


Top Important Computer Vision Papers for the Week from 17/06 to 23/06
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Third Week of June 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. Diffusion Models
1.1. Vivid-ZOO: Multi-View Video Generation with Diffusion Model

While diffusion models have shown impressive performance in 2D image/video generation, diffusion-based Text-to-Multi-view-Video (T2MVid) generation remains underexplored.
The new challenges posed by T2MVid generation lie in the lack of massive captioned multi-view videos and the complexity of modeling such multi-dimensional distribution. To this end, we propose a novel diffusion-based pipeline that generates high-quality multi-view videos centered around a dynamic 3D object from text.
Specifically, we factor the T2MVid problem into viewpoint-space and time components. Such factorization allows us to combine and reuse layers of advanced pre-trained multi-view image and 2D video diffusion models to ensure multi-view consistency as well as temporal coherence for the generated multi-view videos, largely reducing the training cost.
We further introduce alignment modules to align the latent spaces of layers from the pre-trained multi-view and the 2D video diffusion models, addressing the reused layers’ incompatibility that arises from the domain gap between 2D and multi-view data.
In support of this and future research, we further contribute a captioned multi-view video dataset. Experimental results demonstrate that our method generates high-quality multi-view videos, exhibiting vivid motions, temporal coherence, and multi-view consistency, given a variety of text prompts.
1.2. Exploring the Role of Large Language Models in Prompt Encoding for Diffusion Models

Large language models (LLMs) based on decoder-only transformers have demonstrated superior text understanding capabilities compared to CLIP and T5-series models.
However, the paradigm for utilizing current advanced LLMs in text-to-image diffusion models remains to be explored. We observed an unusual phenomenon: directly using a large language model as the prompt encoder significantly degrades the prompt-following ability in image generation. We identified two main obstacles behind this issue.
One is the misalignment between the next token prediction training in LLM and the requirement for discriminative prompt features in diffusion models. The other is the intrinsic positional bias introduced by the decoder-only architecture.
To deal with this issue, we propose a novel framework to fully harness the capabilities of LLMs. Through the carefully designed usage guidance, we effectively enhance the text representation capability for prompt encoding and eliminate its inherent positional bias.
This allows us to integrate state-of-the-art LLMs into the text-to-image generation model flexibly. Furthermore, we also provide an effective manner to fuse multiple LLMs into our framework.
Considering the excellent performance and scaling capabilities demonstrated by the transformer architecture, we further design an LLM-Infused Diffusion Transformer (LI-DiT) based on the framework. We conduct extensive experiments to validate LI-DiT across model size and data size.
Benefiting from the inherent ability of the LLMs and our innovative designs, the prompt understanding performance of LI-DiT easily surpasses state-of-the-art open-source models as well as mainstream closed-source commercial models including Stable Diffusion 3, DALL-E 3, and Midjourney V6. The powerful LI-DiT-10B will be available after further optimization and security checks.
1.3. ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning

Recently, advancements in video synthesis have attracted significant attention. Video synthesis models such as AnimateDiff and Stable Video Diffusion have demonstrated the practical applicability of diffusion models in creating dynamic visual content.
The emergence of SORA has further spotlighted the potential of video generation technologies. Nonetheless, the extension of video lengths has been constrained by the limitations in computational resources. Most existing video synthesis models can only generate short video clips.
In this paper, we propose a novel post-tuning methodology for video synthesis models, called ExVideo. This approach is designed to enhance the capability of current video synthesis models, allowing them to produce content over extended temporal durations while incurring lower training expenditures.
In particular, we design extension strategies across common temporal model architectures respectively, including 3D convolution, temporal attention, and positional embedding. To evaluate the efficacy of our proposed post-tuning approach, we conduct extension training on the Stable Video Diffusion model.
Our approach augments the model’s capacity to generate up to 5times its original number of frames, requiring only 1.5k GPU hours of training on a dataset comprising 40k videos.
Importantly, the substantial increase in video length doesn’t compromise the model’s innate generalization capabilities, and the model showcases its advantages in generating videos of diverse styles and resolutions. We will release the source code and the enhanced model publicly.
1.4. Immiscible Diffusion: Accelerating Diffusion Training with Noise Assignment

In this paper, we point out suboptimal noise-data mapping leads to slow training of diffusion models. During diffusion training, current methods diffuse each image across the entire noise space, resulting in a mixture of all images at every point in the noise layer.
We emphasize that this random mixture of noise-data mapping complicates the optimization of the denoising function in diffusion models. Drawing inspiration from the immiscible phenomenon in physics, we propose Immiscible Diffusion, a simple and effective method to improve the random mixture of noise-data mapping.
In physics, miscibility can vary according to various intermolecular forces. Thus, immiscibility means that the mixing of the molecular sources is distinguishable. Inspired by this, we propose an assignment-then-diffusion training strategy. Specifically, prior to diffusing the image data into noise, we assign diffusion target noise for the image data by minimizing the total image-noise pair distance in a mini-batch.
The assignment functions analogously to external forces to separate the diffuse-able areas of images, thus mitigating the inherent difficulties in diffusion training. Our approach is remarkably simple, requiring only one line of code to restrict the diffuse-able area for each image while preserving the Gaussian distribution of noise.
This ensures that each image is projected only to nearby noise. To address the high complexity of the assignment algorithm, we employ a quantized assignment method to reduce the computational overhead to a negligible level. Experiments demonstrate that our method achieves up to 3x faster training for consistency models and DDIM on the CIFAR dataset, and up to 1.3x faster on CelebA datasets for consistency models.
Besides, we conduct a thorough analysis of the Immiscible Diffusion, which sheds lights on how it improves diffusion training speed while improving the fidelity.
1.5. Not All Prompts Are Made Equal: Prompt-based Pruning of Text-to-Image Diffusion Models

Text-to-image (T2I) diffusion models have demonstrated impressive image generation capabilities. Still, their computational intensity prohibits resource-constrained organizations from deploying T2I models after fine-tuning them on their internal target data.
While pruning techniques offer a potential solution to reduce the computational burden of T2I models, static pruning methods use the same pruned model for all input prompts, overlooking the varying capacity requirements of different prompts.
Dynamic pruning addresses this issue by utilizing a separate sub-network for each prompt, but it prevents batch parallelism on GPUs. To overcome these limitations, we introduce Adaptive Prompt-Tailored Pruning (APTP), a novel prompt-based pruning method designed for T2I diffusion models. Central to our approach is a prompt router model, which learns to determine the required capacity for an input text prompt and routes it to an architecture code, given a total desired compute budget for prompts.
Each architecture code represents a specialized model tailored to the prompts assigned to it, and the number of codes is a hyperparameter. We train the prompt router and architecture codes using contrastive learning, ensuring that similar prompts are mapped to nearby codes. Further, we employ optimal transport to prevent the codes from collapsing into a single one.
We demonstrate APTP’s effectiveness by pruning Stable Diffusion (SD) V2.1 using CC3M and COCO as target datasets. APTP outperforms the single-model pruning baselines in terms of FID, CLIP, and CMMD scores.
Our analysis of the clusters learned by APTP reveals they are semantically meaningful. We also show that APTP can automatically discover previously empirically found challenging prompts for SD, e.g., prompts for generating text images, assigning them to higher capacity codes.
2. Vision Language Models (VLMs)
2.1. OmniCorpus: A Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text

Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning.
However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10-billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens.
Compared to counterparts (e.g., MMC4, OBELICS), our dataset:
Has 15 times larger scales while maintaining good data quality
Features more diverse sources, including both English and non-English websites as well as video-centric websites
It is more flexible, and easily degradable from an image-text interleaved format to pure text corpus and image-text pairs.
Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research.
2.2. VoCo-LLaMA: Towards Vision Compression with Large Language Models

Vision-Language Models (VLMs) have achieved remarkable success in various multi-modal tasks, but they are often bottlenecked by the limited context window and high computational cost of processing high-resolution image inputs and videos.
Vision compression can alleviate this problem by reducing the vision token count. Previous approaches compress vision tokens with external modules and force LLMs to understand the compressed ones, leading to visual information loss.
However, the LLMs’ understanding paradigm of vision tokens is not fully utilised in the compression learning process. We propose VoCo-LLaMA, the first approach to compress vision tokens using LLMs. By introducing Vision Compression tokens during the vision instruction tuning phase and leveraging attention distillation, our method distill how
LLMs comprehend vision tokens into their processing of VoCo tokens. VoCo-LLaMA facilitates effective vision compression and improves the computational efficiency during the inference stage. Specifically, our method achieves minimal performance loss with a compression ratio of 576times, resulting in up to 94.8% fewer FLOPs and 69.6% acceleration in inference time.
Furthermore, through continuous training using time-series compressed token sequences of video frames, VoCo-LLaMA demonstrates the ability to understand temporal correlations, outperforming previous methods on popular video question-answering benchmarks.
Our approach presents a promising way to unlock the full potential of VLMs’ contextual window, enabling more scalable multi-modal applications.
2.3. Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
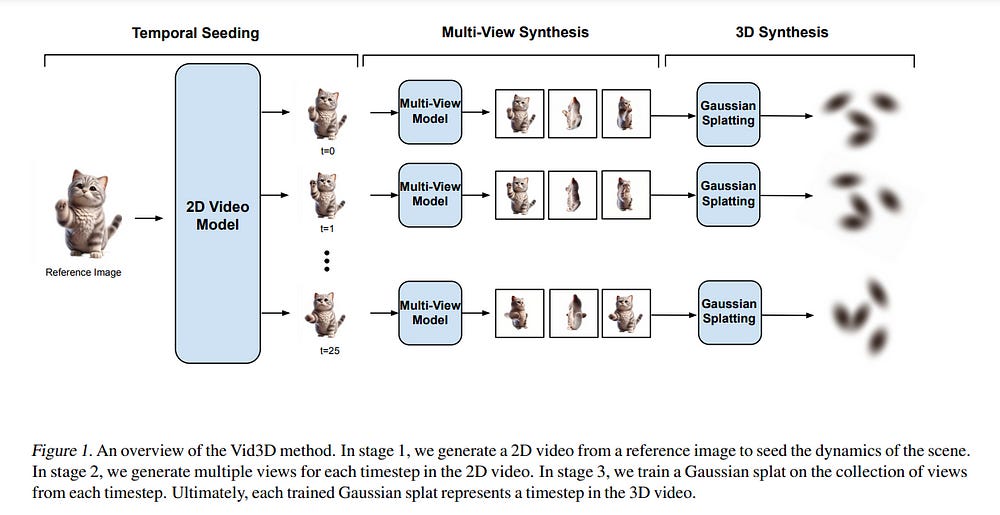
A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene.
In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently.
We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D “seed” of the video’s temporal dynamics and then independently generating a 3D representation for each timestep in the seed video.
We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor.
Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.
3. Image Generation & Editing
3.1. Make It Count: Text-to-Image Generation with an Accurate Number of Objects

Despite the unprecedented success of text-to-image diffusion models, controlling the number of depicted objects using text is surprisingly hard. This is important for various applications from technical documents, to children’s books to illustrating cooking recipes.
Generating object-correct counts is fundamentally challenging because the generative model needs to keep a sense of separate identity for every instance of the object, even if several objects look identical or overlap, and then carry out a global computation implicitly during generation. It is still unknown if such representations exist.
To address count-correct generation, we first identify features within the diffusion model that can carry the object identity information. We then use them to separate and count instances of objects during the denoising process and detect over-generation and under-generation.
We fix the latter by training a model that predicts both the shape and location of a missing object, based on the layout of existing ones, and show how it can be used to guide denoising with correct object count.
Our approach, CountGen, does not depend on external source to determine object layout, but rather uses the prior from the diffusion model itself, creating prompt-dependent and seed-dependent layouts. Evaluated on two benchmark datasets, we find that CountGen strongly outperforms the count-accuracy of existing baselines.
3.2. Invertible Consistency Distillation for Text-Guided Image Editing in Around 7 Steps

Diffusion distillation represents a highly promising direction for achieving faithful text-to-image generation in a few sampling steps. However, despite recent successes, existing distilled models still do not provide the full spectrum of diffusion abilities, such as real image inversion, which enables many precise image manipulation methods.
This work aims to enrich distilled text-to-image diffusion models with the ability to effectively encode real images into their latent space. To this end, we introduce invertible Consistency Distillation (iCD), a generalized consistency distillation framework that facilitates both high-quality image synthesis and accurate image encoding in only 3–4 inference steps.
Though the inversion problem for text-to-image diffusion models gets exacerbated by high classifier-free guidance scales, we notice that dynamic guidance significantly reduces reconstruction errors without noticeable degradation in generation performance.
As a result, we demonstrate that iCD equipped with dynamic guidance may serve as a highly effective tool for zero-shot text-guided image editing, competing with more expensive state-of-the-art alternatives.
3.3. Improving Visual Commonsense in Language Models via Multiple Image Generation

Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information.
In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge — the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs’ visual commonsense.
Specifically, our method generates multiple images based on the input text prompt and integrates these into the model’s decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only.
This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension.
Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks.
4. Video Understanding & Generation
4.1. Rethinking Human Evaluation Protocol for Text-to-Video Models: Enhancing Reliability, Reproducibility, and Practicality

Recent text-to-video (T2V) technology advancements, as demonstrated by models such as Gen2, Pika, and Sora, have significantly broadened its applicability and popularity. Despite these strides, evaluating these models poses substantial challenges.
Primarily, due to the limitations inherent in automatic metrics, manual evaluation is often considered a superior method for assessing T2V generation. However, existing manual evaluation protocols face reproducibility, reliability, and practicality issues.
To address these challenges, this paper introduces the Text-to-Video Human Evaluation (T2VHE) protocol, a comprehensive and standardized protocol for T2V models.
The T2VHE protocol includes well-defined metrics, thorough annotator training, and an effective dynamic evaluation module. Experimental results demonstrate that this protocol not only ensures high-quality annotations but can also reduce evaluation costs by nearly 50%.
We will open-source the entire setup of the T2VHE protocol, including the complete protocol workflow, the dynamic evaluation component details, and the annotation interface code. This will help communities establish more sophisticated human assessment protocols.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
