


Top Important Computer Vision Papers for the Week from 10/06 to 16/06
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Second Week of June 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. Diffusion Models
1.1. Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation

We introduce LlamaGen, a new family of image generation models that apply the original ``next-token prediction’’ paradigm of large language models to the visual generation domain. It is an affirmative answer to whether vanilla autoregressive models, e.g., Llama, without inductive biases on visual signals can achieve state-of-the-art image generation performance if scaled properly.
We reexamine the design spaces of image tokenizers, the scalability properties of image generation models, and their training data quality. The outcome of this exploration consists of:
An image tokenizer with a downsampling ratio of 16, reconstruction quality of 0.94 rFID, and codebook usage of 97% on ImageNet benchmark.
A series of class-conditional image generation models ranging from 111M to 3.1B parameters, achieving 2.18 FID on ImageNet 256x256 benchmarks, outperforming the popular diffusion models such as LDM, and DiT.
A text-conditional image generation model with 775M parameters, from two-stage training on LAION-COCO and high aesthetics quality images, demonstrating the competitive performance of visual quality and text alignment.
We verify the effectiveness of LLM serving frameworks in optimizing the inference speed of image generation models and achieve 326% — 414% speedup.
1.2. Margin-aware Preference Optimization for Aligning Diffusion Models without Reference

Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model.
In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this “reference mismatch” is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy.
Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that do not depend on any reference model, coined margin-aware preference optimization (MaPO).
MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets and the likelihood of the preferred sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style, and Pick-Safety, simulating diverse scenarios of reference mismatch.
Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety and general preference alignment when used with Pick-a-Pic v2, surpassing the base SDXL and other existing methods.
1.3. MLCM: Multistep Consistency Distillation of Latent Diffusion Model

Distilling large latent diffusion models (LDMs) into ones that are fast to sample from is attracting growing research interest. However, the majority of existing methods face a dilemma where they either (i) depend on multiple individual distilled models for different sampling budgets, or (ii) sacrifice generation quality with limited (e.g., 2–4) and/or moderate sampling steps.
To address these, we extend the recent multistep consistency distillation (MCD) strategy to representative LDMs, establishing the Multistep Latent Consistency Models (MLCMs) approach for low-cost high-quality image synthesis. MLCM serves as a unified model for various sampling steps due to the promise of MCD.
We further augment MCD with a progressive training strategy to strengthen inter-segment consistency to boost the quality of few-step generations. We take the states from the sampling trajectories of the teacher model as training data for MLCMs to lift the requirements for high-quality training datasets and to bridge the gap between the training and inference of the distilled model.
MLCM is compatible with preference learning strategies for further improvement of visual quality and aesthetic appeal. Empirically, MLCM can generate high-quality, delightful images with only 2–8 sampling steps.
On the MSCOCO-2017 5K benchmark, MLCM distilled from SDXL gets a CLIP Score of 33.30, Aesthetic Score of 6.19, and Image Reward of 1.20 with only 4 steps, substantially surpassing 4-step LCM, 8-step SDXL-Lightning, and 8-step HyperSD. We also demonstrate the versatility of MLCMs in applications including controllable generation, image style transfer, and Chinese-to-image generation.
1.4. AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising

Diffusion models have garnered significant interest from the community for their great generative ability across various applications. However, their typical multi-step sequential-denoising nature gives rise to high cumulative latency, thereby precluding the possibilities of parallel computation.
To address this, we introduce AsyncDiff, a universal and plug-and-play acceleration scheme that enables model parallelism across multiple devices. Our approach divides the cumbersome noise prediction model into multiple components, assigning each to a different device.
To break the dependency chain between these components, it transforms the conventional sequential denoising into an asynchronous process by exploiting the high similarity between hidden states in consecutive diffusion steps. Consequently, each component is facilitated to compute in parallel on separate devices.
The proposed strategy significantly reduces inference latency while minimally impacting the generative quality. Specifically, for the Stable Diffusion v2.1, AsyncDiff achieves a 2.7x speedup with negligible degradation and a 4.0x speedup with only a slight reduction of 0.38 in CLIP Score, on four NVIDIA A5000 GPUs.
Our experiments also demonstrate that AsyncDiff can be readily applied to video diffusion models with encouraging performances.
1.5. Simple and Effective Masked Diffusion Language Models

While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling.
In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements.
Our objective has a simple form — it is a mixture of classical masked language modeling losses — and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model.
On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models and approaches AR perplexity.
1.6. Neural Gaffer: Relighting Any Object via Diffusion

Single-image relighting is a challenging task that involves reasoning about the complex interplay between geometry, materials, and lighting. Many prior methods either support only specific categories of images, such as portraits or require special capture conditions, like using a flashlight.
Alternatively, some methods explicitly decompose a scene into intrinsic components, such as normals and BRDFs, which can be inaccurate or under-expressive.
In this work, we propose a novel end-to-end 2D relighting diffusion model, called Neural Gaffer, that takes a single image of any object and can synthesize an accurate, high-quality relit image under any novel environmental lighting condition, simply by conditioning an image generator on a target environment map, without an explicit scene decomposition.
Our method builds on a pre-trained diffusion model, and fine-tunes it on a synthetic relighting dataset, revealing and harnessing the inherent understanding of lighting present in the diffusion model. We evaluate our model on both synthetic and in-the-wild Internet imagery and demonstrate its advantages in terms of generalization and accuracy.
Moreover, by combining with other generative methods, our model enables many downstream 2D tasks, such as text-based relighting and object insertion. Our model can also operate as a strong relighting prior to 3D tasks, such as relighting a radiance field.
1.7. Understanding Hallucinations in Diffusion Models through Mode Interpolation

Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit “hallucinations,” samples that could never occur in the training data. But where do such hallucinations come from? In this paper, we study a particular failure mode in diffusion models, which we term mode interpolation.
Specifically, we find that diffusion models smoothly “interpolate” between nearby data modes in the training set, to generate samples that are completely outside the support of the original training distribution; this phenomenon leads diffusion models to generate artifacts that never existed in real data (i.e., hallucinations).
We systematically study the reasons for, and the manifestation of this phenomenon. Through experiments on 1D and 2D Gaussians, we show how a discontinuous loss landscape in the diffusion model’s decoder leads to a region where any smooth approximation will cause such hallucinations.
Through experiments on artificial datasets with various shapes, we show how hallucination leads to the generation of combinations of shapes that never existed. Finally, we show that diffusion models in fact know when they go out of support and hallucinate.
This is captured by the high variance in the trajectory of the generated sample towards the final few backward sampling processes. Using a simple metric to capture this variance, we can remove over 95% of hallucinations at generation time while retaining 96% of in-support samples.
We conclude our exploration by showing the implications of such hallucination (and its removal) on the collapse (and stabilization) of recursive training on synthetic data with experiments on MNIST and 2D Gaussians datasets.
1.8. Hierarchical Patch Diffusion Models for High-Resolution Video Generation

Diffusion models have demonstrated remarkable performance in image and video synthesis. However, scaling them to high-resolution inputs is challenging and requires restructuring the diffusion pipeline into multiple independent components, limiting scalability and complicating downstream applications.
This makes it very efficient during training and unlocks end-to-end optimization on high-resolution videos. We improve PDMs in two principled ways.
First, to enforce consistency between patches, we develop deep context fusion — an architectural technique that propagates the context information from low-scale to high-scale patches in a hierarchical manner.
Second, to accelerate training and inference, we propose adaptive computation, which allocates more network capacity and computation towards coarse image details. The resulting model sets a new state-of-the-art FVD score of 66.32 and an Inception Score of 87.68 in class-conditional video generation on UCF-101 256², surpassing recent methods by more than 100%.
Then, we show that it can be rapidly fine-tuned from a base 36 times 64 low-resolution generator for high-resolution 64 times 288 times 512 text-to-video synthesis. To the best of our knowledge, our model is the first diffusion-based architecture that is trained on such high resolutions entirely end-to-end.
1.9. Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models

This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization. Diffusion models have gained prominence for their effectiveness in high-fidelity image generation.
While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability. However, Transformer architectures, which tokenize input data (via “patchification”), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length.
While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions. To address this challenge, we propose augmenting the Diffusion model with the Multi-Resolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution.
Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance.
Our method’s efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants outperform prior diffusion models, setting new state-of-the-art FID scores of 1.70 on ImageNet 256 x 256 and 2.89 on ImageNet 512 x 512.
1.10. DiTFastAttn: Attention Compression for Diffusion Transformer Models

Diffusion Transformers (DiT) excel at image and video generation but face computational challenges due to self-attention’s quadratic complexity. We propose DiTFastAttn, a novel post-training compression method to alleviate DiT’s computational bottleneck.
We identify three key redundancies in the attention computation during DiT inference:
Spatial redundancy, where many attention heads focus on local information.
Temporal redundancy, with high similarity between neighboring steps’ attention outputs.
Conditional redundancy, where conditional and unconditional inferences exhibit significant similarity. T
To tackle these redundancies, we propose three techniques:
Window Attention with Residual Caching to reduce spatial redundancy.
Temporal Similarity Reduction to exploit the similarity between steps.
Conditional Redundancy Elimination to skip redundant computations during conditional generation.
To demonstrate the effectiveness of DiTFastAttn, we apply it to DiT, PixArt-Sigma for image generation tasks, and OpenSora for video generation tasks. Evaluation results show that for image generation, our method reduces up to 88\% of the FLOPs and achieves up to 1.6x speedup at high-resolution generation.
1.11. Simplified and Generalized Masked Diffusion for Discrete Data
Masked (or absorbing) diffusion is actively explored as an alternative to autoregressive models for generative modeling of discrete data. However, existing work in this area has been hindered by unnecessarily complex model formulations and unclear relationships between different perspectives, leading to suboptimal parameterization, training objectives, and ad hoc adjustments to counteract these issues.
In this work, we aim to provide a simple and general framework that unlocks the full potential of masked diffusion models. We show that the continuous-time variational objective of masked diffusion models is a simple weighted integral of cross-entropy losses. Our framework also enables training generalized masked diffusion models with state-dependent masking schedules.
When evaluated by perplexity, our models trained on OpenWebText surpass prior diffusion language models at the GPT-2 scale and demonstrate superior performance on 4 out of 5 zero-shot language modeling tasks.
Furthermore, our models vastly outperform previous discrete diffusion models on pixel-level image modeling, achieving 2.78~(CIFAR-10) and 3.42 (ImageNet 64times64) bits per dimension that are comparable or better than autoregressive models of similar sizes.
1.12. FontStudio: Shape-Adaptive Diffusion Model for Coherent and Consistent Font Effect Generation

Recently, the application of modern diffusion-based text-to-image generation models for creating artistic fonts, traditionally the domain of professional designers, has garnered significant interest.
Diverging from the majority of existing studies that concentrate on generating artistic typography, our research aims to tackle a novel and more demanding challenge: the generation of text effects for multilingual fonts.
This task essentially requires generating coherent and consistent visual content within the confines of a font-shaped canvas, as opposed to a traditional rectangular canvas. To address this task, we introduce a novel shape-adaptive diffusion model capable of interpreting the given shape and strategically planning pixel distributions within the irregular canvas.
To achieve this, we curate a high-quality shape-adaptive image-text dataset and incorporate the segmentation mask as a visual condition to steer the image generation process within the irregular canvas. This approach enables the traditional rectangle canvas-based diffusion model to produce the desired concepts by the provided geometric shapes.
Second, to maintain consistency across multiple letters, we also present a training-free, shape-adaptive effect transfer method for transferring textures from a generated reference letter to others. The key insights are building a font effect noise prior and propagating the font effect information in a concatenated latent space.
The efficacy of our FontStudio system is confirmed through user preference studies, which show a marked preference (78% win rates on aesthetics) for our system even when compared to the latest unrivaled commercial product, Adobe Firefly.
2. Vision Language Models (VLMs)
2.1. An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels

This work does not introduce a new method. Instead, we present an interesting finding that questions the necessity of the inductive bias — locality in modern computer vision architectures.
Concretely, we find that vanilla Transformers can operate by directly treating each pixel as a token and achieve highly performant results. This is substantially different from the popular design in Vision Transformer, which maintains the inductive bias from ConvNets towards local neighborhoods (e.g. by treating each 16x16 patch as a token).
We mainly showcase the effectiveness of pixels-as-tokens across three well-studied tasks in computer vision: supervised learning for object classification, self-supervised learning via masked autoencoding, and image generation with diffusion models.
Although directly operating on individual pixels is less computationally practical, we believe the community must be aware of this surprising piece of knowledge when devising the next generation of neural architectures for computer vision.
2.2. OpenVLA: An Open-Source Vision-Language-Action Model

Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control.
Yet, the widespread adoption of VLAs for robotics has been challenging as
Existing VLAs are largely closed and inaccessible to the public, and
Prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption.
Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP.
As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters.
We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%.
We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
2.3. Commonsense-T2I Challenge: Can Text-to-Image Generation Models Understand Commonsense?

We present a novel task and benchmark for evaluating the ability of text-to-image(T2I) generation models to produce images that fit common in real life, which we call Commonsense-T2I.
Given two adversarial text prompts containing an identical set of action words with minor differences, such as “a lightbulb without electricity” v.s. “a lightbulb with electricity”, we evaluate whether T2I models can conduct visual-commonsense reasoning, e.g. produce images that fit “the lightbulb is unlit” vs. “the lightbulb is lit” correspondingly.
Commonsense-T2I presents an adversarial challenge, providing pairwise text prompts along with expected outputs. The dataset is carefully hand-curated by experts and annotated with fine-grained labels, such as commonsense type and likelihood of the expected outputs, to assist in analyzing model behavior.
We benchmark a variety of state-of-the-art (SOTA) T2I models and surprisingly find that, there is still a large gap between image synthesis and real-life photos — even the DALL-E 3 model could only achieve 48.92% on Commonsense-T2I, and the stable diffusion XL model only achieves 24.92% accuracy.
Our experiments show that GPT-enriched prompts cannot solve this challenge, and we include a detailed analysis of possible reasons for such deficiency. We aim for Commonsense-T2I to serve as a high-quality evaluation benchmark for T2I commonsense checking, fostering advancements in real-life image generation.
2.4. MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding

We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations).
Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment.
Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy.
Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.
3. Image Generation & Editing
3.1. GTR: Improving Large 3D Reconstruction Models through Geometry and Texture Refinement
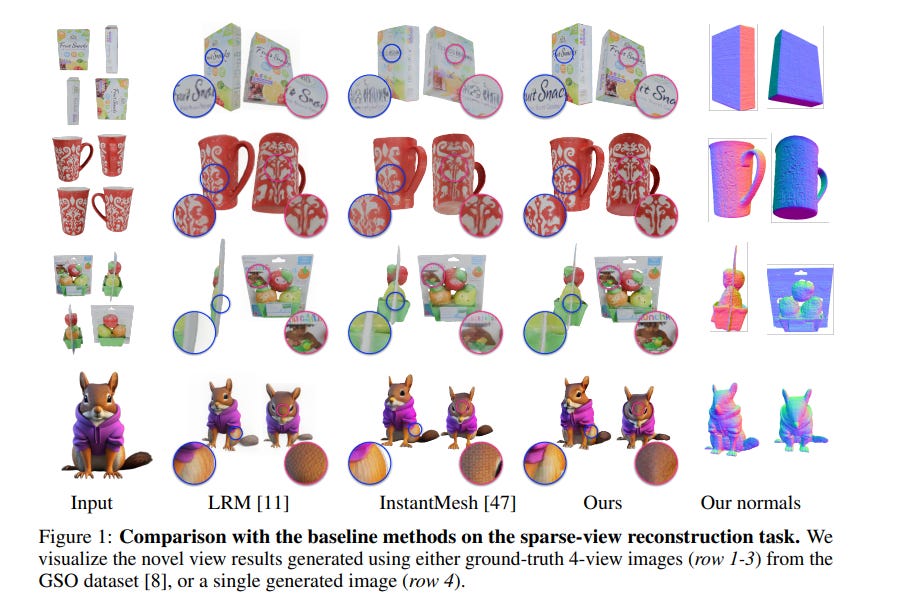
We propose a novel approach for 3D mesh reconstruction from multi-view images. Our method takes inspiration from large reconstruction models like LRM that use a transformer-based triplane generator and a Neural Radiance Field (NeRF) model trained on multi-view images.
However, in our method, we introduce several important modifications that allow us to significantly enhance 3D reconstruction quality. First of all, we examine the original LRM architecture and find several shortcomings. Subsequently, we introduce respective modifications to the LRM architecture, which lead to improved multi-view image representation and more computationally efficient training.
Second, in order to improve geometry reconstruction and enable supervision at full image resolution, we extract meshes from the NeRF field in a differentiable manner and fine-tune the NeRF model through mesh rendering. These modifications allow us to achieve state-of-the-art performance on both 2D and 3D evaluation metrics, such as a PSNR of 28.67 on Google Scanned Objects (GSO) dataset.
Despite these superior results, our feed-forward model still struggles to reconstruct complex textures, such as text and portraits on assets. To address this, we introduce a lightweight per-instance texture refinement procedure. This procedure fine-tunes the triplane representation and the NeRF color estimation model on the mesh surface using the input multi-view images in just 4 seconds.
This refinement improves the PSNR to 29.79 and achieves faithful reconstruction of complex textures, such as text. Additionally, our approach enables various downstream applications, including text- or image-to-3D generation.
3.2. IllumiNeRF: 3D Relighting without Inverse Rendering

Existing methods for relightable view synthesis — using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination — are based on inverse rendering, and attempt to disentangle the object geometry, materials, and lighting that explain the input images.
Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally expensive. In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on lighting and then reconstruct a Neural Radiance Field (NeRF) with these relit images, from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks.
3.3. Unified Text-to-Image Generation and Retrieval

How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity.
By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs).
Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query.
Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.
3.4. An Image is Worth 32 Tokens for Reconstruction and Generation

Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process.
Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities.
To overcome this issue, we introduce a Transformer-based 1-Dimensional Tokenizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TikTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques.
For example, a 256 x 256 x 3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains 1.97 gFID, outperforming MaskGIT baseline significantly by 4.21 at the ImageNet 256 x 256 benchmark.
The advantages of TiTok become even more significant when it comes to higher resolution. At the ImageNet 512 x 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04) but also reduces the image tokens by 64x, leading to a 410x faster generation process. Our best-performing variant can significantly surpass DiT-XL/2 (gFID 2.13 vs. 3.04) while still generating high-quality samples 74x faster.
3.5. Zero-shot Image Editing with Reference Imitation

Image editing serves as a practical yet challenging task considering the diverse demands of users, where one of the hardest parts is to precisely describe how the edited image should look like.
In this work, we present a new form of editing, termed imitative editing, to help users exercise their creativity more conveniently. Concretely, to edit an image region of interest, users are free to directly draw inspiration from some in-the-wild references (e.g., some relative pictures come across online), without having to cope with the fit between the reference and the source.
Such a design requires the system to automatically figure out what to expect from the reference to perform the editing. For this purpose, we propose a generative training framework, dubbed MimicBrush, which randomly selects two frames from a video clip, masks some regions of one frame, and learns to recover the masked regions using the information from the other frame.
That way, our model, developed from a diffusion prior, can capture the semantic correspondence between separate images in a self-supervised manner. We experimentally show the effectiveness of our method under various test cases as well as its superiority over existing alternatives. We also construct a benchmark to facilitate further research.
3.6. Toffee: Efficient Million-Scale Dataset Construction for Subject-Driven Text-to-Image Generation

In subject-driven text-to-image generation, recent works have achieved superior performance by training the model on synthetic datasets containing numerous image pairs.
Trained on these datasets, generative models can produce text-aligned images for specific subjects from arbitrary testing images in a zero-shot manner. They even outperform methods that require additional fine-tuning on testing images.
However, the cost of creating such datasets is prohibitive for most researchers. To generate a single training pair, current methods fine-tune a pre-trained text-to-image model on the subject image to capture fine-grained details, then use the fine-tuned model to create images for the same subject based on creative text prompts.
Consequently, constructing a large-scale dataset with millions of subjects can require hundreds of thousands of GPU hours. To tackle this problem, we propose Toffee, an efficient method to construct datasets for subject-driven editing and generation.
Specifically, our dataset construction does not need any subject-level fine-tuning. After pre-training two generative models, we are able to generate an infinite number of high-quality samples. We construct the first large-scale dataset for subject-driven image editing and generation, which contains 5 million image pairs, text prompts, and masks.
Our dataset is 5 times the size of the previous largest dataset, yet our cost is tens of thousands of GPU hours lower. To test the proposed dataset, we also propose a model that is capable of both subject-driven image editing and generation. By simply training the model on our proposed dataset, it obtains competitive results, illustrating the effectiveness of the proposed dataset construction framework.
4. Video Understanding, Editing & Generation
4.1. Vript: A Video Is Worth Thousands of Words

Advancements in multimodal learning, particularly in video understanding and generation, require high-quality video-text datasets for improved model performance. Vript addresses this issue with a meticulously annotated corpus of 12K high-resolution videos, offering detailed, dense, and script-like captions for over 420K clips.
Each clip has a caption of ~145 words, which is over 10x longer than most video-text datasets. Unlike captions only documenting static content in previous datasets, we enhance video captioning to video scripting by documenting not just the content, but also the camera operations, which include the shot types (medium shot, close-up, etc) and camera movements (panning, tilting, etc).
By utilizing the Vript, we explore three training paradigms of aligning more text with the video modality rather than clip-caption pairs. This results in Vriptor, a top-performing video captioning model among open-source models, comparable to GPT-4V in performance.
Vriptor is also a powerful model capable of end-to-end generation of dense and detailed captions for long videos. Moreover, we introduce Vript-Hard, a benchmark consisting of three video understanding tasks that are more challenging than existing benchmarks: Vript-HAL is the first benchmark evaluating action and object hallucinations in video LLMs, Vript-RR combines reasoning with retrieval resolving question ambiguity in long-video QAs, and Vript-ERO is a new task to evaluate the temporal understanding of events in long videos rather than actions in short videos in previous works.
4.2. MotionClone: Training-Free Motion Cloning for Controllable Video Generation

Motion-based controllable text-to-video generation involves motions to control the video generation. Previous methods typically require the training of models to encode motion cues or the fine-tuning of video diffusion models.
However, these approaches often result in suboptimal motion generation when applied outside the trained domain. In this work, we propose MotionClone, a training-free framework that enables motion cloning from a reference video to control text-to-video generation.
We employ temporal attention in video inversion to represent the motions in the reference video and introduce primary temporal-attention guidance to mitigate the influence of noisy or very subtle motions within the attention weights.
Furthermore, to assist the generation model in synthesizing reasonable spatial relationships and enhance its prompt-following capability, we propose a location-aware semantic guidance mechanism that leverages the coarse location of the foreground from the reference video and original classifier-free guidance features to guide the video generation.
Extensive experiments demonstrate that MotionClone exhibits proficiency in both global camera motion and local object motion, with notable superiority in terms of motion fidelity, textual alignment, and temporal consistency.
4.3. MMWorld: Towards Multi-discipline Multi-faceted World Model Evaluation in Videos

Multimodal Language Language Models (MLLMs) demonstrate the emerging abilities of “world models” — interpreting and reasoning about complex real-world dynamics. To assess these abilities, we posit videos are the ideal medium, as they encapsulate rich representations of real-world dynamics and causalities.
To this end, we introduce MMWorld, a new benchmark for multi-discipline, multi-faceted multimodal video understanding. MMWorld distinguishes itself from previous video understanding benchmarks with two unique advantages:
Multi-discipline, covering various disciplines that often require domain expertise for comprehensive understanding.
Multi-faceted reasoning, including explanation, counterfactual thinking, future prediction, etc.
MMWorld consists of a human-annotated dataset to evaluate MLLMs with questions about the whole video and a synthetic dataset to analyze MLLMs within a single modality of perception. Together, MMWorld encompasses 1,910 videos across seven broad disciplines and 69 subdisciplines, complete with 6,627 question-answer pairs and associated captions.
The evaluation includes 2 proprietary and 10 open-source MLLMs, which struggle on MMWorld (e.g., GPT-4V performs the best with only 52.3\% accuracy), showing large room for improvement.
Further ablation studies reveal other interesting findings such as models’ different skill sets from humans. We hope MMWorld can serve as an essential step toward world model evaluation in videos.
4.4. NaRCan: Natural Refined Canonical Image with Integration of Diffusion Prior to Video Editing

We propose a video editing framework, NaRCan, which integrates a hybrid deformation field and diffusion prior to generating high-quality natural canonical images to represent the input video.
Our approach utilizes homography to model global motion and employs multi-layer perceptrons (MLPs) to capture local residual deformations, enhancing the model’s ability to handle complex video dynamics.
By introducing a diffusion prior to the early stages of training, our model ensures that the generated images retain a high-quality natural appearance, making the produced canonical images suitable for various downstream tasks in video editing, a capability not achieved by current canonical-based methods.
Furthermore, we incorporate low-rank adaptation (LoRA) fine-tuning and introduce a noise and diffusion prior update scheduling technique that accelerates the training process by 14 times. Extensive experimental results show that our method outperforms existing approaches in various video editing tasks and produces coherent and high-quality edited video sequences.
4.5. TC-Bench: Benchmarking Temporal Compositionality in Text-to-Video and Image-to-Video Generation

Video generation has many unique challenges beyond those of image generation. The temporal dimension introduces extensive possible variations across frames, over which consistency and continuity may be violated.
In this study, we move beyond evaluating simple actions and argue that generated videos should incorporate the emergence of new concepts and their relation transitions like in real-world videos as time progresses. To assess the Temporal Compositionality of video generation models, we propose TC-Bench, a benchmark of meticulously crafted text prompts, corresponding ground truth videos, and robust evaluation metrics.
The prompts articulate the initial and final states of scenes, effectively reducing ambiguities for frame development and simplifying the assessment of transition completion.
In addition, by collecting aligned real-world videos corresponding to the prompts, we expand TC-Bench’s applicability from text-conditional models to image-conditional ones that can perform generative frame interpolation. We also develop new metrics to measure the completeness of component transitions in generated videos, which demonstrate significantly higher correlations with human judgments than existing metrics.
Our comprehensive experimental results reveal that most video generators achieve less than 20% of the compositional changes, highlighting enormous space for future improvement. Our analysis indicates that current video generation models struggle to interpret descriptions of compositional changes and synthesize various components across different time steps.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
