


Top Important LLM Papers for the Week from 15/04 to 21/04
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Third Week of April 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
LLM Optimization & Quantization
LLM Ethics & Safety
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. OpenBezoar: Small, Cost-Effective, and Open Models Trained on Mixes of Instruction Data
Instruction fine-tuning pretrained LLMs for diverse downstream tasks has demonstrated remarkable success and has captured the interest of both academics and practitioners. To ensure such fine-tuned LLMs align with human preferences, techniques such as RLHF and DPO have emerged.
At the same time, there is increasing interest in smaller parameter counts for models. In this work, using OpenLLaMA 3Bv2 as a base model, we describe the recipe used to fine-tune the OpenBezoar family of models.
In this recipe: We first generate synthetic instruction fine-tuning data using an open and commercially non-restrictive instruction fine-tuned variant of the Falcon-40B model under three schemes based on: LaMini-LM, WizardLM/Evol-Instruct (with databricks-dolly-15k as a seed dataset) and Orca (with the Flan Collection as a seed dataset), then filter these generations using GPT-4 as a human proxy.
We then perform cost-effective QLoRA-based supervised fine-tuning sequentially with each scheme. The resulting checkpoint is further fine-tuned with a subset of the HH-RLHF dataset to minimize distribution shift before using the DPO loss to obtain the final checkpoint.
Evaluation is done with the LM Eval Harness tasks/metrics as well as on MT-Bench using the “LLM-as-a-judge” framework with Claude 2.1, with the finding that the final checkpoint, “OpenBezoar-HH-RLHF-DPO”, demonstrates superior performance over many models at the 3B parameter scale, even outperforming the top model in one of the categories on the Huggingface Open LLM Leaderboard.
1.2. TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding

With large language models (LLMs) widely deployed in long content generation recently, there has emerged an increasing demand for efficient long-sequence inference support.
However, the key-value (KV) cache, which is stored to avoid re-computation, has emerged as a critical bottleneck by growing linearly in size with the sequence length.
Due to the auto-regressive nature of LLMs, the entire KV cache will be loaded for every generated token, resulting in low utilization of computational cores and high latency. While various compression methods for KV cache have been proposed to alleviate this issue, they suffer from degradation in generation quality.
We introduce TriForce, a hierarchical speculative decoding system that is scalable to long sequence generation. This approach leverages the original model weights and dynamic sparse KV cache via retrieval as a draft model, which serves as an intermediate layer in the hierarchy and is further speculated by a smaller model to reduce its drafting latency.
TriForce not only facilitates impressive speedups for Llama2–7B-128K, achieving up to 2.31 times on an A100 GPU but also showcases scalability in handling even longer contexts.
For the offloading setting on two RTX 4090 GPUs, TriForce achieves 0.108s/tokenx2014only half as slow as the auto-regressive baseline on an A100, which attains 7.78times on our optimized offloading system.
Additionally, TriForce performs 4.86 times more than DeepSpeed-Zero-Inference on a single RTX 4090 GPU. TriForce’s robustness is highlighted by its consistently outstanding performance across various temperatures.
1.3. On Speculative Decoding for Multimodal Large Language Models

Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively.
In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model.
Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37 times using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
1.4. Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models

We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results.
We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute classes. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations.
On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus.
On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4–0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra.
1.5. Learn Your Reference Model for Real Good Alignment
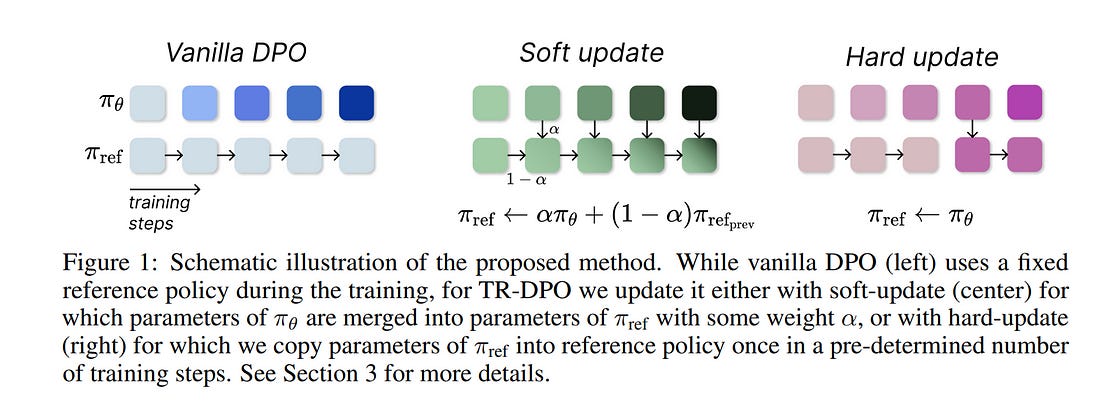
The complexity of the alignment problem stems from the fact that existing methods are unstable. Researchers continuously invent various tricks to address this shortcoming.
For instance, in the fundamental Reinforcement Learning From Human Feedback (RLHF) technique of Language Model alignment, in addition to reward maximization, the Kullback-Leibler divergence between the trainable policy and the SFT policy is minimized.
This addition prevents the model from being overfitted to the Reward Model (RM) and generating texts that are out-of-domain for the RM. The Direct Preference Optimization (DPO) method reformulates the optimization task of RLHF and eliminates the Reward Model while tacitly maintaining the requirement for the policy to be close to the SFT policy.
In our paper, we argue that this implicit limitation in the DPO method leads to sub-optimal results. We propose a new method called Trust Region DPO (TR-DPO), which updates the reference policy during training. With such a straightforward update, we demonstrate the effectiveness of TR-DPO against DPO on the Anthropic HH and TLDR datasets.
We show that TR-DPO outperforms DPO by up to 19%, measured by automatic evaluation with GPT-4. The new alignment approach that we propose allows us to improve the quality of models across several parameters at once, such as coherence, correctness, level of detail, helpfulness, and harmlessness.
2. LLM Reasoning
2.1. Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
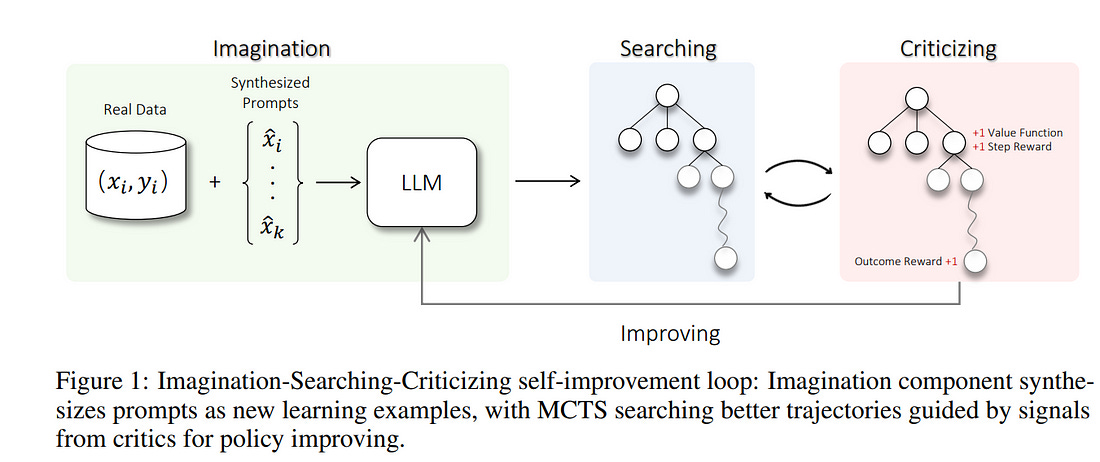
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involve complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs’ reasoning abilities.
However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning tasks, remains dubious.
In this paper, we introduce AlphaLLM for the self-improvement of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations.
Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness of search spaces of language tasks, and the subjective nature of feedback in language tasks.
AlphaLLM is comprised of a prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
3. LLM Training, Evaluation & Inference
3.1. Pre-training Small Base LMs with Fewer Tokens

We study the effectiveness of a simple approach to develop a small base language model (LM) starting from an existing large base LM: first, inherit a few transformer blocks from the larger LM, and then train this smaller model on a very small subset (0.1\%) of the raw pretraining data of the larger model.
We call our simple recipe Inheritune and first demonstrate it for building a small base LM with 1.5B parameters using 1B tokens (and a starting few layers of larger LM of 3B parameters); we do this using a single A6000 GPU for less than half a day.
Across 9 diverse evaluation datasets as well as the MMLU benchmark, the resulting model compares favorably to publicly available base models of 1B-2B size, some of which have been trained using 50–1000 times more tokens.
We investigate Inheritune in a slightly different setting where we train small LMs utilizing larger LMs and their full pre-training dataset. Here we show that smaller LMs trained to utilize some of the layers of GPT2-medium (355M) and GPT-2-large (770M) can effectively match the val loss of their bigger counterparts when trained from scratch for the same number of training steps on the OpenWebText dataset with 9B tokens. We analyze our recipe with extensive experiments and demonstrate its efficacy in diverse settings.
3.2. Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
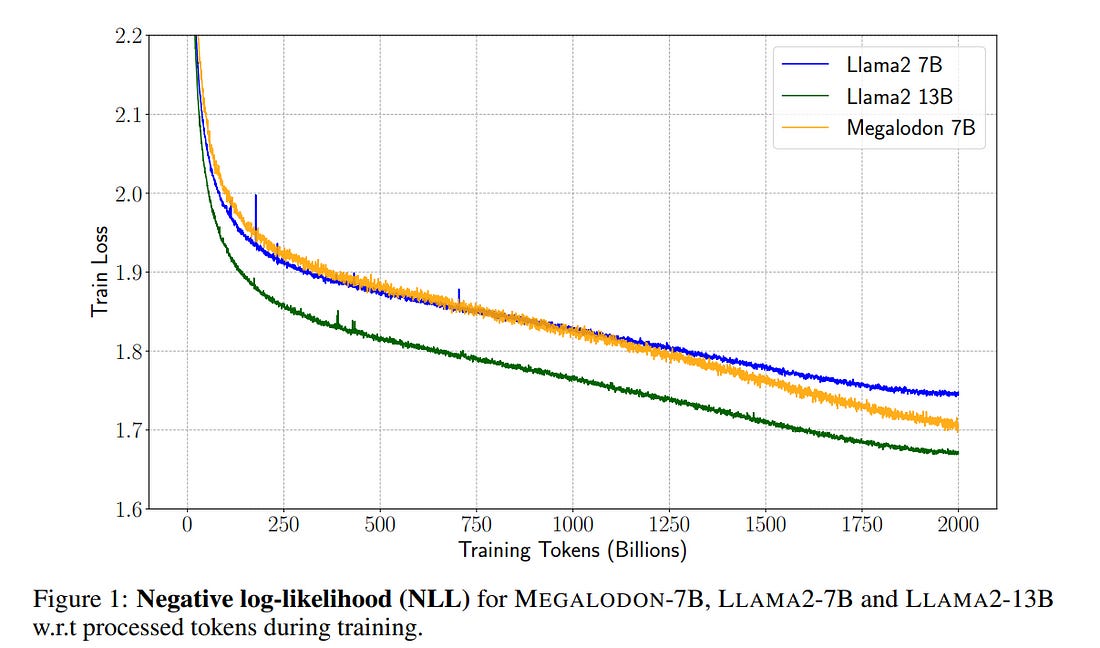
The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy.
We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length. Megalodon inherits the architecture of Mega (exponential moving average with gated attention) and further introduces multiple technical components to improve its capability and stability, including complex exponential moving average (CEMA), timestep normalization layer, normalized attention mechanism and pre-norm with two-hop residual configuration.
In a controlled head-to-head comparison with Llama2, Megalodon achieves better efficiency than Transformer on the scale of 7 billion parameters and 2 trillion training tokens. Megalodon reaches a training loss of 1.70, landing mid-way between Llama2–7B (1.75) and 13B (1.67).
3.3. TextHawk: Exploring Efficient Fine-Grained Perception of Multimodal Large Language Models

Multimodal Large Language Models (MLLMs) have shown impressive results on various multimodal tasks. However, most existing MLLMs are not well suited for document-oriented tasks, which require fine-grained image perception and information compression.
In this paper, we present TextHawk, a MLLM that is specifically designed for document-oriented tasks, while preserving the general capabilities of MLLMs. TextHawk is aimed to explore efficient fine-grained perception by designing four dedicated components.
Firstly, a ReSampling and ReArrangement (ReSA) module is proposed to reduce the redundancy in the document texts and lower the computational cost of the MLLM. We explore encoding the positions of each local feature by presenting Scalable conditional embeddings (SPEs), which can preserve the scalability of various image sizes.
A Query Proposal Network (QPN) is then adopted to initialize the queries dynamically among different sub-images. To further enhance the fine-grained visual perceptual ability of the MLLM, we design a Multi-Level Cross-Attention (MLCA) mechanism that captures the hierarchical structure and semantic relations of document images.
Furthermore, we create a new instruction-tuning dataset for document-oriented tasks by enriching the multimodal document data with Gemini Pro. We conduct extensive experiments on both general and document-oriented MLLM benchmarks and show that TextHawk outperforms the state-of-the-art methods, demonstrating its effectiveness and superiority in fine-grained document perception and general abilities.
4. LLM Optimization & Quantization
4.1. Dataset Reset Policy Optimization for RLHF
Reinforcement Learning (RL) from Human Preference-based feedback is a popular paradigm for fine-tuning generative models, which has produced impressive models such as GPT-4 and Claude3 Opus.
This framework often consists of two steps: learning a reward model from an offline preference dataset followed by running online RL to optimize the learned reward model. In this work, leveraging the idea of reset, we propose a new RLHF algorithm with provable guarantees.
Motivated by the fact that offline preference dataset provides informative states (i.e., data that is preferred by the labelers), our new algorithm, Dataset Reset Policy Optimization (DR-PO), integrates the existing offline preference dataset into the online policy training procedure via dataset reset: it directly resets the policy optimizer to the states in the offline dataset, instead of always starting from the initial state distribution.
In theory, we show that DR-PO learns to perform at least as well as any policy that is covered by the offline dataset under general function approximation with finite sample complexity.
In experiments, we demonstrate that on both the TL;DR summarization and the Anthropic Helpful Harmful (HH) dataset, the generation from DR-PO is better than that from Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO), under the metric of GPT4 win-rate.
4.2. Compression Represents Intelligence Linearly

There is a belief that learning to compress well will lead to intelligence. Recently, language modeling has been equivalent to compression, which offers a compelling rationale for the success of large language models (LLMs): the development of more advanced language models is essentially enhancing compression which facilitates intelligence.
Despite such appealing discussions, little empirical evidence is present for the interplay between compression and intelligence. In this work, we examine their relationship in the context of LLMs, treating LLMs as data compressors.
Given the abstract concept of “intelligence”, we adopt the average downstream benchmark scores as a surrogate, specifically targeting intelligence related to knowledge and commonsense, coding, and mathematical reasoning.
Across 12 benchmarks, our study brings together 30 public LLMs that originate from diverse organizations. Remarkably, we find that LLMs’ intelligence — reflected by average benchmark scores — almost linearly correlates with their ability to compress external text corpora. These results support the belief that superior compression indicates greater intelligence.
Furthermore, our findings suggest that compression efficiency, as an unsupervised metric derived from raw text corpora, serves as a reliable evaluation measure that is linearly associated with the model capabilities. We open-source our compression datasets as well as our data collection pipelines to facilitate future researchers to assess compression properly.
5. LLM Fine-Tuning
5.1. Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment

Aligning language models (LMs) based on human-annotated preference data is a crucial step in obtaining practical and performant LM-based systems. However, multilingual human preference data are difficult to obtain at scale, making it challenging to extend this framework to diverse languages.
In this work, we evaluate a simple approach for zero-shot cross-lingual alignment, where a reward model is trained on preference data in one source language and directly applied to other target languages.
On summarization and open-ended dialog generation, we show that this method is consistently successful under comprehensive evaluation settings, including human evaluation: cross-lingually aligned models are preferred by humans over unaligned models on up to >70% of evaluation instances.
We moreover find that a different-language reward model sometimes yields better-aligned models than a same-language reward model. We also identify best practices when there is no language-specific data for even supervised fine-tuning, another component in alignment.
Check out AlphaSignal to get a weekly summary of the top models, repos, and papers in AI. Read by 180,000+ engineers and researchers.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
