
Top Important Computer Vision Papers for the Week from 15/01 to 21/01
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Third Week of January 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Stable Diffusion
Vision Language Models
Image Generation & Editing
Video Generation & Editing
Image Recognition
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Stable Diffusion
1.1. DiffusionGPT: LLM-Driven Text-to-Image Generation System
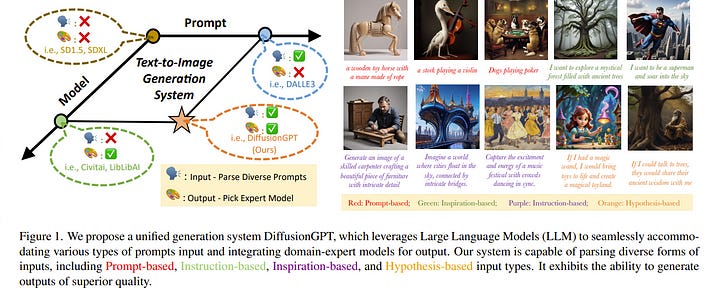
Diffusion models have opened up new avenues for the field of image generation, resulting in the proliferation of high-quality models shared on open-source platforms. However, a major challenge persists in current text-to-image systems are often unable to handle diverse inputs, or are limited to single-model results.
Current unified attempts often fall into two orthogonal aspects: i) parse Diverse Prompts in the input stage; ii) activate expert model to output. To combine the best of both worlds, we propose DiffusionGPT, which leverages Large Language Models (LLM) to offer a unified generation system capable of seamlessly accommodating various types of prompts and integrating domain-expert models.
DiffusionGPT constructs domain-specific Trees for various generative models based on prior knowledge. When provided with input, the LLM parses the prompt and employs the Trees of Thought to guide the selection of an appropriate model, thereby relaxing input constraints and ensuring exceptional performance across diverse domains.
Moreover, we introduce Advantage Databases, where the tree of thought is enriched with human feedback, aligning the model selection process with human preferences. Through extensive experiments and comparisons, we demonstrate the effectiveness of DiffusionGPT, showcasing its potential for pushing the boundaries of image synthesis in diverse domains.
1.2. FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder

The goal of this paper is to generate realistic audio with a lightweight and fast diffusion-based vocoder, named FreGrad. Our framework consists of the following three key components:
We employ a discrete wavelet transform that decomposes a complicated waveform into sub-band wavelets, which helps FreGrad to operate on a simple and concise feature space.
We design a frequency-aware dilated convolution that elevates frequency awareness, resulting in generating speech with accurate frequency information.
We introduce a bag of tricks that boost the generation quality of the proposed model. In our experiments, FreGrad achieves 3.7 times faster training time and 2.2 times faster inference speed compared to our baseline while reducing the model size by 0.6 times (only 1.78M parameters) without sacrificing the output quality.
1.3. VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models

Text-to-video generation aims to produce a video based on a given prompt. Recently, several commercial video models have been able to generate plausible videos with minimal noise, excellent details, and high aesthetic scores.
However, these models rely on large-scale, well-filtered, high-quality videos that are not accessible to the community. Many existing research works, which train models using the low-quality WebVid-10M dataset, struggle to generate high-quality videos because the models are optimized to fit WebVid-10M.
In this work, we explore the training scheme of video models extended from Stable Diffusion and investigate the feasibility of leveraging low-quality videos and synthesized high-quality images to obtain a high-quality video model. We first analyze the connection between the spatial and temporal modules of video models and the distribution shift to low-quality videos.
We observe that full training of all modules results in a stronger coupling between spatial and temporal modules than only training temporal modules. Based on this stronger coupling, we shift the distribution to higher quality without motion degradation by finetuning spatial modules with high-quality images, resulting in a generic high-quality video model. Evaluations are conducted to demonstrate the superiority of the proposed method, particularly in picture quality, motion, and concept composition.
1.4. HexaGen3D: StableDiffusion is just one step away from Fast and Diverse Text-to-3D Generation

Despite the latest remarkable advances in generative modeling, efficient generation of high-quality 3D assets from textual prompts remains a difficult task. A key challenge lies in data scarcity: the most extensive 3D datasets encompass merely millions of assets, while their 2D counterparts contain billions of text-image pairs.
To address this, we propose a novel approach that harnesses the power of large, pretrained 2D diffusion models. More specifically, our approach, HexaGen3D, fine-tunes a pretrained text-to-image model to jointly predict 6 orthographic projections and the corresponding latent triplane.
We then decode these latents to generate a textured mesh. HexaGen3D does not require per-sample optimization and can infer high-quality and diverse objects from textual prompts in 7 seconds, offering significantly better quality-to-latency trade-offs when compared to existing approaches. Furthermore, HexaGen3D demonstrates strong generalization to new objects or compositions.
1.5. Quantum Denoising Diffusion Models

In recent years, machine learning models like DALL-E, Craiyon, and Stable Diffusion have gained significant attention for their ability to generate high-resolution images from concise descriptions.
Concurrently, quantum computing is showing promising advances, especially with quantum machine learning which capitalizes on quantum mechanics to meet the increasing computational requirements of traditional machine learning algorithms.
This paper explores the integration of quantum machine learning and variational quantum circuits to augment the efficacy of diffusion-based image generation models. Specifically, we address two challenges of classical diffusion models: their low sampling speed and the extensive parameter requirements.
We introduce two quantum diffusion models and benchmark their capabilities against their classical counterparts using MNIST digits, Fashion MNIST, and CIFAR-10. Our models surpass the classical models with similar parameter counts in terms of performance metrics FID, SSIM, and PSNR. Moreover, we introduce a consistency model unitary single sampling architecture that combines the diffusion procedure into a single step, enabling a fast one-step image generation.
1.6. Compose and Conquer: Diffusion-Based 3D Depth Aware Composable Image Synthesis

Addressing the limitations of text as a source of accurate layout representation in text-conditional diffusion models, many works incorporate additional signals to condition certain attributes within a generated image.
Although successful, previous works do not account for the specific localization of said attributes extended into the three-dimensional plane. In this context, we present a conditional diffusion model that integrates control over three-dimensional object placement with disentangled representations of global stylistic semantics from multiple exemplar images.
Specifically, we first introduce depth disentanglement training to leverage the relative depth of objects as an estimator, allowing the model to identify the absolute positions of unseen objects through the use of synthetic image triplets. We also introduce soft guidance, a method for imposing global semantics onto targeted regions without the use of any additional localization cues.
Our integrated framework, Compose and Conquer (CnC), unifies these techniques to localize multiple conditions in a disentangled manner. We demonstrate that our approach allows the perception of objects at varying depths while offering a versatile framework for composing localized objects with different global semantics.
1.7. SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers

We present Scalable Interpolant Transformers (SiT), a family of generative models built on the backbone of Diffusion Transformers (DiT). The interpolant framework, which allows for connecting two distributions in a more flexible way than standard diffusion models, makes possible a modular study of various design choices impacting generative models built on dynamical transport: using discrete vs. continuous time learning, deciding the objective for the model to learn, choosing the interpolant connecting the distributions, and deploying a deterministic or stochastic sampler.
By carefully introducing the above ingredients, SiT surpasses DiT uniformly across model sizes on the conditional ImageNet 256x256 benchmark using the same backbone, number of parameters, and GFLOPs. By exploring various diffusion coefficients, which can be tuned separately from learning, SiT achieves an FID-50K score of 2.06.
1.8. TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion

We present TextureDreamer, a novel image-guided texture synthesis method to transfer relightable textures from a small number of input images (3 to 5) to target 3D shapes across arbitrary categories. Texture creation is a pivotal challenge in vision and graphics. Industrial companies hire experienced artists to manually craft textures for 3D assets.
Classical methods require densely sampled views and accurately aligned geometry, while learning-based methods are confined to category-specific shapes within the dataset. In contrast, TextureDreamer can transfer highly detailed, intricate textures from real-world environments to arbitrary objects with only a few casually captured images, potentially significantly democratizing texture creation.
Our core idea, personalized geometry-aware score distillation (PGSD), draws inspiration from recent advancements in diffuse models, including personalized modeling for texture information extraction, variational score distillation for detailed appearance synthesis, and explicit geometry guidance with ControlNet. Our integration and several essential modifications substantially improve the texture quality.
Experiments on real images spanning different categories show that TextureDreamer can successfully transfer highly realistic, semantic meaningful texture to arbitrary objects, surpassing the visual quality of previous state-of-the-art.
2. Vision Language Models
2.1. Improving fine-grained understanding in image-text pre-training
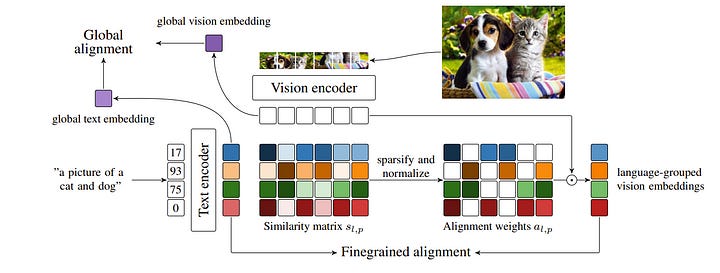
We introduce SPARse Fine-grained Contrastive Alignment (SPARC), a simple method for pretraining more fine-grained multimodal representations from image-text pairs. Given that multiple image patches often correspond to single words, we propose to learn a grouping of image patches for every token in the caption.
To achieve this, we use a sparse similarity metric between image patches and language tokens and compute for each token a language-grouped vision embedding as the weighted average of patches. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples and does not require other batch samples as negatives.
This enables more detailed information to be learned in a computationally inexpensive manner. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to learn representations that simultaneously encode global and local information.
We thoroughly evaluate our proposed method and show improved performance over competing approaches both on image-level tasks relying on coarse-grained information, e.g. classification, as well as region-level tasks relying on fine-grained information, e.g. retrieval, object detection, and segmentation. Moreover, SPARC improves model faithfulness and captioning in foundational vision-language models.
2.2. SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding

3D vision-language grounding, which focuses on aligning language with the 3D physical environment, stands as a cornerstone in the development of embodied agents. In comparison to recent advancements in the 2D domain, grounding language in 3D scenes faces several significant challenges:
The inherent complexity of 3D scenes due to the diverse object configurations, their rich attributes, and intricate relationships
The scarcity of paired 3D vision-language data to support grounded learning
The absence of a unified learning framework to distill knowledge from grounded 3D data.
In this work, we aim to address these three major challenges in 3D vision language by examining the potential of systematically upscaling 3D vision language learning in indoor environments. We introduce the first million-scale 3D vision-language dataset, SceneVerse, encompassing about 68K 3D indoor scenes and comprising 2.5M vision-language pairs derived from both human annotations and our scalable scene-graph-based generation approach.
We demonstrate that this scaling allows for a unified pre-training framework, Grounded Pre-training for Scenes (GPS), for 3D vision-language learning. Through extensive experiments, we showcase the effectiveness of GPS by achieving state-of-the-art performance on all existing 3D visual grounding benchmarks. The vast potential of SceneVerse and GPS is unveiled through zero-shot transfer experiments in challenging 3D vision-language tasks.
2.3. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
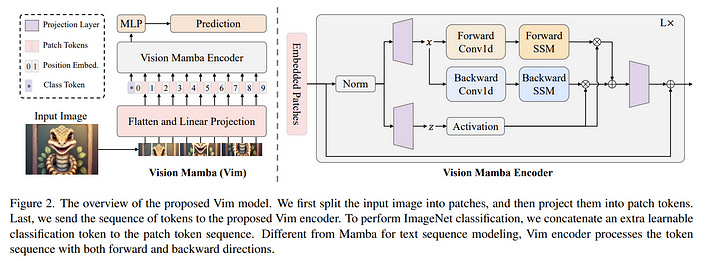
Recently the state space models (SSMs) with efficient hardware-aware designs, i.e., Mamba, have shown great potential for long sequence modeling. Building efficient and generic vision backbones purely upon SSMs is an appealing direction.
However, representing visual data is challenging for SSMs due to the position-sensitivity of visual data and the requirement of global context for visual understanding. In this paper, we show that the reliance of visual representation learning on self-attention is not necessary and propose a new generic vision backbone with bidirectional Mamba blocks (Vim), which marks the image sequences with position embeddings and compresses the visual representation with bidirectional state space models.
On ImageNet classification, COCO object detection, and ADE20k semantic segmentation tasks, Vim achieves higher performance compared to well-established vision transformers like DeiT, while also demonstrating significantly improved computation & memory efficiency. For example, Vim is 2.8 times faster than DeiT and saves 86.8% GPU memory when performing batch inference to extract features on images with a resolution of 1248 times 1248.
The results demonstrate that Vim is capable of overcoming the computation & memory constraints on performing Transformer-style understanding for high-resolution images and it has great potential to become the next-generation backbone for vision foundation models.
3. Image Generation & Editing
3.1. Rethinking FID: Towards a Better Evaluation Metric for Image Generation

As with many machine learning problems, the progress of image generation methods hinges on good evaluation metrics. One of the most popular is the Frechet Inception Distance (FID).
FID estimates the distance between a distribution of Inception-v3 features of real images and those of images generated by the algorithm. We highlight important drawbacks of FID: Inception’s poor representation of the rich and varied content generated by modern text-to-image models, incorrect normality assumptions, and poor sample complexity. We call for a reevaluation of FID’s use as the primary quality metric for generated images.
We empirically demonstrate that FID contradicts human raters, does not reflect the gradual improvement of iterative text-to-image models, does not capture distortion levels and that it produces inconsistent results when varying the sample size. We also propose an alternative new metric, CMMD, based on richer CLIP embeddings and the maximum mean discrepancy distance with the Gaussian RBF kernel.
It is an unbiased estimator that does not make any assumptions on the probability distribution of the embeddings and is sample efficient. Through extensive experiments and analysis, we demonstrate that FID-based evaluations of text-to-image models may be unreliable and that CMMD offers a more robust and reliable assessment of image quality.
3.2. InstantID: Zero-shot Identity-Preserving Generation in Seconds

There has been significant progress in personalized image synthesis with methods such as Textual Inversion, DreamBooth, and LoRA. Yet, their real-world applicability is hindered by high storage demands, lengthy fine-tuning processes, and the need for multiple reference images.
Conversely, existing ID embedding-based methods, while requiring only a single forward inference, face challenges: they either necessitate extensive fine-tuning across numerous model parameters, lack compatibility with community pre-trained models or fail to maintain high face fidelity. Addressing these limitations, we introduce InstantID, a powerful diffusion model-based solution.
Our plug-and-play module adeptly handles image personalization in various styles using just a single facial image, while ensuring high fidelity. To achieve this, we design a novel IdentityNet by imposing strong semantic and weak spatial conditions, integrating facial and landmark images with textual prompts to steer the image generation.
InstantID demonstrates exceptional performance and efficiency, proving highly beneficial in real-world applications where identity preservation is paramount. Moreover, our work seamlessly integrates with popular pre-trained text-to-image diffusion models like SD1.5 and SDXL, serving as an adaptable plugin.
4. Video Generation & Editing
4.1. Towards A Better Metric for Text-to-Video Generation

Generative models have demonstrated remarkable capability in synthesizing high-quality text, images, and videos. For video generation, contemporary text-to-video models exhibit impressive capabilities, crafting visually stunning videos. Nonetheless, evaluating such videos poses significant challenges.
Current research predominantly employs automated metrics such as FVD, IS, and CLIP Score. However, these metrics provide an incomplete analysis, particularly in the temporal assessment of video content, thus rendering them unreliable indicators of true video quality.
Furthermore, while user studies have the potential to reflect human perception accurately, they are hampered by their time-intensive and laborious nature, with outcomes that are often tainted by subjective bias. In this paper, we investigate the limitations inherent in existing metrics and introduce a novel evaluation pipeline, the Text-to-Video Score (T2VScore).
This metric integrates two pivotal criteria:
Text-Video Alignment, which scrutinizes the fidelity of the video in representing the given text description
Video Quality, which evaluates the video’s overall production caliber with a mixture of experts.
Moreover, to evaluate the proposed metrics and facilitate future improvements on them, we present the TVGE dataset, collecting human judgments of 2,543 text-to-video generated videos on the two criteria. Experiments on the TVGE dataset demonstrate the superiority of the proposed T2VScore in offering a better metric for text-to-video generation.
4.2. WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens
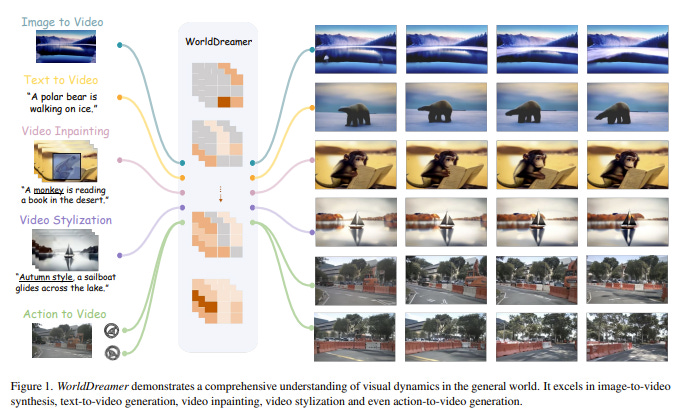
World models play a crucial role in understanding and predicting the dynamics of the world, which is essential for video generation. However, existing world models are confined to specific scenarios such as gaming or driving, limiting their ability to capture the complexity of general world dynamic environments.
Therefore, we introduce WorldDreamer, a pioneering world model to foster a comprehensive comprehension of general world physics and motions, which significantly enhances the capabilities of video generation. Drawing inspiration from the success of large language models, WorldDreamer frames world modeling as an unsupervised visual sequence modeling challenge.
This is achieved by mapping visual inputs to discrete tokens and predicting the masked ones. During this process, we incorporate multi-modal prompts to facilitate interaction within the world model. Our experiments show that WorldDreamer excels in generating videos across different scenarios, including natural scenes and driving environments.
WorldDreamer showcases versatility in executing tasks such as text-to-video conversion, image-to-video synthesis, and video editing. These results underscore WorldDreamer’s effectiveness in capturing dynamic elements within diverse general world environments.
4.3. CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects

Customized text-to-video generation aims to generate high-quality videos guided by text prompts and subject references. Current approaches designed for single subjects suffer from tackling multiple subjects, which is a more challenging and practical scenario.
In this work, we aim to promote multi-subject guided text-to-video customization. We propose CustomVideo, a novel framework that can generate identity-preserving videos with the guidance of multiple subjects. To be specific, firstly, we encourage the co-occurrence of multiple subjects by composing them in a single image.
Further, upon a basic text-to-video diffusion model, we design a simple yet effective attention control strategy to disentangle different subjects in the latent space of the diffusion model. Moreover, to help the model focus on the specific object area, we segment the object from given reference images and provide a corresponding object mask for attention learning.
Also, we collect a multi-subject text-to-video generation dataset as a comprehensive benchmark, with 69 individual subjects and 57 meaningful pairs. Extensive qualitative, quantitative, and user study results demonstrate the superiority of our method, compared with the previous state-of-the-art approaches.
4.4. UniVG: Towards Unified-modal Video Generation

Diffusion-based video generation has received extensive attention and achieved considerable success within both the academic and industrial communities. However, current efforts are mainly concentrated on single-objective or single-task video generation, such as generation driven by text, by image, or by a combination of text and image.
This cannot fully meet the needs of real-world application scenarios, as users are likely to input images and text conditions flexibly, either individually or in combination. To address this, we propose a Unified-modal Video generation system that is capable of handling multiple video generation tasks across text and image modalities.
To this end, we revisit the various video generation tasks within our system from the perspective of generative freedom and classify them into high-freedom and low-freedom video generation categories. For high-freedom video generation, we employ Multi-condition cross-attention to generate videos that align with the semantics of the input images or text.
For low-freedom video generation, we introduce Biased Gaussian Noise to replace the pure random Gaussian Noise, which helps to better preserve the content of the input conditions. Our method achieves the lowest Fr\’echet Video Distance (FVD) on the public academic benchmark MSR-VTT, surpasses the current open-source methods in human evaluations, and is on par with the current closed-source method Gen2.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
