


Top Important LLM Papers for the Week from 2/10 to 8/10
Stay Relevant to Recent Large Language Models Research

Large language models (LLMs) have advanced rapidly in recent years. As new generations of models are developed, it’s important for researchers and engineers to stay informed on the latest progress. This article summarizes some of the most important LLM papers published during the first week of October.
The papers cover a range of topics that are shaping the next generation of language models, from model optimization and scaling to reasoning, benchmarking, and enhancing performance. The final sections discuss papers related to training LLMs safely and ensuring their behavior remains beneficial.
Keeping up with novel LLM research across these domains will help guide continued progress toward models that are more capable, robust, and aligned with human values.

Table of Contents:
LLM Optimization & Scaling
LLM Reasoning
LLM Progress & Benchmarking
Enhancing LLM Performance
Reinforcement Learning from Human Feedback (RLHF)
LLM Regulations & Ethics
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. LLM Optimization & Scaling
1.1. Large Language Model Cascades with Mixture of Thoughts Representations for Cost-efficient Reasoning

Large language models (LLMs) such as GPT-4 have exhibited remarkable performance in a variety of tasks, but this strong performance often comes with the high expense of using paid API services.
In this paper, the authors study building an LLM cascade to save the cost of using LLMs, particularly for performing reasoning (e.g., mathematical, causal) tasks.
The cascade pipeline follows the intuition that simpler questions can be addressed by a weaker but more affordable LLM, whereas only the challenging questions necessitate the stronger and more expensive LLM.
To realize this decision-making, they consider the “answer consistency” of the weaker LLM as a signal of the question difficulty and propose several methods for the answer sampling and consistency checking, including one leveraging a mixture of two thought representations (i.e., Chain-of-Thought and Program-of-Thought).
Through experiments on six reasoning benchmark datasets, with GPT-3.5-turbo and GPT-4 being the weaker and stronger LLMs, respectively, we demonstrate that our proposed LLM cascades can achieve performance comparable to using solely the stronger LLM but require only 40% of its cost.
1.2. EcoAssistant: Using LLM Assistant More Affordably and Accurately

Today, users ask Large language models (LLMs) as assistants to answer queries that require external knowledge; they ask about the weather in a specific city, about stock prices, and even about where specific locations are within their neighborhood.
These queries require the LLM to produce code that invokes external APIs to answer the user’s question, yet LLMs rarely produce correct code on the first try, requiring iterative code refinement upon execution results. In addition, using LLM assistants to support high query volumes can be expensive.
In this work, the authors contribute a framework, EcoAssistant, that enables LLMs to answer code-driven queries more affordably and accurately. EcoAssistant contains three components:
First, it allows the LLM assistants to converse with an automatic code executor to iteratively refine code or to produce answers based on the execution results.
Second, we use a hierarchy of LLM assistants, which attempts to answer the query with weaker, cheaper LLMs before backing off to stronger, expensive ones.
Third, we retrieve solutions from past successful queries as in-context demonstrations to help subsequent queries.
Empirically, we show that EcoAssistant offers distinct advantages for affordability and accuracy, surpassing GPT-4 by 10 points of success rate with less than 50% of GPT-4’s cost.
1.3. AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model

The authors present Any-Modality Augmented Language Model (AnyMAL), a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses.
AnyMAL inherits the powerful text-based reasoning abilities of the state-of-the-art LLMs including LLaMA-2 (70B), and converts modality-specific signals to the joint textual space through a pre-trained aligner module.
To further strengthen the multimodal LLM’s capabilities, they fine-tuned the model with a multimodal instruction set manually collected to cover diverse topics and tasks beyond simple QAs. They conducted comprehensive empirical analysis comprising both human and automatic evaluations and demonstrated state-of-the-art performance on various multimodal tasks.
2. Reinforcement Learning from Human Feedback (RLHF)
2.1. A Long Way to Go: Investigating Length Correlations in RLHF

Great successes have been reported using Reinforcement Learning from Human Feedback (RLHF) to align large language models. Open-source preference datasets and reward models have enabled wider experimentation beyond generic chat settings, particularly to make systems more “helpful” for tasks like web question answering, summarization, and multi-turn dialogue. When optimizing for helpfulness, RLHF has been consistently observed to drive models to produce longer outputs.
This paper demonstrates that optimizing for response length is a significant factor behind RLHF’s reported improvements in these settings. First, they study the relationship between reward and length for reward models trained on three open-source preference datasets for helpfulness. Here, length correlates strongly with reward, and reward score improvements are largely driven by shifting the distribution over output lengths.
Then they explore interventions during both RL and reward model learning to see if we can achieve the same downstream improvements as RLHF without increasing length. While our interventions mitigate length increases, they aren’t uniformly effective across settings.
Furthermore, we find that even running RLHF with a reward based solely on length can reproduce most of the downstream improvements over the initial policy model, showing that reward models in these settings have a long way to go.
3. Reasoning
3.1. MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning

The recently released GPT-4 Code Interpreter has demonstrated remarkable proficiency in solving challenging math problems, primarily attributed to its ability to seamlessly reason with natural language, generate code, execute code, and continue reasoning based on the execution output.
In this paper, we present a method to fine-tune open-source language models, enabling them to use code for modeling and deriving math equations and, consequently, enhancing their mathematical reasoning abilities.
We propose a method of generating novel and high-quality datasets with math problems and their code-based solutions, called MathCodeInstruct. Each solution interleaves natural language, code, and execution results. We also introduce a customized supervised fine-tuning and inference approach.
This approach yields the MathCoder models, a family of models capable of generating code-based solutions for solving challenging math problems. Impressively, the MathCoder models achieve state-of-the-art scores among open-source LLMs on the MATH (45.2%) and GSM8K (83.9%) datasets, substantially outperforming other open-source alternatives. Notably, the MathCoder model not only surpasses ChatGPT-3.5 and PaLM-2 on GSM8K and MATH but also outperforms GPT-4 on the competition-level MATH dataset.
3.2. Large Language Models Cannot Self-Correct Reasoning Yet
Large Language Models (LLMs) have emerged as a groundbreaking technology with unparalleled text-generation capabilities across various applications. Nevertheless, concerns persist regarding the accuracy and appropriateness of their generated content.
A contemporary methodology, self-correction, has been proposed as a remedy to these issues. Building upon this premise, this paper critically examines the role and efficacy of self-correction within LLMs, shedding light on its true potential and limitations.
Central to our investigation is the notion of intrinsic self-correction, whereby an LLM attempts to correct its initial responses based solely on its inherent capabilities, without the crutch of external feedback.
In the context of reasoning, our research indicates that LLMs struggle to self-correct their responses without external feedback, and at times, their performance might even degrade post-self-correction. Drawing from these insights, we offer suggestions for future research and practical applications in this field.
3.3. Large Language Models as Analogical Reasoners
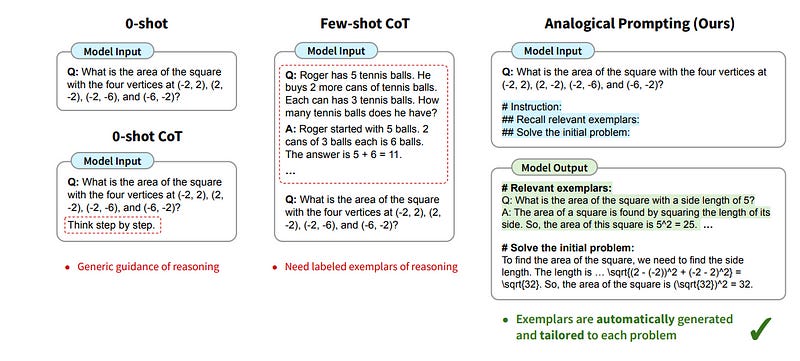
Chain-of-thought (CoT) prompting for language models demonstrates impressive performance across reasoning tasks but typically needs to be labeled exemplars of the reasoning process.
In this work, we introduce a new prompting approach, Analogical Prompting, designed to automatically guide the reasoning process of large language models. Inspired by analogical reasoning, a cognitive process in which humans draw from relevant past experiences to tackle new problems, our approach prompts language models to self-generate relevant exemplars or knowledge in the context, before proceeding to solve the given problem.
This method presents several advantages: it obviates the need for labeling or retrieving exemplars, offering generality and convenience; it can also tailor the generated exemplars and knowledge to each problem, offering adaptability. Experimental results show that our approach outperforms 0-shot CoT and manual few-shot CoT in a variety of reasoning tasks, including math problem-solving in GSM8K and MATH, code generation in Codeforces, and other reasoning tasks in BIG-Bench.
4. LLM Progress & Benchmarking
4.1. How FaR Are Large Language Models From Agents with Theory-of-Mind?

“Thinking is for Doing.” Humans can infer other people’s mental states from observations — an ability called Theory-of-Mind (ToM) — and subsequently act pragmatically on those inferences. Existing question-answering benchmarks such as ToMi ask model questions to make inferences about the beliefs of characters in a story but do not test whether models can then use these inferences to guide their actions.
We propose a new evaluation paradigm for large language models (LLMs): Thinking for Doing (T4D), which requires models to connect inferences about others’ mental states to actions in social scenarios. Experiments on T4D demonstrate that LLMs such as GPT-4 and PaLM 2 seemingly excel at tracking characters’ beliefs in stories, but they struggle to translate this capability into strategic action.
Our analysis reveals the core challenge for LLMs lies in identifying the implicit inferences about mental states without being explicitly asked about as in ToMi, that leads to choosing the correct action in T4D. To bridge this gap, we introduce a zero-shot prompting framework, Foresee and Reflect (FaR), which provides a reasoning structure that encourages LLMs to anticipate future challenges and reason about potential actions.
FaR boosts GPT-4’s performance from 50% to 71% on T4D, outperforming other prompting methods such as Chain-of-Thought and Self-Ask. Moreover, FaR generalizes to diverse out-of-distribution story structures and scenarios that also require ToM inferences to choose an action, consistently outperforming other methods including few-shot in-context learning.
4.2. SmartPlay: A Benchmark for LLMs as Intelligent Agents

Recent large language models (LLMs) have demonstrated great potential for intelligent agents and next-gen automation, but there currently is a systematic benchmark for evaluating LLMs’ abilities as agents.
We introduce SmartPlay: both a challenging benchmark and a methodology for evaluating LLMs as agents. SmartPlay consists of 6 different games, including Rock-Paper-Scissors, Tower of Hanoi, and Minecraft.
Each game features a unique setting, providing up to 20 evaluation settings and infinite environment variations. Each game in SmartPlay uniquely challenges a subset of 9 important capabilities of an intelligent LLM agent, including reasoning with object dependencies, planning ahead, spatial reasoning, learning from history, and understanding randomness. The distinction between the set of capabilities for each game test allows us to analyze each capability separately.
SmartPlay serves not only as a rigorous testing ground for evaluating the overall performance of LLM agents but also as a road map for identifying gaps in current methodologies. We release our benchmark at github.com/LLMsmartplay/SmartPlay
5. Enhancing LLM Performance
5.1. FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation

Most large language models (LLMs) are trained once and never updated; thus, they lack the ability to dynamically adapt to our ever-changing world. In this work, we perform a detailed study of the factuality of LLM-generated text in the context of answering questions that test current world knowledge.
Specifically, we introduce FreshQA, a novel dynamic QA benchmark encompassing a diverse range of question-and-answer types, including questions that require fast-changing world knowledge as well as questions with false premises that need to be debunked.
We benchmark a diverse array of both closed and open-source LLMs under a two-mode evaluation procedure that allows us to measure both correctness and hallucination. Through human evaluations involving more than 50K judgments, we shed light on the limitations of these models and demonstrate significant room for improvement: for instance, all models (regardless of model size) struggle with questions that involve fast-changing knowledge and false premises.
Motivated by these results, we present FreshPrompt, a simple few-shot prompting method that substantially boosts the performance of an LLM on FreshQA by incorporating relevant and up-to-date information retrieved from a search engine into the prompt.
Our experiments show that FreshPrompt outperforms competing search engine-augmented prompting methods such as Self-Ask (Press et al., 2022) as well as commercial systems such as Perplexity AI. Further analysis of FreshPrompt reveals that both the number of retrieved evidence and their order play a key role in influencing the correctness of LLM-generated answers.
Additionally, instructing the LLM to generate concise and direct answers helps reduce hallucination compared to encouraging more verbose answers. To facilitate future work, we release FreshQA at github.com/freshllms/freshqa and commit to updating it at regular intervals.
5.2. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately, existing LM pipelines are typically implemented using hard-coded “prompt templates”, i.e. lengthy strings discovered via trial and error.
Toward a more systematic approach for developing and optimizing LM pipelines, we introduce DSPy, a programming model that abstracts LM pipelines as text transformation graphs, i.e. imperative computational graphs where LMs are invoked through declarative modules. DSPy modules are parameterized, meaning they can learn (by creating and collecting demonstrations) how to apply compositions of prompting, finetuning, augmentation, and reasoning techniques.
We design a compiler that will optimize any DSPy pipeline to maximize a given metric. We conduct two case studies, showing that succinct DSPy programs can express and optimize sophisticated LM pipelines that reason about math word problems, tackle multi-hop retrieval, answer complex questions, and control agent loops.
Within minutes of compiling, a few lines of DSPy allow GPT-3.5 and llama2–13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting (generally by over 25% and 65%, respectively) and pipelines with expert-created demonstrations (by up to 5–46% and 16–40%, respectively). On top of that, DSPy programs compiled to open and relatively small LMs like 770M-parameter T5 and llama2–13b-chat are competitive with approaches that rely on expert-written prompt chains for proprietary GPT-3.5.
5.3. Enable Language Models to Implicitly Learn Self-Improvement From Data

Large Language Models (LLMs) have demonstrated remarkable capabilities in open-ended text generation tasks. However, the inherent open-ended nature of these tasks implies that there is always room for improvement in the quality of model responses.
To address this challenge, various approaches have been proposed to enhance the performance of LLMs. There has been a growing focus on enabling LLMs to self-improve their response quality, thereby reducing the reliance on extensive human annotation efforts for collecting diverse and high-quality training data. Recently, prompting-based methods have been widely explored among self-improvement methods owing to their effectiveness, efficiency, and convenience.
However, those methods usually require explicitly and thoroughly written rubrics as inputs to LLMs. It is expensive and challenging to manually derive and provide all necessary rubrics with a real-world complex goal for improvement (e.g., being more helpful and less harmful). To this end, we propose an ImPlicit Self-ImprovemenT (PIT) framework that implicitly learns the improvement goal from human preference data. PIT only requires preference data that are used to train reward models without extra human effort.
Specifically, we reformulate the training objective of reinforcement learning from human feedback (RLHF) — instead of maximizing response quality for a given input, we maximize the quality gap of the response conditioned on a reference response. In this way, PIT is implicitly trained with the improvement goal of better aligning with human preferences. Experiments on two real-world datasets and one synthetic dataset show that our method significantly outperforms prompting-based methods.
6. LLM Regulations & Ethics
6.1. HeaP: Hierarchical Policies for Web Actions using LLMs

Large language models (LLMs) have demonstrated remarkable capabilities in performing a range of instruction-following tasks in few and zero-shot settings.
However, teaching LLMs to perform tasks on the web presents fundamental challenges — combinatorially large open-world tasks and variations across web interfaces. We tackle these challenges by leveraging LLMs to decompose web tasks into a collection of sub-tasks, each of which can be solved by a low-level, closed-loop policy.
These policies constitute a shared grammar across tasks, i.e., new web tasks can be expressed as a composition of these policies. We propose a novel framework, Hierarchical Policies for Web Actions using LLMs (HeaP), that learns a set of hierarchical LLM prompts from demonstrations for planning high-level tasks and executing them via a sequence of low-level policies.
We evaluate HeaP against a range of baselines on a suite of web tasks, including MiniWoB++, WebArena, a mock airline CRM, as well as live website interactions, and show that it is able to outperform prior works using orders of magnitude less data.
Looking to start a career in data science and do not know how. I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Thanks for your effort