


Top Important LLM Papers for the Week from 11/03 to 17/03
Stay Updated with Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, researchers and engineers need to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the Third Week of March 2024.
The papers cover various topics shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Progress & Benchmarking
LLM Reasoning
LLM Training, Evaluation & Inference
LLM Fine-Tuning
LLM Optimization & Quantization
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. LLM Progress & Benchmarking
1.1. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context

In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio.
Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA, and long-context ASR, and matches or surpasses Gemini 1.0 Ultra’s state-of-the-art performance across a broad set of benchmarks.
Studying the limits of Gemini 1.5 Pro’s long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k).
Finally, we highlight the surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
1.2. ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment

Diffusion models have demonstrated remarkable performance in the domain of text-to-image generation. However, most widely used models still employ CLIP as their text encoder, which constrains their ability to comprehend dense prompts, encompassing multiple objects, detailed attributes, complex relationships, long-text alignment, etc.
In this paper, we introduce an Efficient Large Language Model Adapter, termed ELLA, which equips text-to-image diffusion models with powerful Large Language Models (LLM) to enhance text alignment without training of either U-Net or LLM. To seamlessly bridge two pre-trained models, we investigate a range of semantic alignment connector designs and propose a novel module, the Timestep-Aware Semantic Connector (TSC), which dynamically extracts timestep-dependent conditions from LLM.
Our approach adapts semantic features at different stages of the denoising process, assisting diffusion models in interpreting lengthy and intricate prompts over sampling timesteps. Additionally, ELLA can be readily incorporated with community models and tools to improve their prompt-following capabilities.
To assess text-to-image models in dense prompt following, we introduce the Dense Prompt Graph Benchmark (DPG-Bench), a challenging benchmark consisting of 1K dense prompts. Extensive experiments demonstrate the superiority of ELLA in dense prompt following compared to state-of-the-art methods, particularly in multiple object compositions involving diverse attributes and relationships.
1.3. Stealing Part of a Production Language Model
We introduce the first model-stealing attack that extracts precise, nontrivial information from black-box production language models like OpenAI’s ChatGPT or Google’s PaLM-2.
Specifically, our attack recovers the embedding projection layer (up to symmetries) of a transformer model, given typical API access. For under \20 USD, our attack extracts the entire projection matrix of OpenAI’s Ada and Babbage language models.
We thereby confirm, for the first time, that these black-box models have a hidden dimension of 1024 and 2048, respectively. We also recover the exact hidden dimension size of the gpt-3.5-turbo model, and estimate it would cost under 2,000 in queries to recover the entire projection matrix.
We conclude with potential defenses and mitigations and discuss the implications of possible future work that could extend our attack.
1.4. Veagle: Advancements in Multimodal Representation Learning

Lately, researchers in artificial intelligence have been interested in how language and vision come together, giving rise to the development of multimodal models that aim to seamlessly integrate textual and visual information.
Multimodal models, an extension of Large Language Models (LLMs), have exhibited remarkable capabilities in addressing a diverse array of tasks, ranging from image captioning and visual question answering (VQA) to visual grounding.
While these models have showcased significant advancements, challenges persist in accurately interpreting images and answering the question, a common occurrence in real-world scenarios. This paper introduces a novel approach to enhance the multimodal capabilities of existing models.
In response to the limitations observed in current Vision Language Models (VLMs) and Multimodal Large Language Models (MLLMs), our proposed model Veagle, incorporates a unique mechanism inspired by the successes and insights of previous works.
Veagle leverages a dynamic mechanism to project encoded visual information directly into the language model. This dynamic approach allows for a more nuanced understanding of intricate details present in visual contexts.
To validate the effectiveness of Veagle, we conduct comprehensive experiments on benchmark datasets, emphasizing tasks such as visual question answering and image understanding. Our results indicate an improvement of 5–6 \% in performance, with Veagle outperforming existing models by a notable margin. The outcomes underscore the model’s versatility and applicability beyond traditional benchmarks.
1.5. Algorithmic progress in language models
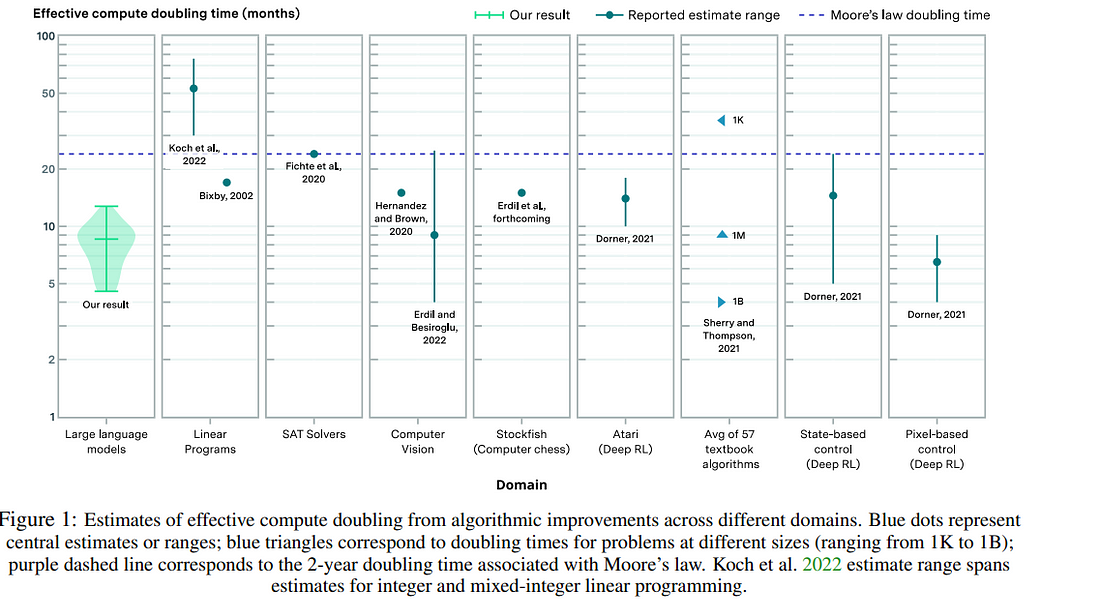
We investigate the rate at which algorithms for pre-training language models have improved since the advent of deep learning. Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012–2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore’s Law.
We estimate augmented scaling laws, which enable us to quantify algorithmic progress and determine the relative contributions of scaling models versus innovations in training algorithms. Despite the rapid pace of algorithmic progress and the development of new architectures such as the transformer, our analysis reveals that the increase in computing made an even larger contribution to overall performance improvements over this period.
Though limited by noisy benchmark data, our analysis quantifies the rapid progress in language modeling, shedding light on the relative contributions from computing and algorithms.
1.6. MoAI: Mixture of All Intelligence for Large Language and Vision Models
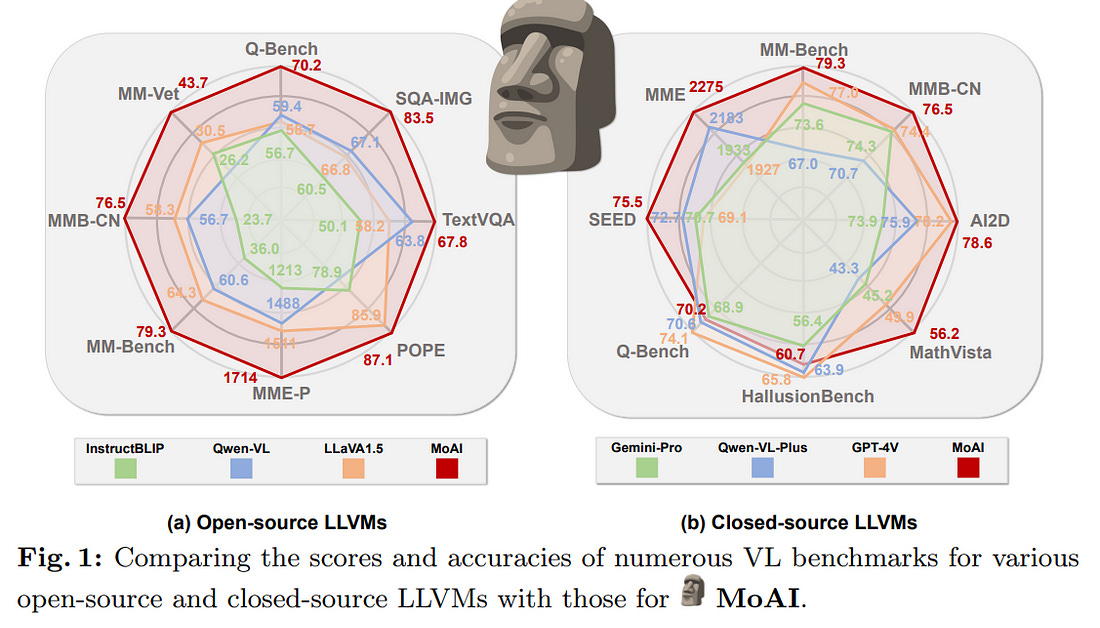
The rise of large language models (LLMs) and instruction tuning has led to the current trend of instruction-tuned large language and vision models (LLVMs). This trend involves either meticulously curating numerous instruction-tuning datasets tailored to specific objectives or enlarging LLVMs to manage vast amounts of vision language (VL) data.
However, current LLVMs have disregarded the detailed and comprehensive real-world scene understanding available from specialized computer vision (CV) models in visual perception tasks such as segmentation, detection, scene graph generation (SGG), and optical character recognition (OCR).
Instead, the existing LLVMs rely mainly on the large capacity and emergent capabilities of their LLM backbones. Therefore, we present a new LLVM, Mixture of All Intelligence (MoAI), which leverages auxiliary visual information obtained from the outputs of external segmentation, detection, SGG, and OCR models. MoAI operates through two newly introduced modules: MoAI-Compressor and MoAI-Mixer.
After verbalizing the outputs of the external CV models, the MoAI-Compressor aligns and condenses them to efficiently use relevant auxiliary visual information for VL tasks. MoAI-Mixer then blends three types of intelligence (1) visual features, (2) auxiliary features from the external CV models, and (3) language features by utilizing the concept of Mixture of Experts.
Through this integration, MoAI significantly outperforms both open-source and closed-source LLVMs in numerous zero-shot VL tasks, particularly those related to real-world scene understanding such as object existence, positions, relations, and OCR without enlarging the model size or curating extra visual instruction tuning datasets.
1.7. Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM

We investigate efficient methods for training Large Language Models (LLMs) to possess capabilities in multiple specialized domains, such as coding, math reasoning, and world knowledge. Our method, named Branch-Train-MiX (BTX), starts from a seed model, which is branched to train experts in an embarrassingly parallel fashion with high throughput and reduced communication cost.
After individual experts are asynchronously trained, BTX brings together their feedforward parameters as experts in Mixture-of-Expert (MoE) layers and averages the remaining parameters, followed by a MoE-finetuning stage to learn token-level routing.
BTX generalizes two special cases, the Branch-Train-Merge method, which does not have the MoE finetuning stage to learn routing, and sparse upcycling, which omits the stage of training experts asynchronously. Compared to alternative approaches, BTX achieves the best accuracy-efficiency tradeoff.
1.8. Gemma: Open Models Based on Gemini Research and Technology
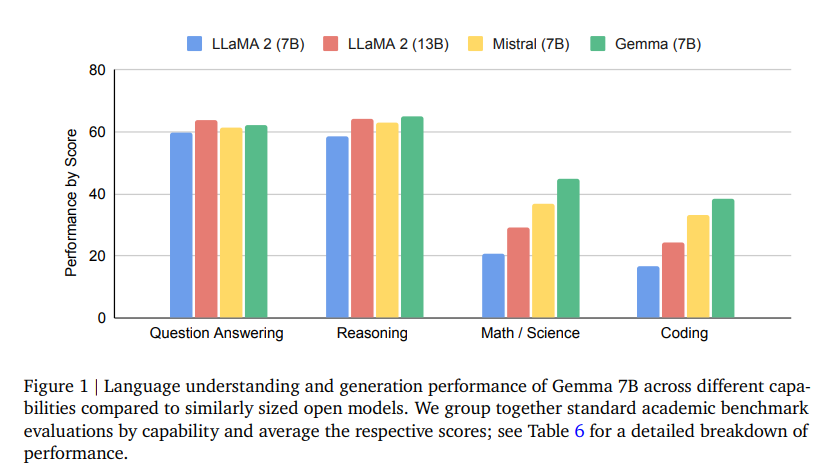
This work introduces Gemma, a family of lightweight, state-of-the-art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety.
We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of the safety and responsibility aspects of the models, alongside a detailed description of model development.
We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
1.9. SOTOPIA-$π$: Interactive Learning of Socially Intelligent Language Agents

Humans learn social skills through both imitation and social interaction. This social learning process is largely understudied by existing research on building language agents. Motivated by this gap, we propose an interactive learning method, SOTOPIA-pi, to improve the social intelligence of language agents.
This method leverages behavior cloning and self-reinforcement training on filtered social interaction data according to large language model (LLM) ratings. We show that our training method allows a 7B LLM to reach the social goal completion ability of an expert model (GPT-4-based agent) while improving the safety of language agents and maintaining general QA ability on the MMLU benchmark.
We also find that this training paradigm uncovers some difficulties in the LLM-based evaluation of social intelligence: LLM-based evaluators overestimate the abilities of the language agents trained specifically for social interaction.
1.10. Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset

Using vision-language models (VLMs) in web development presents a promising strategy to increase efficiency and unblock no-code solutions: by providing a screenshot or a sketch of a UI, a VLM could generate the code to reproduce it, for instance in a language like HTML.
Despite the advancements in VLMs for various tasks, the specific challenge of converting a screenshot into a corresponding HTML has been minimally explored. We posit that this is mainly due to the absence of a suitable, high-quality dataset. This work introduces WebSight, a synthetic dataset consisting of 2 million pairs of HTML codes and their corresponding screenshots.
We fine-tune a foundational VLM on our dataset and show proficiency in converting webpage screenshots to functional HTML code. To accelerate the research in this area, we open-source WebSight.
1.11. MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training

In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architectural components and data choices.
Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results.
Further, we show that the image encoder together with image resolution and the image token count has a substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, consisting of both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks.
Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
2. LLM Reasoning
2.1. Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking

When writing and talking, people sometimes pause to think. Although reasoning-focused works have often framed reasoning as a method of answering questions or completing agentic tasks, reasoning is implicit in almost all written text.
For example, this applies to the steps not stated between the lines of proof or to the theory of mind underlying a conversation. In the Self-Taught Reasoner (STaR, Zelikman, et al. 2022), useful thinking is learned by inferring rationales from few-shot examples in question-answering and learning from those that lead to a correct answer.
This is a highly constrained setting — ideally, a language model could instead learn to infer unstated rationales in arbitrary text. We present Quiet-STaR, a generalization of STaR in which LMs learn to generate rationales at each token to explain the future text, improving their predictions.
We address key challenges, including 1) the computational cost of generating continuations, 2) the fact that the LM does not initially know how to generate or use internal thoughts, and 3) the need to predict beyond individual next tokens.
To resolve these, we propose a tokenwise parallel sampling algorithm, using learnable tokens indicating a thought’s start and end, and an extended teacher-forcing technique. Encouragingly, generated rationales disproportionately help model difficult-to-predict tokens and improve the LM’s ability to directly answer difficult questions.
In particular, after continued pretraining of an LM on a corpus of internet text with Quiet-STaR, we find zero-shot improvements on GSM8K (5.9%rightarrow10.9%) and CommonsenseQA (36.3%rightarrow47.2%) and observe a perplexity improvement of difficult tokens in natural text. Crucially, these improvements require no fine-tuning on these tasks. Quiet-STaR marks a step towards LMs that can learn to reason in a more general and scalable way.
3. LLM Fine-Tuning
3.1. Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
Recent advances in large language models have brought immense value to the world, with their superior capabilities stemming from the massive number of parameters they utilize. However, even the GPUs with the highest memory capacities, currently peaking at 80GB, are far from sufficient to accommodate these vast parameters and their associated optimizer states when conducting stochastic gradient descent-based optimization.
One approach to hosting such huge models is to aggregate device memory from many GPUs. However, this approach introduces prohibitive costs for most academic researchers, who always have a limited budget for many high-end GPU servers. In this paper, we focus on huge model fine-tuning on a single, even low-end, GPU in a commodity server, which is accessible to most AI researchers.
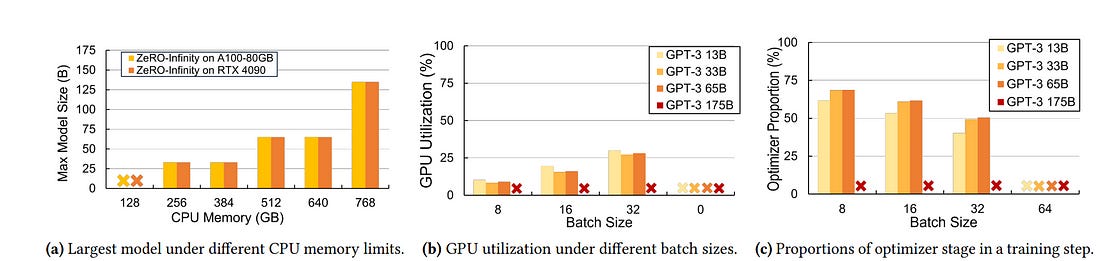
In such a scenario, the state-of-the-art work ZeRO-Infinity suffers from two severe issues when running in a commodity server: 1) low GPU utilization due to inefficient swapping, and 2) limited trainable model size due to CPU memory capacity. The underlying reason is that ZeRO-Infinity is optimized for running on high-end GPU servers.
To this end, we present Fuyou, a low-cost training framework that enables efficient 100B huge model fine-tuning on a low-end server with a low-end GPU and limited CPU memory capacity. The key idea is to add the SSD-CPU communication as an optimization dimension and thus carefully co-optimize computation and data swapping from a systematic approach to maximize GPU utilization.
The experimental results show that 1) Fuyou can fine-tune 175B GPT-3 on a consumer GPU RTX 4090 with high GPU utilization, while ZeRO-Infinity fails to fine-tune; and 2) when training a small GPT-3 13B model, Fuyou achieves 156 TFLOPS on an RTX 4090 GPU while ZeRO-Infinity only achieves 45 TFLOPS.
4. LLM Optimization & Quantization
4.1. Simple and Scalable Strategies to Continually Pre-train Large Language Models
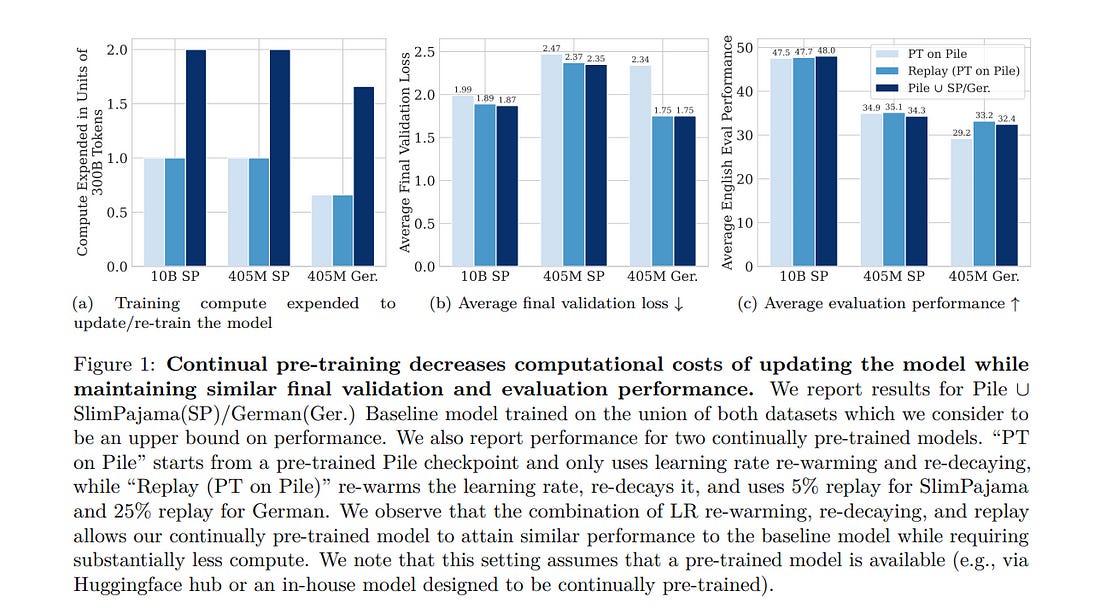
Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models, saving significant computing compared to re-training.
However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by final loss and language model (LM) evaluation benchmarks.
Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (EnglishrightarrowEnglish) and a stronger distribution shift (EnglishrightarrowGerman) at the 405M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM.
Our results demonstrate that LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.
4.2. Language models scale reliably with over-training and on downstream tasks

Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., “Chinchilla optimal” regime); however, in practice, models are often over-trained to reduce inference costs.
Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters.
This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32 times over-trained), and a 6.9B parameter, 138B token runx2014each from experiments that take 300 times less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20 times less compute.
4.3. BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences

Effective attention modules have played a crucial role in the success of Transformer-based large language models (LLMs), but the quadratic time and memory complexities of these attention modules also pose a challenge when processing long sequences.
One potential solution for the long sequence problem is to utilize distributed clusters to parallelize the computation of attention modules across multiple devices (e.g., GPUs). However, adopting a distributed approach inevitably introduces extra memory overheads to store local attention results and incurs additional communication costs to aggregate local results into global ones.
In this paper, we propose a distributed attention framework named ``BurstAttention’’ to optimize memory access and communication operations at both the global cluster and local device levels. In our experiments, we compare BurstAttention with other competitive distributed attention solutions for long sequence processing.
The experimental results under different length settings demonstrate that BurstAttention offers significant advantages for processing long sequences compared with these competitive baselines, reducing 40% communication overheads and achieving 2 X speedup during training 32K sequence length on 8 X A100.
5. Responsible AI & LLM Ethics
5.1. On the Societal Impact of Open Foundation Models
Foundation models are powerful technologies: how they are released publicly directly shapes their societal impact. In this position paper, we focus on open foundation models, defined here as those with broadly available model weights (e.g. Llama 2, Stable Diffusion XL). We identify five distinctive properties (e.g. greater customizability, poor monitoring) of open foundation models that lead to both their benefits and risks.
Open foundation models present significant benefits, with some caveats, that span innovation, competition, the distribution of decision-making power, and transparency. To understand their risks of misuse, we design a risk assessment framework for analyzing their marginal risk. Across several misuse vectors (e.g. cyberattacks, bioweapons), we find that current research is insufficient to effectively characterize the marginal risk of open foundation models relative to pre-existing technologies.
The framework helps explain why the marginal risk is low in some cases, clarifies disagreements about misuse risks by revealing that past work has focused on different subsets of the framework with different assumptions, and articulates a way forward for more constructive debate. Overall, our work helps support a more grounded assessment of the societal impact of open foundation models by outlining what research is needed to empirically validate their theoretical benefits and risks.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
