


Top Important LLM Papers for the Week from 16/10 to 22/10
Stay Relevant to Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, it’s important for researchers and engineers to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the third week of October.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. The final sections discuss papers related to training LLMs safely and ensuring their behavior remains beneficial.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Fine Tuning
Text Generation & Summarization
Reinforcement Learning from Human Feedback (RLHF)
LLM Reasoning
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. LLM Progress & Benchmarking
1.1. Can GPT models be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on mock CFA Exams
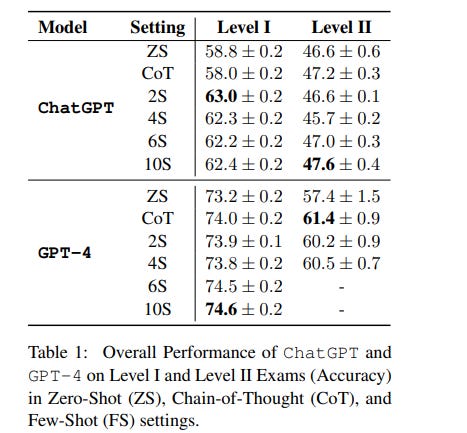
Large Language Models (LLMs) have demonstrated remarkable performance on a wide range of Natural Language Processing (NLP) tasks, often matching or even beating state-of-the-art task-specific models. This study aims at assessing the financial reasoning capabilities of LLMs.
The researchers leverage mock exam questions of the Chartered Financial Analyst (CFA) Program to conduct a comprehensive evaluation of ChatGPT and GPT-4 in financial analysis, considering Zero-Shot (ZS), Chain-of-Thought (CoT), and Few-Shot (FS) scenarios. They present an in-depth analysis of the models’ performance and limitations, and estimate whether they would have a chance at passing the CFA exams.
Finally, they outline insights into potential strategies and improvements to enhance the applicability of LLMs in finance. In this perspective, the authors hope this work paves the way for future studies to continue enhancing LLMs for financial reasoning through rigorous evaluation.
1.2. Table-GPT: Table-tuned GPT for Diverse Table Tasks
Language models, such as GPT-3.5 and ChatGPT, demonstrate remarkable abilities to follow diverse human instructions and perform a wide range of tasks. However, when probing language models using a range of basic table-understanding tasks, we observe that today’s language models are still sub-optimal in many table-related tasks, likely because they are pre-trained predominantly on one-dimensional natural-language texts, whereas relational tables are two-dimensional objects.
In this work, the authors propose a new “table-tuning” paradigm, where they continue to train/fine-tune language models like GPT-3.5 and ChatGPT, using diverse table-tasks synthesized from real tables as training data, with the goal of enhancing language models’ ability to understand tables and perform table tasks.
They show that the resulting Table-GPT models demonstrate:
Better table-understanding capabilities, by consistently outperforming the vanilla GPT-3.5 and ChatGPT, on a wide-range of table tasks, including holdout unseen tasks.
Strong generalizability, in its ability to respond to diverse human instructions to perform new table-tasks, in a manner similar to GPT-3.5 and ChatGPT.
1.3. CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules

LLMs have already become quite proficient at solving simpler programming tasks like those in HumanEval or MBPP benchmarks. However, solving more complex and competitive programming tasks is still quite challenging for these models possibly due to their tendency to generate solutions as monolithic code blocks instead of decomposing them into logical sub-tasks and sub-modules.
On the other hand, experienced programmers instinctively write modularized code with abstraction for solving complex tasks, often reusing previously developed modules. To address this gap, the authors propose CodeChain, a novel framework for inference that elicits modularized code generation through a chain of self-revisions, each being guided by some representative sub-modules generated in previous iterations.
Concretely, CodeChain first instructs the LLM to generate modularized codes through chain-of-thought prompting. Then it applies a chain of self-revisions by iterating the two steps:
Extracting and clustering the generated sub-modules and selecting the cluster representatives as the more generic and re-usable implementations.
Augmenting the original chain-of-thought prompt with these selected module-implementations and instructing the LLM to re-generate new modularized solutions.
They find that by naturally encouraging the LLM to reuse the previously developed and verified sub-modules, CodeChain can significantly boost both modularity as well as correctness of the generated solutions, achieving relative pass@1 improvements of 35% on APPS and 76% on CodeContests.
It is shown to be effective on both OpenAI LLMs as well as open-sourced LLMs like WizardCoder. They also conduct comprehensive ablation studies with different methods of prompting, number of clusters, model sizes, program qualities, etc., to provide useful insights that underpin CodeChain’s success.
1.4. Llemma: An Open Language Model For Mathematics

This paper presents Llemma, a large language model for mathematics. The authors continue pretraining Code Llama on the Proof-Pile-2, a mixture of scientific papers, web data containing mathematics, and mathematical code, yielding Llemma. On the MATH benchmark, Llemma outperforms all known open base models, as well as the unreleased Minerva model suite on an equi-parameter basis.
Moreover, Llemma is capable of tool use and formal theorem proving without any further finetuning. We openly release all artifacts, including 7 billion and 34 billion parameter models, the Proof-Pile-2, and code to replicate our experiments.
1.5. Can GPT models be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on mock CFA Exams

Large Language Models (LLMs) have demonstrated remarkable performance on a wide range of Natural Language Processing (NLP) tasks, often matching or even beating state-of-the-art task-specific models.
This study aims to assess the financial reasoning capabilities of LLMs. We leverage mock exam questions of the Chartered Financial Analyst (CFA) Program to conduct a comprehensive evaluation of ChatGPT and GPT-4 in financial analysis, considering Zero-Shot (ZS), Chain-of-Thought (CoT), and Few-Shot (FS) scenarios. We present an in-depth analysis of the models’ performance and limitations and estimate whether they would have a chance at passing the CFA exams.
Finally, we outline insights into potential strategies and improvements to enhance the applicability of LLMs in finance. From this perspective, we hope this work paves the way for future studies to continue enhancing LLMs for financial reasoning through rigorous evaluation.
1.6. A Zero-Shot Language Agent for Computer Control with Structured Reflection

Large language models (LLMs) have shown increasing capacity for planning and executing a high-level goal in a live computer environment (e.g. MiniWoB++). To perform a task, recent works often require a model to learn from trace examples of the task via either supervised learning or few/many-shot prompting.
Without these trace examples, it remains a challenge how an agent can autonomously learn and improve its control on a computer, which limits the ability of an agent to perform a new task.
They approached this problem with a zero-shot agent that requires no given expert traces. Our agent plans for executable actions on a partially observed environment, and iteratively progresses a task by identifying and learning from its mistakes via self-reflection and structured thought management.
On the easy tasks of MiniWoB++, they show that our zero-shot agent often outperforms recent SoTAs, with more efficient reasoning. For tasks with more complexity, our reflective agent performs on par with prior best models, even though previous works had the advantage of accessing expert traces or additional screen information.
1.7. MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
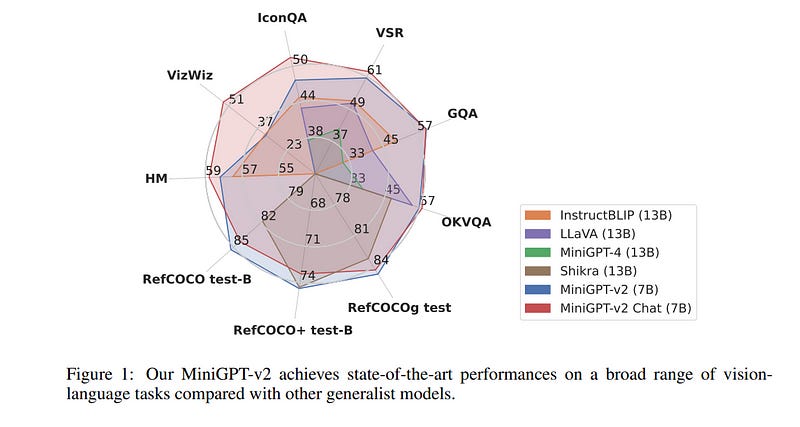
Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, they target to build a unified interface for completing many vision-language tasks including image description, visual question answering, and visual grounding, among others.
The challenge is to use a single model for performing diverse vision-language tasks effectively with simple multi-modal instructions. Towards this objective, they introduce MiniGPT-v2, a model that can be treated as a unified interface for better handling various vision-language tasks. We propose using unique identifiers for different tasks when training the model.
These identifiers enable our model to better distinguish each task instruction effortlessly and also improve the model learning efficiency for each task. After the three-stage training, the experimental results show that MiniGPT-v2 achieves strong performance on many visual question-answering and visual grounding benchmarks compared to other vision-language generalist models.
1.8. Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V

The authors present a Set-of-Mark (SoM), a new visual prompting method, to unleash the visual grounding abilities of large multimodal models (LMMs), such as GPT-4V. As illustrated in Figure (right), they employ off-the-shelf interactive segmentation models, such as SAM, to partition an image into regions at different levels of granularity, and overlay these regions with a set of marks e.g., alphanumerics, masks, and boxes.
Using the marked image as input, GPT-4V can answer the questions that require visual grounding. They perform a comprehensive empirical study to validate the effectiveness of SoM on a wide range of fine-grained vision and multimodal tasks. For example, our experiments show that GPT-4V with SoM outperforms the state-of-the-art fully-finetuned referring segmentation model on RefCOCOg in a zero-shot setting.
1.9. Ranking LLM-Generated Loop Invariants for Program Verification
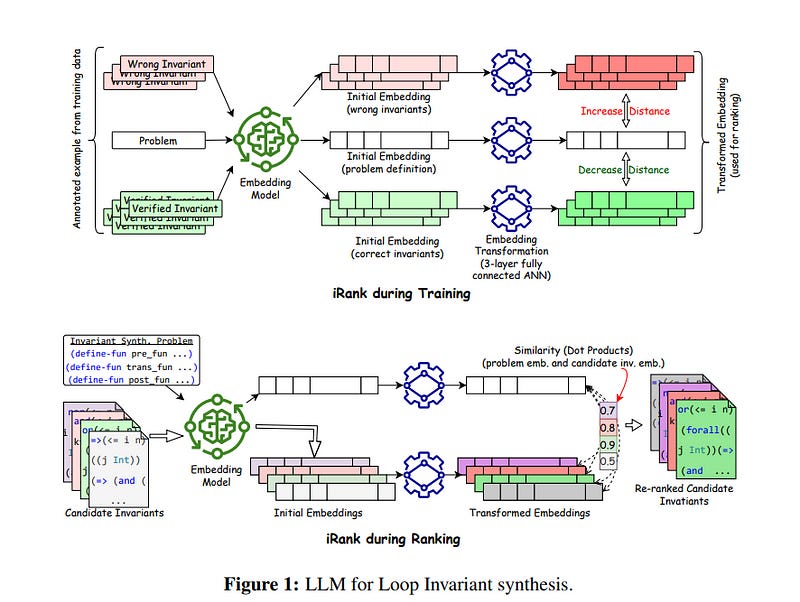
Synthesizing inductive loop invariants is fundamental to automating program verification. In this work, the authors observe that Large Language Models (such as gpt-3.5 or gpt-4) are capable of synthesizing loop invariants for a class of programs in a 0-shot setting, yet require several samples to generate the correct invariants.
This can lead to a large number of calls to a program verifier to establish an invariant. To address this issue, the authors propose a {\it re-ranking} approach for the generated results of LLMs. We have designed a ranker that can distinguish between correct inductive invariants and incorrect attempts based on the problem definition.
The ranker is optimized as a contrastive ranker. Experimental results demonstrate that this re-ranking mechanism significantly improves the ranking of correct invariants among the generated candidates, leading to a notable reduction in the number of calls to a verifier.
2. LLM Fine Tuning
2.1. LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models

Quantization is an indispensable technique for serving Large Language Models (LLMs) and has recently found its way into LoRA fine-tuning. In this work, the authors focus on the scenario where quantization and LoRA fine-tuning are applied together on a pre-trained model.
In such cases, it is common to observe a consistent gap in the performance on downstream tasks between full fine-tuning and quantization plus the LoRA fine-tuning approach.
In response, the authors propose LoftQ (LoRA-Fine-Tuning-aware Quantization), a novel quantization framework that simultaneously quantizes an LLM and finds a proper low-rank initialization for LoRA fine-tuning.
Such an initialization alleviates the discrepancy between the quantized and full-precision model and significantly improves the generalization in downstream tasks. They evaluate our method on natural language understanding, question answering, summarization, and natural language generation tasks.
Experiments show that this method is highly effective and outperforms existing quantization methods, especially in the challenging 2-bit and 2/4-bit mixed precision regimes. We will release our code.
2.2. An Emulator for Fine-Tuning Large Language Models using Small Language Models

Widely used language models (LMs) are typically built by scaling up a two-stage training pipeline: a pre-training stage that uses a very large, diverse dataset of text and a fine-tuning (sometimes, ‘alignment’) stage that uses targeted examples or other specifications of desired behaviors.
While it has been hypothesized that knowledge and skills come from pre-training and fine-tuning mostly filters this knowledge and skillset, this intuition has not been extensively tested.
To aid in doing so, they introduce a novel technique for decoupling the knowledge and skills gained in these two stages, enabling a direct answer to the question, “What would happen if we combined the knowledge learned by a large model during pre-training with the knowledge learned by a small model during fine-tuning (or vice versa)?”
Using an RL-based framework derived from recent developments in learning from human preferences, we introduce emulated fine-tuning (EFT), a principled and practical method for sampling from a distribution that approximates (or ‘emulates’) the result of pre-training and fine-tuning at different scales.
The experiments with EFT show that scaling up fine-tuning tends to improve helpfulness while scaling up pre-training tends to improve factuality. Beyond the decoupling scale, we show that EFT enables test-time adjustment of competing behavioral traits like helpfulness and harmlessness without additional training.
Finally, a special case of emulated fine-tuning, which we call LM up-scaling, avoids resource-intensive fine-tuning of large pre-trained models by ensembling them with small fine-tuned models, essentially emulating the result of fine-tuning the large pre-trained model.
Up-scaling consistently improves the helpfulness and factuality of instruction-following models in the Llama, Llama-2, and Falcon families, without additional hyperparameters or training.
2.3. Improving Large Language Model Fine-tuning for Solving Math Problems
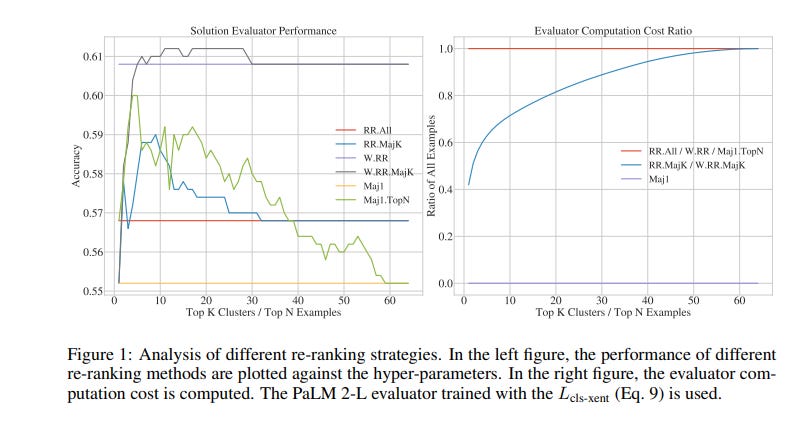
Despite their success in many natural language tasks, solving math problems remains a significant challenge for large language models (LLMs). A large gap exists between LLMs’ pass-at-one and pass-at-N performance in solving math problems, suggesting LLMs might be close to finding correct solutions, motivating our exploration of fine-tuning methods to unlock LLMs’ performance.
Using the challenging MATH dataset, we investigate three fine-tuning strategies:
Solution fine-tuning, where we fine-tune to generate a detailed solution for a given math problem.
Solution-cluster re-ranking, where the LLM is fine-tuned as a solution verifier/evaluator to choose among generated candidate solution clusters.
Multi-task sequential fine-tuning, which integrates both solution generation and evaluation tasks together efficiently to enhance the LLM performance.
With these methods, we present a thorough empirical study on a series of PaLM 2 models and find:
The quality and style of the step-by-step solutions used for fine-tuning can make a significant impact on the model's performance.
While solution re-ranking and majority voting are both effective for improving the model performance when used separately, they can also be used together for an even greater performance boost.
Multi-task fine-tuning that sequentially separates the solution generation and evaluation tasks can offer improved performance compared with the solution fine-tuning baseline.
Guided by these insights, we design a fine-tuning recipe that yields approximately 58.8% accuracy on the MATH dataset with fine-tuned PaLM 2-L models, an 11.2% accuracy improvement over the few-shot performance of pre-trained PaLM 2-L model with majority voting.
3. Text Generation & Summarization
3.1. The Consensus Game: Language Model Generation via Equilibrium Search

When applied to question answering and other text generation tasks, language models (LMs) may be queried generatively (by sampling answers from their output distribution) or discriminatively (by using them to score or rank a set of candidate outputs).
These procedures sometimes yield very different predictions. How do we reconcile mutually incompatible scoring procedures to obtain coherent LM predictions? We introduce a new, training-free, game-theoretic procedure for language model decoding.
This approach casts language model decoding as a regularized imperfect-information sequential signaling game — which we term the CONSENSUS GAME — in which a GENERATOR seeks to communicate an abstract correctness parameter using natural language sentences to a DISCRIMINATOR. The authors develop computational procedures for finding approximate equilibria of this game, resulting in a decoding algorithm we call EQUILIBRIUM-RANKING.
Applied to a large number of tasks (including reading comprehension, commonsense reasoning, mathematical problem-solving, and dialog), EQUILIBRIUM-RANKING consistently, and sometimes substantially, improves performance over existing LM decoding procedures — on multiple benchmarks, they observe that applying EQUILIBRIUM-RANKING to LLaMA-7B outperforms the much larger LLaMA-65B and PaLM-540B models. These results highlight the promise of game-theoretic tools for addressing fundamental challenges of truthfulness and consistency in LMs.
3.2. Toward Joint Language Modeling for Speech Units and Text

Speech and text are two major forms of human language. The research community has been focusing on mapping speech to text or vice versa for many years. However, in the field of language modeling, very little effort has been made to model them jointly. In light of this, the authors explore joint language modeling for speech units and text.
Specifically, they compare different speech tokenizers to transform continuous speech signals into discrete units and use different methods to construct mixed speech-text data. They introduce automatic metrics to evaluate how well the joint LM mixes speech and text.
They also fine-tune the LM on downstream spoken language understanding (SLU) tasks with different modalities (speech or text) and test its performance to assess the model’s learning of shared representations.
The results show that by mixing speech units and text with our proposed mixing techniques, the joint LM improves over a speech-only baseline on SLU tasks and shows zero-shot cross-modal transferability.
4. Reinforcement Learning from Human Feedback (RLHF)
4.1. Safe RLHF: Safe Reinforcement Learning from Human Feedback

With the development of large language models (LLMs), striking a balance between the performance and safety of AI systems has never been more critical. However, the inherent tension between the objectives of helpfulness and harmlessness presents a significant challenge during LLM training.
To address this issue, the authors propose Safe Reinforcement Learning from Human Feedback (Safe RLHF), a novel algorithm for human value alignment. Safe RLHF explicitly decouples human preferences regarding helpfulness and harmlessness, effectively avoiding the crowd workers' confusion about the tension and allowing us to train separate reward and cost models.
We formalize the safety concern of LLMs as an optimization task of maximizing the reward function while satisfying specified cost constraints. Leveraging the Lagrangian method to solve this constrained problem, Safe RLHF dynamically adjusts the balance between the two objectives during fine-tuning.
Through a three-round fine-tuning using Safe RLHF, we demonstrate a superior ability to mitigate harmful responses while enhancing model performance compared to existing value-aligned algorithms.
Experimentally, they fine-tuned the Alpaca-7B using Safe RLHF and aligned it with collected human preferences, significantly improving its helpfulness and harmlessness according to human evaluations.
5. LLM Reasoning
5.1. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection

Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Retrieval-augmented generation (RAG), an ad hoc approach that augments LMs with the retrieval of relevant knowledge, decreases such issues.
However, indiscriminately retrieving and incorporating a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are relevant, diminishes LM versatility or can lead to unhelpful response generation. They introduce a new framework called Self-Reflective Retrieval-Augmented Generation (Self-RAG) that enhances an LM’s quality and factuality through retrieval and self-reflection.
This framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using special tokens, called reflection tokens. Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements.
Experiments show that Self-RAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks. Specifically, Self-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning, and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.
5.2. In-Context Pretraining: Language Modeling Beyond Document Boundaries

Large language models (LMs) are currently trained to predict tokens given document prefixes, enabling them to directly perform long-form generation and prompting-style tasks which can be reduced to document completion. Existing pretraining pipelines train LMs by concatenating random sets of short documents to create input contexts but the prior documents provide no signal for predicting the next document.
They instead present In-Context Pretraining, a new approach where language models are pretrained on a sequence of related documents, thereby explicitly encouraging them to read and reason across document boundaries. We can do In-Context Pretraining by simply changing the document ordering so that each context contains related documents, and directly applying existing pretraining pipelines. However, this document sorting problem is challenging.
There are billions of documents and we would like the sort to maximize contextual similarity for every document without repeating any data. To do this, we introduce approximate algorithms for finding related documents with efficient nearest neighbor search and constructing coherent input contexts with a graph traversal algorithm.
Our experiments show that In-Context Pretraining offers a simple and scalable approach to significantly enhance performance: we see notable improvements in tasks that require more complex contextual reasoning, including in-context learning (+8%), reading comprehension (+15%), faithfulness to previous contexts (+16%), long-context reasoning (+5%), and retrieval augmentation (+9%).
5.3. AgentTuning: Enabling Generalized Agent Abilities for LLMs

Open large language models (LLMs) with great performance in various tasks have significantly advanced the development of LLMs. However, they are far inferior to commercial models such as ChatGPT and GPT-4 when acting as agents to tackle complex tasks in the real world.
These agent tasks employ LLMs as the central controller responsible for planning, memorization, and tool utilization, necessitating both fine-grained prompting methods and robust LLMs to achieve satisfactory performance. Though many prompting methods have been proposed to complete particular agent tasks, there is a lack of research focusing on improving the agent capabilities of LLMs themselves without compromising their general abilities.
In this work, the authors present AgentTuning, a simple and general method to enhance the agent abilities of LLMs while maintaining their general LLM capabilities.
They construct AgentInstruct, a lightweight instruction-tuning dataset containing high-quality interaction trajectories. They employ a hybrid instruction-tuning strategy by combining AgentInstruct with open-source instructions from general domains. AgentTuning is used to instruction-tune the Llama 2 series, resulting in AgentLM. Our evaluations show that AgentTuning enables LLMs’ agent capabilities without compromising general abilities. The AgentLM-70B is comparable to GPT-3.5-turbo on unseen agent tasks, demonstrating generalized agent capabilities.
Looking to start a career in data science and AI do not know how. I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Thanks for sharing