


Top Important Computer Vision Papers for the Week from 15/07 to 21/07
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Third Week of July 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
Image Editing & Generation
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. Diffusion Models
1.1. Make-An-Agent: A Generalizable Policy Network Generator with Behavior-Prompted Diffusion

Can we generate a control policy for an agent using just one demonstration of desired behaviors as a prompt, as effortlessly as creating an image from a textual description?
In this paper, we present Make-An-Agent, a novel policy parameter generator that leverages the power of conditional diffusion models for behavior-to-policy generation.
Guided by behavior embeddings that encode trajectory information, our policy generator synthesizes latent parameter representations, which can then be decoded into policy networks.
Trained on policy network checkpoints and their corresponding trajectories, our generation model demonstrates remarkable versatility and scalability on multiple tasks and has a strong generalization ability on unseen tasks to output well-performed policies with only few-shot demonstrations as inputs.
We showcase its efficacy and efficiency on various domains and tasks, including varying objectives, behaviors, and even across different robot manipulators. Beyond simulation, we directly deploy policies generated by Make-An-Agent onto real-world robots on locomotion tasks.
1.2. Scaling Diffusion Transformers to 16 Billion Parameters

In this paper, we present DiT-MoE, a sparse version of the diffusion Transformer, that is scalable and competitive with dense networks while exhibiting highly optimized inference.
The DiT-MoE includes two simple designs: shared expert routing and expert-level balance loss, thereby capturing common knowledge and reducing redundancy among the different routed experts. When applied to conditional image generation, a deep analysis of experts' specialization gains some interesting observations:
The expert selection shows a preference for spatial position and denoising time step, while insensitive to different class-conditional information
As the MoE layers go deeper, the selection of experts gradually shifts from specific spatial position to dispersion and balance.
Expert specialization tends to be more concentrated at the early time step and then gradually uniform after half.
We attribute it to the diffusion process that first models the low-frequency spatial information and then high-frequency complex information. Based on the above guidance, a series of DiT-MoE experimentally achieves performance on par with dense networks yet requires much less computational load during inference.
More encouragingly, we demonstrate the potential of DiT-MoE with synthesized image data, scaling diffusion model at a 16.5B parameter that attains a new SoTA FID-50K score of 1.80 in 512 times 512 resolution settings.
2. Vision Language Models (VLMs)
2.1. Understanding Retrieval Robustness for Retrieval-Augmented Image Captioning

Recent advances in retrieval-augmented models for image captioning highlight the benefit of retrieving related captions for efficient, lightweight models with strong domain-transfer capabilities.
While these models demonstrate the success of retrieval augmentation, retrieval models are still far from perfect in practice: the retrieved information can sometimes mislead the model, resulting in incorrect generation and worse performance.
In this paper, we analyze the robustness of a retrieval-augmented captioning model SmallCap. Our analysis shows that the model is sensitive to tokens that appear in the majority of the retrieved captions, and the input attribution shows that those tokens are likely copied into the generated output.
Given these findings, we propose to train the model by sampling retrieved captions from more diverse sets. This decreases the chance that the model learns to copy majority tokens, and improves both in-domain and cross-domain performance.
2.2. Goldfish: Vision-Language Understanding of Arbitrarily Long Videos

Most current LLM-based models for video understanding can process videos within minutes. However, they struggle with lengthy videos due to challenges such as “noise and redundancy”, as well as “memory and computation” constraints. In this paper, we present Goldfish, a methodology tailored for comprehending videos of arbitrary lengths.
We also introduce the TVQA-long benchmark, specifically designed to evaluate models’ capabilities in understanding long videos with questions in both vision and text content. Goldfish approaches these challenges with an efficient retrieval mechanism that initially gathers the top-k video clips relevant to the instruction before proceeding to provide the desired response.
This design of the retrieval mechanism enables the Goldfish to efficiently process arbitrarily long video sequences, facilitating its application in contexts such as movies or television series. To facilitate the retrieval process, we developed a MiniGPT4-Video that generates detailed descriptions for the video clips.
In addressing the scarcity of benchmarks for long video evaluation, we adapted the TVQA short video benchmark for extended content analysis by aggregating questions from entire episodes, thereby shifting the evaluation from partial to full episode comprehension.
We attained a 41.78% accuracy rate on the TVQA-long benchmark, surpassing previous methods by 14.94%. Our MiniGPT4-Video also shows exceptional performance in short video comprehension, exceeding existing state-of-the-art methods by 3.23%, 2.03%, 16.5% and 23.59% on the MSVD, MSRVTT, TGIF, and TVQA short video benchmarks, respectively. These results indicate that our models have significant improvements in both long and short-video understanding.
2.3. NavGPT-2: Unleashing Navigational Reasoning Capability for Large Vision-Language Models

Capitalizing on the remarkable advancements in Large Language Models (LLMs), there is a burgeoning initiative to harness LLMs for instruction following robotic navigation. Such a trend underscores the potential of LLMs to generalize navigational reasoning and diverse language understanding.
However, a significant discrepancy in agent performance is observed when integrating LLMs in the Vision-and-Language navigation (VLN) tasks compared to previous downstream specialist models. Furthermore, the inherent capacity of language to interpret and facilitate communication in agent interactions is often underutilized in these integrations. In this work, we strive to bridge the divide between VLN-specialized models and LLM-based navigation paradigms, while maintaining the interpretative prowess of LLMs in generating linguistic navigational reasoning.
By aligning visual content in a frozen LLM, we encompass visual observation comprehension for LLMs and exploit a way to incorporate LLMs and navigation policy networks for effective action predictions and navigational reasoning. We demonstrate the data efficiency of the proposed methods and eliminate the gap between LM-based agents and state-of-the-art VLN specialists.
3. Video Understanding & Generation
3.1. Video Occupancy Models

We introduce a new family of video prediction models designed to support downstream control tasks. We call these models Video Occupancy models (VOCs).
VOCs operate in a compact latent space, thus avoiding the need to make predictions about individual pixels. Unlike prior latent-space world models, VOCs directly predict the discounted distribution of future states in a single step, thus avoiding the need for multistep roll-outs.
We show that both properties are beneficial when building predictive models of video for use in downstream control.
3.2. VD3D: Taming Large Video Diffusion Transformers for 3D Camera Control

Modern text-to-video synthesis models demonstrate coherent, photorealistic generation of complex videos from a text description. However, most existing models lack fine-grained control over camera movement, which is critical for downstream applications related to content creation, visual effects, and 3D vision.
Recently, new methods demonstrated the ability to generate videos with controllable camera poses these techniques leverage pre-trained U-Net-based diffusion models that explicitly disentangle spatial and temporal generation. Still, no existing approach enables camera control for new, transformer-based video diffusion models that process spatial and temporal information jointly.
Here, we propose to tame video transformers for 3D camera control using a ControlNet-like conditioning mechanism that incorporates spatiotemporal camera embeddings based on Plucker coordinates.
The approach demonstrates state-of-the-art performance for controllable video generation after fine-tuning on the RealEstate10K dataset. To the best of our knowledge, our work is the first to enable camera control for transformer-based video diffusion models.
3.3. Towards Understanding Unsafe Video Generation

Video generation models (VGMs) have demonstrated the capability to synthesize high-quality output. It is important to understand their potential to produce unsafe content, such as violent or terrifying videos. In this work, we provide a comprehensive understanding of unsafe video generation.
First, to confirm the possibility that these models could indeed generate unsafe videos, we choose unsafe content generation prompts collected from 4chan and Lexica, and three open-source SOTA VGMs to generate unsafe videos. After filtering out duplicates and poorly generated content, we created an initial set of 2112 unsafe videos from an original pool of 5607 videos.
Through clustering and thematic coding analysis of these generated videos, we identify 5 unsafe video categories: Distorted/Weird, Terrifying, Pornographic, Violent/Bloody, and Political. With IRB approval, we then recruit online participants to help label the generated videos. Based on the annotations submitted by 403 participants, we identified 937 unsafe videos from the initial video set.
With the labeled information and the corresponding prompts, we created the first dataset of unsafe videos generated by VGMs. We then study possible defense mechanisms to prevent the generation of unsafe videos. Existing defense methods in image generation focus on filtering either input prompt or output results.
We propose a new approach called Latent Variable Defense (LVD), which works within the model’s internal sampling process. LVD can achieve 0.90 defense accuracy while reducing time and computing resources by 10x when sampling a large number of unsafe prompts.
3.4. Shape of Motion: 4D Reconstruction from a Single Video

Monocular dynamic reconstruction is a challenging and long-standing vision problem due to the highly ill-posed nature of the task. Existing approaches are limited in that they either depend on templates, are effective only in quasi-static scenes, or fail to model 3D motion explicitly.
In this work, we introduce a method capable of reconstructing generic dynamic scenes, featuring explicit, full-sequence-long 3D motion, from casually captured monocular videos.
We tackle the under-constrained nature of the problem with two key insights:
First, we exploit the low-dimensional structure of 3D motion by representing scene motion with a compact set of SE3 motion bases. Each point’s motion is expressed as a linear combination of these bases, facilitating the soft decomposition of the scene into multiple rigidly-moving groups.
Second, we utilize a comprehensive set of data-driven priors, including monocular depth maps and long-range 2D tracks, and devise a method to effectively consolidate these noisy supervisory signals, resulting in a globally consistent representation of the dynamic scene.
Experiments show that our method achieves state-of-the-art performance for both long-range 3D/2D motion estimation and novel view synthesis on dynamic scenes.
4. Image Editing & Generation
4.1. DreamCatalyst: Fast and High-Quality 3D Editing via Controlling Editability and Identity Preservation

Score distillation sampling (SDS) has emerged as an effective framework in text-driven 3D editing tasks due to its inherent 3D consistency. However, existing SDS-based 3D editing methods suffer from extensive training time and lead to low-quality results, primarily because these methods deviate from the sampling dynamics of diffusion models.
In this paper, we propose DreamCatalyst, a novel framework that interprets SDS-based editing as a diffusion reverse process. Our objective function considers the sampling dynamics, thereby making the optimization process of DreamCatalyst an approximation of the diffusion reverse process in editing tasks.
DreamCatalyst aims to reduce training time and improve editing quality. DreamCatalyst presents two modes: (1) a faster mode, which edits the NeRF scene in only about 25 minutes, and (2) a high-quality mode, which produces superior results in less than 70 minutes. Specifically, our high-quality mode outperforms current state-of-the-art NeRF editing methods both in terms of speed and quality.
5. Image Segmentation
5.1. Ref-AVS: Refer and Segment Objects in Audio-Visual Scenes
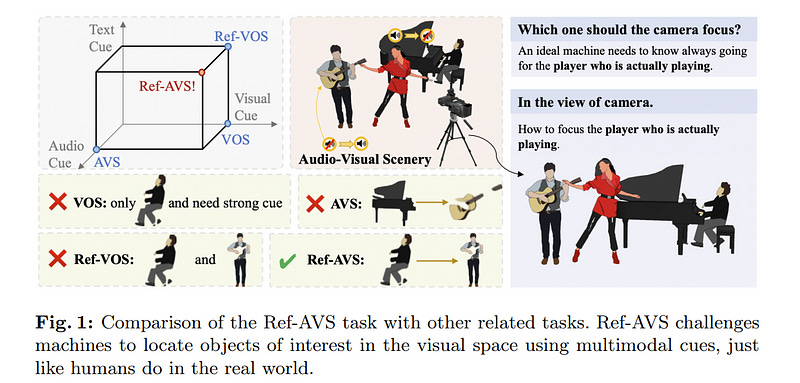
Traditional reference segmentation tasks have predominantly focused on silent visual scenes, neglecting the integral role of multimodal perception and interaction in human experiences.
In this work, we introduce a novel task called Reference Audio-Visual Segmentation (Ref-AVS), which seeks to segment objects within the visual domain based on expressions containing multimodal cues.
Such expressions are articulated in natural language forms but are enriched with multimodal cues, including audio and visual descriptions. We construct the first Ref-AVS benchmark to facilitate this research, which provides pixel-level annotations for objects described in corresponding multimodal-cue expressions.
To tackle the Ref-AVS task, we propose a new method that adequately utilizes multimodal cues to offer precise segmentation guidance. Finally, we conduct quantitative and qualitative experiments on three test subsets to compare our approach with existing methods from related tasks.
The results demonstrate the effectiveness of our method, highlighting its capability to precisely segment objects using multimodal-cue expressions.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
