


Top Important Computer Vision Papers for the Week from 13/05 to 19/05
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Third Week of May 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
Object Detection
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion

We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only 1 minute. The key component is a dual-mode multi-view latent diffusion model.
Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising.
Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch.
To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only 1/10 denoising steps with 3D mode, successfully generating a 3D asset in just 10 seconds without sacrificing quality.
The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time.
1.2. CAT3D: Create Anything in 3D with Multi-View Diffusion Models

Advances in 3D reconstruction have enabled high-quality 3D capture, but require a user to collect hundreds to thousands of images to create a 3D scene.
We present CAT3D, a method for creating anything in 3D by simulating this real-world capture process with a multi-view diffusion model. Given any number of input images and a set of target novel viewpoints, our model generates highly consistent novel views of a scene.
These generated views can be used as input to robust 3D reconstruction techniques to produce 3D representations that can be rendered from any viewpoint in real time. CAT3D can create entire 3D scenes in as little as one minute and outperforms existing methods for single-image and few-view 3D scene creation.
1.3. Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding

We present Hunyuan-DiT, a text-to-image diffusion transformer with a fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding.
We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images.
Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models.
1.4. Naturalistic Music Decoding from EEG Data via Latent Diffusion Models
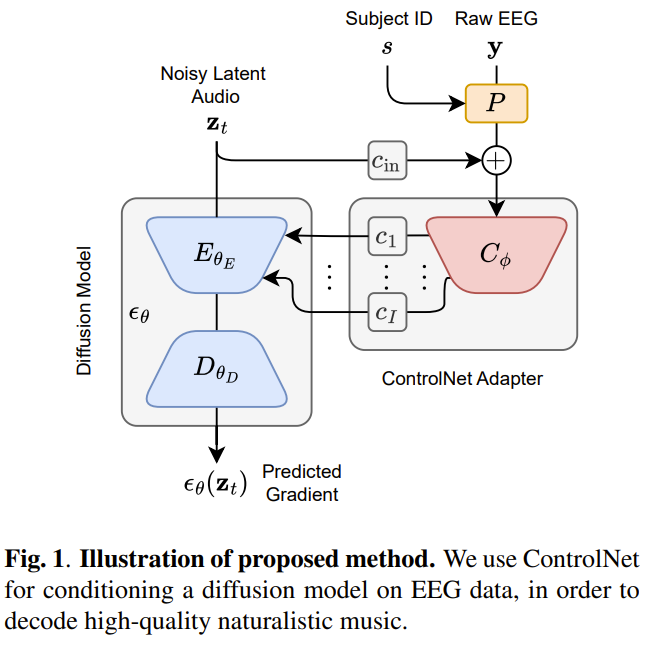
In this article, we explore the potential of using latent diffusion models, a family of powerful generative models, for the task of reconstructing naturalistic music from electroencephalogram (EEG) recordings.
Unlike simpler music with limited timbres, such as MIDI-generated tunes or monophonic pieces, the focus here is on intricate music featuring a diverse array of instruments, voices, and effects, rich in harmonics and timbre.
This study represents an initial foray into achieving general music reconstruction of high quality using non-invasive EEG data, employing an end-to-end training approach directly on raw data without the need for manual pre-processing and channel selection.
We train our models on the public NMED-T dataset and perform quantitative evaluation proposing neural embedding-based metrics. We additionally perform song classification based on the generated tracks.
Our work contributes to the ongoing research in neural decoding and brain-computer interfaces, offering insights into the feasibility of using EEG data for complex auditory information reconstruction.
2. Vision Language Models (VLMs)
2.1. What matters when building vision-language models?

The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified.
We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods.
Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
2.2. Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
We introduce Xmodel-VLM, a cutting-edge multimodal vision language model. It is designed for efficient deployment on consumer GPU servers. Our work directly confronts a pivotal industry issue by grappling with the prohibitive service costs that hinder the broad adoption of large-scale multimodal systems.
Through rigorous training, we have developed a 1B-scale language model from the ground up, employing the LLaVA paradigm for modal alignment. The result, which we call Xmodel-VLM, is a lightweight yet powerful multimodal vision language model.
Extensive testing across numerous classic multimodal benchmarks has revealed that despite its smaller size and faster execution, Xmodel-VLM delivers performance comparable to that of larger models.
3. Image Generation & Editing
3.1. Compositional Text-to-Image Generation with Dense Blob Representations

Existing text-to-image models struggle to follow complex text prompts, raising the need for extra grounding inputs for better controllability. In this work, we propose to decompose a scene into visual primitives — denoted as dense blob representations — that contain fine-grained details of the scene while being modular, human-interpretable, and easy to construct.
Based on blob representations, we develop a blob-grounded text-to-image diffusion model, termed BlobGEN, for compositional generation. Particularly, we introduce a new masked cross-attention module to disentangle the fusion between blob representations and visual features.
To leverage the compositionality of large language models (LLMs), we introduce a new in-context learning approach to generate blob representations from text prompts.
Our extensive experiments show that BlobGEN achieves superior zero-shot generation quality and better layout-guided controllability on MS-COCO. When augmented by LLMs, our method exhibits superior numerical and spatial correctness on compositional image generation benchmarks.
3.2. Toon3D: Seeing Cartoons from a New Perspective
In this work, we recover the underlying 3D structure of non-geometrically consistent scenes. We focus our analysis on hand-drawn images from cartoons and anime.
Many cartoons are created by artists without a 3D rendering engine, which means that any new image of a scene is hand-drawn. The hand-drawn images are usually faithful representations of the world, but only in a qualitative sense since it is difficult for humans to draw multiple perspectives of an object or scene in 3D consistently.
Nevertheless, people can easily perceive 3D scenes from inconsistent inputs! In this work, we correct for 2D drawing inconsistencies to recover a plausible 3D structure such that the newly warped drawings are consistent with each other.
Our pipeline consists of a user-friendly annotation tool, camera pose estimation, and image deformation to recover a dense structure. Our method warps images to obey a perspective camera model, enabling our aligned results to be plugged into novel-view synthesis reconstruction methods to experience cartoons from viewpoints never drawn before.
4. Video Understanding & Generation
4.1. No Time to Waste: Squeeze Time into Channel for Mobile Video Understanding
Current architectures for video understanding mainly build upon 3D convolutional blocks or 2D convolutions with additional operations for temporal modeling.
However, these methods all regard the temporal axis as a separate dimension of the video sequence, which requires large computation and memory budgets and thus limits their usage on mobile devices. In this paper, we propose to squeeze the time axis of a video sequence into the channel dimension and present a lightweight video recognition network, term as SqueezeTime, for mobile video understanding.
To enhance the temporal modeling capability of the proposed network, we design a Channel-Time Learning (CTL) Block to capture the temporal dynamics of the sequence. This module has two complementary branches, which one branch is for temporal importance learning and another branch with temporal position restoring capability to enhance inter-temporal object modeling ability.
The proposed SqueezeTime is much lightweight and fast with high accuracies for mobile video understanding. Extensive experiments on various video recognition and action detection benchmarks, i.e., Kinetics400, Kinetics600, HMDB51, AVA2.1, and THUMOS14, demonstrate the superiority of our model.
For example, our SqueezeTime achieves +1.2% accuracy and +80% GPU throughput gain on Kinetics400 than prior methods.
5. Object Detection
5.1. Grounding DINO 1.5: Advance the “Edge” of Open-Set Object Detection

This paper introduces Grounding DINO 1.5, a suite of advanced open-set object detection models developed by IDEA Research, which aims to advance the “Edge” of open-set object detection.
The suite encompasses two models: Grounding DINO 1.5 Pro, a high-performance model designed for stronger generalization capability across a wide range of scenarios, and Grounding DINO 1.5 Edge, an efficient model optimized for faster speed demanded in many applications requiring edge deployment.
The Grounding DINO 1.5 Pro model advances its predecessor by scaling up the model architecture, integrating an enhanced vision backbone, and expanding the training dataset to over 20 million images with grounding annotations, thereby achieving a richer semantic understanding.
The Grounding DINO 1.5 Edge model, while designed for efficiency with reduced feature scales, maintains robust detection capabilities by being trained on the same comprehensive dataset. Empirical results demonstrate the effectiveness of Grounding DINO 1.5, with the Grounding DINO 1.5 Pro model attaining a 54.3 AP on the COCO detection benchmark and a 55.7 AP on the LVIS-minival zero-shot transfer benchmark, setting new records for open-set object detection.
Furthermore, the Grounding DINO 1.5 Edge model, when optimized with TensorRT, achieves a speed of 75.2 FPS while attaining a zero-shot performance of 36.2 AP on the LVIS-minival benchmark, making it more suitable for edge computing scenarios.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
