


Top Important Computer Vision Papers for the Week from 12/02 to 18/02
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Third Week of February 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Stable Diffusion
Vision Language Models
Image Generation & Editing
Video Generation & Editing
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Stable Diffusion
1.1. Rolling Diffusion Models
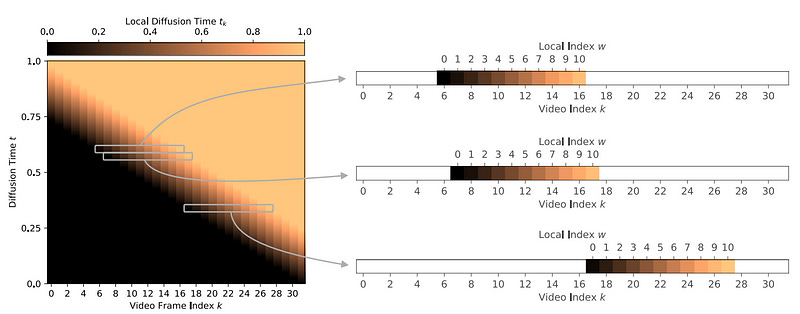
Diffusion models have recently been increasingly applied to temporal data such as video, fluid mechanics simulations, or climate data. These methods generally treat subsequent frames equally regarding the amount of noise in the diffusion process.
This paper explores Rolling Diffusion: a new approach that uses a sliding window denoising process. It ensures that the diffusion process progressively corrupts through time by assigning more noise to frames that appear later in a sequence, reflecting greater uncertainty about the future as the generation process unfolds.
Empirically, we show that when the temporal dynamics are complex, Rolling Diffusion is superior to standard diffusion. In particular, this result is demonstrated in a video prediction task using the Kinetics-600 video dataset and in a chaotic fluid dynamics forecasting experiment.
1.2. Animated Stickers: Bringing Stickers to Life with Video Diffusion

We introduce animated stickers, a video diffusion model that generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion.
Due to the domain gap, i.e. differences in visual and motion style, a model that performed well in generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by a human-in-the-loop (HITL) strategy which we term ensemble-of-teachers.
It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model can generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.
1.3. Self-Play Fine-Tuning of Diffusion Models for Text-to-Image Generation

Fine-tuning Diffusion Models remains an underexplored frontier in generative artificial intelligence (GenAI), especially when compared with the remarkable progress made in fine-tuning Large Language Models (LLMs). While cutting-edge diffusion models such as Stable Diffusion (SD) and SDXL rely on supervised fine-tuning, their performance inevitably plateaus after seeing a certain volume of data.
Recently, reinforcement learning (RL) has been employed to fine-tune diffusion models with human preference data, but it requires at least two images (“winner” and “loser” images) for each text prompt. In this paper, we introduce an innovative technique called self-play fine-tuning for diffusion models (SPIN-Diffusion), where the diffusion model engages in competition with its earlier versions, facilitating an iterative self-improvement process.
Our approach offers an alternative to conventional supervised fine-tuning and RL strategies, significantly improving both model performance and alignment. Our experiments on the Pick-a-Pic dataset reveal that SPIN-Diffusion outperforms the existing supervised fine-tuning method in aspects of human preference alignment and visual appeal right from its first iteration. By the second iteration, it exceeds the performance of RLHF-based methods across all metrics, achieving these results with less data.
1.4. IM-3D: Iterative Multiview Diffusion and Reconstruction for High-Quality 3D Generation

Most text-to-3D generators build upon off-the-shelf text-to-image models trained on billions of images. They use variants of Score Distillation Sampling (SDS), which is slow, somewhat unstable, and prone to artifacts.
Mitigation is to fine-tune the 2D generator to be multi-view aware, which can help distillation or can be combined with reconstruction networks to output 3D objects directly. In this paper, we further explore the design space of text-to-3D models.
We significantly improve multi-view generation by considering video instead of image generators. Combined with a 3D reconstruction algorithm which, by using Gaussian splatting, can optimize a robust image-based loss, we directly produce high-quality 3D outputs from the generated views.
Our new method, IM-3D, reduces the number of evaluations of the 2D generator network by 10–100x, resulting in a much more efficient pipeline, better quality, fewer geometric inconsistencies, and higher yield of usable 3D assets.
1.5. Magic-Me: Identity-Specific Video Customized Diffusion

Creating content for a specific identity (ID) has shown significant interest in the field of generative models. In the field of text-to-image generation (T2I), subject-driven content generation has achieved great progress with the ID in the images controllable. However, extending it to video generation is not well explored.
In this work, we propose a simple yet effective subject identity controllable video generation framework, termed Video Custom Diffusion (VCD). With a specified subject ID defined by a few images, VCD reinforces the identity information extraction and injects frame-wise correlation at the initialization stage for stable video outputs with identity preserved to a large extent.
To achieve this, we propose three novel components that are essential for high-quality ID preservation:
An ID module trained with the cropped identity by prompt-to-segmentation to disentangle the ID information and the background noise for more accurate ID token learning;
A text-to-video (T2V) VCD module with 3D Gaussian Noise Prior for better inter-frame consistency
Video-to-video (V2V) Face VCD and Tiled VCD modules to deblur the face and upscale the video for higher resolution.
Despite its simplicity, we conducted extensive experiments to verify that VCD is able to generate stable and high-quality videos with better ID over the selected strong baselines.
Besides, due to the transferability of the ID module, VCD is also working well with finetuned text-to-image models available publically, further improving its usability. The codes are available at
1.6. PRDP: Proximal Reward Difference Prediction for Large-Scale Reward Finetuning of Diffusion Models

Reward finetuning has emerged as a promising approach to aligning foundation models with downstream objectives. Remarkable success has been achieved in the language domain by using reinforcement learning (RL) to maximize rewards that reflect human preference.
However, in the vision domain, existing RL-based reward finetuning methods are limited by their instability in large-scale training, rendering them incapable of generalizing to complex, unseen prompts. In this paper, we propose Proximal Reward Difference Prediction (PRDP), enabling stable black-box reward finetuning for diffusion models for the first time on large-scale prompt datasets with over 100K prompts.
Our key innovation is the Reward Difference Prediction (RDP) objective which has the same optimal solution as the RL objective while enjoying better training stability. Specifically, the RDP objective is a supervised regression objective that tasks the diffusion model with predicting the reward difference of generated image pairs from their denoising trajectories.
We theoretically prove that the diffusion model that obtains perfect reward difference prediction is exactly the maximizer of the RL objective. We further develop an online algorithm with proximal updates to stably optimize the RDP objective.
In experiments, we demonstrate that PRDP can match the reward maximization ability of well-established RL-based methods in small-scale training. Furthermore, through large-scale training on text prompts from the Human Preference Dataset v2 and the Pick-a-Pic v1 dataset, PRDP achieves superior generation quality on a diverse set of complex, unseen prompts whereas RL-based methods completely fail.
2. Vision Language Models
2.1. Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models

Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3.
Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance — a challenge further complicated by the lack of objective, consistent evaluations.
To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization from language, and targeted challenge sets that probe properties such as hallucination; evaluations that provide calibrated, fine-grained insight into a VLM’s capabilities.
Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and quantifying the tradeoffs of using base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions:
A unified framework for evaluating VLMs
Optimized, flexible code for VLM training
Checkpoints for all models, including a family of VLMs at the 7–13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art open-source VLMs.
2.2. ViGoR: Improving Visual Grounding of Large Vision Language Models with Fine-Grained Reward Modeling
By combining natural language understanding and the generation capabilities and breadth of knowledge of large language models with image perception, recent large vision language models (LVLMs) have shown unprecedented reasoning capabilities in the real world.
However, the generated text often suffers from an inaccurate grounding in the visual input, resulting in errors such as hallucinating nonexistent scene elements, missing significant parts of the scene, and inferring incorrect attributes and relationships between objects.
To address these issues, we introduce a novel framework, ViGoR (Visual Grounding Through Fine-Gained Reward Modeling) that utilizes fine-grained reward modeling to significantly enhance the visual grounding of LVLMs over pre-trained baselines. This improvement is efficiently achieved using much cheaper human evaluations instead of full supervision, as well as automated methods.
We show the effectiveness of our approach through numerous metrics on several benchmarks. Additionally, we construct a comprehensive and challenging dataset specifically designed to validate the visual grounding capabilities of LVLMs. Finally, we plan to release our human annotation comprising approximately 16,000 images and generated text pairs with fine-grained evaluations to contribute to related research in the community.
2.3. World Model on Million-Length Video And Language With RingAttention
Current language models fall short in understanding aspects of the world not easily described in words and struggle with complex, long-form tasks. Video sequences offer valuable temporal information absent in language and static images, making them attractive for joint modeling with language.
Such models could develop an understanding of both human textual knowledge and the physical world, enabling broader AI capabilities for assisting humans. However, learning from millions of tokens of video and language sequences poses challenges due to memory constraints, computational complexity, and limited datasets.
To address these challenges, we curate a large dataset of diverse videos and books, utilize the RingAttention technique to scalably train on long sequences, and gradually increase context size from 4K to 1M tokens. This paper makes the following contributions:
Largest context size neural network: We train one of the largest context size transformers on long video and language sequences, setting new benchmarks in difficult retrieval tasks and long video understanding.
Solutions for overcoming vision-language training challenges include using masked sequence packing for mixing different sequence lengths, loss weighting to balance language and vision, and model-generated QA dataset for long sequence chat.
A highly optimized implementation with RingAttention, masked sequence packing, and other key features for training on millions-length multimodal sequences.
Fully open-sourced a family of 7B parameter models capable of processing long text documents (LWM-Text, LWM-Text-Chat) and videos (LWM, LWM-Chat) of over 1M tokens.
This work paves the way for training on massive datasets of long videos and language to develop an understanding of both human knowledge and the multimodal world and broader capabilities.
2.4. DreamMatcher: Appearance Matching Self-Attention for Semantically-Consistent Text-to-Image Personalization

The objective of text-to-image (T2I) personalization is to customize a diffusion model to a user-provided reference concept, generating diverse images of the concept aligned with the target prompts. Conventional methods representing the reference concepts using unique text embeddings often fail to accurately mimic the appearance of the reference.
To address this, one solution may be explicitly conditioning the reference images into the target denoising process, known as key-value replacement. However, prior works are constrained to local editing since they disrupt the structure path of the pre-trained T2I model.
To overcome this, we propose a novel plug-in method, called DreamMatcher, which reformulates T2I personalization as semantic matching. Specifically, DreamMatcher replaces the target values with reference values aligned by semantic matching, while leaving the structure path unchanged to preserve the versatile capability of pre-trained T2I models for generating diverse structures.
We also introduce a semantic-consistent masking strategy to isolate the personalized concept from irrelevant regions introduced by the target prompts. Compatible with existing T2I models, DreamMatcher shows significant improvements in complex scenarios. Intensive analyses demonstrate the effectiveness of our approach.
3. Image Generation & Editing
3.1. Learning Continuous 3D Words for Text-to-Image Generation

Current controls over diffusion models (e.g., through text or ControlNet) for image generation fall short in recognizing abstract, continuous attributes like illumination direction or non-rigid shape change. In this paper, we present an approach for allowing users of text-to-image models to have fine-grained control of several attributes in an image.
We do this by engineering special sets of input tokens that can be transformed continuously — we call them Continuous 3D Words. These attributes can, for example, be represented as sliders and applied jointly with text prompts for fine-grained control over image generation.
Given only a single mesh and a rendering engine, we show that our approach can be adapted to provide continuous user control over several 3D-aware attributes, including time-of-day illumination, bird wing orientation, dolly zoom effect, and object poses.
Our method is capable of conditioning image creation with multiple Continuous 3D Words and text descriptions simultaneously while adding no overhead to the generative process.
4. Video Generation & Editing
4.1. Keyframer: Empowering Animation Design using Large Language Models

Large language models (LLMs) have the potential to impact a wide range of creative domains, but the application of LLMs to animation is underexplored and presents novel challenges such as how users might effectively describe motion in natural language.
In this paper, we present Keyframer, a design tool for animating static images (SVGs) with natural language. Informed by interviews with professional animation designers and engineers, Keyframer supports the exploration and refinement of animations through the combination of prompting and direct editing of generated output.
The system also enables users to request design variants, supporting comparison and ideation. Through a user study with 13 participants, we contribute a characterization of user prompting strategies, including a taxonomy of semantic prompt types for describing motion and a ‘decomposed’ prompting style where users continually adapt their goals in response to the generated output.
We share how direct editing along with prompting enables iteration beyond one-shot prompting interfaces common in generative tools today. Through this work, we propose how LLMs might empower a range of audiences to engage with animation creation.
4.2. HeadStudio: Text to Animatable Head Avatars with 3D Gaussian Splatting

Creating digital avatars from textual prompts has long been a desirable yet challenging task. Despite the promising outcomes obtained through 2D diffusion priors in recent works, current methods face challenges in achieving high-quality and animated avatars effectively.
In this paper, we present HeadStudio, a novel framework that utilizes 3D Gaussian splatting to generate realistic and animated avatars from text prompts. Our method drives 3D Gaussians semantically to create a flexible and achievable appearance through the intermediate FLAME representation.
Specifically, we incorporate the FLAME into both 3D representation and score distillation:
FLAME-based 3D Gaussian splatting, driving 3D Gaussian points by rigging each point to a FLAME mesh.
FLAME-based score distillation sampling, utilizing FLAME-based fine-grained control signal to guide score distillation from the text prompt. Extensive experiments demonstrate the efficacy of HeadStudio in generating animatable avatars from textual prompts, exhibiting visually appealing appearances.
The avatars are capable of rendering high-quality real-time (geq 40 fps) novel views at a resolution of 1024. They can be smoothly controlled by real-world speech and video. We hope that HeadStudio can advance digital avatar creation and that the present method can widely be applied across various domains.

Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
