


Top Important Computer Vision Papers for the Week from 27/05 to 02/06
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Fifth Week of May 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
Object Detection
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. EM Distillation for One-step Diffusion Models

While diffusion models can learn complex distributions, sampling requires a computationally expensive iterative process. Existing distillation methods enable efficient sampling, but have notable limitations, such as performance degradation with very few sampling steps, reliance on training data access, or mode-seeking optimization that may fail to capture the full distribution.
We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality.
Our approach is derived through the lens of Expectation-Maximization (EM), where the generator parameters are updated using samples from the joint distribution of the diffusion teacher prior and inferred generator latents.
We develop a reparametrized sampling scheme and a noise cancellation technique that together stabilizes the distillation process. We further reveal an interesting connection of our method with existing methods that minimize mode-seeking KL.
EMD outperforms existing one-step generative methods in terms of FID scores on ImageNet-64 and ImageNet-128 and compares favorably with prior work on distilling text-to-image diffusion models.
1.2. Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control
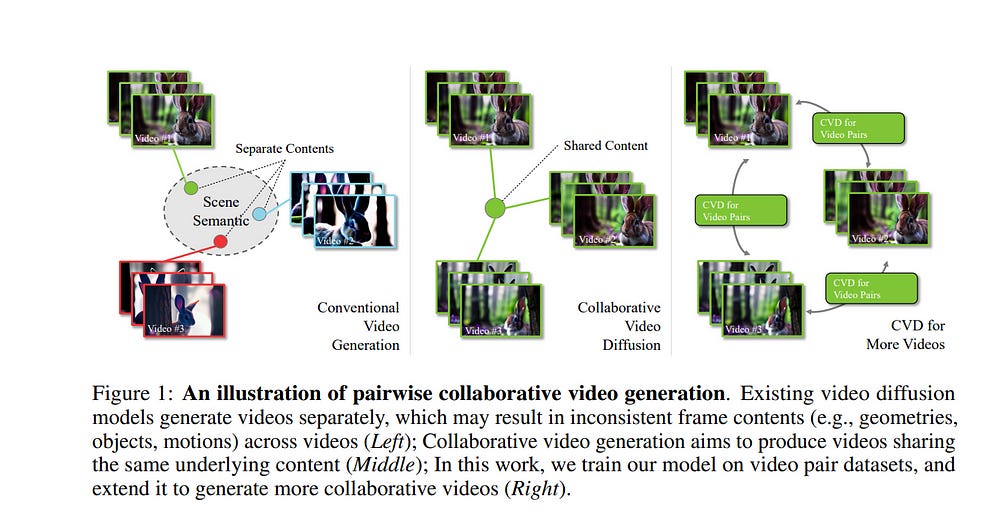
Research on video generation has recently made tremendous progress, enabling high-quality videos to be generated from text prompts or images. Adding control to the video generation process is an important goal moving forward and recent approaches that condition video generation models on camera trajectories make strides towards it.
Yet, it remains challenging to generate a video of the same scene from multiple different camera trajectories. Solutions to this multi-video generation problem could enable large-scale 3D scene generation with editable camera trajectories, among other applications. We introduce collaborative video diffusion (CVD) as an important step towards this vision.
The CVD framework includes a novel cross-video synchronization module that promotes consistency between corresponding frames of the same video rendered from different camera poses using an epipolar attention mechanism.
Trained on top of a state-of-the-art camera-control module for video generation, CVD generates multiple videos rendered from different camera trajectories with significantly better consistency than baselines, as shown in extensive experiments.
1.3. Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models

We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components.
The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition.
Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets.
This enables a single-stage model capable of generating high-resolution images without the need for a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes.
Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
2. Vision Language Models (VLMs)
2.1. ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
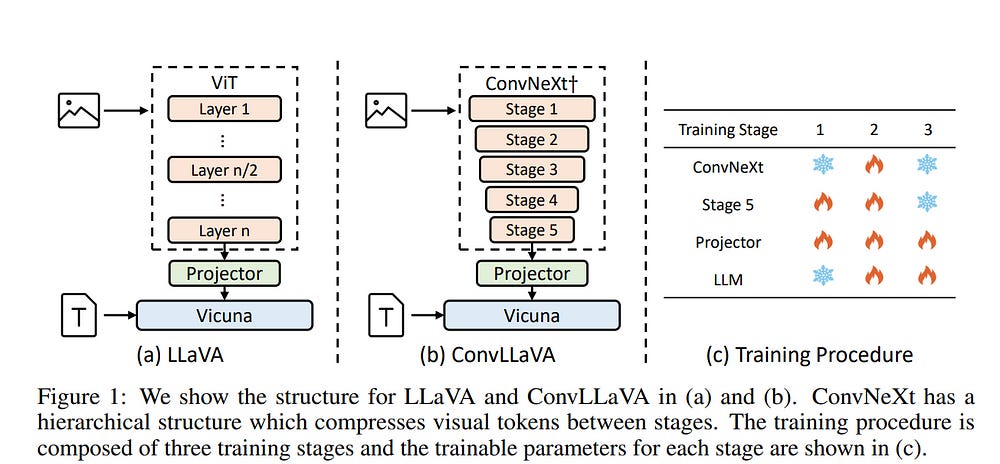
High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens.
However, the redundancy in visual tokens is the key problem as it leads to more substantial computing. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT).
ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations.
Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt’s original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy.
These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks.
2.2. An Introduction to Vision-Language Modeling

Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology.
However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized.
To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field.
First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
2.3. MotionLLM: Understanding Human Behaviors from Human Motions and Videos

This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs).
Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively.
In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights.
Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion.
Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.
3. Image Generation & Editing
3.1. PLA4D: Pixel-Level Alignments for Text-to-4D Gaussian Splatting

As text-conditioned diffusion models (DMs) achieve breakthroughs in image, video, and 3D generation, the research community’s focus has shifted to the more challenging task of text-to-4D synthesis, which introduces a temporal dimension to generate dynamic 3D objects.
In this context, we identify Score Distillation Sampling (SDS), a widely used technique for text-to-3D synthesis, as a significant hindrance to text-to-4D performance due to its Janus-faced and texture-unrealistic problems coupled with high computational costs.
In this paper, we propose Pixel-Level Alignments for Text-to-4D Gaussian Splatting (PLA4D), a novel method that utilizes text-to-video frames as explicit pixel alignment targets to generate static 3D objects and inject motion into them. Specifically, we introduce Focal Alignment to calibrate camera poses for rendering and GS-Mesh Contrastive Learning to distill geometry priors from rendered image contrasts at the pixel level.
Additionally, we develop Motion Alignment using a deformation network to drive changes in Gaussians and implement Reference Refinement for smooth 4D object surfaces. These techniques enable 4D Gaussian Splatting to align geometry, texture, and motion with generated videos at the pixel level.
Compared to previous methods, PLA4D produces synthesized outputs with better texture details in less time and effectively mitigates the Janus-faced problem. PLA4D is fully implemented using open-source models, offering an accessible, user-friendly, and promising direction for 4D digital content creation.
3.2. GECO: Generative Image-to-3D within a SECOnd

3D generation has seen remarkable progress in recent years. Existing techniques, such as score distillation methods, produce notable results but require extensive per-scene optimization, impacting time efficiency. Alternatively, reconstruction-based approaches prioritize efficiency but compromise quality due to their limited handling of uncertainty.
We introduce GECO, a novel method for high-quality 3D generative modeling that operates within a second. Our approach addresses the prevalent issues of uncertainty and inefficiency in current methods through a two-stage approach.
In the initial stage, we train a single-step multi-view generative model with score distillation. Then, a second-stage distillation is applied to address the challenge of view inconsistency from the multi-view prediction.
This two-stage process ensures a balanced approach to 3D generation, optimizing both quality and efficiency. Our comprehensive experiments demonstrate that GECO achieves high-quality image-to-3D generation with an unprecedented level of efficiency.
3.3. Part123: Part-aware 3D Reconstruction from a Single-view Image

Recently, the emergence of diffusion models has opened up new opportunities for single-view reconstruction. However, all the existing methods represent the target object as a closed mesh devoid of any structural information, thus neglecting the part-based structure, which is crucial for many downstream applications, of the reconstructed shape.
Moreover, the generated meshes usually suffer from large noises, unsmooth surfaces, and blurry textures, making it challenging to obtain satisfactory part segments using 3D segmentation techniques. In this paper, we present Part123, a novel framework for part-aware 3D reconstruction from a single-view image.
We first use diffusion models to generate multiview-consistent images from a given image, and then leverage Segment Anything Model (SAM), which demonstrates powerful generalization ability on arbitrary objects, to generate multiview segmentation masks.
To effectively incorporate 2D part-based information into 3D reconstruction and handle inconsistency, we introduce contrastive learning into a neural rendering framework to learn a part-aware feature space based on the multiview segmentation masks.
A clustering-based algorithm is also developed to automatically derive 3D part segmentation results from the reconstructed models. Experiments show that our method can generate 3D models with high-quality segmented parts on various objects.
Compared to existing unstructured reconstruction methods, the part-aware 3D models from our method benefit some important applications, including feature-preserving reconstruction, primitive fitting, and 3D shape editing.
3.4. Atlas3D: Physically Constrained Self-Supporting Text-to-3D for Simulation and Fabrication

Existing diffusion-based text-to-3D generation methods primarily focus on producing visually realistic shapes and appearances, often neglecting the physical constraints necessary for downstream tasks. Generated models frequently fail to maintain balance when placed in physics-based simulations or 3D printed.
This balance is crucial for satisfying user design intentions in interactive gaming, embodied AI, and robotics, where stable models are needed for reliable interaction. Additionally, stable models ensure that 3D-printed objects, such as figurines for home decoration, can stand on their own without requiring additional support.
To fill this gap, we introduce Atlas3D, an automatic and easy-to-implement method that enhances existing Score Distillation Sampling (SDS)-based text-to-3D tools. Atlas3D ensures the generation of self-supporting 3D models that adhere to physical laws of stability under gravity, contact, and friction.
Our approach combines a novel differentiable simulation-based loss function with physically inspired regularization, serving as either a refinement or a post-processing module for existing frameworks. We verify Atlas3D’s efficacy through extensive generation tasks and validate the resulting 3D models in both simulated and real-world environments.
4. Video Understanding & Generation
4.1. iVideoGPT: Interactive VideoGPTs are Scalable World Models

World models empower model-based agents to interactively explore, reason, and plan within imagined environments for real-world decision-making. However, the high demand for interactivity poses challenges in harnessing recent advancements in video generative models for developing world models at scale.
This work introduces Interactive VideoGPT (iVideoGPT), a scalable autoregressive transformer framework that integrates multimodal signals — visual observations, actions, and rewards — into a sequence of tokens, facilitating an interactive experience of agents via next-token prediction. iVideoGPT features a novel compressive tokenization technique that efficiently discretizes high-dimensional visual observations.
Leveraging its scalable architecture, we are able to pre-train iVideoGPT on millions of human and robotic manipulation trajectories, establishing a versatile foundation that is adaptable to serve as interactive world models for a wide range of downstream tasks.
These include action-conditioned video prediction, visual planning, and model-based reinforcement learning, where iVideoGPT achieves competitive performance compared with state-of-the-art methods. Our work advances the development of interactive general world models, bridging the gap between generative video models and practical model-based reinforcement learning applications.
4.2. I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models

The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop.
In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model.
Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve.
At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching.
We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework’s superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
4.3. Human4DiT: Free-view Human Video Generation with 4D Diffusion Transformer

We present a novel approach for generating high-quality, spatio-temporally coherent human videos from a single image under arbitrary viewpoints. Our framework combines the strengths of U-Nets for accurate condition injection and diffusion transformers for capturing global correlations across viewpoints and time.
The core is a cascaded 4D transformer architecture that factorizes attention across views, time, and spatial dimensions, enabling efficient modeling of the 4D space. Precise conditioning is achieved by injecting human identity, camera parameters, and temporal signals into the respective transformers.
To train this model, we curate a multi-dimensional dataset spanning images, videos, multi-view data and 3D/4D scans, along with a multi-dimensional training strategy. Our approach overcomes the limitations of previous methods based on GAN or UNet-based diffusion models, which struggle with complex motions and viewpoint changes.
Through extensive experiments, we demonstrate our method’s ability to synthesize realistic, coherent and free-view human videos, paving the way for advanced multimedia applications in areas such as virtual reality and animation.
4.4. Looking Backward: Streaming Video-to-Video Translation with Feature Banks
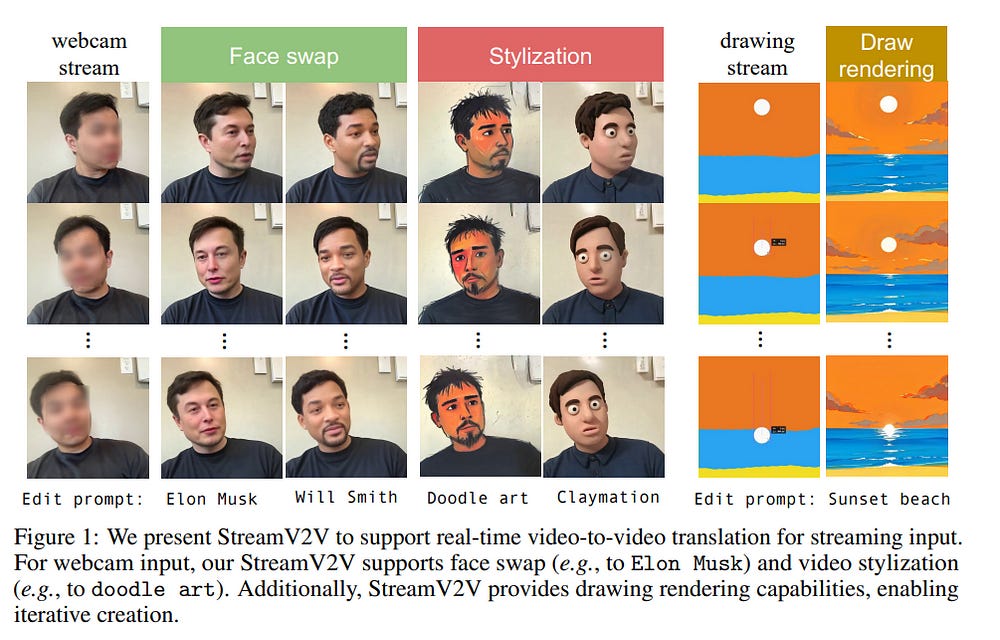
This paper introduces StreamV2V, a diffusion model that achieves real-time streaming video-to-video (V2V) translation with user prompts. Unlike prior V2V methods using batches to process limited frames, we opt to process frames in a streaming fashion, to support unlimited frames.
At the heart of StreamV2V lies a backward-looking principle that relates the present to the past. This is realized by maintaining a feature bank, which archives information from past frames. For incoming frames, StreamV2V extends self-attention to include banked keys and values and directly fuses similar past features into the output.
The feature bank is continually updated by merging stored and new features, making it compact but informative. StreamV2V stands out for its adaptability and efficiency, seamlessly integrating with image diffusion models without fine-tuning.
It can run 20 FPS on one A100 GPU, being 15x, 46x, 108x, and 158x faster than FlowVid, CoDeF, Rerender, and TokenFlow, respectively. Quantitative metrics and user studies confirm StreamV2V’s exceptional ability to maintain temporal consistency.
4.5. Vidu4D: Single Generated Video to High-Fidelity 4D Reconstruction with Dynamic Gaussian Surfels

Video generative models are receiving particular attention given their ability to generate realistic and imaginative frames. Besides, these models are also observed to exhibit strong 3D consistency, significantly enhancing their potential to act as world simulators.
In this work, we present Vidu4D, a novel reconstruction model that excels in accurately reconstructing 4D (i.e., sequential 3D) representations from single generated videos, addressing challenges associated with non-rigidity and frame distortion. This capability is pivotal for creating high-fidelity virtual contents that maintain both spatial and temporal coherence.
At the core of Vidu4D is our proposed Dynamic Gaussian Surfels (DGS) technique. DGS optimizes time-varying warping functions to transform Gaussian surfels (surface elements) from a static state to a dynamically warped state. This transformation enables a precise depiction of motion and deformation over time.
To preserve the structural integrity of surface-aligned Gaussian surfels, we design the warped-state geometric regularization based on continuous warping fields for estimating normals. Additionally, we learn refinements on rotation and scaling parameters of Gaussian surfels, which greatly alleviates texture flickering during the warping process and enhances the capture of fine-grained appearance details.
Vidu4D also contains a novel initialization state that provides a proper start for the warping fields in DGS. Equipping Vidu4D with an existing video generative model, the overall framework demonstrates high-fidelity text-to-4D generation in both appearance and geometry.
4.6. MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model

We present MOFA-Video, an advanced controllable image animation method that generates video from the given image using various additional controllable signals (such as human landmarks reference, manual trajectories, and another even provided video) or their combinations.
This is different from previous methods which only can work on a specific motion domain or show weak control abilities with diffusion prior. To achieve our goal, we design several domain-aware motion field adapters (\ie, MOFA-Adapters) to control the generated motions in the video generation pipeline.
For MOFA-Adapters, we consider the temporal motion consistency of the video and generate the dense motion flow from the given sparse control conditions first, and then, the multi-scale features of the given image are wrapped as a guided feature for stable video diffusion generation.
We naively train two motion adapters for the manual trajectories and the human landmarks individually since they both contain sparse information about the control. After training, the MOFA-Adapters in different domains can also work together for more controllable video generation.
4.7. T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback

Diffusion-based text-to-video (T2V) models have achieved significant success but continue to be hampered by the slow sampling speed of their iterative sampling processes.
To address the challenge, consistency models have been proposed to facilitate fast inference, albeit at the cost of sample quality. In this work, we aim to break the quality bottleneck of a video consistency model (VCM) to achieve both fast and high-quality video generation.
We introduce T2V-Turbo, which integrates feedback from a mixture of differentiable reward models into the consistency distillation (CD) process of a pre-trained T2V model.
Notably, we directly optimize rewards associated with single-step generations that arise naturally from computing the CD loss, effectively bypassing the memory constraints imposed by backpropagating gradients through an iterative sampling process.
Remarkably, the 4-step generations from our T2V-Turbo achieve the highest total score on VBench, even surpassing Gen-2 and Pika. We further conduct human evaluations to corroborate the results, validating that the 4-step generations from our T2V-Turbo are preferred over the 50-step DDIM samples from their teacher models, representing more than a tenfold acceleration while improving video generation quality.
4.8. 3DitScene: Editing Any Scene via Language-guided Disentangled Gaussian Splatting

Scene image editing is crucial for entertainment, photography, and advertising design. Existing methods solely focus on either 2D individual object or 3D global scene editing.
This results in a lack of a unified approach to effectively control and manipulate scenes at the 3D level with different levels of granularity. In this work, we propose 3DitScene, a novel and unified scene editing framework leveraging language-guided disentangled Gaussian Splatting that enables seamless editing from 2D to 3D, allowing precise control over scene composition and individual objects.
We first incorporate 3D Gaussians that are refined through generative priors and optimization techniques. Language features from CLIP then introduce semantics into 3D geometry for object disentanglement.
With the disentangled Gaussians, 3DitScene allows for manipulation at both the global and individual levels, revolutionizing creative expression and empowering control over scenes and objects. Experimental results demonstrate the effectiveness and versatility of 3DitScene in scene image editing.
4.9. EasyAnimate: A High-Performance Long Video Generation Method based on Transformer Architecture

This paper presents EasyAnimate, an advanced method for video generation that leverages the power of transformer architecture for high-performance outcomes.
We have expanded the DiT framework originally designed for 2D image synthesis to accommodate the complexities of 3D video generation by incorporating a motion module block. It is used to capture temporal dynamics, thereby ensuring the production of consistent frames and seamless motion transitions.
The motion module can be adapted to various DiT baseline methods to generate video with different styles. It can also generate videos with different frame rates and resolutions during both training and inference phases, suitable for both images and videos.
Moreover, we introduce slice VAE, a novel approach to condense the temporal axis, facilitating the generation of long duration videos. Currently, EasyAnimate exhibits the proficiency to generate videos with 144 frames.
We provide a holistic ecosystem for video production based on DiT, encompassing aspects such as data pre-processing, VAE training, DiT models training (both the baseline model and LoRA model), and end-to-end video inference.
5. Object Detection
5.1. DeMamba: AI-Generated Video Detection on Million-Scale GenVideo Benchmark

Recently, video generation techniques have advanced rapidly. Given the popularity of video content on social media platforms, these models intensify concerns about the spread of fake information. Therefore, there is a growing demand for detectors capable of distinguishing between fake AI-generated videos and mitigating the potential harm caused by fake information.
However, the lack of large-scale datasets from the most advanced video generators poses a barrier to the development of such detectors. To address this gap, we introduce the first AI-generated video detection dataset, GenVideo.
It features the following characteristics:
A large volume of videos, including over one million AI-generated and real videos collected
A rich diversity of generated content and methodologies, covering a broad spectrum of video categories and generation techniques.
We conducted extensive studies of the dataset and proposed two evaluation methods tailored for real-world-like scenarios to assess the detectors’ performance: the cross-generator video classification task assesses the generalizability of trained detectors on generators; the degraded video classification task evaluates the robustness of detectors to handle videos that have degraded in quality during dissemination.
Moreover, we introduced a plug-and-play module, named Detail Mamba (DeMamba), designed to enhance the detectors by identifying AI-generated videos through the analysis of inconsistencies in temporal and spatial dimensions.
Our extensive experiments demonstrate DeMamba’s superior generalizability and robustness on GenVideo compared to existing detectors. We believe that the GenVideo dataset and the DeMamba module will significantly advance the field of AI-generated video detection.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
