


Top Important Computer Vision Papers for the Week from 02/09 to 08/09
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the First Week of September 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
Text to Image Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. VQ4DiT: Efficient Post-Training Vector Quantization for Diffusion Transformers
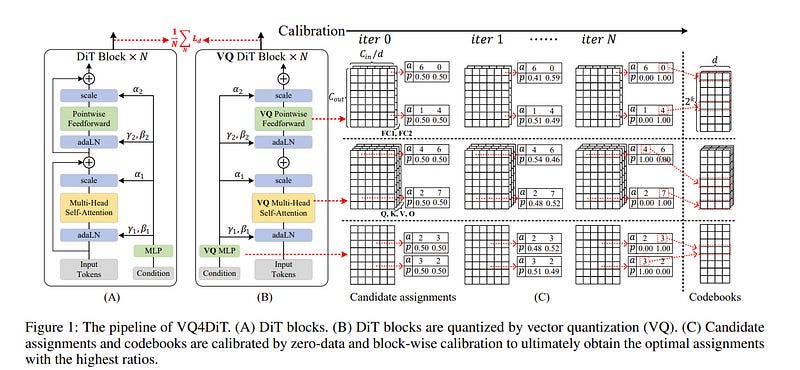
The Diffusion Transformers Models (DiTs) have transitioned the network architecture from traditional UNets to transformers, demonstrating exceptional capabilities in image generation. Although DiTs have been widely applied to high-definition video generation tasks, their large parameter size hinders inference on edge devices.
Vector quantization (VQ) can decompose model weight into a codebook and assignments, allowing extreme weight quantization and significantly reducing memory usage. In this paper, we propose VQ4DiT, a fast post-training vector quantization method for DiTs. We found that traditional VQ methods calibrate only the codebook without calibrating the assignments.
This leads to weight sub-vectors being incorrectly assigned to the same assignment, providing inconsistent gradients to the codebook and resulting in a suboptimal result.
To address this challenge, VQ4DiT calculates the candidate assignment set for each weight sub-vector based on Euclidean distance and reconstructs the sub-vector based on the weighted average. Then, using the zero-data and block-wise calibration method, the optimal assignment from the set is efficiently selected while calibrating the codebook.
VQ4DiT quantizes a DiT XL/2 model on a single NVIDIA A100 GPU within 20 minutes to 5 hours depending on the different quantization settings. Experiments show that VQ4DiT establishes a new state-of-the-art in model size and performance trade-offs, quantizing weights to 2-bit precision while retaining acceptable image generation quality.
1.2. Geometry Image Diffusion: Fast and Data-Efficient Text-to-3D with Image-Based Surface Representation

Generating high-quality 3D objects from textual descriptions remains a challenging problem due to computational cost, the scarcity of 3D data, and complex 3D representations.
We introduce Geometry Image Diffusion (GIMDiffusion), a novel Text-to-3D model that utilizes geometry images to efficiently represent 3D shapes using 2D images, thereby avoiding the need for complex 3D-aware architectures.
By integrating a Collaborative Control mechanism, we exploit the rich 2D priors of existing Text-to-Image models such as Stable Diffusion. This enables strong generalization even with limited 3D training data (allowing us to use only high-quality training data) as well as retaining compatibility with guidance techniques such as IPAdapter.
In short, GIMDiffusion enables the generation of 3D assets at speeds comparable to current Text-to-Image models. The generated objects consist of semantically meaningful, separate parts and include internal structures, enhancing both usability and versatility.
2. Vision Language Models (VLMs)
2.1. mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding

Multimodel Large Language Models(MLLMs) have achieved promising OCR-free Document Understanding performance by increasing the supported resolution of document images.
However, this comes at the cost of generating thousands of visual tokens for a single document image, leading to excessive GPU memory and slower inference times, particularly in multi-page document comprehension.
In this work, to address these challenges, we propose a High-resolution DocCompressor module to compress each high-resolution document image into 324 tokens, guided by low-resolution global visual features.
With this compression module, to strengthen multi-page document comprehension ability and balance both token efficiency and question-answering performance, we develop the DocOwl2 under a three-stage training framework: Single-image Pretraining, Multi-image Continue-pretraining, and Multi-task Finetuning.
DocOwl2 sets new state-of-the-art across multi-page document understanding benchmarks and reduces first token latency by more than 50%, demonstrating advanced capabilities in multi-page questioning answering, explanation with evidence pages, and cross-page structure understanding.
Additionally, compared to single-image MLLMs trained on similar data, our DocOwl2 achieves comparable single-page understanding performance with less than 20% of the visual tokens.
2.2. VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters

Foundation models have emerged as a promising approach in time series forecasting (TSF). Existing approaches either fine-tune large language models (LLMs) or build large-scale time-series datasets to develop TSF foundation models. However, these methods face challenges due to the severe cross-domain gap or in-domain heterogeneity.
In this paper, we explore a new road to building a TSF foundation model from rich and high-quality natural images, based on the intrinsic similarities between images and time series. To bridge the gap between the two domains, we reformulate the TSF task as an image reconstruction task, which is further processed by a visual masked autoencoder (MAE) self-supervised pre-trained on the ImageNet dataset.
Surprisingly, without further adaptation in the time-series domain, the proposed VisionTS could achieve superior zero-shot forecasting performance compared to existing TSF foundation models. With minimal fine-tuning, VisionTS could further improve the forecasting and achieve state-of-the-art performance in most cases.
These findings suggest that visual models could be a free lunch for TSF and highlight the potential for future cross-domain research between computer vision and TSF.
2.3. Kvasir-VQA: A Text-Image Pair GI Tract Dataset
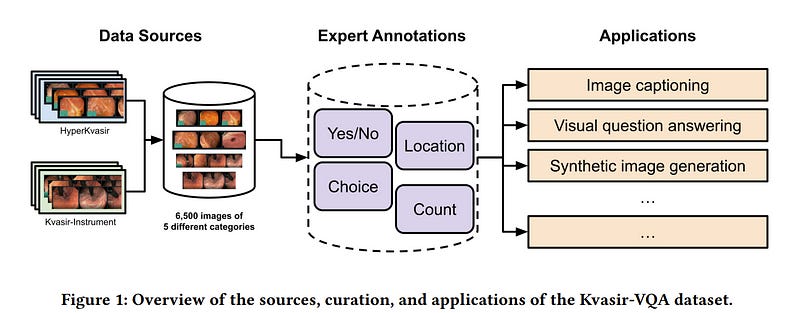
We introduce Kvasir-VQA, an extended dataset derived from the HyperKvasir and Kvasir-Instrument datasets, augmented with question-and-answer annotations to facilitate advanced machine learning tasks in Gastrointestinal (GI) diagnostics.
This dataset comprises 6,500 annotated images spanning various GI tract conditions and surgical instruments, and it supports multiple question types including yes/no, choice, location, and numerical count.
The dataset is intended for applications such as image captioning, Visual Question Answering (VQA), text-based generation of synthetic medical images, object detection, and classification.
Our experiments demonstrate the dataset’s effectiveness in training models for three selected tasks, showcasing significant applications in medical image analysis and diagnostics. We also present evaluation metrics for each task, highlighting the usability and versatility of our dataset.
2.4. LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture

Expanding the long-context capabilities of Multi-modal Large Language Models~(MLLMs) is crucial for video understanding, high-resolution image understanding, and multi-modal agents.
This involves a series of systematic optimizations, including model architecture, data construction, and training strategy, particularly addressing challenges such as degraded performance with more images and high computational costs.
In this paper, we adapt the model architecture to a hybrid of Mamba and Transformer blocks, approach data construction with both temporal and spatial dependencies among multiple images, and employ a progressive training strategy.
The released model LongLLaVA~(Long-Context Large Language and Vision Assistant) is the first hybrid MLLM, which achieved a better balance between efficiency and effectiveness. LongLLaVA not only achieves competitive results across various benchmarks but also maintains high throughput and low memory consumption.
Especially, it could process nearly a thousand images on a single A100 80GB GPU, showing promising application prospects for a wide range of tasks.
3. Video Understanding & Generation
3.1. DepthCrafter: Generating Consistent Long Depth Sequences for Open-world Videos

Despite significant advancements in monocular depth estimation for static images, estimating video depth in the open world remains challenging, since open-world videos are extremely diverse in content, motion, camera movement, and length.
We present DepthCrafter, an innovative method for generating temporally consistent long-depth sequences with intricate details for open-world videos, without requiring any supplementary information such as camera poses or optical flow.
DepthCrafter achieves generalization ability to open-world videos by training a video-to-depth model from a pre-trained image-to-video diffusion model, through our meticulously designed three-stage training strategy with the compiled paired video-depth datasets.
Our training approach enables the model to generate depth sequences with variable lengths at one time, up to 110 frames, and harvest both precise depth details and rich content diversity from realistic and synthetic datasets.
We also propose an inference strategy that processes extremely long videos through segment-wise estimation and seamless stitching. Comprehensive evaluations on multiple datasets reveal that DepthCrafter achieves state-of-the-art performance in open-world video depth estimation under zero-shot settings.
Furthermore, DepthCrafter facilitates various downstream applications, including depth-based visual effects and conditional video generation.
4. Text to Image Generation & Editing
4.1. CoRe: Context-Regularized Text Embedding Learning for Text-to-Image Personalization

Recent advances in text-to-image personalization have enabled high-quality and controllable image synthesis for user-provided concepts. However, existing methods still struggle to balance identity preservation with text alignment.
Our approach is based on the fact that generating prompt-aligned images requires a precise semantic understanding of the prompt, which involves accurately processing the interactions between the new concept and its surrounding context tokens within the CLIP text encoder.
To address this, we aim to embed the new concept properly into the input embedding space of the text encoder, allowing for seamless integration with existing tokens. We introduce Context Regularization (CoRe), which enhances the learning of the new concept’s text embedding by regularizing its context tokens in the prompt.
This is based on the insight that appropriate output vectors of the text encoder for the context tokens can only be achieved if the new concept’s text embedding is correctly learned. CoRe can be applied to arbitrary prompts without requiring the generation of corresponding images, thus improving the generalization of the learned text embedding.
Additionally, CoRe can serve as a test-time optimization technique to further enhance the generations for specific prompts. Comprehensive experiments demonstrate that our method outperforms several baseline methods in both identity preservation and text alignment. The code will be made publicly available.
4.2. LinFusion: 1 GPU, 1 Minute, 16K Image

Modern diffusion models, particularly those utilizing a Transformer-based UNet for denoising, rely heavily on self-attention operations to manage complex spatial relationships, thus achieving impressive generation performance.
However, this existing paradigm faces significant challenges in generating high-resolution visual content due to its quadratic time and memory complexity with respect to the number of spatial tokens. To address this limitation, we aim at a novel linear attention mechanism as an alternative in this paper.
Specifically, we begin our exploration from recently introduced models with linear complexity, e.g., Mamba, Mamba2, and Gated Linear Attention, and identify two key features-attention normalization and non-causal inference-that enhance high-resolution visual generation performance.
Building on these insights, we introduce a generalized linear attention paradigm, which serves as a low-rank approximation of a wide spectrum of popular linear token mixers.
To save the training cost and better leverage pre-trained models, we initialize our models and distill the knowledge from pre-trained StableDiffusion (SD). We find that the distilled model, termed LinFusion, achieves performance on par with or superior to the original SD after only modest training, while significantly reducing time and memory complexity.
Extensive experiments on SD-v1.5, SD-v2.1, and SD-XL demonstrate that LinFusion delivers satisfactory zero-shot cross-resolution generation performance, generating high-resolution images like 16K resolution. Moreover, it is highly compatible with pre-trained SD components, such as ControlNet and IP-Adapter, requiring no adaptation efforts.
4.3. Guide-and-Rescale: Self-Guidance Mechanism for Effective Tuning-Free Real Image Editing

Despite recent advances in large-scale text-to-image generative models, manipulating real images with these models remains a challenging problem.
The main limitations of existing editing methods are that they either fail to perform with consistent quality on a wide range of image edits or require time-consuming hyperparameter tuning or fine-tuning of the diffusion model to preserve the image-specific appearance of the input image. We propose a novel approach that is built upon a modified diffusion sampling process via the guidance mechanism.
In this work, we explore the self-guidance technique to preserve the overall structure of the input image and its local region appearance that should not be edited. In particular, we explicitly introduce layout-preserving energy functions that are aimed to save local and global structures of the source image.
Additionally, we propose a noise rescaling mechanism that allows to preserve noise distribution by balancing the norms of classifier-free guidance and our proposed guiders during generation. Such a guiding approach does not require fine-tuning the diffusion model and exact inversion process.
As a result, the proposed method provides a fast and high-quality editing mechanism. In our experiments, we show through human evaluation and quantitative analysis that the proposed method allows to produce of desired editing which is preferable by humans and also achieves a better trade-off between editing quality and preservation of the original image.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
