


Top Important Computer Vision Papers for the Week from 4/9 to 10/9
Stay Relevant to Recent Computer Vision Research

Computer vision, a field of artificial intelligence that enables machines to interpret and understand the visual world, is rapidly evolving with groundbreaking research and technological advancements.
On a weekly basis, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
In this article, we will provide a comprehensive overview of the most significant papers published in the first week of September 2023, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of contents:
Image Recognition
Video Analysis & Understanding
Image Generation
Image Segmentation
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
All the resources and tools you need to teach yourself Data Science for free!
The best interactive roadmaps for Data Science roles. With links to free learning resources. Start here: https://aigents.co/learn/roadmaps/intro
The search engine for Data Science learning recourses. 100K handpicked articles and tutorials. With GPT-powered summaries and explanations. https://aigents.co/learn
Teach yourself Data Science with the help of an AI tutor (powered by GPT-4). https://community.aigents.co/spaces/10362739/
1. Image Recognition
1.1. FACET: Fairness in Computer Vision Evaluation Benchmark
Computer vision models have known performance disparities across attributes such as gender and skin tone. This means during tasks such as classification and detection, model performance differs for certain classes based on the demographics of the people in the image. These disparities have been shown to exist, but until now there has not been a unified approach to measure these differences for common use cases of computer vision models. We present a new benchmark named FACET (FAirness in Computer Vision EvaluaTion), a large, publicly available evaluation set of 32k images for some of the most common vision tasks — image classification, object detection, and segmentation. For every image in FACET, we hired expert reviewers to manually annotate person-related attributes such as perceived skin tone and hair type, manually draw bounding boxes, and label fine-grained person-related classes such as disk jockey or guitarist. In addition, we use FACET to benchmark state-of-the-art vision models and present a deeper understanding of potential performance disparities and challenges across sensitive demographic attributes. With the exhaustive annotations collected, we probe models using single demographic attributes as well as multiple attributes using an intersectional approach (e.g. hair color and perceived skin tone). Our results show that classification, detection, segmentation, and visual grounding models exhibit performance disparities across demographic attributes and intersections of attributes. These harms suggest that not all people represented in datasets receive fair and equitable treatment in these vision tasks. We hope current and future results using our benchmark will contribute to fairer, more robust vision models.
1.2. Contrastive Feature Masking Open-Vocabulary Vision Transformer

We present a Contrastive Feature Masking Vision Transformer (CFM-ViT) — an image-text pretraining methodology that achieves simultaneous learning of image- and region-level representation for open-vocabulary object detection (OVD). Our approach combines the masked autoencoder (MAE) objective with the contrastive learning objective to improve the representation of localization tasks. Unlike standard MAE, we perform reconstruction in the joint image-text embedding space, rather than the pixel space as is customary with the classical MAE method, which causes the model to better learn region-level semantics. Moreover, we introduce Positional Embedding Dropout (PED) to address scale variation between image-text pretraining and detection finetuning by randomly dropping out the positional embeddings during pretraining. PED improves detection performance and enables the use of a frozen ViT backbone as a region classifier, preventing the forgetting of open-vocabulary knowledge during detection finetuning. On the LVIS open-vocabulary detection benchmark, CFM-ViT achieves a state-of-the-art 33.9 APr, surpassing the best approach by 7.6 points and achieving better zero-shot detection transfer. Finally, CFM-ViT acquires strong image-level representation, outperforming the state of the art on 8 out of 12 metrics on zero-shot image-text retrieval benchmarks.
2. Video Analysis & Understanding
2.1. Tracking Anything with Decoupled Video Segmentation
Training data for video segmentation are expensive to annotate. This impedes extensions of end-to-end algorithms to new video segmentation tasks, especially in large-vocabulary settings. To ‘track anything’ without training on video data for every individual task, we develop a decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation. Due to this design, we only need an image-level model for the target task (which is cheaper to train) and a universal temporal propagation model which is trained once and generalizes across tasks. To effectively combine these two modules, we use bi-directional propagation for (semi-)online fusion of segmentation hypotheses from different frames to generate a coherent segmentation. We show that this decoupled formulation compares favorably to end-to-end approaches in several data-scarce tasks including large-vocabulary video panoptic segmentation, open-world video segmentation, referring video segmentation, and unsupervised video object segmentation.
2.2. ProPainter: Improving Propagation and Transformer for Video Inpainting
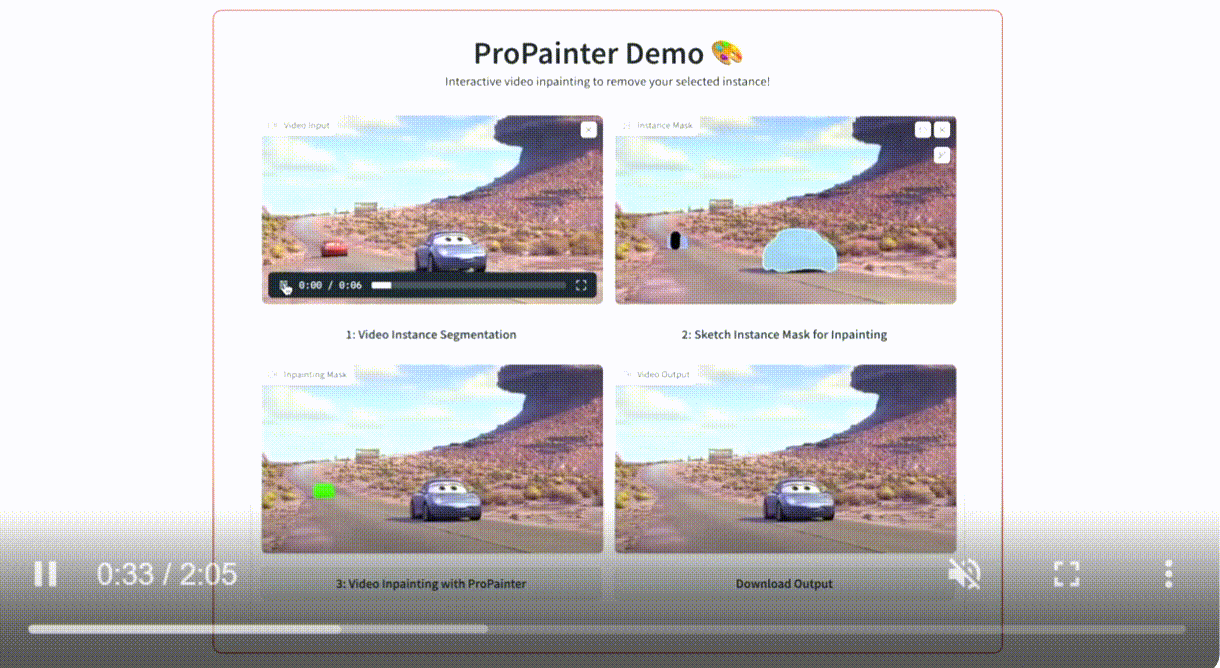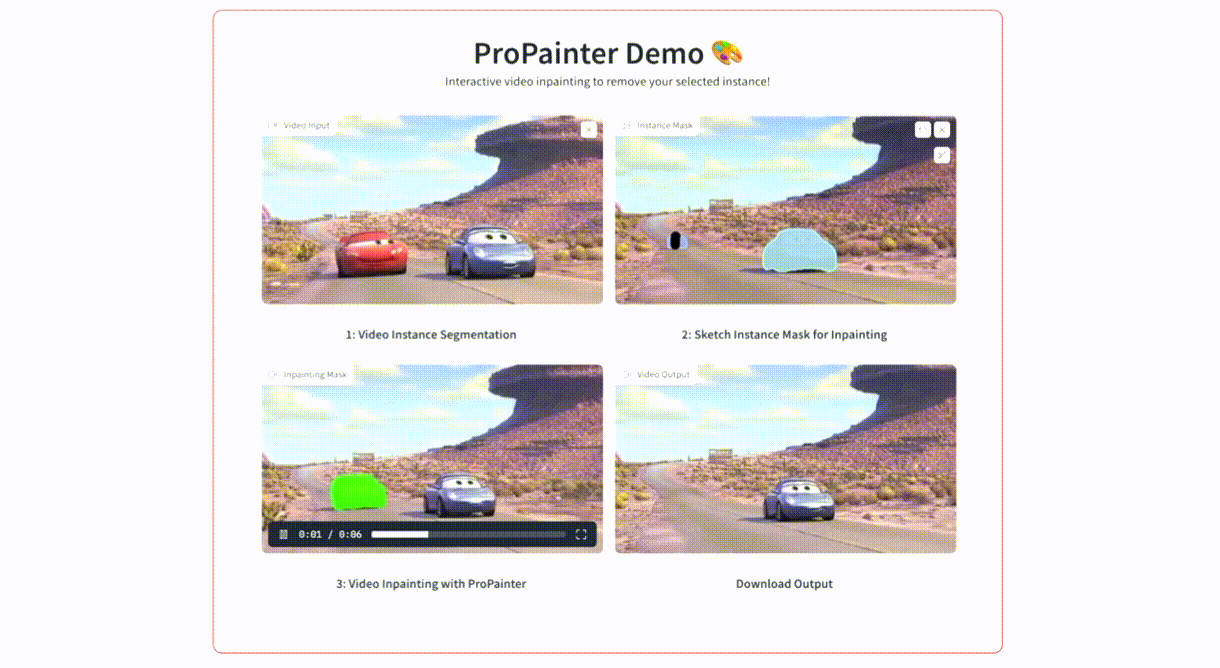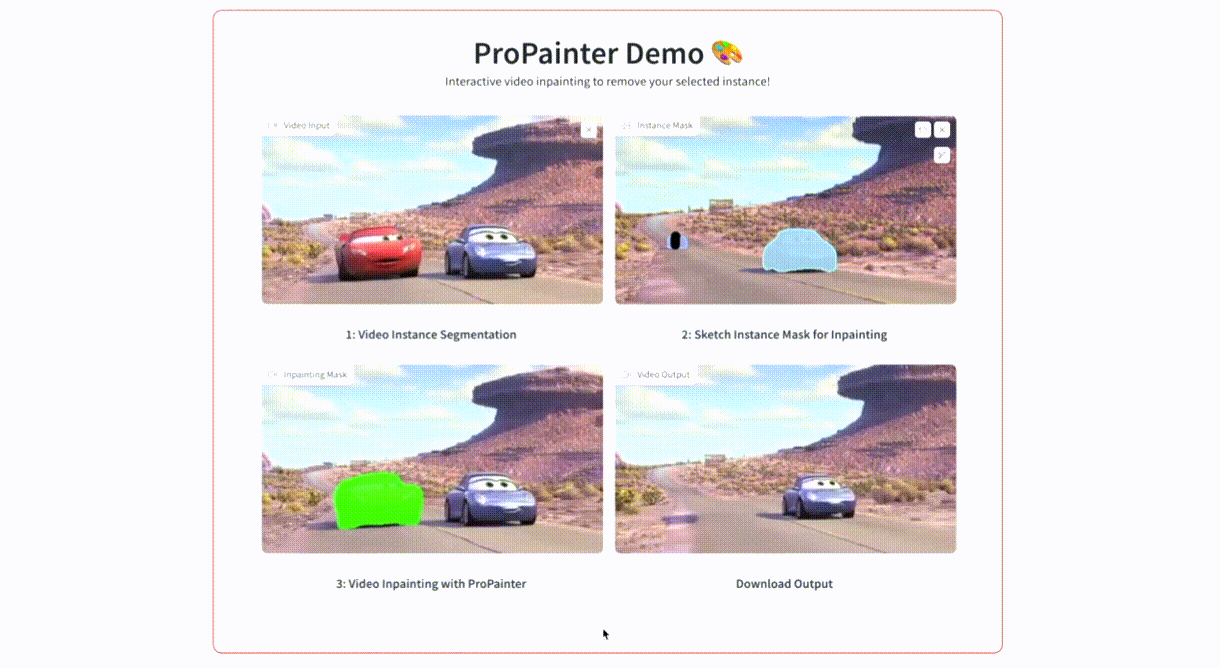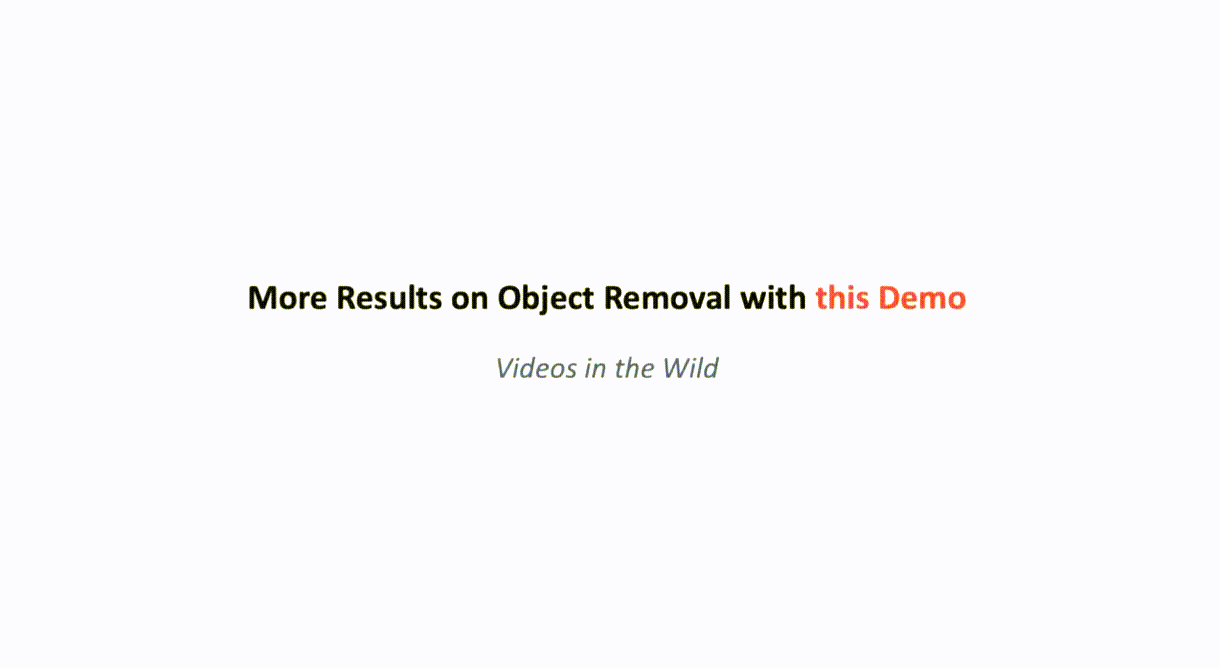
Flow-based propagation and spatiotemporal Transformer are two mainstream mechanisms in video inpainting (VI). Despite the effectiveness of these components, they still suffer from some limitations that affect their performance. Previous propagation-based approaches are performed separately either in the image or feature domain. Global image propagation isolated from learning may cause spatial misalignment due to inaccurate optical flow. Moreover, memory or computational constraints limit the temporal range of feature propagation and video Transformer, preventing exploration of correspondence information from distant frames. To address these issues, we propose an improved framework, called ProPainter, which involves enhanced ProPagation and an efficient Transformer. Specifically, we introduce dual-domain propagation that combines the advantages of image and feature warping, exploiting global correspondences reliably. We also propose a mask-guided sparse video Transformer, which achieves high efficiency by discarding unnecessary and redundant tokens. With these components, ProPainter outperforms prior arts by a large margin of 1.46 dB in PSNR while maintaining appealing efficiency.
3. Image & Video Generation
3.1. VideoGen: A Reference-Guided Latent Diffusion Approach for High-Definition Text-to-Video Generation

In this paper, we present VideoGen, a text-to-video generation approach, which can generate a high-definition video with high frame fidelity and strong temporal consistency using reference-guided latent diffusion. We leverage an off-the-shelf text-to-image generation model, e.g., Stable Diffusion, to generate an image with high content quality from the text prompt, as a reference image to guide video generation. Then, we introduce an efficient cascaded latent diffusion module conditioned on both the reference image and the text prompt, for generating latent video representations, followed by a flow-based temporal upsampling step to improve the temporal resolution. Finally, we map latent video representations into a high-definition video through an enhanced video decoder. During training, we use the first frame of a ground-truth video as the reference image for training the cascaded latent diffusion module. The main characteristics of our approach include: the reference image generated by the text-to-image model improves the visual fidelity; using it as the condition makes the diffusion model focus more on learning the video dynamics; and the video decoder is trained over unlabeled video data, thus benefiting from high-quality easily-available videos. VideoGen sets a new state-of-the-art in text-to-video generation in terms of both qualitative and quantitative evaluation.
3.2. CityDreamer: Compositional Generative Model of Unbounded 3D Cities

In recent years, extensive research has focused on 3D natural scene generation, but the domain of 3D city generation has not received as much exploration. This is due to the greater challenges posed by 3D city generation, mainly because humans are more sensitive to structural distortions in urban environments. Additionally, generating 3D cities is more complex than 3D natural scenes since buildings, as objects of the same class, exhibit a wider range of appearances compared to the relatively consistent appearance of objects like trees in natural scenes. To address these challenges, we propose CityDreamer, a compositional generative model designed specifically for unbounded 3D cities, which separates the generation of building instances from other background objects, such as roads, green lands, and water areas, into distinct modules. Furthermore, we construct two datasets, OSM and GoogleEarth, containing a vast amount of real-world city imagery to enhance the realism of the generated 3D cities both in their layouts and appearances. Through extensive experiments, CityDreamer has proven its superiority over state-of-the-art methods in generating a wide range of lifelike 3D cities.
3.3. Point-Bind & Point-LLM: Aligning Point Cloud with Multi-modality for 3D Understanding, Generation, and Instruction Following

We introduce Point-Bind, a 3D multi-modality model aligning point clouds with 2D image, language, audio, and video. Guided by ImageBind, we construct a joint embedding space between 3D and multi-modalities, enabling many promising applications, e.g., any-to-3D generation, 3D embedding arithmetic, and 3D open-world understanding. On top of this, we further present Point-LLM, the first 3D large language model (LLM) following 3D multi-modal instructions. By parameter-efficient fine-tuning techniques, Point-LLM injects the semantics of Point-Bind into pre-trained LLMs, e.g., LLaMA, which requires no 3D instruction data, but exhibits superior 3D and multi-modal question-answering capacity. We hope our work may cast a light on the community for extending 3D point clouds to multi-modality applications.
3.4. AniPortraitGAN: Animatable 3D Portrait Generation from 2D Image Collections
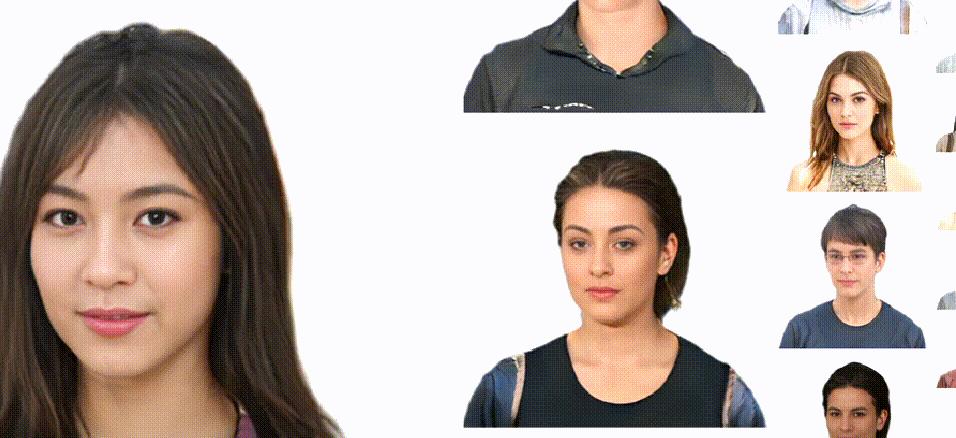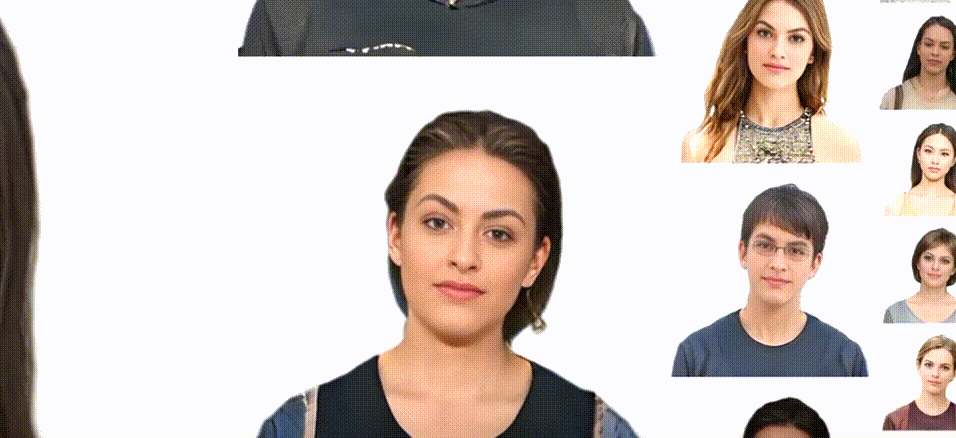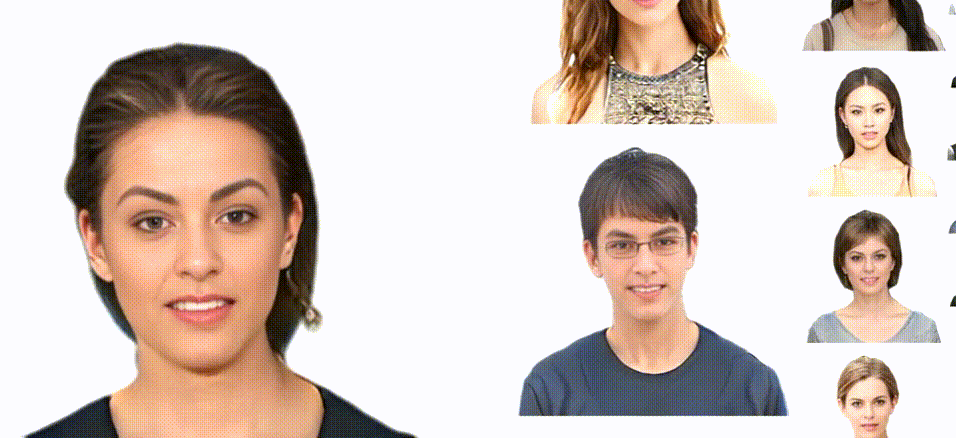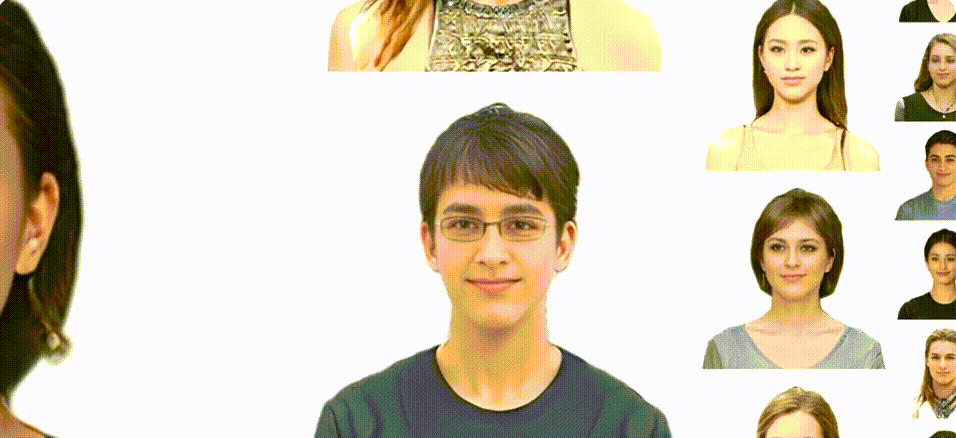
Previous animatable 3D-aware GANs for the human generation have primarily focused on either the human head or the full body. However, head-only videos are relatively uncommon in real life, and full-body generation typically does not deal with facial expression control and still has challenges in generating high-quality results. Towards applicable video avatars, we present an animatable 3D-aware GAN that generates portrait images with controllable facial expressions, head pose, and shoulder movements. It is a generative model trained on unstructured 2D image collections without using 3D or video data. For the new task, we base our method on the generative radiance manifold representation and equip it with learnable facial and head-shoulder deformations. A dual-camera rendering and adversarial learning scheme is proposed to improve the quality of the generated faces, which is critical for portrait images. A pose deformation processing network is developed to generate plausible deformations for challenging regions such as long hair. Experiments show that our method, trained on unstructured 2D images, can generate diverse and high-quality 3D portraits with desired control over different properties.
3.5. ControlMat: A Controlled Generative Approach to Material Capture

Material reconstruction from a photograph is a key component of 3D content creation democratization. We propose to formulate this ill-posed problem as a controlled synthesis one, leveraging the recent progress in generative deep networks. We present ControlMat, a method which, given a single photograph with uncontrolled illumination as input, conditions a diffusion model to generate plausible, tileable, high-resolution physically-based digital materials. We carefully analyze the behavior of diffusion models for multi-channel outputs, adapt the sampling process to fuse multi-scale information, and introduce rolled diffusion to enable both tileability and patched diffusion for high-resolution outputs. Our generative approach further permits the exploration of a variety of materials that could correspond to the input image, mitigating the unknown lighting conditions. We show that our approach outperforms recent inference and latent-space-optimization methods, and carefully validate our diffusion process design choices.
3.6. Hierarchical Masked 3D Diffusion Model for Video Outpainting

Video outpainting aims to adequately complete missing areas at the edges of video frames. Compared to image outpainting, it presents an additional challenge as the model should maintain the temporal consistency of the filled area. In this paper, we introduce a masked 3D diffusion model for video outpainting. We use the technique of mask modeling to train the 3D diffusion model. This allows us to use multiple guide frames to connect the results of multiple video clip inferences, thus ensuring temporal consistency and reducing jitter between adjacent frames. Meanwhile, we extract the global frames of the video as prompts and guide the model to obtain information other than the current video clip using cross-attention. We also introduce a hybrid coarse-to-fine inference pipeline to alleviate the artifact accumulation problem. The existing coarse-to-fine pipeline only uses the infilling strategy, which brings degradation because the time interval of the sparse frames is too large. Our pipeline benefits from bidirectional learning of the mask modeling and thus can employ a hybrid strategy of infilling and interpolation when generating sparse frames. Experiments show that our method achieves state-of-the-art results in video outpainting tasks.
3.7. MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation

This paper addresses the issue of modifying the visual appearance of videos while preserving their motion. A novel framework, named MagicProp, is proposed, which disentangles the video editing process into two stages: appearance editing and motion-aware appearance propagation. In the first stage, MagicProp selects a single frame from the input video and applies image-editing techniques to modify the content and/or style of the frame. The flexibility of these techniques enables the editing of arbitrary regions within the frame. In the second stage, MagicProp employs the edited frame as an appearance reference and generates the remaining frames using an autoregressive rendering approach. To achieve this, a diffusion-based conditional generation model, called PropDPM, is developed, which synthesizes the target frame by conditioning on the reference appearance, the target motion, and its previous appearance. The autoregressive editing approach ensures temporal consistency in the resulting videos. Overall, MagicProp combines the flexibility of image-editing techniques with the superior temporal consistency of autoregressive modeling, enabling flexible editing of object types and aesthetic styles in arbitrary regions of input videos while maintaining good temporal consistency across frames. Extensive experiments in various video editing scenarios demonstrate the effectiveness of MagicProp.
3.8. Diffusion Generative Inverse Design

Inverse design refers to the problem of optimizing the input of an objective function in order to enact a target outcome. For many real-world engineering problems, the objective function takes the form of a simulator that predicts how the system state will evolve over time, and the design challenge is to optimize the initial conditions that lead to a target outcome. Recent developments in learned simulation have shown that graph neural networks (GNNs) can be used for accurate, efficient, differentiable estimation of simulator dynamics, and support high-quality design optimization with gradient- or sampling-based optimization procedures. However, optimizing designs from scratch requires many expensive model queries, and these procedures exhibit basic failures on either non-convex or high-dimensional problems. In this work, we show how denoising diffusion models (DDMs) can be used to solve inverse design problems efficiently and propose a particle sampling algorithm for further improving their efficiency. We perform experiments on a number of fluid dynamics design challenges and find that our approach substantially reduces the number of calls to the simulator compared to standard techniques.
3.9. InstructDiffusion: A Generalist Modeling Interface for Vision Tasks

We present InstructDiffusion, a unifying and generic framework for aligning computer vision tasks with human instructions. Unlike existing approaches that integrate prior knowledge and pre-define the output space (e.g., categories and coordinates) for each vision task, we cast diverse vision tasks into a human-intuitive image-manipulating process whose output space is a flexible and interactive pixel space. Concretely, the model is built upon the diffusion process and is trained to predict pixels according to user instructions, such as encircling the man’s left shoulder in red or applying a blue mask to the left car. InstructDiffusion could handle a variety of vision tasks, including understanding tasks (such as segmentation and keypoint detection) and generative tasks (such as editing and enhancement). It even exhibits the ability to handle unseen tasks and outperforms prior methods on novel datasets. This represents a significant step towards a generalist modeling interface for vision tasks, advancing artificial general intelligence in the field of computer vision.
3.10. SyncDreamer: Generating Multiview-consistent Images from a Single-view Image

In this paper, we present a novel diffusion model that generates multiview-consistent images from a single-view image. Using pretrained large-scale 2D diffusion models, recent work Zero123 demonstrates the ability to generate plausible novel views from a single-view image of an object. However, maintaining consistency in geometry and colors for the generated images remains a challenge. To address this issue, we propose a synchronized multiview diffusion model that models the joint probability distribution of multiview images, enabling the generation of multiview-consistent images in a single reverse process. SyncDreamer synchronizes the intermediate states of all the generated images at every step of the reverse process through a 3D-aware feature attention mechanism that correlates the corresponding features across different views. Experiments show that SyncDreamer generates images with high consistency across different views, thus making it well-suited for various 3D generation tasks such as novel-view-synthesis, text-to-3D, and image-to-3D.
3.11. Text2Control3D: Controllable 3D Avatar Generation in Neural Radiance Fields using Geometry-Guided Text-to-Image Diffusion Model

Recent advances in diffusion models such as ControlNet have enabled geometrically controllable, high-fidelity text-to-image generation. However, none of them addresses the question of adding such controllability to text-to-3D generation. In response, we propose Text2Control3D, a controllable text-to-3D avatar generation method whose facial expression is controllable given a monocular video casually captured with a hand-held camera. Our main strategy is to construct the 3D avatar in Neural Radiance Fields (NeRF) optimized with a set of controlled viewpoint-aware images that we generate from ControlNet, whose condition input is the depth map extracted from the input video. When generating viewpoint-aware images, we utilize cross-reference attention to inject well-controlled, referential facial expressions and appearance via cross attention. We also conduct low-pass filtering of the Gaussian latent of the diffusion model in order to ameliorate the viewpoint-agnostic texture problem we observed from our empirical analysis, where the viewpoint-aware images contain identical textures on identical pixel positions that are incomprehensible in 3D. Finally, to train NeRF with images that are viewpoint-aware yet are not strictly consistent in geometry, our approach considers per-image geometric variation as a view of deformation from a shared 3D canonical space. Consequently, we construct the 3D avatar in a canonical space of deformable NeRF by learning a set of per-image deformation via the deformation field table. We demonstrate the empirical results and discuss the effectiveness of our method.
3.12. Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation

Inspired by the remarkable success of Latent Diffusion Models (LDMs) for image synthesis, we study LDM for text-to-video generation, which is a formidable challenge due to the computational and memory constraints during both model training and inference. A single LDM is usually only capable of generating a very limited number of video frames. Some existing works focus on separate prediction models for generating more video frames, which suffer from additional training costs and frame-level jittering, however. In this paper, we propose a framework called “Reuse and Diffuse” dubbed VidRD to produce more frames following the frames already generated by an LDM. Conditioned on an initial video clip with a small number of frames, additional frames are iteratively generated by reusing the original latent features and following the previous diffusion process. Besides, for the autoencoder used for translation between pixel space and latent space, we inject temporal layers into its decoder and fine-tune these layers for higher temporal consistency. We also propose a set of strategies for composing video-text data that involve diverse content from multiple existing datasets including video datasets for action recognition and image-text datasets. Extensive experiments show that our method achieves good results in both quantitative and qualitative evaluations.
4. Image Segmentation
4.1. SLiMe: Segment Like Me

Significant strides have been made using large vision-language models, like Stable Diffusion (SD), for a variety of downstream tasks, including image editing, image correspondence, and 3D shape generation. Inspired by these advancements, we explore leveraging these extensive vision-language models for segmenting images at any desired granularity using as few as one annotated sample by proposing SLiMe. SLiMe frames this problem as an optimization task. Specifically, given a single training image and its segmentation mask, we first extract attention maps, including our novel “weighted accumulated self-attention map” from the SD prior. Then, using the extracted attention maps, the text embeddings of Stable Diffusion are optimized such that, each of them, learns about a single segmented region from the training image. These learned embeddings then highlight the segmented region in the attention maps, which in turn can then be used to derive the segmentation map. This enables SLiMe to segment any real-world image during inference with the granularity of the segmented region in the training image, using just one example. Moreover, leveraging additional training data when available, i.e. few-shot, improves the performance of SLiMe. We carried out a knowledge-rich set of experiments examining various design factors and showed that SLiMe outperforms other existing one-shot and few-shot segmentation methods.
5. Image Reconstruction
5.1. Doppelgangers: Learning to Disambiguate Images of Similar Structures
We consider the visual disambiguation task of determining whether a pair of visually similar images depict the same or distinct 3D surfaces (e.g., the same or opposite sides of a symmetric building). Illusory image matches, where two images observe distinct but visually similar 3D surfaces, can be challenging for humans to differentiate, and can also lead 3D reconstruction algorithms to produce erroneous results. We propose a learning-based approach to visual disambiguation, formulating it as a binary classification task on image pairs. To that end, we introduce a new dataset for this problem, Doppelgangers, which includes image pairs of similar structures with ground truth labels. We also design a network architecture that takes the spatial distribution of local key points and matches them as input, allowing for better reasoning about both local and global cues. Our evaluation shows that our method can distinguish illusory matches in difficult cases, and can be integrated into SfM pipelines to produce correct, disambiguated 3D reconstructions.
Looking to start a career in data science and AI do not know how. I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
