


Top Important Computer Vision Papers for the Week from 20/11 to 26/11
Stay Updated with Recent Computer Vision Research

On a weekly basis, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the fourth week of November 2023, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

1. Image Generation
1.1. MetaDreamer: Efficient Text-to-3D Creation With Disentangling Geometry and Texture

Generative models for 3D object synthesis have seen significant advancements with the incorporation of prior knowledge distilled from 2D diffusion models. Nevertheless, challenges persist in the form of multi-view geometric inconsistencies and slow generation speeds within the existing 3D synthesis frameworks.
This can be attributed to two factors: firstly, the deficiency of abundant geometric a priori knowledge in optimization, and secondly, the entanglement issue between geometry and texture in conventional 3D generation methods.
In response, the authors introduce MetaDreammer, a two-stage optimization approach that leverages rich 2D and 3D prior knowledge. In the first stage, the emphasis is on optimizing the geometric representation to ensure multi-view consistency and accuracy of 3D objects. In the second stage, the authors concentrate on fine-tuning the geometry and optimizing the texture, thereby achieving a more refined 3D object. By leveraging 2D and 3D prior knowledge in two stages, respectively, they effectively mitigate the interdependence between geometry and texture.
MetaDreamer establishes clear optimization objectives for each stage, resulting in significant time savings in the 3D generation process. Ultimately, MetaDreamer can generate high-quality 3D objects based on textual prompts within 20 minutes, and to the best of our knowledge, it is the most efficient text-to-3D generation method.
Furthermore, they introduce image control into the process, enhancing the controllability of 3D generation. Extensive empirical evidence confirms that the method is not only highly efficient but also achieves a quality level that is at the forefront of current state-of-the-art 3D generation techniques.
1.2. I&S-ViT: An Inclusive & Stable Method for Pushing the Limit of Post-Training ViTs Quantization

Albeit the scalable performance of vision transformers (ViTs), the dense computational costs (training & inference) undermine their position in industrial applications. Post-training quantization (PTQ), tuning ViTs with a tiny dataset and running in a low-bit format, well addresses the cost issue but unluckily bears more performance drops in lower-bit cases.
In this paper, the authors introduce I&S-ViT, a novel method that regulates the PTQ of ViTs in an inclusive and stable fashion. I&S-ViT first identifies two issues in the PTQ of ViTs:
Quantization inefficiency in the prevalent log2 quantizer for post-Softmax activations.
Rugged and magnified loss landscape in coarse-grained quantization granularity for post-LayerNorm activations.
Then, I&S-ViT addresses these issues by introducing:
A novel shift-uniform-log2 quantizer (SULQ) incorporates a shift mechanism followed by uniform quantization to achieve both an inclusive domain representation and accurate distribution approximation.
A three-stage smooth optimization strategy (SOS) that amalgamates the strengths of channel-wise and layer-wise quantization to enable stable learning.
Comprehensive evaluations across diverse vision tasks validate I&S-ViT’s superiority over existing PTQ of ViT methods, particularly in low-bit scenarios. For instance, I&S-ViT elevates the performance of 3-bit ViT-B by an impressive 50.68%.
1.3. Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression

The authors introduce Style Tailoring, a recipe to finetune Latent Diffusion Models (LDMs) in a distinct domain with high visual quality, prompt alignment, and scene diversity. We choose sticker image generation as the target domain, as the images significantly differ from photorealistic samples typically generated by large-scale LDMs.
The authors start with a competent text-to-image model, like Emu, and show that relying on prompt engineering with a photorealistic model to generate stickers leads to poor prompt alignment and scene diversity. To overcome these drawbacks, they first finetune Emu on millions of sticker-like images collected using weak supervision to elicit diversity. Next, they curate human-in-the-loop (HITL) Alignment and Style datasets from model generations and finetune to improve prompt alignment and style alignment respectively.
Sequential finetuning on these datasets poses a tradeoff between better style alignment and prompt alignment gains. To address this tradeoff, they propose a novel fine-tuning method called Style Tailoring, which jointly fits the content and style distribution and achieves the best tradeoff. Evaluation results show our method improves visual quality by 14%, prompt alignment by 16.2%, and scene diversity by 15.3%, compared to prompt engineering of the base Emu model for stickers generation.
1.4. Diffusion360: Seamless 360-Degree Panoramic Image Generation based on Diffusion Models
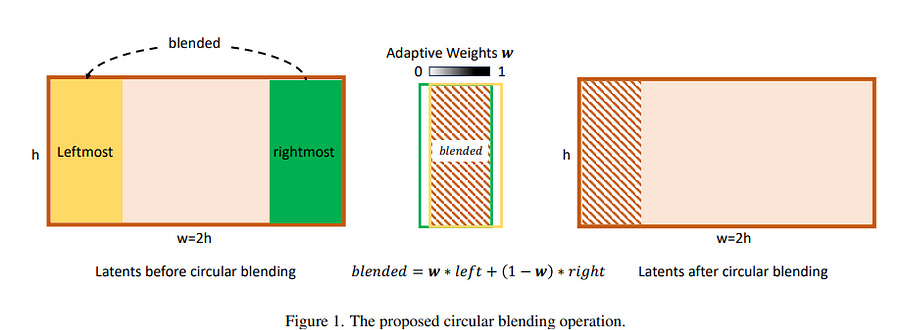
This is a technical report on the 360-degree panoramic image generation task based on diffusion models. Unlike ordinary 2D images, 360-degree panoramic images capture the entire 360^circtimes 180-degree field of view.
So the rightmost and the leftmost sides of the 360 panoramic image should be continued, which is the main challenge in this field. However, the current diffusion pipeline is not appropriate for generating such a seamless 360-degree panoramic image.
To this end, the authors propose a circular blending strategy on both the denoising and VAE decoding stages to maintain the geometry continuity. Based on this, this paper presents two models for Text-to-360-panoramas and Single-Image-to-360-panoramas tasks.
1.5. Using Human Feedback to Fine-tune Diffusion Models without Any Reward Model

Using reinforcement learning with human feedback (RLHF) has shown significant promise in fine-tuning diffusion models. Previous methods start by training a reward model that aligns with human preferences, then leverage RL techniques to fine-tune the underlying models.
However, crafting an efficient reward model demands extensive datasets, optimal architecture, and manual hyperparameter tuning, making the process both time and cost-intensive. The direct preference optimization (DPO) method, effective in fine-tuning large language models, eliminates the necessity for a reward model.
However, the extensive GPU memory requirement of the diffusion model’s denoising process hinders the direct application of the DPO method. To address this issue, this paper introduces the Direct Preference for Denoising Diffusion Policy Optimization (D3PO) method to directly fine-tune diffusion models. The theoretical analysis demonstrates that although D3PO omits training a reward model, it effectively functions as the optimal reward model trained using human feedback data to guide the learning process.
This approach requires no training of a reward model, proving to be more direct, cost-effective, and minimizing computational overhead. In experiments, our method uses the relative scale of objectives as a proxy for human preference, delivering comparable results to methods using ground-truth rewards. Moreover, D3PO demonstrates the ability to reduce image distortion rates and generate safer images, overcoming challenges lacking robust reward models.
1.6. LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes

With the widespread usage of VR devices and content, demands for 3D scene generation techniques become more popular. Existing 3D scene generation models, however, limit the target scene to a specific domain, primarily due to their training strategies using a 3D scan dataset that is far from the real world.
To address such limitation, researchers propose LucidDreamer, a domain-free scene generation pipeline by fully leveraging the power of the existing large-scale diffusion-based generative model. The LucidDreamer has two alternate steps: Dreaming and Alignment. First, to generate multi-view consistent images from inputs, they set the point cloud as a geometrical guideline for each image generation.
Specifically, they project a portion of the point cloud to the desired view and provide the projection as guidance for inpainting using the generative model. The inpainted images are lifted to 3D space with estimated depth maps, composing new points.
Second, to aggregate the new points into the 3D scene, we propose an aligning algorithm that harmoniously integrates the portions of newly generated 3D scenes.
The finally obtained 3D scene serves as initial points for optimizing Gaussian splats. LucidDreamer produces Gaussian splats that are highly detailed compared to the previous 3D scene generation methods, with no constraint on the domain of the target scene.
1.7. Diffusion Model Alignment Using Direct Preference Optimization

Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback (RLHF) methods to make them better aligned with users’ preferences.
In contrast to LLMs, human preference learning has not been widely explored in text-to-image diffusion models; the best existing approach is to fine-tune a pretrained model using carefully curated high-quality images and captions to improve visual appeal and text alignment.
The authors propose diffusion-DPO, a method to align diffusion models to human preferences by directly optimizing human comparison data. Diffusion-DPO is adapted from the recently developed Direct Preference Optimization (DPO), a simpler alternative to RLHF which directly optimizes a policy that best satisfies human preferences under a classification objective.
The authors re-formulate DPO to account for a diffusion model notion of likelihood, utilizing the evidence lower bound to derive a differentiable objective. Using the Pick-a-Pic dataset of 851K crowdsourced pairwise preferences, they fine-tuned the base model of the state-of-the-art Stable Diffusion XL (SDXL)-1.0 model with Diffusion-DPO.
The fine-tuned base model significantly outperforms both base SDXL-1.0 and the larger SDXL-1.0 model consisting of an additional refinement model in human evaluation, improving visual appeal and prompt alignment. We also develop a variant that uses AI feedback and has comparable performance to training on human preferences, opening the door for scaling of diffusion model alignment methods.
1.8. ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs
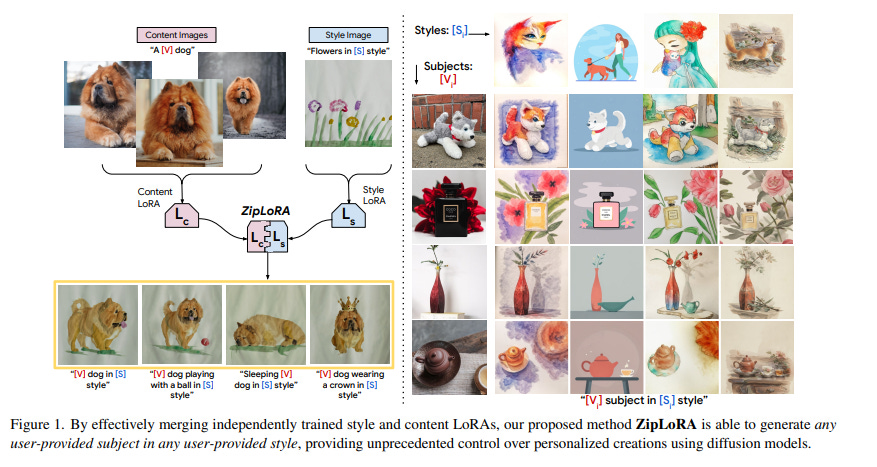
Methods for finetuning generative models for concept-driven personalization generally achieve strong results for subject-driven or style-driven generation. Recently, low-rank adaptations (LoRA) have been proposed as a parameter-efficient way of achieving concept-driven personalization.
While recent work explores the combination of separate LoRAs to achieve a joint generation of learned styles and subjects, existing techniques do not reliably address the problem; they often compromise either subject fidelity or style fidelity.
The authors propose ZipLoRA, a method to cheaply and effectively merge independently trained style and subject LoRAs in order to achieve the generation of any user-provided subject in any user-provided style. Experiments on a wide range of subject and style combinations show that ZipLoRA can generate compelling results with meaningful improvements over baselines in subject and style fidelity while preserving the ability to contextualize.
1.9. AutoStory: Generating Diverse Storytelling Images with Minimal Human Effort

Story visualization aims to generate a series of images that match the story described in texts, and it requires the generated images to satisfy high quality, alignment with the text description, and consistency in character identities.
Given the complexity of story visualization, existing methods drastically simplify the problem by considering only a few specific characters and scenarios, or requiring the users to provide per-image control conditions such as sketches. However, these simplifications render these methods incompetent for real applications.
To this end, the authors propose an automated story visualization system that can effectively generate diverse, high-quality, and consistent sets of story images, with minimal human interactions.
Specifically, they utilize the comprehension and planning capabilities of large language models for layout planning and then leverage large-scale text-to-image models to generate sophisticated story images based on the layout.
The authors empirically find that sparse control conditions, such as bounding boxes, are suitable for layout planning, while dense control conditions, e.g., sketches and key points, are suitable for generating high-quality image content.
To obtain the best of both worlds, we devise a dense condition generation module to transform simple bounding box layouts into sketch or keypoint control conditions for final image generation, which not only improves the image quality but also allows easy and intuitive user interactions. In addition, we propose a simple yet effective method to generate multi-view consistent character images, eliminating the reliance on human labor to collect or draw character images.
1.10. Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models

The authors present a method to create interpretable concept sliders that enable precise control over attributes in image generations from diffusion models. This approach identifies a low-rank parameter direction corresponding to one concept while minimizing interference with other attributes.
A slider is created using a small set of prompts or sample images; thus slider directions can be created for either textual or visual concepts. Concept Sliders are plug-and-play: they can be composed efficiently and continuously modulated, enabling precise control over image generation. In quantitative experiments compared to previous editing techniques, our sliders exhibit stronger targeted edits with lower interference.
The authors showcase sliders for weather, age, styles, and expressions, as well as slider compositions. We show how sliders can transfer latents from StyleGAN for intuitive editing of visual concepts for which textual description is difficult. We also find that our method can help address persistent quality issues in Stable Diffusion XL including repair of object deformations and fixing distorted hands. Our code, data, and trained sliders are available at
1.11. NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation

Despite impressive recent advances in text-to-image diffusion models, obtaining high-quality images often requires prompt engineering by humans who have developed expertise in using them. In this work, we present NeuroPrompts, an adaptive framework that automatically enhances a user’s prompt to improve the quality of generations produced by text-to-image models.
Our framework utilizes constrained text decoding with a pre-trained language model that has been adapted to generate prompts similar to those produced by human prompt engineers. This approach enables higher-quality text-to-image generations and provides user control over stylistic features via constraint set specification. We demonstrate the utility of our framework by creating an interactive application for prompt enhancement and image generation using Stable Diffusion.
Additionally, we conduct experiments utilizing a large dataset of human-engineered prompts for text-to-image generation and show that our approach automatically produces enhanced prompts that result in superior image quality. We make our code, a screencast video demo, and a live demo instance of NeuroPrompts publicly available.
1.12. PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics

We introduce PhysGaussian, a new method that seamlessly integrates physically grounded Newtonian dynamics within 3D Gaussians to achieve high-quality novel motion synthesis. Employing a custom Material Point Method (MPM), our approach enriches 3D Gaussian kernels with physically meaningful kinematic deformation and mechanical stress attributes, all evolved in line with continuum mechanics principles.
A defining characteristic of our method is the seamless integration between physical simulation and visual rendering: both components utilize the same 3D Gaussian kernels as their discrete representations. This negates the necessity for triangle/tetrahedron meshing, marching cubes, “cage meshes,” or any other geometry embedding, highlighting the principle of “what you see is what you simulate (WS²).”
Our method demonstrates exceptional versatility across a wide variety of materials — including elastic entities, metals, non-Newtonian fluids, and granular materials — showcasing its strong capabilities in creating diverse visual content with novel viewpoints and movements.
2. Video Generation
2.1. Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning

We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image.
We identify critical design decisions — adjusted noise schedules for diffusion, and multi-stage training — that enable us to directly generate high-quality and high-resolution videos, without requiring a deep cascade of models as in prior work. In human evaluations, our generated videos are strongly preferred in quality compared to all prior work — 81% vs. Google’s Imagen Video, 90% vs. Nvidia’s PYOCO, and 96% vs. Meta’s Make-A-Video.
Our model outperforms commercial solutions such as RunwayML’s Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user’s text prompt, where our generations are preferred 96% over prior work.
2.2. VideoCon: Robust Video-Language Alignment via Contrast Captions

Despite being (pre)trained on a massive amount of data, state-of-the-art video-language alignment models are not robust to semantically plausible contrastive changes in the video captions. Our work addresses this by identifying a broad spectrum of contrast misalignments, such as replacing entities, actions, and flipping event order, which alignment models should be robust against.
To this end, we introduce VideoCon, a video-language alignment dataset constructed by a large language model that generates plausible contrast video captions and explanations for differences between original and contrast video captions. Then, a generative video-language model is finetuned with VideoCon to assess video-language entailment and generate explanations.
Our VideoCon-based alignment model significantly outperforms current models. It exhibits a 12-point increase in AUC for the video-language alignment task on human-generated contrast captions. Finally, our model sets new state-of-the-art zero-shot performance in temporally-extensive video-language tasks such as text-to-video retrieval (SSv2-Temporal) and video question answering (ATP-Hard). Moreover, our model shows superior performance on novel videos and human-crafted captions and explanations.
2.3. Make Pixels Dance: High-Dynamic Video Generation

Creating high-dynamic videos such as motion-rich actions and sophisticated visual effects poses a significant challenge in the field of artificial intelligence.
Unfortunately, current state-of-the-art video generation methods, primarily focusing on text-to-video generation, tend to produce video clips with minimal motions despite maintaining high fidelity. We argue that relying solely on text instructions is insufficient and suboptimal for video generation.
In this paper, we introduce PixelDance, a novel approach based on diffusion models that incorporates image instructions for both the first and last frames in conjunction with text instructions for video generation. Comprehensive experimental results demonstrate that PixelDance trained with public data exhibits significantly better proficiency in synthesizing videos with complex scenes and intricate motions, setting a new standard for video generation.
2.4. FusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline

Multimedia generation approaches occupy a prominent place in artificial intelligence research. Text-to-image models achieved high-quality results over the last few years. However, video synthesis methods recently started to develop. This paper presents a new two-stage latent diffusion text-to-video generation architecture based on the text-to-image diffusion model.
The first stage concerns keyframe synthesis to figure out the storyline of a video, while the second one is devoted to interpolation frame generation to make movements of the scene and objects smooth. We compare several temporal conditioning approaches for keyframes generation. The results show the advantage of using separate temporal blocks over temporal layers in terms of metrics reflecting video generation quality aspects and human preference.
The design of our interpolation model significantly reduces computational costs compared to other masked frame interpolation approaches. Furthermore, we evaluate different configurations of MoVQ-based video decoding schemes to improve consistency and achieve higher PSNR, SSIM, MSE, and LPIPS scores.
Finally, we compare our pipeline with existing solutions and achieve top-2 scores overall and top-1 among open-source solutions: CLIPSIM = 0.2976 and FVD = 433.054.
2.5. GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning

Recent advances in text-to-video generation have harnessed the power of diffusion models to create visually compelling content conditioned on text prompts. However, they usually encounter high computational costs and often struggle to produce videos with coherent physical motions.
To tackle these issues, we propose GPT4Motion, a training-free framework that leverages the planning capability of large language models such as GPT, the physical simulation strength of Blender, and the excellent image generation ability of text-to-image diffusion models to enhance the quality of video synthesis.
Specifically, GPT4Motion employs GPT-4 to generate a Blender script based on a user textual prompt, which commands Blender’s built-in physics engine to craft fundamental scene components that encapsulate coherent physical motions across frames. Then these components are inputted into Stable Diffusion to generate a video aligned with the textual prompt.
Experimental results on three basic physical motion scenarios, including rigid object drop and collision, cloth draping and swinging, and liquid flow, demonstrate that GPT4Motion can generate high-quality videos efficiently in maintaining motion coherency and entity consistency. GPT4Motion offers new insights into text-to-video research, enhancing its quality and broadening its horizon for future explorations.
2.6. MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer

In this work, we propose MagicDance, a diffusion-based model for 2D human motion and facial expression transfer on challenging human dance videos. Specifically, we aim to generate human dance videos of any target identity driven by novel pose sequences while keeping the identity unchanged.
To this end, we propose a two-stage training strategy to disentangle human motions and appearance (e.g., facial expressions, skin tone, and dressing), consisting of the pretraining of an appearance-control block and fine-tuning of an appearance-pose-joint-control block over human dance poses of the same dataset.
Our novel design enables robust appearance control with temporally consistent upper body, facial attributes, and even background. The model also generalizes well on unseen human identities and complex motion sequences without the need for any fine-tuning with additional data with diverse human attributes by leveraging the prior knowledge of image diffusion models.
Moreover, the proposed model is easy to use and can be considered as a plug-in module/extension to Stable Diffusion. We also demonstrate the model’s ability for zero-shot 2D animation generation, enabling not only the appearance transfer from one identity to another but also allowing for cartoon-like stylization given only pose inputs. Extensive experiments demonstrate our superior performance on the TikTok dataset.
3. Video Understanding
3.1. Video-LLaVA: Learning United Visual Representation by Alignment Before Projection

The Large Vision-Language Model (LVLM) has enhanced the performance of various downstream tasks in visual-language understanding. Most existing approaches encode images and videos into separate feature spaces, which are then fed as inputs to large language models.
However, due to the lack of unified tokenization for images and videos, namely misalignment before projection, it becomes challenging for a Large Language Model (LLM) to learn multi-modal interactions from several poor projection layers. In this work, we unify visual representation into the language feature space to advance the foundational LLM towards a unified LVLM.
As a result, we establish a simple but robust LVLM baseline, Video-LLaVA, which learns from a mixed dataset of images and videos, mutually enhancing each other. Video-LLaVA achieves superior performances on a broad range of 9 image benchmarks across 5 image question-answering datasets and 4 image benchmark toolkits.
Additionally, our Video-LLaVA also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively. Notably, extensive experiments demonstrate that Video-LLaVA mutually benefits images and videos within a unified visual representation, outperforming models designed specifically for images or videos.
3.2. PG-Video-LLaVA: Pixel Grounding Large Video-Language Models

Extending image-based Large Multimodal Models (LMM) to videos is challenging due to the inherent complexity of video data. The recent approaches extending image-based LMM to videos either lack the grounding capabilities (e.g., VideoChat, Video-ChatGPT, Video-LLaMA) or do not utilize the audio signals for better video understanding (e.g., Video-ChatGPT).
Addressing these gaps, we propose Video-LLaVA, the first LMM with pixel-level grounding capability, integrating audio cues by transcribing them into text to enrich video-context understanding.
Our framework uses an off-the-shelf tracker and a novel grounding module, enabling it to spatially and temporally localize objects in videos following user instructions. We evaluate Video-LLaVA using video-based generative and question-answering benchmarks and introduce new benchmarks specifically designed to measure prompt-based object grounding performance in videos.
Further, we propose the use of Vicuna over GPT-3.5, as utilized in Video-ChatGPT, for video-based conversation benchmarking, ensuring reproducibility of results which is a concern with the proprietary nature of GPT-3.5. Our framework builds on the SoTA image-based LLaVA model and extends its advantages to the video domain, delivering promising gains on video-based conversation and grounding tasks.
4. Vision Language Models
4.1. UnifiedVisionGPT: Streamlining Vision-Oriented AI through Generalized Multimodal Framework
In the current landscape of artificial intelligence, foundation models serve as the bedrock for advancements in both language and vision domains. OpenAI GPT-4 has emerged as the pinnacle in large language models (LLMs), while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models such as Meta’s SAM and DINO, and YOLOS.
However, the financial and computational burdens of training new models from scratch remain a significant barrier to progress. In response to this challenge, we introduce UnifiedVisionGPT, a novel framework designed to consolidate and automate the integration of SOTA vision models, thereby facilitating the development of vision-oriented AI. UnifiedVisionGPT distinguishes itself through four key features:
Provides a versatile multimodal framework adaptable to a wide range of applications, building upon the strengths of multimodal foundation models.
Seamlessly integrates various SOTA vision models to create a comprehensive multimodal platform, capitalizing on the best components of each model.
Prioritizes vision-oriented AI, ensuring a more rapid progression in the CV domain compared to the current trajectory of LLMs
Introduces automation in the selection of SOTA vision models, generating optimal results based on diverse multimodal inputs such as text prompts and images.
This paper outlines the architecture and capabilities of UnifiedVisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, generalization, and performance.
4.2. Visual In-Context Prompting

In-context prompting in large language models (LLMs) has become a prevalent approach to improve zero-shot capabilities, but this idea is less explored in the vision domain. Existing visual prompting methods focus on referring to segmentation to segment the most relevant object, falling short of addressing many generic vision tasks like open-set segmentation and detection.
In this paper, we introduce a universal visual in-context prompting framework for both tasks. In particular, we build on top of an encoder-decoder architecture and develop a versatile prompt encoder to support a variety of prompts like strokes, boxes, and points. We further enhance it to take an arbitrary number of reference image segments as the context.
Our extensive explorations show that the proposed visual in-context prompting elicits extraordinary referring and generic segmentation capabilities to refer and detect, yielding competitive performance to close-set in-domain datasets and showing promising results on many open-set segmentation datasets. By joint training on COCO and SA-1B, our model achieves 57.7 PQ on COCO and 23.2 PQ on ADE20K.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Thanks for sharing