


Top Important LLM Papers for the Week from 04/03 to 10/03
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Second Week of March 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
LLM Fine-Tuning
LLM Optimization & Quantization
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. Resonance RoPE: Improving Context Length Generalization of Large Language Models

This paper addresses the challenge of train-short-test-long (TSTL) scenarios in Large Language Models (LLMs) equipped with Rotary Position Embedding (RoPE), where models pre-trained on shorter sequences face difficulty with out-of-distribution (OOD) token positions in longer sequences.
We introduce Resonance RoPE, a novel approach designed to narrow the generalization gap in TSTL scenarios by refining the interpolation of RoPE features for OOD positions, significantly improving the model performance without additional online computational costs. Furthermore, we present PosGen, a new synthetic benchmark specifically designed for fine-grained behavior analysis in TSTL scenarios. We aim to isolate the constantly increasing difficulty of token generation in long contexts from the challenges of recognizing new token positions.
Our experiments on synthetic tasks show that after applying Resonance RoPE, Transformers recognize OOD position better and more robustly. Our extensive LLM experiments also show superior performance after applying Resonance RoPE to the current state-of-the-art RoPE scaling method, YaRN, on both upstream language modeling tasks and a variety of downstream long-text applications.
1.2. AtP*: An efficient and scalable method for localizing LLM behavior to components

Activation Patching is a method of directly computing causal attributions of behavior to model components. However, applying it exhaustively requires a sweep with cost scaling linearly in the number of model components, which can be prohibitively expensive for SoTA Large Language Models (LLMs).
We investigate Attribution Patching (AtP), a fast gradient-based approximation to Activation Patching, and find two classes of failure modes of AtP which lead to significant false negatives. We propose a variant of AtP called AtP*, with two changes to address these failure modes while retaining scalability.
We present the first systematic study of AtP and alternative methods for faster activation patching and show that AtP significantly outperforms all other investigated methods, with AtP* providing further significant improvement. Finally, we provide a method to bind the probability of remaining false negatives of AtP* estimates.
1.3. InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding

Multimodal Large Language Models (MLLMs) have experienced significant advancements recently. Nevertheless, challenges persist in the accurate recognition and comprehension of intricate details within high-resolution images.
Despite being indispensable for the development of robust MLLMs, this area remains underinvestigated. To tackle this challenge, our work introduces InfiMM-HD, a novel architecture specifically designed for processing images of different resolutions with low computational overhead. This innovation facilitates the enlargement of MLLMs to higher-resolution capabilities.
InfiMM-HD incorporates a cross-attention module and visual windows to reduce computation costs. By integrating this architectural design with a four-stage training pipeline, our model attains improved visual perception efficiently and cost-effectively. The empirical study underscores the robustness and effectiveness of InfiMM-HD, opening new avenues for exploration in related areas.
1.4. Design2Code: How Far Are We From Automating Front-End Engineering?

Generative AI has made rapid advancements in recent years, achieving unprecedented capabilities in multimodal understanding and code generation. This can enable a new paradigm of front-end development, in which multimodal LLMs might directly convert visual designs into code implementations. In this work, we formalize this as a Design2Code task and conduct comprehensive benchmarking.
Specifically, we manually curate a benchmark of 484 diverse real-world webpages as test cases and develop a set of automatic evaluation metrics to assess how well current multimodal LLMs can generate the code implementations that directly render into the given reference webpages, given the screenshots as input.
We also complement automatic metrics with comprehensive human evaluations. We develop a suite of multimodal prompting methods and show their effectiveness on GPT-4V and Gemini Pro Vision. We further finetune an open-source Design2Code-18B model that successfully matches the performance of Gemini Pro Vision. Both human evaluation and automatic metrics show that GPT-4V performs the best on this task compared to other models.
Moreover, annotators think GPT-4V generated webpages can replace the original reference webpages in 49% of cases in terms of visual appearance and content; and perhaps surprisingly, in 64% of cases, GPT-4V generated webpages are considered better than the original reference webpages.
Our fine-grained break-down metrics indicate that open-source models mostly lag in recalling visual elements from the input web pages and in generating correct layout designs, while aspects like text content and coloring can be drastically improved with proper finetuning.
1.5. LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error

Tools are essential for large language models (LLMs) to acquire up-to-date information and take consequential actions in external environments. Existing work on tool-augmented LLMs primarily focuses on the broad coverage of tools and the flexibility of adding new tools.
However, a critical aspect that has surprisingly been understudied is simply how accurately an LLM uses tools for which it has been trained. We find that existing LLMs, including GPT-4 and open-source LLMs specifically fine-tuned for tool use, only reach a correctness rate in the range of 30% to 60%, far from reliable use in practice.
We propose a biologically inspired method for tool-augmented LLMs, simulated trial and error (STE), that orchestrates three key mechanisms for successful tool use behaviors in the biological system: trial and error, imagination, and memory. Specifically, STE leverages an LLM’s ‘imagination’ to simulate plausible scenarios for using a tool, after which the LLM interacts with the tool to learn from its execution feedback.
Both short-term and long-term memory are employed to improve the depth and breadth of the exploration, respectively. Comprehensive experiments on ToolBench show that STE substantially improves tool learning for LLMs under both in-context learning and fine-tuning settings, bringing a boost of 46.7% to Mistral-Instruct-7B and enabling it to outperform GPT-4. We also show effective continual learning of tools via a simple experience replay strategy.
1.6. Yi: Open Foundation Models by 01.AI

We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models.
Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rates on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts.
We construct 3.1 trillion tokens of English and Chinese corpora for pretraining using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small-scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers.
For vision language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance.
We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
1.7. SaulLM-7B: A Pioneering Large Language Model for Law

In this paper, we introduce SaulLM-7B, a large language model (LLM) tailored for the legal domain. With 7 billion parameters, SaulLM-7B is the first LLM designed explicitly for legal text comprehension and generation. Leveraging the Mistral 7B architecture as its foundation, SaulLM-7B is trained on an English legal corpus of over 30 billion tokens.
SaulLM-7B exhibits state-of-the-art proficiency in understanding and processing legal documents. Additionally, we present a novel instructional fine-tuning method that leverages legal datasets to further enhance SaulLM-7B’s performance in legal tasks. SaulLM-7B is released under the CC-BY-SA-4.0 License.
1.8. ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
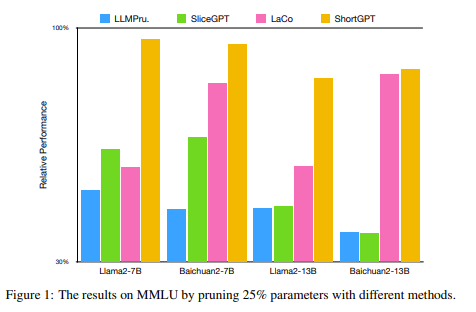
As Large Language Models (LLMs) continue to advance in performance, their size has escalated significantly, with current LLMs containing billions or even trillions of parameters. However, in this study, we discovered that many layers of LLMs exhibit high similarity, and some layers play a negligible role in network functionality.
Based on this observation, we define a metric called Block Influence (BI) to gauge the significance of each layer in LLMs. We then propose a straightforward pruning approach: layer removal, in which we directly delete the redundant layers in LLMs based on their BI scores. Experiments demonstrate that our method, which we call ShortGPT, significantly outperforms previous state-of-the-art (SOTA) methods in model pruning.
Moreover, ShortGPT is orthogonal to quantization-like methods, enabling further reduction in parameters and computation. The ability to achieve better results through simple layer removal, as opposed to more complex pruning techniques, suggests a high degree of redundancy in the model architecture.
1.9. Wukong: Towards a Scaling Law for Large-Scale Recommendation

Scaling laws play an instrumental role in the sustainable improvement of model quality. Unfortunately, recommendation models to date do not exhibit such laws similar to those observed in the domain of large language models, due to the inefficiencies of their upscaling mechanisms.
This limitation poses significant challenges in adapting these models to increasingly more complex real-world datasets. In this paper, we propose an effective network architecture based purely on stacked factorization machines, and a synergistic upscaling strategy, collectively dubbed Wukong, to establish a scaling law in the domain of recommendation. Wukong’s unique design makes it possible to capture diverse, any-order interactions simply through taller and wider layers.
We conducted extensive evaluations on six public datasets, and our results demonstrate that Wukong consistently outperforms state-of-the-art models quality-wise. Further, we assessed Wukong’s scalability on an internal, large-scale dataset.
The results show that Wukong retains its superiority in quality over state-of-the-art models, while holding the scaling law across two orders of magnitude in model complexity, extending beyond 100 Gflop or equivalently up to GPT-3/LLaMa-2 scale of total training compute, where prior arts fall short.
1.10. MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets

The development of multimodal interactive systems is hindered by the lack of rich, multimodal (text, images) conversational data, which is needed in large quantities for LLMs. Previous approaches augment textual dialogues with retrieved images, posing privacy, diversity, and quality constraints.
In this work, we introduce Multimodal Augmented Generative Images Dialogues (MAGID), a framework to augment text-only dialogues with diverse and high-quality images. Subsequently, a diffusion model is applied to craft corresponding images, ensuring alignment with the identified text.
Finally, MAGID incorporates an innovative feedback loop between an image description generation module (textual LLM) and image quality modules (addressing aesthetics, image-text matching, and safety), that work in tandem to generate high-quality and multi-modal dialogues. We compare MAGID to other SOTA baselines on three dialogue datasets, using automated and human evaluation.
Our results show that MAGID is comparable to or better than baselines, with significant improvements in human evaluation, especially against retrieval baselines where the image database is small.
1.11. Learning to Decode Collaboratively with Multiple Language Models

We propose a method to teach multiple large language models (LLM) to collaborate by interleaving their generations at the token level. We model the decision of which LLM generates the next token as a latent variable.
By optimizing the marginal likelihood of a training set under our latent variable model, the base LLM automatically learns when to generate itself and when to call on one of the ``assistant’’ language models to generate, all without direct supervision. Token-level collaboration during decoding allows for a fusion of each model’s expertise in a manner tailored to the specific task at hand.
Our collaborative decoding is especially useful in cross-domain settings where a generalist base LLM learns to invoke domain expert models. On instruction-following, domain-specific QA, and reasoning tasks, we show that the performance of the joint system exceeds that of the individual models.
Through qualitative analysis of the learned latent decisions, we show models trained with our method exhibit several interesting collaboration patterns, e.g., template-filling.
2. LLM Reasoning
2.1. How Far Are We from Intelligent Visual Deductive Reasoning?
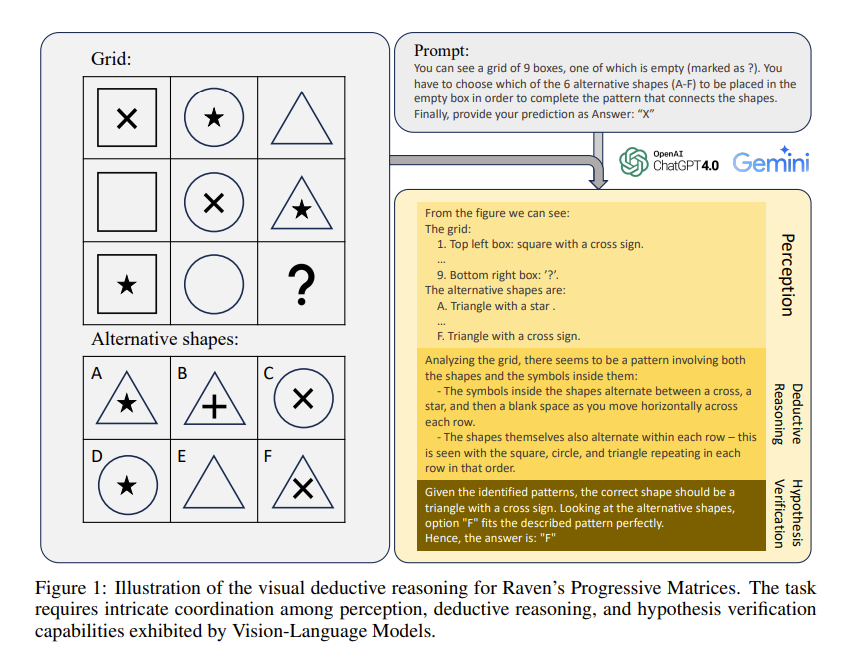
Vision-language models (VLMs) such as GPT-4V have recently demonstrated incredible strides on diverse vision language tasks. We dig into vision-based deductive reasoning, a more sophisticated but less explored realm, and find previously unexposed blindspots in the current SOTA VLMs.
Specifically, we leverage Raven’s Progressive Matrices (RPMs), to assess VLMs’ abilities to perform multi-hop relational and deductive reasoning relying solely on visual clues. We perform comprehensive evaluations of several popular VLMs employing standard strategies such as in-context learning, self-consistency, and Chain-of-thoughts (CoT) on three diverse datasets, including the Mensa IQ test, IntelligenceTest, and RAVEN.
The results reveal that despite the impressive capabilities of LLMs in text-based reasoning, we are still far from achieving comparable proficiency in visual deductive reasoning. We found that certain standard strategies that are effective when applied to LLMs do not seamlessly translate to the challenges presented by visual reasoning tasks.
Moreover, a detailed analysis reveals that VLMs struggle to solve these tasks mainly because they are unable to perceive and comprehend multiple, confounding abstract patterns in RPM examples.
2.2. Common 7B Language Models Already Possess Strong Math Capabilities

Mathematical capabilities were previously believed to emerge in common language models only at a very large scale or require extensive math-related pre-training. This paper shows that the LLaMA-2 7B model with common pre-training already exhibits strong mathematical abilities, as evidenced by its impressive accuracy of 97.7% and 72.0% on the GSM8K and MATH benchmarks, respectively, when selecting the best response from 256 random generations.
The primary issue with the current base model is the difficulty in consistently eliciting its inherent mathematical capabilities. Notably, the accuracy for the first answer drops to 49.5% and 7.9% on the GSM8K and MATH benchmarks, respectively. We find that simply scaling up the SFT data can significantly enhance the reliability of generating correct answers. However, the potential for extensive scaling is constrained by the scarcity of publicly available math questions.
To overcome this limitation, we employ synthetic data, which proves to be nearly as effective as real data and shows no clear saturation when scaled up to approximately one million samples. This straightforward approach achieves an accuracy of 82.6% on GSM8K and 40.6% on MATH using LLaMA-2 7B models, surpassing previous models by 14.2% and 20.8%, respectively. We also provide insights into scaling behaviors across different reasoning complexities and error types.
2.3. Teaching Large Language Models to Reason with Reinforcement Learning

Reinforcement Learning from Human Feedback (RLHF) has emerged as a dominant approach for aligning LLM outputs with human preferences. Inspired by the success of RLHF, we study the performance of multiple algorithms that learn from feedback (Expert Iteration, Proximal Policy Optimization (PPO), and Return-Conditioned RL) on improving LLM reasoning capabilities.
We investigate both sparse and dense rewards provided to the LLM both heuristically and via a learned reward model. We additionally start from multiple model sizes and initializations both with and without supervised fine-tuning (SFT) data. Overall, we find all algorithms perform comparably, with Expert Iteration performing best in most cases.
Surprisingly, we find the sample complexity of Expert Iteration is similar to that of PPO, requiring at most on the order of 10⁶ samples to converge from a pretrained checkpoint. We investigate why this is the case, concluding that during RL training models fail to explore significantly beyond solutions already produced by SFT models. Additionally, we discuss a trade-off between maj@1 and pass@96 metric performance during SFT training and how conversely RL training improves both simultaneously. We then conclude by discussing the implications of our findings for RLHF and the future role of RL in LLM fine-tuning.
2.4. MathScale: Scaling Instruction Tuning for Mathematical Reasoning

Large language models (LLMs) have demonstrated remarkable capabilities in problem-solving. However, their proficiency in solving mathematical problems remains inadequate. We propose MathScale, a simple and scalable method to create high-quality mathematical reasoning data using frontier LLMs (e.g., {\tt GPT-3.5}).
Inspired by the cognitive mechanism in human mathematical learning, it first extracts topics and knowledge points from seed math questions and then builds a concept graph, which is subsequently used to generate new math questions. MathScale exhibits effective scalability along the size axis of the math dataset that we generate. As a result, we create a mathematical reasoning dataset (MathScaleQA) containing two million math question-answer pairs.
To evaluate the mathematical reasoning abilities of LLMs comprehensively, we construct {\sc MwpBench}, a benchmark of Math Word Problems, which is a collection of ten datasets (including GSM8K and MATH) covering K-12, college, and competition-level math problems. We apply MathScaleQA to fine-tune open-source LLMs (e.g., LLaMA-2 and Mistral), resulting in significantly improved capabilities in mathematical reasoning.
Evaluated on {\sc MwpBench}, MathScale-7B achieves state-of-the-art performance across all datasets, surpassing its best peers of equivalent size by 42.9\% in micro average accuracy and 43.7\% in macro average accuracy, respectively.
3. LLM Training, Evaluation & Inference
3.1. Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference

Large Language Models (LLMs) have unlocked new capabilities and applications; however, evaluating the alignment with human preferences still poses significant challenges. To address this issue, we introduce Chatbot Arena, an open platform for evaluating LLMs based on human preferences.
Our methodology employs a pairwise comparison approach and leverages input from a diverse user base through crowdsourcing. The platform has been operational for several months, amassing over 240K votes. This paper describes the platform, analyzes the data we have collected so far, and explains the tried-and-true statistical methods we are using for efficient and accurate evaluation and ranking of models.
We confirm that the crowdsourced questions are sufficiently diverse and discriminating and that the crowdsourced human votes are in good agreement with those of expert raters. These analyses collectively establish a robust foundation for the credibility of Chatbot Arena. Because of its unique value and openness, Chatbot Arena has emerged as one of the most referenced LLM leaderboards, widely cited by leading LLM developers and companies.
4. LLM Fine-Tuning
4.1. Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters

We propose a novel framework for filtering image-text data by leveraging fine-tuned Multimodal Language Models (MLMs). Our approach outperforms predominant filtering methods (e.g., CLIPScore) by integrating the recent advances in MLMs. We design four distinct yet complementary metrics to holistically measure the quality of image-text data.
A new pipeline is established to construct high-quality instruction data for fine-tuning MLMs as data filters. Compared with CLIPScore, our MLM filters produce more precise and comprehensive scores that directly improve the quality of filtered data and boost the performance of pre-trained models. We achieve significant improvements over CLIPScore on popular foundation models (i.e., CLIP and BLIP2) and various downstream tasks.
Our MLM filter can generalize to different models and tasks, and be used as a drop-in replacement for CLIPScore. An additional ablation study is provided to verify our design choices for the MLM filter.
5. LLM Optimization & Quantization
5.1. GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection

Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states.
However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start.
In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks.
Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
5.2. DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models

Large language models (LLMs) face a daunting challenge due to the excessive computational and memory requirements of the commonly used Transformer architecture.
While the state space model (SSM) is a new type of foundational network architecture offering lower computational complexity, their performance has yet to fully rival that of Transformers. This paper introduces DenseSSM, a novel approach to enhance the flow of hidden information between layers in SSMs. By selectively integrating shallow-layer hidden states into deeper layers, DenseSSM retains fine-grained information crucial for the final output. Dense connections enhanced DenseSSM still maintains the training parallelizability and inference efficiency. The proposed method can be widely applicable to various SSM types like RetNet and Mamba.
With a similar model size, DenseSSM achieves significant improvements, exemplified by DenseRetNet outperforming the original RetNet with up to 5% accuracy improvement on public benchmarks.
5.3. EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs

Large language models (LLMs) have proven to be very superior to conventional methods in various tasks. However, their expensive computations and high memory requirements are prohibitive for deployment. Model quantization is an effective method for reducing this overhead.
The problem is that in most previous works, the quantized model was calibrated using a few samples from the training data, which might affect the generalization of the quantized LLMs to unknown cases and tasks. Hence in this work, we explore an important question: Can we design a data-independent quantization method for LLMs to guarantee its generalization performance?
In this work, we propose EasyQuant, a training-free and data-independent weight-only quantization algorithm for LLMs. Our observation indicates that two factors: outliers in the weight and quantization ranges, are essential for reducing the quantization error.
Therefore, in EasyQuant, we leave the outliers (less than 1%) unchanged and optimize the quantization range to reduce the reconstruction error. With these methods, we surprisingly find that EasyQuant achieves comparable performance to the original model.
Since EasyQuant does not depend on any training data, the generalization performance of quantized LLMs is safely guaranteed. Moreover, EasyQuant can be implemented in parallel so that the quantized model can be attained in a few minutes even for LLMs over 100B.
To our knowledge, we are the first work that achieves almost lossless quantization performance for LLMs under a data-independent setting and our algorithm runs over 10 times faster than the data-dependent methods.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
