


Top Important LLM Papers for the Week from 27/11 to 03/12
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the first week of December.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Merlin: Empowering Multimodal LLMs with Foresight Minds

Humans possess the remarkable ability to foresee the future to a certain extent based on present observations, a skill we term as foresight minds. However, this capability remains largely under-explored within existing Multimodal Large Language Models (MLLMs), hindering their capacity to learn the fundamental principles of how things operate and the intentions behind the observed subjects. To address this issue, the authors introduce the integration of future modeling into the existing learning frameworks of MLLMs.
Using the subject trajectory, a highly structured representation of a consecutive frame sequence, as a learning objective, they aim to bridge the gap between the past and the future. They propose two innovative methods to empower MLLMs with foresight minds, Foresight Pre-Training (FPT) and Foresight Instruction-Tuning (FIT), which are inspired by the modern learning paradigm of LLMs. Specifically, FPT jointly trains various tasks centered on trajectories, enabling MLLMs to learn how to attend and predict entire trajectories from a given initial observation.
Then, FIT requires MLLMs first to predict trajectories of related objects and then reason about potential future events based on them. Aided by FPT and FIT, they built a novel and unified MLLM named Merlin that supports multi-image input and analysis about the potential actions of multiple objects for future reasoning. Experimental results show Merlin's powerful foresight minds with impressive performance on future reasoning and visual comprehension tasks.
2. SeaLLMs — Large Language Models for Southeast Asia

Despite the remarkable achievements of large language models (LLMs) in various tasks, there remains a linguistic bias that favors high-resource languages, such as English, often at the expense of low-resource and regional languages. To address this imbalance, the authors introduce SeaLLMs, an innovative series of language models that specifically focuses on Southeast Asian (SEA) languages.
SeaLLMs are built upon the Llama-2 model and further advanced through continued pre-training with an extended vocabulary, specialized instruction, and alignment tuning to better capture the intricacies of regional languages. This allows them to respect and reflect local cultural norms, customs, stylistic preferences, and legal considerations. The comprehensive evaluation demonstrates that SeaLLM-13b models exhibit superior performance across a wide spectrum of linguistic tasks and assistant-style instruction-following capabilities relative to comparable open-source models.
Moreover, they outperform ChatGPT-3.5 in non-Latin languages, such as Thai, Khmer, Lao, and Burmese, by large margins while remaining lightweight and cost-effective to operate.
3. Instruction-tuning Aligns LLMs to the Human Brain
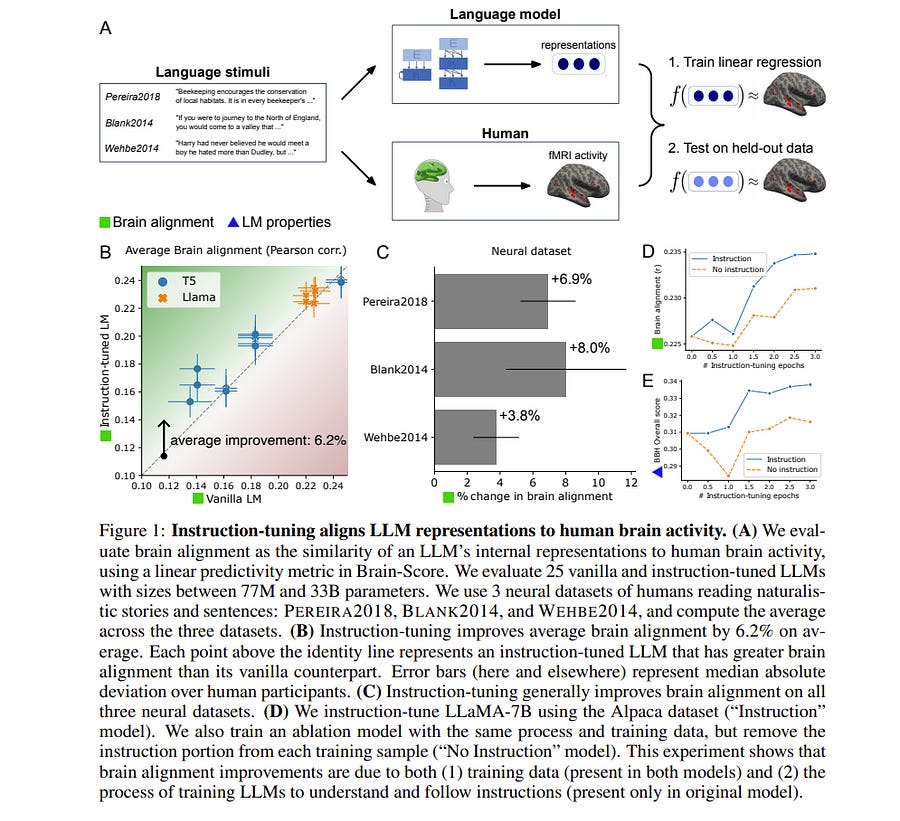
Instruction-tuning is a widely adopted method of finetuning that enables large language models (LLMs) to generate output that more closely resembles human responses to natural language queries, in many cases leading to human-level performance on diverse testbeds. However, it remains unclear whether instruction-tuning truly makes LLMs more similar to how humans process language.
We investigate the effect of instruction-tuning on LLM-human similarity in two ways:
Brain alignment, the similarity of LLM internal representations to neural activity in the human language system
Behavioral alignment, the similarity of LLM and human behavior on a reading task. We assess 25 vanilla and instruction-tuned LLMs across three datasets involving humans reading naturalistic stories and sentences.
We discover that instruction tuning generally enhances brain alignment by an average of 6%, but does not have a similar effect on behavioral alignment. To identify the factors underlying LLM-brain alignment, we compute correlations between the brain alignment of LLMs and various model properties, such as model size, various problem-solving abilities, and performance on tasks requiring world knowledge spanning various domains.
Notably, we find a strong positive correlation between brain alignment and model size (r = 0.95), as well as performance on tasks requiring world knowledge (r = 0.81). Our results demonstrate that instruction-tuning LLMs improves both world knowledge representations and brain alignment, suggesting that mechanisms that encode world knowledge in LLMs also improve representational alignment to the human brain.
4. Mamba: Linear-Time Sequence Modeling with Selective State Spaces

Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module.
Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers’ computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning and make several improvements.
First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode.
We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5 times higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences.
As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
5. Beyond ChatBots: ExploreLLM for Structured Thoughts and Personalized Model Responses

LLM-powered chatbots are primarily text-based today and impose a large interactional cognitive load, especially for exploratory or sensemaking tasks such as planning a trip or learning about a new city. Because the interaction is textual, users have little scaffolding in the way of structure, informational “scent”, or ability to specify high-level preferences or goals.
We introduce ExploreLLM which allows users to structure thoughts, help explore different options, navigate through the choices and recommendations, and more easily steer models to generate more personalized responses.
They conducted a user study and showed that users find it helpful to use ExploreLLM for exploratory or planning tasks, because it provides a useful schema-like structure to the task, and guides users in planning.
The study also suggests that users can more easily personalize responses with high-level preferences with ExploreLLM. Together, ExploreLLM points to a future where users interact with LLMs beyond the form of chatbots, and instead are designed to support complex user tasks with tighter integration between natural language and graphical user interfaces.
6. Towards Accurate Differential Diagnosis with Large Language Models
An accurate differential diagnosis (DDx) is a cornerstone of medical care, often reached through an iterative process of interpretation that combines clinical history, physical examination, investigations, and procedures. Interactive interfaces powered by Large Language Models (LLMs) present new opportunities to both assist and automate aspects of this process. In this study, the authors introduce an LLM optimized for diagnostic reasoning and evaluate its ability to generate a DDx alone or as an aid to clinicians.
20 clinicians evaluated 302 challenging, real-world medical cases sourced from the New England Journal of Medicine (NEJM) case reports. Each case report was read by two clinicians, who were randomized to one of two assistive conditions: either assistance from search engines and standard medical resources, or LLM assistance in addition to these tools. All clinicians provided a baseline, unassisted DDx before using the respective assistive tools.
Our LLM for DDx exhibited standalone performance that exceeded that of unassisted clinicians (top-10 accuracy 59.1% vs 33.6%, [p = 0.04]). Comparing the two assisted study arms, the DDx quality score was higher for clinicians assisted by our LLM (top-10 accuracy 51.7%) compared to clinicians without its assistance (36.1%) (McNemar’s Test: 45.7, p < 0.01) and clinicians with search (44.4%) (4.75, p = 0.03). Further, clinicians assisted by our LLM arrived at more comprehensive differential lists than those without its assistance.
This study suggests that our LLM for DDx has the potential to improve clinicians’ diagnostic reasoning and accuracy in challenging cases, meriting further real-world evaluation for its ability to empower physicians and widen patients’ access to specialist-level expertise.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Thanks for sharing