


Top Important Computer Vision Papers for the Week from 25/03 to 31/03
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Fifth Week of March 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Image Generation & Editing
Video Understanding & Generation
Image Recognition
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. FlexEdit: Flexible and Controllable Diffusion-based Object-centric Image Editing

Our work addresses limitations seen in previous approaches for object-centric editing problems, such as unrealistic results due to shape discrepancies and limited control in object replacement or insertion.
To this end, we introduce FlexEdit, a flexible and controllable editing framework for objects where we iteratively adjust latents at each denoising step using our FlexEdit block. Initially, we optimize latents at test time to align with specified object constraints.
Then, our framework employs an adaptive mask, automatically extracted during denoising, to protect the background while seamlessly blending new content into the target image. We demonstrate the versatility of FlexEdit in various object editing tasks and curate an evaluation test suite with samples from both real and synthetic images, along with novel evaluation metrics designed for object-centric editing.
We conduct extensive experiments on different editing scenarios, demonstrating the superiority of our editing framework over recent advanced text-guided image editing methods.
1.2. DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion

We present DreamPolisher, a novel Gaussian splatting-based method with geometric guidance, tailored to learn cross-view consistency and intricate detail from textual descriptions.
While recent progress in text-to-3D generation methods has been promising, prevailing methods often fail to ensure view consistency and textural richness. This problem becomes particularly noticeable for methods that work with text input alone.
To address this, we propose a two-stage Gaussian Splatting based approach that enforces geometric consistency among views. Initially, a coarse 3D generation undergoes refinement via geometric optimization. Subsequently, we use a ControlNet-driven refiner coupled with the geometric consistency term to improve both texture fidelity and overall consistency of the generated 3D asset.
Empirical evaluations across diverse textual prompts spanning various object categories demonstrate the efficacy of DreamPolisher in generating consistent and realistic 3D objects, aligning closely with the semantics of the textual instructions.
1.3. TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models

Recent advances in text-to-video generation have demonstrated the utility of powerful diffusion models. Nevertheless, the problem is not trivial when shaping diffusion models to animate static images (i.e., image-to-video generation).
The difficulty originates from the aspect that the diffusion process of subsequent animated frames should not only preserve the faithful alignment with the given image but also pursue temporal coherence among adjacent frames.
To alleviate this, we present TRIP, a new recipe of image-to-video diffusion paradigm that pivots on image noise prior derived from a static image to jointly trigger inter-frame relational reasoning and ease the coherent temporal modeling via temporal residual learning. Technically, the image noise prior is first attained through a one-step backward diffusion process based on both static image and noised video latent codes.
Next, TRIP executes a residual-like dual-path scheme for noise prediction: 1) a shortcut path that directly takes image noise prior as the reference noise of each frame to amplify the alignment between the first frame and subsequent frames; 2) a residual path that employs 3D-UNet over noised video and static image latent codes to enable inter-frame relational reasoning, thereby easing the learning of the residual noise for each frame.
Furthermore, both the reference and residual noise of each frame are dynamically merged via the attention mechanism for final video generation. Extensive experiments on WebVid-10M, DTDB, and MSR-VTT datasets demonstrate the effectiveness of our TRIP for image-to-video generation.
1.4. SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions

Recent advancements in diffusion models have positioned them at the forefront of image generation. Despite their superior performance, diffusion models are not without drawbacks; they are characterized by complex architectures and substantial computational demands, resulting in significant latency due to their iterative sampling process.
To mitigate these limitations, we introduce a dual approach involving model miniaturization and a reduction in sampling steps to significantly decrease model latency. Our methodology leverages knowledge distillation to streamline the U-Net and image decoder architectures and introduces an innovative one-step DM training technique that utilizes feature matching and score distillation.
We present two models, SDXS-512 and SDXS-1024, achieving inference speeds of approximately 100 FPS (30x faster than SD v1.5) and 30 FP (60x faster than SDXL) on a single GPU, respectively. Moreover, our training approach offers promising applications in image-conditioned control, facilitating efficient image-to-image translation.
2. Image Generation & Editing
2.1. LATTE3D: Large-scale Amortized Text-To-Enhanced3D Synthesis

Recent text-to-3D generation approaches produce impressive 3D results but require time-consuming optimization that can take up to an hour per prompt.
Amortized methods like ATT3D optimize multiple prompts simultaneously to improve efficiency, enabling fast text-to-3D synthesis. However, they cannot capture high-frequency geometry and texture details and struggle to scale to large prompt sets, so they generalize poorly. We introduce LATTE3D, addressing these limitations to achieve fast, high-quality generation on a significantly larger prompt set.
The key to our method is 1) building a scalable architecture and 2) leveraging 3D data during optimization through 3D-aware diffusion priors, shape regularization, and model initialization to achieve robustness to diverse and complex training prompts.
LATTE3D amortizes both neural field and textured surface generation to produce highly detailed textured meshes in a single forward pass. LATTE3D generates 3D objects in 400ms and can be further enhanced with fast test-time optimization.
2.2. Be Yourself: Bounded Attention for Multi-Subject Text-to-Image Generation

Text-to-image diffusion models have an unprecedented ability to generate diverse and high-quality images. However, they often struggle to faithfully capture the intended semantics of complex input prompts that include multiple subjects.
Recently, numerous layout-to-image extensions have been introduced to improve user control, aiming to localize subjects represented by specific tokens. Yet, these methods often produce semantically inaccurate images, especially when dealing with multiple semantically or visually similar subjects.
In this work, we study and analyze the causes of these limitations. Our exploration reveals that the primary issue stems from inadvertent semantic leakage between subjects in the denoising process. This leakage is attributed to the diffusion model’s attention layers, which tend to blend the visual features of different subjects.
To address these issues, we introduce Bounded Attention, a training-free method for bounding the information flow in the sampling process. Bounded Attention prevents detrimental leakage among subjects and enables guiding the generation to promote each subject’s individuality, even with complex multi-subject conditioning.
Through extensive experimentation, we demonstrate that our method empowers the generation of multiple subjects that better align with given prompts and layouts.
2.3. Improving Text-to-Image Consistency via Automatic Prompt Optimization

Impressive advances in text-to-image (T2I) generative models have yielded a plethora of high-performing models that can generate aesthetically appealing, photorealistic images. Despite the progress, these models still struggle to produce images that are consistent with the input prompt, oftentimes failing to capture object quantities, relations, and attributes properly.
Existing solutions to improve prompt-image consistency suffer from the following challenges: (1) they oftentimes require model fine-tuning, (2) they only focus on nearby prompt samples, and (3) they are affected by unfavorable trade-offs among image quality, representation diversity, and prompt-image consistency.
In this paper, we address these challenges and introduce a T2I optimization-by-prompting framework, OPT2I, which leverages a large language model (LLM) to improve prompt-image consistency in T2I models. Our framework starts from a user prompt and iteratively generates revised prompts with the goal of maximizing a consistency score.
Our extensive validation on two datasets, MSCOCO and PartiPrompts, shows that OPT2I can boost the initial consistency score by up to 24.9% in terms of DSG score while preserving the FID and increasing the recall between generated and real data. Our work paves the way toward building more reliable and robust T2I systems by harnessing the power of LLMs.
2.4. VP3D: Unleashing 2D Visual Prompt for Text-to-3D Generation

Recent innovations in text-to-3D generation have featured Score Distillation Sampling (SDS), which enables the zero-shot learning of implicit 3D models (NeRF) by directly distilling prior knowledge from 2D diffusion models.
However, current SDS-based models still struggle with intricate text prompts and commonly result in distorted 3D models with unrealistic textures or cross-view inconsistency issues. In this work, we introduce a novel Visual Prompt-guided text-to-3D diffusion model (VP3D) that explicitly unleashes the visual appearance knowledge in 2D visual prompts to boost text-to-3D generation.
Instead of solely supervising SDS with text prompts, VP3D first capitalizes on the 2D diffusion model to generate a high-quality image from the input text, which subsequently acts as a visual prompt to strengthen SDS optimization with explicit visual appearance. Meanwhile, we couple the SDS optimization with an additional differentiable reward function that encourages rendering images of 3D models to better visually align with 2D visual prompt and semantically match with text prompt.
Through extensive experiments, we show that the 2D Visual Prompt in our VP3D significantly eases the learning of the visual appearance of 3D models and thus leads to higher visual fidelity with more detailed textures. It is also appealing in view that when replacing the self-generating visual prompt with a given reference image, VP3D can trigger a new task of stylized text-to-3D generation.
2.5. Garment3DGen: 3D Garment Stylization and Texture Generation

We introduce Garment3DGen a new method to synthesize 3D garment assets from a base mesh given a single input image as guidance. Our proposed approach allows users to generate 3D textured clothes based on both real and synthetic images, such as those generated by text prompts.
The generated assets can be directly draped and simulated on human bodies. First, we leverage the recent progress of image to 3D diffusion methods to generate 3D garment geometries.
However, since these geometries cannot be utilized directly for downstream tasks, we propose to use them as pseudo ground truth and set up a mesh deformation optimization procedure that deforms a base template mesh to match the generated 3D target.
Second, we introduce carefully designed losses that allow the input base mesh to freely deform towards the desired target, yet preserve mesh quality and topology such that they can be simulated.
Finally, a texture estimation module generates high-fidelity texture maps that are globally and locally consistent and faithfully capture the input guidance, allowing us to render the generated 3D assets. With Garment3DGen users can generate the textured 3D garment of their choice without the need for artist intervention.
One can provide a textual prompt describing the garment they desire to generate a simulation-ready 3D asset. We present a plethora of quantitative and qualitative comparisons on various assets both real and generated and provide use cases of how one can generate simulation-ready 3D garments.
2.6. TextCraftor: Your Text Encoder Can be an Image Quality Controller

Diffusion-based text-to-image generative models, e.g., Stable Diffusion, have revolutionized the field of content generation, enabling significant advancements in areas like image editing and video synthesis. Despite their formidable capabilities, these models are not without their limitations.
It is still challenging to synthesize an image that aligns well with the input text, and multiple runs with carefully crafted prompts are required to achieve satisfactory results. To mitigate these limitations, numerous studies have endeavored to fine-tune the pre-trained diffusion models, i.e., UNet, utilizing various technologies.
Yet, amidst these efforts, a pivotal question of text-to-image diffusion model training has remained largely unexplored: Is it possible and feasible to fine-tune the text encoder to improve the performance of text-to-image diffusion models?
Our findings reveal that, instead of replacing the CLIP text encoder used in Stable Diffusion with other large language models, we can enhance it through our proposed fine-tuning approach, TextCraftor, leading to substantial improvements in quantitative benchmarks and human assessments.
Interestingly, our technique also empowers controllable image generation through the interpolation of different text encoders fine-tuned with various rewards. We also demonstrate that TextCraftor is orthogonal to UNet finetuning, and can be combined to further improve generative quality.
2.7. Gamba: Marry Gaussian Splatting with Mamba for single-view 3D reconstruction

We tackle the challenge of efficiently reconstructing a 3D asset from a single image with growing demands for automated 3D content creation pipelines. Previous methods primarily rely on Score Distillation Sampling (SDS) and Neural Radiance Fields (NeRF).
Despite their significant success, these approaches encounter practical limitations due to lengthy optimization and considerable memory usage. In this report, we introduce Gamba, an end-to-end amortized 3D reconstruction model from single-view images, emphasizing two main insights:
3D representation: leveraging a large number of 3D Gaussians for an efficient 3D Gaussian splatting process
Backbone design: introducing a Mamba-based sequential network that facilitates context-dependent reasoning and linear scalability with the sequence (token) length, accommodating a substantial number of Gaussians.
Gamba incorporates significant advancements in data preprocessing, regularization design, and training methodologies. We assessed Gamba against existing optimization-based and feed-forward 3D generation approaches using the real-world scanned OmniObject3D dataset.
Here, Gamba demonstrates competitive generation capabilities, both qualitatively and quantitatively, while achieving remarkable speed, approximately 0.6 seconds on a single NVIDIA A100 GPU.
3. Video Understanding & Generation
3.1. InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding

We introduce InternVideo2, a new video foundation model (ViFM) that achieves state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue.
Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction.
Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text.
We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks.
Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts.
3.2. VidLA: Video-Language Alignment at Scale

In this paper, we propose VidLA, an approach for video-language alignment at scale. There are two major limitations of previous video-language alignment approaches.
First, they do not capture both short-range and long-range temporal dependencies and typically employ complex hierarchical deep network architectures that are hard to integrate with existing pretrained image-text foundation models.
To effectively address this limitation, we instead keep the network architecture simple and use a set of data tokens that operate at different temporal resolutions in a hierarchical manner, accounting for the temporally hierarchical nature of videos.
By employing a simple two-tower architecture, we are able to initialize our video-language model with pretrained image-text foundation models, thereby boosting the final performance.
Second, existing video-language alignment works struggle due to the lack of semantically aligned large-scale training data. To overcome it, we leverage recent LLMs to curate the largest video-language dataset to date with better visual grounding.
Furthermore, unlike existing video-text datasets which only contain short clips, our dataset is enriched with video clips of varying durations to aid our temporally hierarchical data tokens in extracting better representations at varying temporal scales.
Overall, empirical results show that our proposed approach surpasses state-of-the-art methods on multiple retrieval benchmarks, especially on longer videos, and performs competitively on classification benchmarks.
3.3. StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text

Text-to-video diffusion models enable the generation of high-quality videos that follow text instructions, making it easy to create diverse and individual content. However, existing approaches mostly focus on high-quality short video generation (typically 16 or 24 frames), ending up with hard cuts when naively extended to the case of long video synthesis.
To overcome these limitations, we introduce StreamingT2V, an autoregressive approach for long video generation of 80, 240, 600, 1200, or more frames with smooth transitions.
The key components are:
A short-term memory block called conditional attention module (CAM), conditions the current generation of the features extracted from the previous chunk via an attentional mechanism, leading to consistent chunk transitions
A long-term memory block called the appearance preservation module, extracts high-level scene and object features from the first video chunk to prevent the model from forgetting the initial scene
A randomized blending approach enables the application of a video enhancer autoregressively for infinitely long videos without inconsistencies between chunks.
Experiments show that StreamingT2V generates a high motion amount. In contrast, all competing image-to-video methods are prone to video stagnation when applied naively in an autoregressive manner. Thus, we propose StreamingT2V a high-quality seamless text-to-long video generator that outperforms competitors with consistency and motion.
4. Image Recognition
4.1. ViTAR: Vision Transformer with Any Resolution

This paper tackles a significant challenge faced by Vision Transformers (ViTs): their constrained scalability across different image resolutions. Typically, ViTs experience a performance decline when processing resolutions different from those seen during training. Our work introduces two key innovations to address this issue.
Firstly, we propose a novel module for dynamic resolution adjustment, designed with a single Transformer block, specifically to achieve highly efficient incremental token integration.
Secondly, we introduce fuzzy positional encoding in the Vision Transformer to provide consistent positional awareness across multiple resolutions, thereby preventing overfitting to any single training resolution.
Our resulting model, ViTAR (Vision Transformer with Any Resolution), demonstrates impressive adaptability, achieving 83.3\% top-1 accuracy at an 1120x1120 resolution and 80.4\% accuracy at a 4032x4032 resolution, all while reducing computational costs.
ViTAR also shows strong performance in downstream tasks such as instance and semantic segmentation and can easily combined with self-supervised learning techniques like Masked AutoEncoder.
Our work provides a cost-effective solution for enhancing the resolution scalability of ViTs, paving the way for more versatile and efficient high-resolution image processing.
4.2. SiMBA: Simplified Mamba-Based Architecture for Vision and Multivariate Time series

Transformers have widely adopted attention networks for sequence mixing and MLPs for channel mixing, playing a pivotal role in achieving breakthroughs across domains.
However, recent literature highlights issues with attention networks, including low inductive bias and quadratic complexity concerning input sequence length. State Space Models (SSMs) like S4 and others (Hippo, Global Convolutions, liquid S4, LRU, Mega, and Mamba), have emerged to address the above issues to help handle longer sequence lengths.
Mamba, while being the state-of-the-art SSM, has a stability issue when scaled to large networks for computer vision datasets. We propose SiMBA, a new architecture that introduces Einstein FFT (EinFFT) for channel modeling by specific eigenvalue computations and uses the Mamba block for sequence modeling.
Extensive performance studies across image and time-series benchmarks demonstrate that SiMBA outperforms existing SSMs, bridging the performance gap with state-of-the-art transformers.
Notably, SiMBA establishes itself as the new state-of-the-art SSM on ImageNet and transfer learning benchmarks such as Stanford Car and Flower as well as task learning benchmarks as well as seven time series benchmark datasets.
4.3. DragAPart: Learning a Part-Level Motion Prior for Articulated Objects
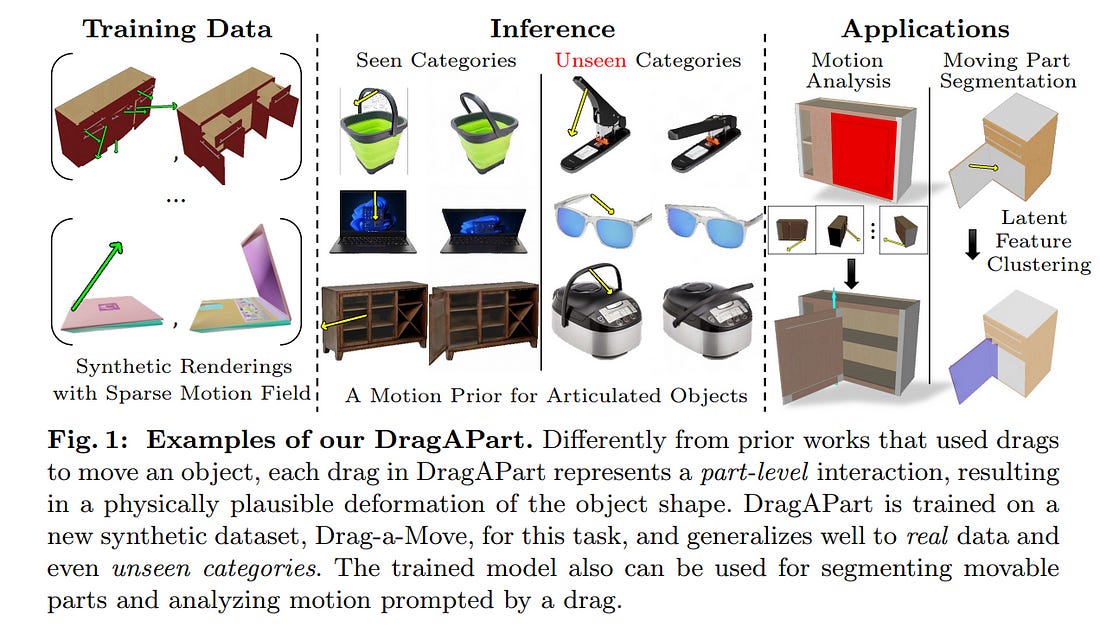
We introduce DragAPart, a method that, given an image and a set of drags as input, can generate a new image of the same object in a new state, compatible with the action of the drags.
Differently from prior works that focused on repositioning objects, DragAPart predicts part-level interactions, such as opening and closing a drawer. We study this problem as a proxy for learning a generalist motion model, not restricted to a specific kinematic structure or object category.
To this end, we start from a pre-trained image generator and fine-tune it on a new synthetic dataset, Drag-a-Move, which we introduce. Combined with a new encoding for the drags and dataset randomization, the new model generalizes well to real images and different categories. Compared to prior motion-controlled generators, we demonstrate much better part-level motion understanding.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
