


Top Important Computer Vision Papers for the Week from 22/04 to 28/04
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of April 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. Align Your Steps: Optimizing Sampling Schedules in Diffusion Models

Diffusion models (DMs) have established themselves as the state-of-the-art generative modeling approach in the visual domain and beyond. A crucial drawback of DMs is their slow sampling speed, relying on many sequential function evaluations through large neural networks.
Sampling from DMs can solve a differential equation through a discretized set of noise levels known as the sampling schedule. While past works primarily focused on deriving efficient solvers, little attention has been given to finding optimal sampling schedules, and the entire literature relies on hand-crafted heuristics. In this work, for the first time, we propose a general and principled approach to optimizing the sampling schedules of DMs for high-quality outputs, called Align Your Steps.
We leverage methods from stochastic calculus and find optimal schedules specific to different solvers, trained DMs, and datasets. We evaluate our novel approach on several images, video, and 2D toy data synthesis benchmarks, using various samplers.
We observe that our optimized schedules outperform previous hand-crafted schedules in almost all experiments. Our method demonstrates the untapped potential of sampling schedule optimization, especially in the few-step synthesis regime.
2. Vision Language Models (VLMs)
2.1. TextSquare: Scaling up Text-Centric Visual Instruction Tuning
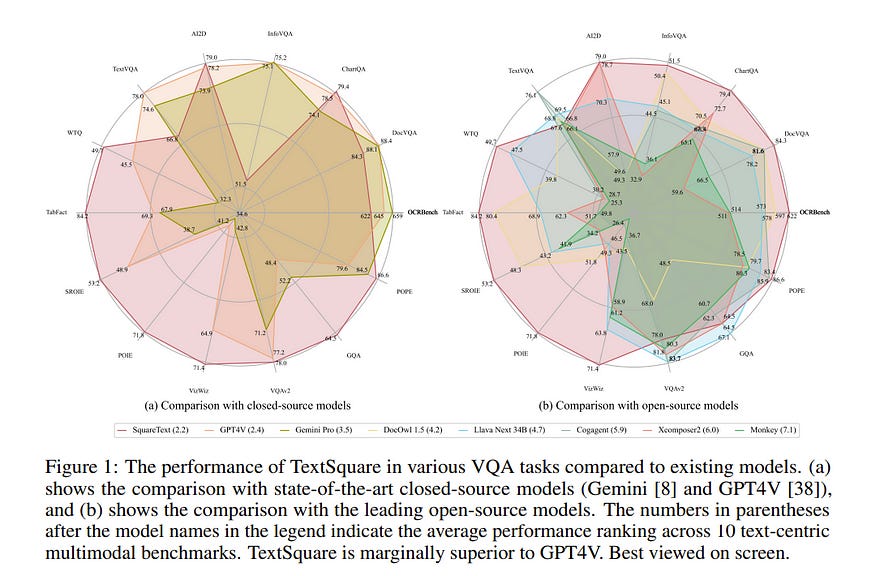
Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data.
To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation.
Our experiments with Square-10M led to three key findings:
Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks.
Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations.
Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.
2.2. PuLID: Pure and Lightning ID Customization via Contrastive Alignment

We propose Pure and Lightning ID customization (PuLID), a novel tuning-free ID customization method for text-to-image generation. By incorporating a Lightning T2I branch with a standard diffusion one, PuLID introduces both contrastive alignment loss and accurate ID loss, minimizing disruption to the original model and ensuring high ID fidelity.
Experiments show that PuLID achieves superior performance in both ID fidelity and editability. Another attractive property of PuLID is that the image elements (e.g., background, lighting, composition, and style) before and after the ID insertion are kept as consistent as possible.
3. Image Generation & Editing
3.1. Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis

Recently, a series of diffusion-aware distillation algorithms have emerged to alleviate the computational overhead associated with the multi-step inference process of Diffusion Models (DMs).
Current distillation techniques often dichotomize into two distinct aspects: i) ODE Trajectory Preservation; and ii) ODE Trajectory Reformulation. However, these approaches suffer from severe performance degradation or domain shifts.
To address these limitations, we propose Hyper-SD, a novel framework that synergistically amalgamates the advantages of ODE Trajectory Preservation and Reformulation, while maintaining near-lossless performance during step compression.
Firstly, we introduce Trajectory Segmented Consistency Distillation to progressively perform consistent distillation within pre-defined time-step segments, which facilitates the preservation of the original ODE trajectory from a higher-order perspective.
Secondly, we incorporate human feedback learning to boost the performance of the model in a low-step regime and mitigate the performance loss incurred by the distillation process.
Thirdly, we integrate score distillation to further improve the low-step generation capability of the model and offer the first attempt to leverage a unified LoRA to support the inference process at all steps. Extensive experiments and user studies demonstrate that Hyper-SD achieves SOTA performance from 1 to 8 inference steps for both SDXL and SD1.5. For example, Hyper-SDXL surpasses SDXL-Lightning by +0.68 in CLIP Score and +0.51 in Aes Score in the 1-step inference.
3.2. CatLIP: CLIP-level Visual Recognition Accuracy with 2.7x Faster Pre-training on Web-scale Image-Text Data

Contrastive learning has emerged as a transformative method for learning effective visual representations through the alignment of image and text embeddings. However, pairwise similarity computation in contrastive loss between image and text pairs poses computational challenges.
This paper presents a novel weakly supervised pre-training of vision models on web-scale image-text data. The proposed method reframes pre-training on image-text data as a classification task.
Consequently, it eliminates the need for pairwise similarity computations in contrastive loss, achieving a remarkable 2.7 times acceleration in training speed compared to contrastive learning on web-scale data.
Through extensive experiments spanning diverse vision tasks, including detection and segmentation, we demonstrate that the proposed method maintains high representation quality.
3.3. Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings

While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgments, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings — and thereby the prompt set used to compare models — is not evaluated.
We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates.
This skills-based benchmark categorizes prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations.
This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
3.4. Editable Image Elements for Controllable Synthesis

Diffusion models have made significant advances in text-guided synthesis tasks. However, editing user-provided images remains challenging, as the high dimensional noise input space of diffusion models is not naturally suited for image inversion or spatial editing.
In this work, we propose an image representation that promotes spatial editing of input images using a diffusion model. Concretely, we learn to encode an input into “image elements” that can faithfully reconstruct an input image.
These elements can be intuitively edited by a user, and are decoded by a diffusion model into realistic images. We show the effectiveness of our representation on various image editing tasks, such as object resizing, rearrangement, dragging, de-occlusion, removal, variation, and image composition.
3.5. Interactive3D: Create What You Want by Interactive 3D Generation

3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability.
User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images.
Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations.
The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation.
3.6. ID-Aligner: Enhancing Identity-Preserving Text-to-Image Generation with Reward Feedback Learning

The rapid development of diffusion models has triggered diverse applications. Identity-preserving text-to-image generation (ID-T2I) particularly has received significant attention due to its wide range of application scenarios like AI portrait and advertising.
While existing ID-T2I methods have demonstrated impressive results, several key challenges remain:
It is hard to maintain the identity characteristics of reference portraits accurately
The generated images lack aesthetic appeal especially while enforcing identity retention
There is a limitation that cannot be compatible with LoRA-based and Adapter-based methods simultaneously.
To address these issues, we present ID-Aligner, a general feedback learning framework to enhance ID-T2I performance. To resolve identity features lost, we introduce identity consistency reward fine-tuning to utilize the feedback from face detection and recognition models to improve generated identity preservation.
Furthermore, we propose identity aesthetic reward fine-tuning leveraging rewards from human-annotated preference data and automatically constructed feedback on character structure generation to provide aesthetic tuning signals.
Thanks to its universal feedback fine-tuning framework, our method can be readily applied to both LoRA and Adapter models, achieving consistent performance gains. Extensive experiments on SD1.5 and SDXL diffusion models validate the effectiveness of our approach.
3.7. ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving

Diffusion-based technologies have made significant strides, particularly in personalized and customized facial generation. However, existing methods face challenges in achieving high-fidelity and detailed identity (ID)consistency, primarily due to insufficient fine-grained control over facial areas and the lack of a comprehensive strategy for ID preservation by fully considering intricate facial details and the overall face.
To address these limitations, we introduce ConsistentID, an innovative method crafted for diverse identity-preserving portrait generation under fine-grained multimodal facial prompts, utilizing only a single reference image.
ConsistentID comprises two key components: a multimodal facial prompt generator that combines facial features, corresponding facial descriptions, and the overall facial context to enhance precision in facial details, and an ID-preservation network optimized through the facial attention localization strategy, aimed at preserving ID consistency in facial regions.
Together, these components significantly enhance the accuracy of ID preservation by introducing fine-grained multimodal ID information from facial regions. To facilitate training of ConsistentID, we present a fine-grained portrait dataset, FGID, with over 500,000 facial images, offering greater diversity and comprehensiveness than existing public facial datasets. % such as LAION-Face, CelebA, FFHQ, and SFHQ.
Experimental results substantiate that our ConsistentID achieves exceptional precision and diversity in personalized facial generation, surpassing existing methods in the MyStyle dataset. Furthermore, while ConsistentID introduces more multimodal ID information, it maintains a fast inference speed during generation.
4. Video Understanding & Generation
4.1. PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation

Realistic object interactions are crucial for creating immersive virtual experiences, yet synthesizing realistic 3D object dynamics in response to novel interactions remains a significant challenge.
Unlike unconditional or text-conditioned dynamics generation, action-conditioned dynamics requires perceiving the physical material properties of objects and grounding the 3D motion prediction on these properties, such as object stiffness. However, estimating physical material properties is an open problem due to the lack of material ground-truth data, as measuring these properties for real objects is highly difficult.
We present PhysDreamer, a physics-based approach that endows static 3D objects with interactive dynamics by leveraging the object dynamics priors learned by video generation models. By distilling these priors, PhysDreamer enables the synthesis of realistic object responses to novel interactions, such as external forces or agent manipulations.
We demonstrate our approach to diverse examples of elastic objects and evaluate the realism of the synthesized interactions through a user study. PhysDreamer takes a step towards more engaging and realistic virtual experiences by enabling static 3D objects to dynamically respond to interactive stimuli in a physically plausible manner. See our project page at
https://physdreamer.github.io/.
4.2. MotionMaster: Training-free Camera Motion Transfer For Video Generation

The emergence of diffusion models has greatly propelled the progress in image and video generation. Recently, some efforts have been made in controllable video generation, including text-to-video generation and video motion control, among which camera motion control is an important topic.
However, existing camera motion control methods rely on training a temporal camera module, and necessitate substantial computation resources due to the large amount of parameters in video generation models. Moreover, existing methods pre-define camera motion types during training, which limits their flexibility in camera control.
Therefore, to reduce training costs and achieve flexible camera control, we propose COMD, a novel training-free video motion transfer model, which disentangles camera motions and object motions in source videos and transfers the extracted camera motions to new videos. We first propose a one-shot camera motion disentanglement method to extract camera motion from a single source video, which separates the moving objects from the background and estimates the camera motion in the moving objects region based on the motion in the background by solving a Poisson equation.
Furthermore, we propose a few-shot camera motion disentanglement method to extract the common camera motion from multiple videos with similar camera motions, which employs a window-based clustering technique to extract the common features in temporal attention maps of multiple videos.
Finally, we propose a motion combination method to combine different types of camera motions together, enabling our model a more controllable and flexible camera control. Extensive experiments demonstrate that our training-free approach can effectively decouple camera-object motion and apply the decoupled camera motion to a wide range of controllable video generation tasks, achieving flexible and diverse camera motion control.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
