


Top Important LLM Papers for the Week from 29/04 to 05/05
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress.
This article summarizes some of the most important LLM papers published during the Fourth Week of April 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
LLM Optimization & Quantization
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. Extending Llama-3’s Context Ten-Fold Overnight

We extend the context length of Llama-3–8B-Instruct from 8K to 80K via QLoRA fine-tuning. The entire training cycle is super efficient, which takes 8 hours on one 8xA800 (80G) GPU machine.
The resulting model exhibits superior performances across a broad range of evaluation tasks, such as NIHS, topic retrieval, and long-context language understanding; meanwhile, it also well preserves the original capability over short contexts.
The dramatic context extension is mainly attributed to merely 3.5K synthetic training samples generated by GPT-4, which indicates the LLMs’ inherent (yet largely underestimated) potential to extend its original context length. The context length could be extended far beyond 80K with more computation resources.
1.2. Capabilities of Gemini Models in Medicine

Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge, and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine.
Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders.
We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin.
On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy.
On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%.
We demonstrate the effectiveness of Med-Gemini’s long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning.
Finally, Med-Gemini’s performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research, and education.
Taken together, our results offer compelling evidence for Med-Gemini’s potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
1.3. Better & Faster Large Language Models via Multi-token Prediction
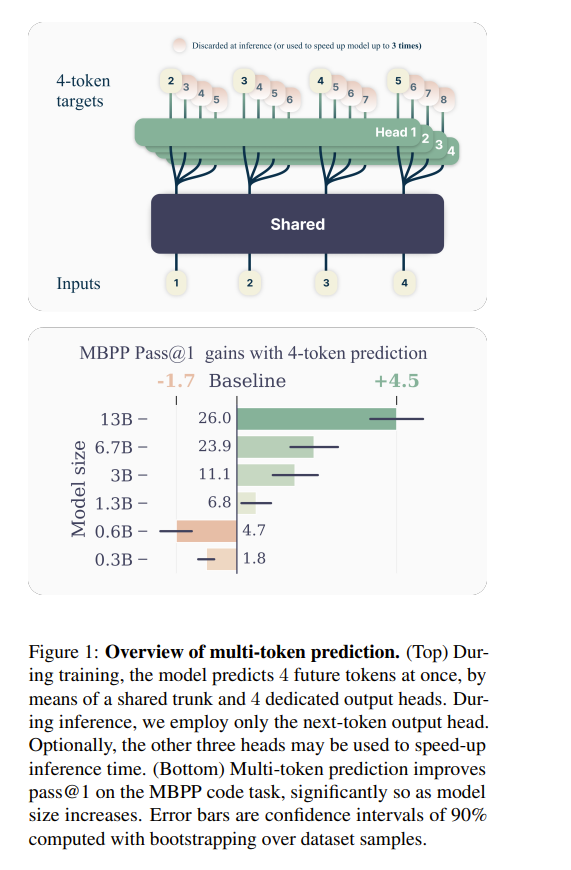
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency.
More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models.
The method is increasingly useful for larger model sizes and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points.
Our 13B parameter models solve 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
1.4. LEGENT: Open Platform for Embodied Agents

Despite advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), their integration into language-grounded, human-like embodied agents remains incomplete, hindering complex real-life task performance in physical environments.
Existing integrations often feature limited open sourcing, challenging collective progress in this field. We introduce LEGENT, an open, scalable platform for developing embodied agents using LLMs and LMMs.
LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale.
In our experiments, an embryonic vision-language-action model trained on LEGENT-generated data surpasses GPT-4V in embodied tasks, showcasing promising generalization capabilities.
1.5. Octopus v4: Graph of language models

Language models have been effective in many applications, yet the most sophisticated models are often proprietary. For example, GPT-4 by OpenAI and various models by Anthropic are expensive and consume substantial energy.
In contrast, the open-source community has produced competitive models, like Llama3. Furthermore, niche-specific smaller language models, such as those tailored for legal, medical, or financial tasks, have outperformed their proprietary counterparts.
This paper introduces a novel approach that employs functional tokens to integrate multiple open-source models, each optimized for particular tasks. Our newly developed Octopus v4 model leverages functional tokens to intelligently direct user queries to the most appropriate vertical model and reformat the query to achieve the best performance.
Octopus v4, an evolution of the Octopus v1, v2, and v3 models, excels in selection and parameter understanding and reformatting. Additionally, we explore the use of graphs as a versatile data structure that effectively coordinates multiple open-source models by harnessing the capabilities of the Octopus model and functional tokens.
1.6. WildChat: 1M ChatGPT Interaction Logs in the Wild

Chatbots such as GPT-4 and ChatGPT are now serving millions of users. Despite their widespread use, there remains a lack of public datasets showcasing how these tools are used by a population of users in practice.
To bridge this gap, we offered free access to ChatGPT for online users in exchange for their affirmative, consensual opt-in to anonymously collect their chat transcripts and request headers. From this, we compiled WildChat, a corpus of 1 million user-ChatGPT conversations, which consists of over 2.5 million interaction turns.
We compare WildChat with other popular user-chatbot interaction datasets, and find that our dataset offers the most diverse user prompts, contains the largest number of languages, and presents the richest variety of potentially toxic use cases for researchers to study.
In addition to timestamped chat transcripts, we enrich the dataset with demographic data, including state, country, and hashed IP addresses, alongside request headers. This augmentation allows for a more detailed analysis of user behaviors across different geographical regions and temporal dimensions.
Finally, because it captures a broad range of use cases, we demonstrate the dataset’s potential utility in fine-tuning instruction-following models.
1.7. LLM-AD: Large Language Model-based Audio Description System

The development of Audio Description (AD) has been a pivotal step forward in making video content more accessible and inclusive. Traditionally, AD production has demanded a considerable amount of skilled labor, while existing automated approaches still necessitate extensive training to integrate multimodal inputs and tailor the output from a captioning style to an AD style.
In this paper, we introduce an automated AD generation pipeline that harnesses the potent multimodal and instruction-following capacities of GPT-4V(ision). Notably, our methodology employs readily available components, eliminating the need for additional training.
It produces ADs that not only comply with established natural language AD production standards but also maintain contextually consistent character information across frames, courtesy of a tracking-based character recognition module.
A thorough analysis on the MAD dataset reveals that our approach achieves a performance on par with learning-based methods in automated AD production, as substantiated by a CIDEr score of 20.5.
1.8. Is Bigger Edit Batch Size Always Better? — An Empirical Study on Model Editing with Llama-3

This study presents a targeted model editing analysis focused on the latest large language model, Llama-3. We explore the efficacy of popular model editing techniques — ROME, MEMIT, and EMMET, which are designed for precise layer interventions.
We identify the most effective layers for targeted edits through an evaluation that encompasses up to 4096 edits across three distinct strategies: sequential editing, batch editing, and a hybrid approach we call sequential-batch editing.
Our findings indicate that increasing edit batch sizes may degrade model performance more significantly than using smaller edit batches sequentially for an equal number of edits.
With this, we argue that sequential model editing is an important component for scaling model editing methods and future research should focus on methods that combine both batched and sequential editing.
This observation suggests a potential limitation in current model editing methods which push towards bigger edit batch sizes, and we hope it paves the way for future investigations into optimizing batch sizes and model editing performance.
1.9. Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting

Speculative decoding has demonstrated its effectiveness in accelerating the inference of large language models while maintaining a consistent sampling distribution. However, the conventional approach of training a separate draft model to achieve a satisfactory token acceptance rate can be costly.
Drawing inspiration from early exiting, we propose a novel self-speculative decoding framework Kangaroo, which uses a fixed shallow sub-network as a self-draft model, with the remaining layers serving as the larger target model.
We train a lightweight and efficient adapter module on top of the sub-network to bridge the gap between the sub-network and the full model’s representation ability.
It is noteworthy that the inference latency of the self-draft model may no longer be negligible compared to the large model, necessitating strategies to increase the token acceptance rate while minimizing the drafting steps of the small model.
To address this challenge, we introduce an additional early exiting mechanism for generating draft tokens. Specifically, we halt the small model’s subsequent prediction during the drafting phase once the confidence level for the current token falls below a certain threshold.
Extensive experiments on the Spec-Bench demonstrate the effectiveness of the Kangaroo. Under single-sequence verification, Kangaroo achieves speedups up to 1.68 times on Spec-Bench, outperforming Medusa-1 with 88.7\% fewer additional parameters (67M compared to 591M).
1.10. KAN: Kolmogorov-Arnold Networks

Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes (“neurons”), KANs have learnable activation functions on edges (“weights”).
KANs have no linear weights at all — every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interoperability.
For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs.
For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws.
In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today’s deep learning models which rely heavily on MLPs.
2. LLM Reasoning
2.1. Iterative Reasoning Preference Optimization

Iterative preference optimization methods have recently been shown to perform well for general instruction tuning tasks, but typically make little improvement on reasoning tasks.
In this work, we develop an iterative approach that optimizes the preference between competing generated Chain-of-Thought (CoT) candidates by optimizing for winning vs. losing reasoning steps that lead to the correct answer.
We train using a modified DPO loss (Rafailov et al., 2023) with an additional negative log-likelihood term, which we find to be crucial. We show reasoning improves across repeated iterations of this scheme. While only relying on examples in the training set, our approach results in increasing accuracy for Llama-2–70B-Chat from 55.6% to 81.6% on GSM8K (and 88.7% with majority voting out of 32 samples), from 12.5% to 20.8% on MATH, and from 77.8% to 86.7% on ARC-Challenge, which outperforms other Llama-2-based models not relying on additionally sourced datasets.
3. LLM Training, Evaluation & Inference
3.1. Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
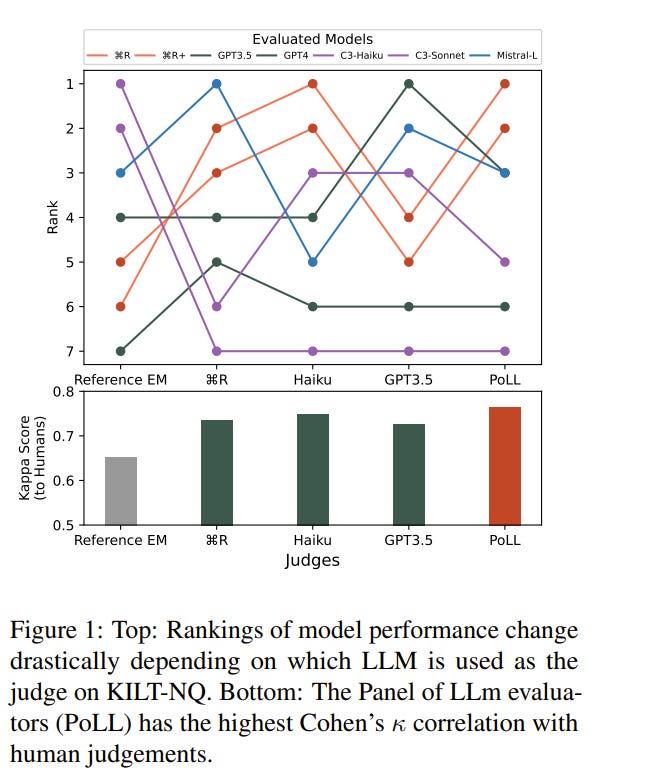
As Large Language Models (LLMs) have become more advanced, they have outpaced our abilities to accurately evaluate their quality. Not only is finding data to adequately probe particular model properties difficult, but evaluating the correctness of a model’s freeform generation alone is a challenge.
To address this, many evaluations now rely on using LLMs themselves as judges to score the quality of outputs from other LLMs. Evaluations most commonly use a single large model like GPT4. While this method has grown in popularity, it is costly and has been shown to introduce intramodel bias, and in this work, we find that very large models are often unnecessary.
We propose instead to evaluate models using a Panel of LLm evaluators (PoLL). Across three distinct judge settings and spanning six different datasets, we find that using a PoLL composed of a larger number of smaller models outperforms a single large judge, exhibits less intra-model bias due to its composition of disjoint model families, and does so while being over seven times less expensive.
3.2. LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
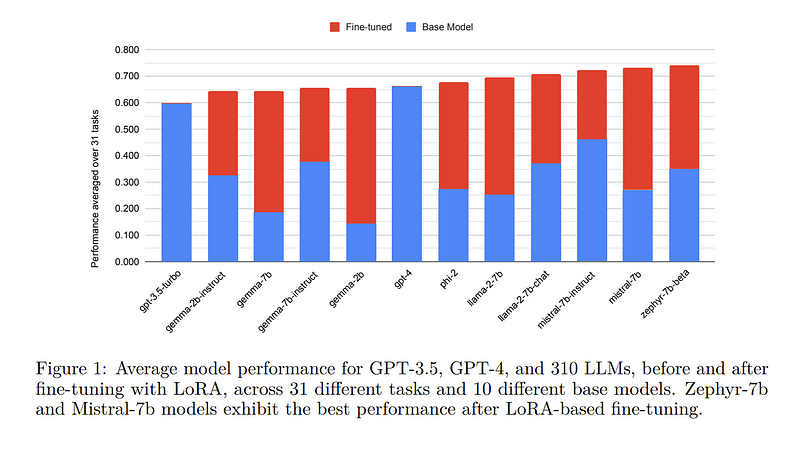
Low-Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning.
We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low-rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average.
Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning.
Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading.
LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
3.3. Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
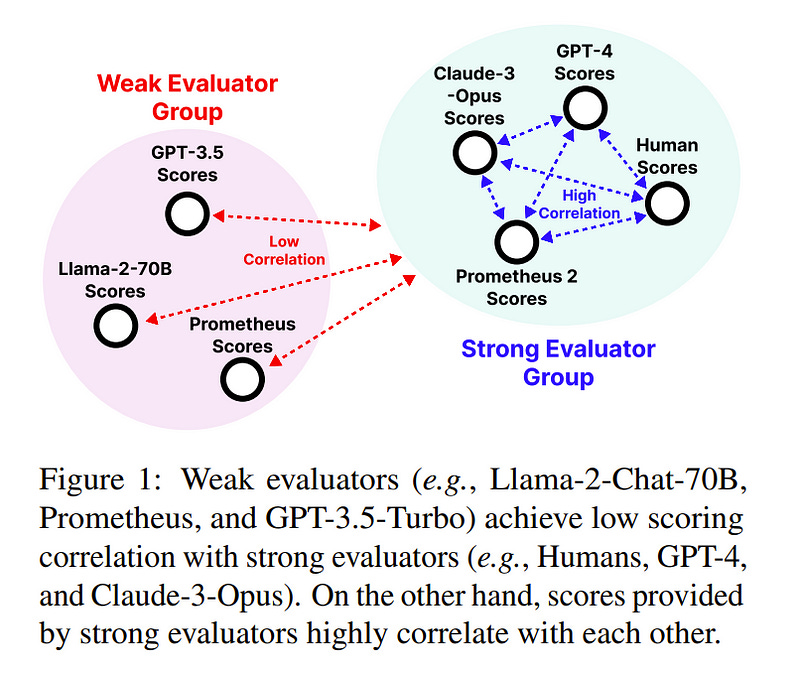
Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the development of open-source LMs specialized in evaluations.
On the other hand, existing open evaluator LMs exhibit critical shortcomings:
They issue scores that significantly diverge from those assigned by humans
They lack the flexibility to perform both direct assessment and pairwise ranking, the two most prevalent forms of assessment.
Additionally, they do not possess the ability to evaluate based on custom evaluation criteria, focusing instead on general attributes like helpfulness and harmlessness. To address these issues, we introduce Prometheus 2, a more powerful evaluator LM than its predecessor that closely mirrors human and GPT-4 judgments.
Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with user-defined evaluation criteria. On four direct assessment benchmarks and four pairwise ranking benchmarks, Prometheus 2 scores the highest correlation and agreement with humans and proprietary LM judges among all tested open evaluator LMs.
3.4. A Careful Examination of Large Language Model Performance on Grade School Arithmetic

Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability.
To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning.
We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more.
When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes.
At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman’s r²=0.32) between a model’s probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
3.5. AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs

While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to the generation of inappropriate or harmful content.
Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming.
On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that perplexity-based filters can easily detect, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space.
In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, sim800times faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM.
This process alternates between two steps:
Generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions
Low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes.
The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response.
Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs.
Further, we demonstrate that by fine-tuning a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
4. LLM Optimization & Quantization
4.1. NeMo-Aligner: Scalable Toolkit for Efficient Model Alignment

Aligning Large Language Models (LLMs) with human values and preferences is essential for making them helpful and safe. However, building efficient tools to perform alignment can be challenging, especially for the largest and most competent LLMs which often contain tens or hundreds of billions of parameters.
We create NeMo-Aligner, a toolkit for model alignment that can efficiently scale to using hundreds of GPUs for training. NeMo-Aligner comes with highly optimized and scalable implementations for major paradigms of model alignment such as Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), SteerLM, and Self-Play Fine-Tuning (SPIN).
Additionally, our toolkit supports running most of the alignment techniques in a Parameter Efficient Fine-Tuning (PEFT) setting. NeMo-Aligner is designed for extensibility, allowing support for other alignment techniques with minimal effort.
4.2. FLAME: Factuality-Aware Alignment for Large Language Models

Alignment is a standard procedure to fine-tune pre-trained large language models (LLMs) to follow natural language instructions and serve as helpful AI assistants.
We have observed, however, that the conventional alignment process fails to enhance the factual accuracy of LLMs, and often leads to the generation of more false facts (i.e. hallucination).
In this paper, we study how to make the LLM alignment process more factual, by first identifying factors that lead to hallucination in both alignment steps:\ supervised fine-tuning (SFT) and reinforcement learning (RL). In particular, we find that training the LLM on new knowledge or unfamiliar texts can encourage hallucination.
This makes SFT less factual as it trains on human-labeled data that may be novel to the LLM. Furthermore, reward functions used in standard RL can also encourage hallucination, because it guides the LLM to provide more helpful responses on a diverse set of instructions, often preferring longer and more detailed responses.
Based on these observations, we propose factuality-aware alignment, comprised of factuality-aware SFT and factuality-aware RL through direct preference optimization. Experiments show that our proposed factuality-aware alignment guides LLMs to output more factual responses while maintaining instruction-following capability.
4.3. Self-Play Preference Optimization for Language Model Alignment
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment.
In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed Self-Play Preference Optimization (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys a theoretical convergence guarantee.
Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO).
In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0.
It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
