


Top Important Computer Vision Papers for the Week from 13/11 to 19/11
Stay Relevant to Recent Computer Vision Research

On a weekly basis, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Second week of November 2023, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Image & Video Generation
Vision Language Models
Image & Video Understanding
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. Image Generation
1.1. MetaDreamer: Efficient Text-to-3D Creation With Disentangling Geometry and Texture

Generative models for 3D object synthesis have seen significant advancements with the incorporation of prior knowledge distilled from 2D diffusion models. Nevertheless, challenges persist in the form of multi-view geometric inconsistencies and slow generation speeds within the existing 3D synthesis frameworks.
This can be attributed to two factors: firstly, the deficiency of abundant geometric a priori knowledge in optimization, and secondly, the entanglement issue between geometry and texture in conventional 3D generation methods.
In response, we introduce MetaDreammer, a two-stage optimization approach that leverages rich 2D and 3D prior knowledge. In the first stage, our emphasis is on optimizing the geometric representation to ensure multi-view consistency and accuracy of 3D objects. In the second stage, we concentrate on fine-tuning the geometry and optimizing the texture, thereby achieving a more refined 3D object.
Through leveraging 2D and 3D prior knowledge in two stages, respectively, we effectively mitigate the interdependence between geometry and texture. MetaDreamer establishes clear optimization objectives for each stage, resulting in significant time savings in the 3D generation process. Ultimately, MetaDreamer can generate high-quality 3D objects based on textual prompts within 20 minutes, and to the best of our knowledge, it is the most efficient text-to-3D generation method.
Furthermore, we introduce image control into the process, enhancing the controllability of 3D generation. Extensive empirical evidence confirms that our method is not only highly efficient but also achieves a quality level that is at the forefront of current state-of-the-art 3D generation techniques.
1.2. Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning

We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical design decisions — adjusted noise schedules for diffusion, and multi-stage training — that enable us to directly generate high-quality and high-resolution videos, without requiring a deep cascade of models as in prior work.
In human evaluations, our generated videos are strongly preferred in quality compared to all prior work — 81% vs. Google’s Imagen Video, 90% vs. Nvidia’s PYOCO, and 96% vs. Meta’s Make-A-Video. Our model outperforms commercial solutions such as RunwayML’s Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user’s text prompt, where our generations are preferred 96% over prior work.
1.3. The Chosen One: Consistent Characters in Text-to-Image Diffusion Models

Recent advances in text-to-image generation models have unlocked vast potential for visual creativity. However, these models struggle with the generation of consistent characters, a crucial aspect for numerous real-world applications such as story visualization, game development asset design, advertising, and more.
Current methods typically rely on multiple pre-existing images of the target character or involve labor-intensive manual processes. In this work, we propose a fully automated solution for consistent character generation, with the sole input being a text prompt.
We introduce an iterative procedure that, at each stage, identifies a coherent set of images sharing a similar identity and extracts a more consistent identity from this set. Our quantitative analysis demonstrates that our method strikes a better balance between prompt alignment and identity consistency compared to the baseline methods, and these findings are reinforced by a user study. To conclude, we showcase several practical applications of our approach.
1.4. UFOGen: You Forward Once Large-Scale Text-to-Image Generation via Diffusion GANs

Text-to-image diffusion models have demonstrated remarkable capabilities in transforming textual prompts into coherent images, yet the computational cost of their inference remains a persistent challenge. To address this issue, we present UFOGen, a novel generative model designed for ultra-fast, one-step text-to-image synthesis.
In contrast to conventional approaches that focus on improving samplers or employing distillation techniques for diffusion models, UFOGen adopts a hybrid methodology, integrating diffusion models with a GAN objective. Leveraging a newly introduced diffusion-GAN objective and initialization with pre-trained diffusion models, UFOGen excels in efficiently generating high-quality images conditioned on textual descriptions in a single step. Beyond traditional text-to-image generation, UFOGen showcases versatility in applications.
Notably, UFOGen stands among the pioneering models enabling one-step text-to-image generation and diverse downstream tasks, presenting a significant advancement in the landscape of efficient generative models.
1.5. Drivable 3D Gaussian Avatars

We present Drivable 3D Gaussian Avatars (D3GA), the first 3D controllable model for human bodies rendered with Gaussian splats. Current photorealistic drivable avatars require either accurate 3D registrations during training, dense input images during testing, or both. The ones based on neural radiance fields also tend to be prohibitively slow for telepresence applications.
This work uses the recently presented 3D Gaussian Splatting (3DGS) technique to render realistic humans at real-time framerates, using dense calibrated multi-view videos as input. To deform those primitives, we depart from the commonly used point deformation method of linear blend skinning (LBS) and use a classic volumetric deformation method: cage deformations. Given their smaller size, we drive these deformations with joint angles and key points, which are more suitable for communication applications.
Our experiments on nine subjects with varied body shapes, clothes, and motions obtain higher-quality results than state-of-the-art methods when using the same training and test data.
1.6. DMV3D: Denoising Multi-View Diffusion using 3D Large Reconstruction Model

We propose DMV3D, a novel 3D generation approach that uses a transformer-based 3D large reconstruction model to denoise multi-view diffusion. Our reconstruction model incorporates a triplane NeRF representation and can denoise noisy multi-view images via NeRF reconstruction and rendering, achieving single-stage 3D generation in sim30s on a single A100 GPU.
We train DMV3D on large-scale multi-view image datasets of highly diverse objects using only image reconstruction losses, without accessing 3D assets. We demonstrate state-of-the-art results for the single-image reconstruction problem where probabilistic modeling of unseen object parts is required for generating diverse reconstructions with sharp textures. We also show high-quality text-to-3D generation results outperforming previous 3D diffusion models.
1.7. Story-to-Motion: Synthesizing Infinite and Controllable Character Animation from Long Text

Generating natural human motion from a story has the potential to transform the landscape of animation, gaming, and film industries. A new and challenging task, Story-to-Motion, arises when characters are required to move to various locations and perform specific motions based on a long text description.
This task demands a fusion of low-level control (trajectories) and high-level control (motion semantics). Previous works in character control and text-to-motion have addressed related aspects, yet a comprehensive solution remains elusive: character control methods do not handle text description, whereas text-to-motion methods lack position constraints and often produce unstable motions. In light of these limitations, we propose a novel system that generates controllable, infinitely long motions and trajectories aligned with the input text.
We leverage contemporary Large Language Models to act as a text-driven motion scheduler to extract a series of (text, position, duration) pairs from long text.
We develop a text-driven motion retrieval scheme that incorporates motion matching with motion semantic and trajectory constraints.
We design a progressive mask transformer that addresses common artifacts in the transition motion such as unnatural pose and foot sliding.
Beyond its pioneering role as the first comprehensive solution for Story-to-Motion, our system undergoes evaluation across three distinct sub-tasks: trajectory following, temporal action composition, and motion blending, where it outperforms previous state-of-the-art motion synthesis methods across the board.
1.8. Instant3D: Instant Text-to-3D Generation

Text-to-3D generation, which aims to synthesize vivid 3D objects from text prompts, has attracted much attention from the computer vision community. While several existing works have achieved impressive results for this task, they mainly rely on a time-consuming optimization paradigm. Specifically, these methods optimize a neural field from scratch for each text prompt, taking approximately one hour or more to generate one object.
This heavy and repetitive training cost impedes their practical deployment. In this paper, we propose a novel framework for fast text-to-3D generation, dubbed Instant3D. Once trained, Instant3D is able to create a 3D object for an unseen text prompt in less than one second with a single run of a feedforward network. We achieve this remarkable speed by devising a new network that directly constructs a 3D triplane from a text prompt. The core innovation of our Instant3D lies in our exploration of strategies to effectively inject text conditions into the network.
Furthermore, we propose a simple yet effective activation function, the scaled-sigmoid, to replace the original sigmoid function, which speeds up the training convergence by more than ten times. Finally, to address the Janus (multi-head) problem in 3D generation, we propose an adaptive Perp-Neg algorithm that can dynamically adjust its concept negation scales according to the severity of the Janus problem during training, effectively reducing the multi-head effect.
Extensive experiments on a wide variety of benchmark datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods both qualitatively and quantitatively while achieving significantly better efficiency.
1.9. Single-Image 3D Human Digitization with Shape-Guided Diffusion

We present an approach to generate a 360-degree view of a person with a consistent, high-resolution appearance from a single input image. NeRF and its variants typically require videos or images from different viewpoints. Most existing approaches taking monocular input either rely on ground-truth 3D scans for supervision or lack 3D consistency.
While recent 3D generative models show promise of 3D consistent human digitization, these approaches do not generalize well to diverse clothing appearances, and the results lack photorealism. Unlike existing work, we utilize high-capacity 2D diffusion models pretrained for general image synthesis tasks as an appearance prior to clothed humans.
To achieve better 3D consistency while retaining the input identity, we progressively synthesize multiple views of the human in the input image by inpainting missing regions with shape-guided diffusion conditioned on silhouette and surface normal. We then fuse these synthesized multi-view images via inverse rendering to obtain a fully textured high-resolution 3D mesh of the given person.
Experiments show that our approach outperforms prior methods and achieves a photorealistic 360-degree synthesis of a wide range of clothed humans with complex textures from a single image.
1.10. Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model

Text-to-3D with diffusion models has achieved remarkable progress in recent years. However, existing methods either rely on score distillation-based optimization which suffers from slow inference, low diversity, and Janus problems, or are feed-forward methods that generate low-quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that generates high-quality and diverse 3D assets from text prompts in a feed-forward manner.
We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a novel transformer-based sparse-view reconstruction.
Through extensive experiments, we demonstrate that our method can generate high-quality, diverse, and Janus-free 3D assets within 20 seconds, which is two orders of magnitude faster than previous optimization-based methods that can take 1 to 10 hours.
1.11. One-2–3–45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion

Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images — two features essential for practical applications.
In this paper, we present One-2–3–45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data.
This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image.
1.12. Adaptive Shells for Efficient Neural Radiance Field Rendering

Neural radiance fields achieve unprecedented quality for novel view synthesis, but their volumetric formulation remains expensive, requiring a huge number of samples to render high-resolution images. Volumetric encodings are essential to represent fuzzy geometry such as foliage and hair, and they are well-suited for stochastic optimization. Yet, many scenes ultimately consist largely of solid surfaces that can be accurately rendered by a single sample per pixel.
Based on this insight, we propose a neural radiance formulation that smoothly transitions between volumetric- and surface-based rendering, greatly accelerating rendering speed and even improving visual fidelity. Our method constructs an explicit mesh envelope that spatially bounds a neural volumetric representation. In solid regions, the envelope nearly converges to a surface and can often be rendered with a single sample.
To this end, we generalize the NeuS formulation with a learned spatially-varying kernel size which encodes the spread of the density, fitting a wide kernel to volume-like regions and a tight kernel to surface-like regions. We then extract an explicit mesh of a narrow band around the surface, with a width determined by the kernel size, and fine-tune the radiance field within this band.
At inference time, we cast rays against the mesh and evaluate the radiance field only within the enclosed region, greatly reducing the number of samples required. Experiments show that our approach enables efficient rendering at very high fidelity. We also demonstrate that the extracted envelope enables downstream applications such as animation and simulation.
2. Vision Language Models
2.1. UnifiedVisionGPT: Streamlining Vision-Oriented AI through Generalized Multimodal Framework

In the current landscape of artificial intelligence, foundation models serve as the bedrock for advancements in both language and vision domains. OpenAI GPT-4 has emerged as the pinnacle in large language models (LLMs), while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models such as Meta’s SAM and DINO, and YOLOS.
However, the financial and computational burdens of training new models from scratch remain a significant barrier to progress. In response to this challenge, we introduce UnifiedVisionGPT, a novel framework designed to consolidate and automate the integration of SOTA vision models, thereby facilitating the development of vision-oriented AI.
UnifiedVisionGPT distinguishes itself through four key features:
Provides a versatile multimodal framework adaptable to a wide range of applications, building upon the strengths of multimodal foundation models.
Seamlessly integrates various SOTA vision models to create a comprehensive multimodal platform, capitalizing on the best components of each model.
Prioritizes vision-oriented AI, ensuring a more rapid progression in the CV domain compared to the current trajectory of LLMs.
Introduces automation in the selection of SOTA vision models, generating optimal results based on diverse multimodal inputs such as text prompts and images.
This paper outlines the architecture and capabilities of UnifiedVisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, generalization, and performance.
2.2. FinGPT: Large Generative Models for a Small Language
Large language models (LLMs) excel in many tasks in NLP and beyond, but most open models have very limited coverage of smaller languages and LLM work tends to focus on languages where nearly unlimited data is available for pretraining. In this work, we study the challenges of creating LLMs for Finnish, a language spoken by less than 0.1% of the world population.
We compile an extensive dataset of Finnish combining web crawls, news, social media, and eBooks. We pursue two approaches to pre-train models:
We train seven monolingual models from scratch (186M to 13B parameters) dubbed FinGPT.
We continue the pretraining of the multilingual BLOOM model on a mix of its original training data and Finnish, resulting in a 176 billion parameter model we call BLUUMI.
For model evaluation, we introduce FIN-bench, a version of BIG-bench with Finnish tasks. We also assess other model qualities such as toxicity and bias.
2.3. To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning

Existing visual instruction tuning methods typically prompt large language models with textual descriptions to generate instruction-following data. Despite the promising performance achieved, these descriptions are derived from image annotations, which are oftentimes coarse-grained. Furthermore, the instructions might even contradict the visual content without observing the entire visual context.
To address this challenge, we introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains 220K visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. Through experimental validation and case studies, we demonstrate that high-quality visual instructional data could improve the performance of LLaVA-1.5, a state-of-the-art large multimodal model, across a wide spectrum of benchmarks by clear margins.
Notably, by simply replacing the LLaVA-Instruct with our LVIS-Instruct4V, we achieve better results than LLaVA on most challenging LMM benchmarks, e.g., LLaVA^w (76.7 vs. 70.7) and MM-Vet (40.2 vs. 35.4).
2.4. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks

We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. While existing large vision models excel in transfer learning, they struggle to perform a diversity of tasks with simple instructions, a capability that implies handling the complexity of various spatial hierarchies and semantic granularity.
Florence-2 was designed to take text prompts as task instructions and generate desirable results in text forms, whether it be captioning, object detection, grounding, or segmentation. This multi-task learning setup demands large-scale, high-quality annotated data. To this end, we co-developed FLD-5B which consists of 5.4 billion comprehensive visual annotations on 126 million images, using an iterative strategy of automated image annotation and model refinement.
We adopted a sequence-to-sequence structure to train Florence-2 to perform versatile and comprehensive vision tasks. Extensive evaluations on numerous tasks demonstrated Florence-2 to be a strong vision foundation model contender with unprecedented zero-shot and fine-tuning capabilities.
3. Image & Video Understanding
3.1. VideoCon: Robust Video-Language Alignment via Contrast Captions

Despite being (pre)trained on a massive amount of data, state-of-the-art video-language alignment models are not robust to semantically plausible contrastive changes in the video captions. Our work addresses this by identifying a broad spectrum of contrast misalignments, such as replacing entities, actions, and flipping event order, which alignment models should be robust against.
To this end, we introduce VideoCon, a video-language alignment dataset constructed by a large language model that generates plausible contrast video captions and explanations for differences between original and contrast video captions.
Then, a generative video-language model is finetuned with VideoCon to assess video-language entailment and generate explanations. Our VideoCon-based alignment model significantly outperforms current models. It exhibits a 12-point increase in AUC for the video-language alignment task on human-generated contrast captions.
Finally, our model sets new state-of-the-art zero-shot performance in temporally-extensive video-language tasks such as text-to-video retrieval (SSv2-Temporal) and video question answering (ATP-Hard). Moreover, our model shows superior performance on novel videos and human-crafted captions and explanations.
3.2. Video-LLaVA: Learning United Visual Representation by Alignment Before Projection

The Large Vision-Language Model (LVLM) has enhanced the performance of various downstream tasks in visual-language understanding. Most existing approaches encode images and videos into separate feature spaces, which are then fed as inputs to large language models. However, due to the lack of unified tokenization for images and videos, namely misalignment before projection, it becomes challenging for a Large Language Model (LLM) to learn multi-modal interactions from several poor projection layers.
In this work, we unify visual representation into the language feature space to advance the foundational LLM towards a unified LVLM. As a result, we establish a simple but robust LVLM baseline, Video-LLaVA, which learns from a mixed dataset of images and videos, mutually enhancing each other. Video-LLaVA achieves superior performances on a broad range of 9 image benchmarks across 5 image question-answering datasets and 4 image benchmark toolkits.
Additionally, our Video-LLaVA also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively. Notably, extensive experiments demonstrate that Video-LLaVA mutually benefits images and videos within a unified visual representation, outperforming models designed specifically for images or videos.
3.3. Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
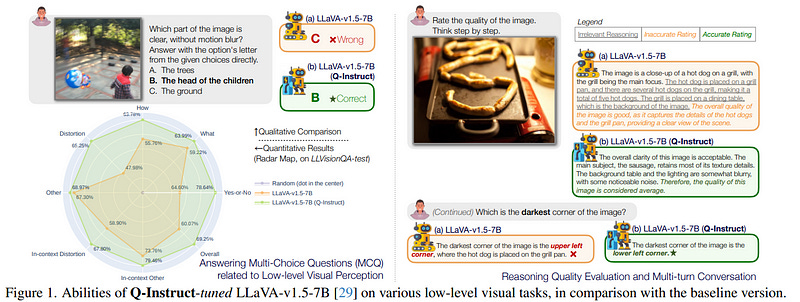
Multi-modality foundation models, as represented by GPT-4V, have brought a new paradigm for low-level visual perception and understanding tasks, that can respond to a broad range of natural human instructions in a model.
While existing foundation models have shown exciting potential on low-level visual tasks, their related abilities are still preliminary and need to be improved. In order to enhance these models, we conduct a large-scale subjective experiment collecting a vast number of real human feedbacks on low-level vision.
Each feedback follows a pathway that starts with a detailed description of the low-level visual appearance (*e.g. clarity, color, brightness* of an image, and ends with an overall conclusion, with an average length of 45 words. The constructed **Q-Pathway** dataset includes 58K detailed human feedback on 18,973 images with diverse low-level appearances.
Moreover, to enable foundation models to robustly respond to diverse types of questions, we design a GPT-participated conversion to process these feedbacks into diverse-format 200K instruction-response pairs. Experimental results indicate that the **Q-Instruct** consistently elevates low-level perception and understanding abilities across several foundational models.
We anticipate that our datasets can pave the way for a future in which general intelligence can perceive, and understand low-level visual appearance, and evaluate visual quality like a human.
3.4. I&S-ViT: An Inclusive & Stable Method for Pushing the Limit of Post-Training ViTs Quantization
Albeit the scalable performance of vision transformers (ViTs), the dense computational costs (training & inference) undermine their position in industrial applications. Post-training quantization (PTQ), tuning ViTs with a tiny dataset and running in a low-bit format, well addresses the cost issue but unluckily bears more performance drops in lower-bit cases.
In this paper, we introduce I&S-ViT, a novel method that regulates the PTQ of ViTs in an inclusive and stable fashion. I&S-ViT first identifies two issues in the PTQ of ViTs: (1) Quantization inefficiency in the prevalent log2 quantizer for post-Softmax activations; (2) Rugged and magnified loss landscape in coarse-grained quantization granularity for post-LayerNorm activations. Then, I&S-ViT addresses these issues by introducing:
A novel shift-uniform-log2 quantizer (SULQ) incorporates a shift mechanism followed by uniform quantization to achieve both an inclusive domain representation and accurate distribution approximation.
A three-stage smooth optimization strategy (SOS) that amalgamates the strengths of channel-wise and layer-wise quantization to enable stable learning.
Comprehensive evaluations across diverse vision tasks validate I&S-ViT’ superiority over existing PTQ of ViT methods, particularly in low-bit scenarios. For instance, I&S-ViT elevates the performance of 3-bit ViT-B by an impressive 50.68%.
Looking to start a career in data science & AI and do not know how. I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
