


Top Important Computer Vision Papers for the Week from 05/02 to 11/02
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Second Week of February 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Stable Diffusion
Vision Language Models
Image Generation & Editing
Video Generation & Editing
Image Recognition
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Stable Diffusion
1.1. DiffEditor: Boosting Accuracy and Flexibility on Diffusion-based Image Editing

Large-scale Text-to-Image (T2I) diffusion models have revolutionized image generation over the last few years. Although owning diverse and high-quality generation capabilities, translating these abilities to fine-grained image editing remains challenging.
In this paper, we propose DiffEditor to rectify two weaknesses in existing diffusion-based image editing:
In complex scenarios, editing results often lack editing accuracy and exhibit unexpected artifacts
Lack of flexibility to harmonize editing operations, e.g., imagine new content.
In our solution, we introduce image prompts in fine-grained image editing, cooperating with the text prompt to better describe the editing content. To increase the flexibility while maintaining content consistency, we locally combine stochastic differential equation (SDE) into the ordinary differential equation (ODE) sampling.
In addition, we incorporate regional score-based gradient guidance and a time travel strategy into the diffusion sampling, further improving the editing quality. Extensive experiments demonstrate that our method can efficiently achieve state-of-the-art performance on various fine-grained image editing tasks, including editing within a single image (e.g., object moving, resizing, and content dragging) and across images (e.g., appearance replacing and object pasting).
1.2. Implicit Diffusion: Efficient Optimization through Stochastic Sampling

We present a new algorithm to optimize distributions defined implicitly by parameterized stochastic diffusions. Doing so allows us to modify the outcome distribution of sampling processes by optimizing their parameters. We introduce a general framework for first-order optimization of these processes, that performs jointly, in a single loop, optimization and sampling steps.
This approach is inspired by recent advances in bilevel optimization and automatic implicit differentiation, leveraging the point of view of sampling as an optimization over the space of probability distributions. We provide theoretical guarantees on the performance of our method, as well as experimental results demonstrating its effectiveness in real-world settings.
1.3. Diffusion World Model
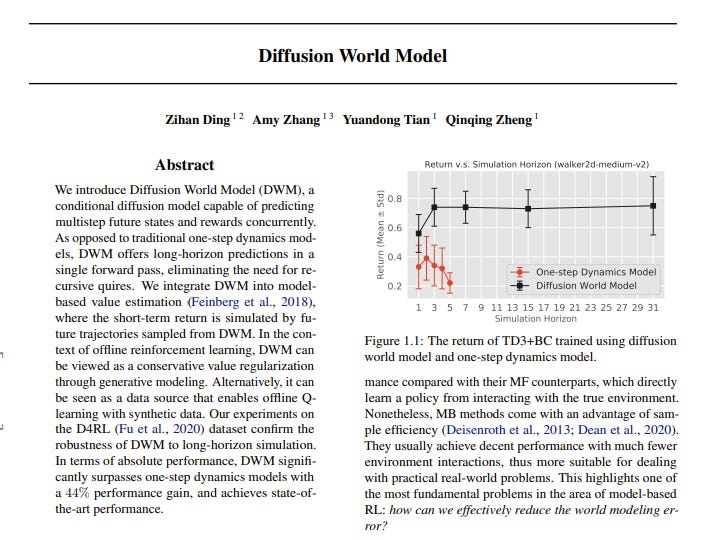
We introduce the Diffusion World Model (DWM), a conditional diffusion model capable of predicting multistep future states and rewards concurrently. As opposed to traditional one-step dynamics models, DWM offers long-horizon predictions in a single forward pass, eliminating the need for recursive queries.
We integrate DWM into model-based value estimation, where the short-term return is simulated by future trajectories sampled from DWM. In the context of offline reinforcement learning, DWM can be viewed as a conservative value regularization through generative modeling. Alternatively, it can be seen as a data source that enables offline Q-learning with synthetic data. Our experiments on the D4RL dataset confirm the robustness of DWM to long-horizon simulation.
In terms of absolute performance, DWM significantly surpasses one-step dynamics models with a 44% performance gain and achieves state-of-the-art performance.
1.4. $λ$-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent Space
Despite the recent advances in personalized text-to-image (P-T2I) generative models, subject-driven T2I remains challenging. The primary bottlenecks include 1) Intensive training resource requirements, 2) Hyper-parameter sensitivity leading to inconsistent outputs, and 3) Balancing the intricacies of novel visual concepts and composition alignment.
We start by re-iterating the core philosophy of T2I diffusion models to address the above limitations. Predominantly, contemporary subject-driven T2I approaches hinge on Latent Diffusion Models (LDMs), which facilitate T2I mapping through cross-attention layers. While LDMs offer distinct advantages, P-T2I methods’ reliance on the latent space of these diffusion models significantly escalates resource demands, leading to inconsistent results and necessitating numerous iterations for a single desired image.
Recently, ECLIPSE has demonstrated a more resource-efficient pathway for training UnCLIP-based T2I models, circumventing the need for diffusion text-to-image priors. Building on this, we introduce lambda-ECLIPSE. Our method illustrates that effective P-T2I does not necessarily depend on the latent space of diffusion models.
lambda-ECLIPSE achieves single, multi-subject, and edge-guided T2I personalization with just 34M parameters and is trained on a mere 74 GPU hours using 1.6M image-text interleaved data. Through extensive experiments, we also establish that lambda-ECLIPSE surpasses existing baselines in composition alignment while preserving concept alignment performance, even with significantly lower resource utilization.
2. Vision Language Models
2.1. ScreenAI: A Vision-Language Model for UI and Infographics Understanding

Screen user interfaces (UIs) and infographics, sharing similar visual language and design principles, play important roles in human communication and human-machine interaction. We introduce ScreenAI, a vision-language model that specializes in UI and infographics understanding.
Our model improves upon the PaLI architecture with the flexible patching strategy of pix2struct and is trained on a unique mixture of datasets. At the heart of this mixture is a novel screen annotation task in which the model has to identify the type and location of UI elements. We use these text annotations to describe screens to Large Language Models and automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale.
We run ablation studies to demonstrate the impact of these design choices. At only 5B parameters, ScreenAI achieves new state-of-the-artresults on UI- and infographics-based tasks (Multi-page DocVQA, WebSRC, MoTIF, and Widget Captioning), and new best-in-class performance on others (Chart QA, DocVQA, and InfographicVQA) compared to models of similar size. Finally, we released three new datasets: one focused on the screen annotation task and two others focused on question answering.
2.2. MobileVLM V2: Faster and Stronger Baseline for Vision Language Model

We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs’ performance.
Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale.
2.3. CogCoM: Train Large Vision-Language Models Diving into Details through Chain of Manipulations
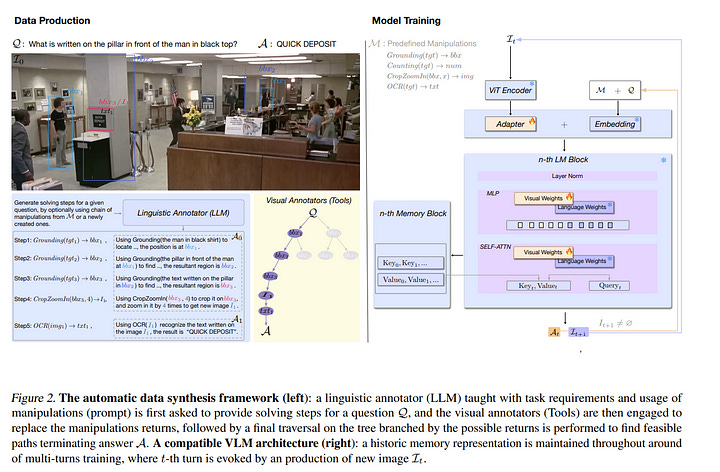
Vision-Language Models (VLMs) have demonstrated their widespread viability thanks to extensive training in aligning visual instructions to answers. However, this conclusive alignment leads models to ignore critical visual reasoning and further results in failures in meticulous visual problems and unfaithful responses.
In this paper, we propose a Chain of Manipulations, a mechanism that enables VLMs to solve problems with a series of manipulations, where each manipulation refers to an operation on the visual input, either from intrinsic abilities (e.g., grounding) acquired through prior training or from imitating human-like behaviors (e.g., zoom in).
This mechanism encourages VLMs to generate faithful responses with evidential visual reasoning, and permits users to trace error causes in the interpretable paths. We thus train CogCoM, a general 17B VLM with a memory-based compatible architecture endowed with this reasoning mechanism.
Experiments show that our model achieves state-of-the-art performance across 8 benchmarks from 3 categories, and a limited number of training steps with the data swiftly gains a competitive performance.
3. Image Generation & Editing
3.1. Training-Free Consistent Text-to-Image Generation

Text-to-image models offer a new level of creative flexibility by allowing users to guide the image generation process through natural language. However, using these models to consistently portray the same subject across diverse prompts remains challenging.
Existing approaches fine-tune the model to teach it new words that describe specific user-provided subjects or add image conditioning to the model. These methods require lengthy per-subject optimization or large-scale pre-training. Moreover, they struggle to align generated images with text prompts and face difficulties in portraying multiple subjects.
Here, we present ConsiStory, a training-free approach that enables consistent subject generation by sharing the internal activations of the pretrained model. We introduce a subject-driven shared attention block and correspondence-based feature injection to promote subject consistency between images.
Additionally, we develop strategies to encourage layout diversity while maintaining subject consistency. We compare ConsiStory to a range of baselines, and demonstrate state-of-the-art performance on subject consistency and text alignment, without requiring a single optimization step. Finally, ConsiStory can naturally extend to multi-subject scenarios and even enable training-free personalization for common objects.
3.2. EscherNet: A Generative Model for Scalable View Synthesis

We introduce EscherNet, a multi-view conditioned diffusion model for view synthesis. EscherNet learns implicit and generative 3D representations coupled with a specialized camera positional encoding, allowing precise and continuous relative control of the camera transformation between an arbitrary number of reference and target views.
EscherNet offers exceptional generality, flexibility, and scalability in view synthesis — it can generate more than 100 consistent target views simultaneously on a single consumer-grade GPU, despite being trained with a fixed number of 3 reference views to 3 target views. As a result, EscherNet not only addresses zero-shot novel view synthesis but also naturally unifies single- and multi-image 3D reconstruction, combining these diverse tasks into a single, cohesive framework.
Our extensive experiments demonstrate that EscherNet achieves state-of-the-art performance in multiple benchmarks, even when compared to methods specifically tailored for each problem. This remarkable versatility opens up new directions for designing scalable neural architectures for 3D vision.
3.3. LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation

3D content creation has achieved significant progress in terms of both quality and speed. Although current feed-forward models can produce 3D objects in seconds, their resolution is constrained by the intensive computation required during training.
In this paper, we introduce the Large Multi-View Gaussian Model (LGM), a novel framework designed to generate high-resolution 3D models from text prompts or single-view images.
Our key insights are two-fold: 1) 3D Representation: We propose multi-view Gaussian features as an efficient yet powerful representation, which can then be fused for differentiable rendering. 2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operating on multi-view images, which can be produced from text or single-view image input by leveraging multi-view diffusion models.
Extensive experiments demonstrate the high fidelity and efficiency of our approach. Notably, we maintain the fast speed to generate 3D objects within 5 seconds while boosting the training resolution to 512, thereby achieving high-resolution 3D content generation.
4. Video Generation & Editing
4.1. Boximator: Generating Rich and Controllable Motions for Video Synthesis

Generating rich and controllable motion is a pivotal challenge in video synthesis. We propose Boximator, a new approach for fine-grained motion control. Boximator introduces two constraint types: hard box and softbox.
Users select objects in the conditional frame using hard boxes and then use either type of box to roughly or rigorously define the object’s position, shape, or motion path in future frames. Boximator functions as a plug-in for existing video diffusion models.
Its training process preserves the base model’s knowledge by freezing the original weights and training only the control module. To address training challenges, we introduce a novel self-tracking technique that greatly simplifies the learning of box-object correlations. Empirically, Boximator achieves state-of-the-art video quality (FVD) scores, improving on two base models, and further enhancing after incorporating box constraints.
Its robust motion controllability is validated by drastic increases in the bounding box alignment metric. The human evaluation also shows that users favor Boximator generation results over the base model.
4.2. Direct-a-Video: Customized Video Generation with User-Directed Camera Movement and Object Motion
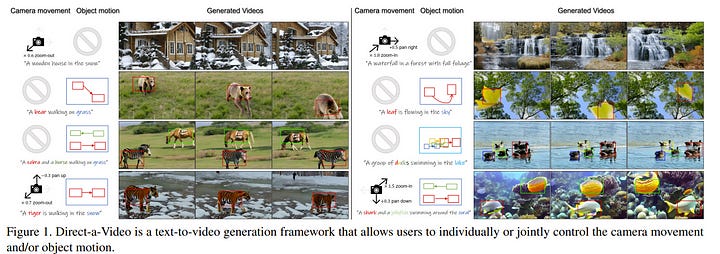
Recent text-to-video diffusion models have achieved impressive progress. In practice, users often desire the ability to control object motion and camera movement independently for customized video creation. However, current methods lack the focus on separately controlling object motion and camera movement in a decoupled manner, which limits the controllability and flexibility of text-to-video models.
In this paper, we introduce Direct-a-Video, a system that allows users to independently specify motions for one or multiple objects and/or camera movements as if directing a video. We propose a simple yet effective strategy for the decoupled control of object motion and camera movement. Object motion is controlled through spatial cross-attention modulation using the model’s inherent priors, requiring no additional optimization. For camera movement, we introduce new temporal cross-attention layers to interpret quantitative camera movement parameters.
We further employ an augmentation-based approach to train these layers in a self-supervised manner on a small-scale dataset, eliminating the need for explicit motion annotation. Both components operate independently, allowing individual or combined control, and can generalize to open-domain scenarios. Extensive experiments demonstrate the superiority and effectiveness of our method.
4.3. Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization

In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos.
Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions.
These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content.
Our proposed framework is capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation.
4.4. InteractiveVideo: User-Centric Controllable Video Generation with Synergistic Multimodal Instructions

We introduce InteractiveVideo, a user-centric framework for video generation. Different from traditional generative approaches that operate based on user-provided images or text, our framework is designed for dynamic interaction, allowing users to instruct the generative model through various intuitive mechanisms during the whole generation process, e.g. text and image prompts, painting, drag-and-drop, etc.
We propose a Synergistic Multimodal Instruction mechanism, designed to seamlessly integrate users’ multimodal instructions into generative models, thus facilitating a cooperative and responsive interaction between user inputs and the generative process.
This approach enables iterative and fine-grained refinement of the generation result through precise and effective user instructions. With InteractiveVideo, users are given the flexibility to meticulously tailor key aspects of a video. They can paint the reference image, edit semantics, and adjust video motions until their requirements are fully met.
4.5. ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation

Image-to-video (I2V) generation aims to use the initial frame (alongside a text prompt) to create a video sequence. A grand challenge in I2V generation is to maintain visual consistency throughout the video: existing methods often struggle to preserve the integrity of the subject, background, and style from the first frame, as well as ensure a fluid and logical progression within the video narrative.
To mitigate these issues, we propose ConsistI2V, a diffusion-based method to enhance visual consistency for I2V generation. Specifically, we introduce (1) spatiotemporal attention over the first frame to maintain spatial and motion consistency, and (2) noise initialization from the low-frequency band of the first frame to enhance layout consistency.
These two approaches enable ConsistI2V to generate highly consistent videos. We also extend the proposed approaches to show their potential to improve consistency in auto-regressive long video generation and camera motion control. To verify the effectiveness of our method, we propose I2V-Bench, a comprehensive evaluation benchmark for I2V generation. Our automatic and human evaluation results demonstrate the superiority of ConsistI2V over existing methods.
5. Image Recognition
5.1. Question-Aware Vision Transformer for Multimodal Reasoning

Vision-language (VL) models have gained significant research focus, enabling remarkable advances in multimodal reasoning. These architectures typically comprise a vision encoder, a Large Language Model (LLM), and a projection module that aligns visual features with the LLM’s representation space.
Despite their success, a critical limitation persists: the vision encoding process remains decoupled from user queries, often in the form of image-related questions. Consequently, the resulting visual features may not be optimally attuned to the query-specific elements of the image. To address this, we introduce QA-ViT, a Question Vision Transformer approach for multimodal reasoning, which embeds question awareness directly within the vision encoder.
This integration results in dynamic visual features focusing on relevant image aspects to the posed question. QA-ViT is model-agnostic and can be incorporated efficiently into any VL architecture. Extensive experiments demonstrate the effectiveness of applying our method to various multimodal architectures, leading to consistent improvement across diverse tasks and showcasing its potential for enhancing visual and scene-text understanding.
5.2. Vision Superalignment: Weak-to-Strong Generalization for Vision Foundation Models

Recent advancements in large language models have sparked interest in their extraordinary and near-superhuman capabilities, leading researchers to explore methods for evaluating and optimizing these abilities, which is called superalignment.
In this context, our paper delves into the realm of vision foundation models, focusing on the concept of weak-to-strong generalization, which involves using a weaker model to supervise a stronger one, aiming to enhance the latter’s capabilities beyond the former’s limits.
We introduce a novel and adaptively adjustable loss function for weak-to-strong supervision. Our comprehensive experiments span various scenarios, including few-shot learning, transfer learning, noisy label learning, and common knowledge distillation settings.
The results are striking: our approach not only exceeds the performance benchmarks set by strong-to-strong generalization but also surpasses the outcomes of fine-tuning strong models with whole datasets. This compelling evidence underscores the significant potential of weak-to-strong generalization, showcasing its capability to substantially elevate the performance of vision foundation models.
5.3. InstaGen: Enhancing Object Detection by Training on Synthetic Dataset

In this paper, we introduce a novel paradigm to enhance the ability of object detectors, e.g., expanding categories or improving detection performance, by training on synthetic datasets generated from diffusion models. Specifically, we integrate an instance-level grounding head into a pre-trained, generative diffusion model, to augment it with the ability of localising arbitrary instances in the generated images.
The grounding head is trained to align the text embedding of category names with the regional visual feature of the diffusion model, using supervision from an off-the-shelf object detector, and a novel self-training scheme on (novel) categories not covered by the detector.
This enhanced version of the diffusion model, termed InstaGen, can serve as a data synthesizer for object detection. We conduct thorough experiments to show that, the object detectors can be enhanced while training on the synthetic dataset from InstaGen, demonstrating superior performance over existing state-of-the-art methods in open-vocabulary (+4.5 AP) and data-sparse (+1.2 to 5.2 AP) scenarios.
5.4. IMUSIC: IMU-based Facial Expression Capture

For facial motion capture and analysis, the dominated solutions are generally based on visual cues, which cannot protect privacy and are vulnerable to occlusions. Inertial measurement units (IMUs) serve as potential rescues yet are mainly adopted for full-body motion capture. In this paper, we propose IMUSIC to fill the gap, a novel path for facial expression capture using purely IMU signals, significantly distant from previous visual solutions.
The key design in our IMUSIC is a trilogy. We first design micro-IMUs to suit facial capture, companion with an anatomy-driven IMU placement scheme. Then, we contribute a novel IMU-ARKit dataset, which provides rich paired IMU/visual signals for diverse facial expressions and performances. Such unique multi-modality brings huge potential for future directions like IMU-based facial behavior analysis.
Moreover, utilizing IMU-ARKit, we introduce a strong baseline approach to accurately predict facial blend shape parameters from purely IMU signals. Specifically, we tailor a Transformer diffusion model with a two-stage training strategy for this novel tracking task. The IMUSIC framework empowers us to perform accurate facial capture in scenarios where visual methods falter and simultaneously safeguard user privacy.
We conduct extensive experiments about both the IMU configuration and technical components to validate the effectiveness of our IMUSIC approach. Notably, IMUSIC enables various potential and novel applications, i.e., privacy-protecting facial capture, hybrid capture against occlusions, or detecting minute facial movements that are often invisible through visual cues. We will release our dataset and implementations to enrich more possibilities of facial capture and analysis in our community.
5.5. EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss

We present EfficientViT-SAM, a new family of accelerated segment anything models. We retain SAM’s lightweight prompt encoder and mask decoder while replacing the heavy image encoder with EfficientViT.
For the training, we begin with the knowledge distillation from the SAM-ViT-H image encoder to EfficientViT. Subsequently, we conduct end-to-end training on the SA-1B dataset. Benefiting from EfficientViT’s efficiency and capacity, EfficientViT-SAM delivers 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing performance.

Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
