LLMs just need to predict the multi-modal tokens autoregressively as the textual LLMs do.
Finally, the corresponding de-tokenizer is applied to generate the output in each modality based on the predicted token sequence. With the joint embedding space, TEAL enables the frozen LLMs to perform both understanding and generation tasks involving non-textual modalities, such as image and audio.
Thus, the textual LLM can just work as an interface and maintain its high performance in textual understanding and generation. Experiments show that TEAL achieves substantial improvements in multi-modal understanding, and implements a simple scheme for multi-modal generations.
3.5. GLaMM: Pixel Grounding Large Multimodal Model

Large Multimodal Models (LMMs) extend Large Language Models to the vision domain. Initial efforts towards LMMs used holistic images and text prompts to generate ungrounded textual responses.
Very recently, region-level LMMs have been used to generate visually grounded responses. However, they are limited to only referring to a single object category at a time, require users to specify the regions in inputs, or cannot offer dense pixel-wise object grounding.
In this work, we present Grounding LMM (GLaMM), the first model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks. GLaMM not only grounds objects appearing in the conversations but is flexible enough to accept both textual and optional visual prompts (region of interest) as input.
This empowers users to interact with the model at various levels of granularity, both in textual and visual domains. Due to the lack of standard benchmarks for the novel setting of generating visually grounded detailed conversations, we introduce a comprehensive evaluation protocol with our curated grounded conversations. Our proposed Grounded Conversation Generation (GCG) task requires densely grounded concepts in natural scenes at a large scale.
To this end, we propose a densely annotated Grounding-anything Dataset (GranD) using our proposed automated annotation pipeline that encompasses 7.5M unique concepts grounded in a total of 810M regions available with segmentation masks. Besides GCG, GLaMM also performs effectively on several downstream tasks e.g., referring expression segmentation, image and region-level captioning, and vision-language conversations.
3.6. Prompt Cache: Modular Attention Reuse for Low-Latency Inference

We present Prompt Cache, an approach for accelerating inference for large language models (LLM) by reusing attention states across different LLM prompts. Many input prompts have overlapping text segments, such as system messages, prompt templates, and documents provided for context.
Our key insight is that by precomputing and storing the attention states of these frequently occurring text segments on the inference server, we can efficiently reuse them when these segments appear in user prompts. Prompt Cache employs a schema to define such reusable text segments, called prompt modules explicitly.
The schema ensures positional accuracy during attention state reuse and provides users with an interface to access cached states in their prompt. Using a prototype implementation, we evaluate Prompt Cache across several LLMs. Prompt Cache significantly reduces latency in time-to-first-token, especially for longer prompts such as document-based question answering and recommendations.
The improvements range from 8x for GPU-based inference to 60x for CPU-based inference, all while maintaining output accuracy and without the need for model parameter modifications.
4. Responsible AI & LLM Ethics
4.1. Unveiling Safety Vulnerabilities of Large Language Models

As large language models become more prevalent, their possible harmful or inappropriate responses are a cause for concern. This paper introduces a unique dataset containing adversarial examples in the form of questions, which we call AttaQ, designed to provoke such harmful or inappropriate responses.
We assess the efficacy of our dataset by analyzing the vulnerabilities of various models when subjected to it. Additionally, we introduce a novel automatic approach for identifying and naming vulnerable semantic regions — input semantic areas for which the model is likely to produce harmful outputs.
This is achieved through the application of specialized clustering techniques that consider both the semantic similarity of the input attacks and the harmfulness of the model’s responses. Automatically identifying vulnerable semantic regions enhances the evaluation of model weaknesses, facilitating targeted improvements to its safety mechanisms and overall reliability.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
