


Top Important Computer Vision Papers for the Week from 18/03 to 24/03
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of March 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Image Generation & Editing
Video Generation & Editing
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model

Reconstructing detailed 3D objects from single-view images remains a challenging task due to the limited information available. In this paper, we introduce FDGaussian, a novel two-stage framework for single-image 3D reconstruction.
Recent methods typically utilize pre-trained 2D diffusion models to generate plausible novel views from the input image, yet they encounter issues with either multi-view inconsistency or lack of geometric fidelity.
To overcome these challenges, we propose an orthogonal plane decomposition mechanism to extract 3D geometric features from the 2D input, enabling the generation of consistent multi-view images.
Moreover, we further accelerate the state-of-the-art Gaussian Splatting incorporating epipolar attention to fuse images from different viewpoints. We demonstrate that FDGaussian generates images with high consistency across different views and reconstructs high-quality 3D objects, both qualitatively and quantitatively.
1.2. Generic 3D Diffusion Adapter Using Controlled Multi-View Editing

Open-domain 3D object synthesis has been lagging behind image synthesis due to limited data and higher computational complexity. To bridge this gap, recent works have investigated multi-view diffusion but often fall short in either 3D consistency, visual quality, or efficiency.
This paper proposes MVEdit, which functions as a 3D counterpart of SDEdit, employing ancestral sampling to jointly denoise multi-view images and output high-quality textured meshes. Built on off-the-shelf 2D diffusion models, MVEdit achieves 3D consistency through a training-free 3D Adapter, which lifts the 2D views of the last timestep into a coherent 3D representation, then conditions the 2D views of the next timestep using rendered views, without uncompromising visual quality.
With an inference time of only 2–5 minutes, this framework achieves a better trade-off between quality and speed than score distillation. MVEdit is highly versatile and extendable, with a wide range of applications including text/image-to-3D generation, 3D-to-3D editing, and high-quality texture synthesis.
In particular, evaluations demonstrate state-of-the-art performance in both image-to-3D and text-guided texture generation tasks. Additionally, we introduce a method for fine-tuning 2D latent diffusion models on small 3D datasets with limited resources, enabling fast low-resolution text-to-3D initialization.
1.3. Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation

Diffusion models are the main driver of progress in image and video synthesis but suffer from slow inference speed. Distillation methods, like the recently introduced adversarial diffusion distillation (ADD), aim to shift the model from many-shot to single-step inference, albeit at the cost of expensive and difficult optimization due to its reliance on a fixed pretrained DINOv2 discriminator.
We introduce Latent Adversarial Diffusion Distillation (LADD), a novel distillation approach to overcoming the limitations of ADD. In contrast, to pixel-based ADD, LADD utilizes generative features from pretrained latent diffusion models.
This approach simplifies training and enhances performance, enabling high-resolution multi-aspect ratio image synthesis. We apply LADD to Stable Diffusion 3 (8B) to obtain SD3-Turbo, a fast model that matches the performance of state-of-the-art text-to-image generators using only four unguided sampling steps.
Moreover, we systematically investigate its scaling behavior and demonstrate LADD’s effectiveness in various applications such as image editing and inpainting.
1.4. LightIt: Illumination Modeling and Control for Diffusion Models

We introduce LightIt, a method for explicit illumination control for image generation. Recent generative methods lack lighting control, which is crucial to numerous artistic aspects of image generation such as setting the overall mood or cinematic appearance.
To overcome these limitations, we propose to condition the generation on shading and normal maps. We model the lighting with single bounce shading, which includes cast shadows. We first train a shading estimation module to generate a dataset of real-world images and shading pairs. Then, we train a control network using the estimated shading and normals as input.
Our method demonstrates high-quality image generation and lighting control in numerous scenes. Additionally, we use our generated dataset to train an identity-preserving relighting model, conditioned on an image and a target shading.
Our method is the first that enables the generation of images with controllable, consistent lighting and performs on par with specialized relighting state-of-the-art methods.
1.5. VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models

This paper presents a novel paradigm for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire.
This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model.
The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 70% of the time.
1.6. AnimateDiff-Lightning: Cross-Model Diffusion Distillation

We present AnimateDiff-Lightning for lightning-fast video generation. Our model uses progressive adversarial diffusion distillation to achieve new state-of-the-art in few-step video generation.
We discuss our modifications to adapt it for the video modality. Furthermore, we propose to simultaneously distill the probability flow of multiple base diffusion models, resulting in a single distilled motion module with broader style compatibility.
1.7. LN3Diff: Scalable Latent Neural Fields Diffusion for Speedy 3D Generation

The field of neural rendering has witnessed significant progress with advancements in generative models and differentiable rendering techniques. Though 2D diffusion has achieved success, a unified 3D diffusion pipeline remains unsettled.
This paper introduces a novel framework called LN3Diff to address this gap and enable fast, high-quality, and generic conditional 3D generation. Our approach harnesses a 3D-aware architecture and variational autoencoder (VAE) to encode the input image into a structured, compact, and 3D latent space. The latent is decoded by a transformer-based decoder into a high-capacity 3D neural field.
Through training a diffusion model on this 3D-aware latent space, our method achieves state-of-the-art performance on ShapeNet for 3D generation and demonstrates superior performance in monocular 3D reconstruction and conditional 3D generation across various datasets.
Moreover, it surpasses existing 3D diffusion methods in terms of inference speed, requiring no per-instance optimization. Our proposed LN3Diff presents a significant advancement in 3D generative modeling and holds promise for various applications in 3D vision and graphics tasks.
1.8. Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition

Video diffusion models have recently made great progress in generation quality, but are still limited by the high memory and computational requirements.
This is because current video diffusion models often attempt to process high-dimensional videos directly. To tackle this issue, we propose a content-motion latent diffusion model (CMD), a novel efficient extension of pretrained image diffusion models for video generation. Specifically, we propose an autoencoder that succinctly encodes a video as a combination of a content frame (like an image) and a low-dimensional motion latent representation.
The former represents the common content, and the latter represents the underlying motion in the video, respectively. We generate the content frame by fine-tuning a pretrained image diffusion model, and we generate the motion latent representation by training a new lightweight diffusion model.
A key innovation here is the design of a compact latent space that can directly utilize a pretrained image diffusion model, which has not been done in previous latent video diffusion models. This leads to considerably better quality generation and reduced computational costs.
For instance, CMD can sample a video 7.7 times faster than prior approaches by generating a video of 512 times1024 resolution and length 16 in 3.1 seconds. Moreover, CMD achieves an FVD score of 212.7 on WebVid-10M, 27.3% better than the previous state-of-the-art of 292.4.
1.9. ComboVerse: Compositional 3D Assets Creation Using Spatially-Aware Diffusion Guidance

Generating high-quality 3D assets from a given image is highly desirable in various applications such as AR/VR. Recent advances in single-image 3D generation explore feed-forward models that learn to infer the 3D model of an object without optimization.
Though promising results have been achieved in single object generation, these methods often struggle to model complex 3D assets that inherently contain multiple objects.
In this work, we present ComboVerse, a 3D generation framework that produces high-quality 3D assets with complex compositions by learning to combine multiple models.
We first perform an in-depth analysis of this ``multi-object gap’’ from both model and data perspectives. Next, with reconstructed 3D models of different objects, we seek to adjust their sizes, rotation angles, and locations to create a 3D asset that matches the given image. To automate this process, we apply spatially-aware score distillation sampling (SSDS) from pretrained diffusion models to guide the positioning of objects.
Our proposed framework emphasizes spatial alignment of objects, compared with standard score distillation sampling, and thus achieves more accurate results. Extensive experiments validate that ComboVerse achieves clear improvements over existing methods in generating compositional 3D assets.
1.10. ZigMa: Zigzag Mamba Diffusion Model

The diffusion model has long been plagued by scalability and quadratic complexity issues, especially within transformer-based structures. In this study, we aim to leverage the long sequence modeling capability of a State-Space Model called Mamba to extend its applicability to visual data generation.
Firstly, we identify a critical oversight in most current Mamba-based vision methods, namely the lack of consideration for spatial continuity in the scan scheme of Mamba.
Secondly, building upon this insight, we introduce a simple, plug-and-play, zero-parameter method named Zigzag Mamba, which outperforms Mamba-based baselines and demonstrates improved speed and memory utilization compared to transformer-based baselines.
Lastly, we integrate Zigzag Mamba with the Stochastic Interpolant framework to investigate the scalability of the model on large-resolution visual datasets, such as FacesHQ 1024times 1024 and UCF101, MultiModal-CelebA-HQ, and MS COCO 256times 256.
2. Vision Language Models
2.1. SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model

We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach.
Recent successes inspire our proposed scene representation in transformers & LLMs and depart from more traditional methods that commonly describe scenes as meshes, voxel grids, point clouds, or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture.
To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs.
Our method gives state-of-the-art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage of SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
2.2. When Do We Not Need Larger Vision Models?

Scaling up the size of vision models has been the de facto standard to obtain more powerful visual representations. In this work, we discuss the point beyond which larger vision models are optional.
First, we demonstrate the power of Scaling on Scales (S²), whereby a pre-trained and frozen smaller vision model (e.g., ViT-B or ViT-L), run over multiple image scales, can outperform larger models (e.g., ViT-H or ViT-G) on classification, segmentation, depth estimation, Multimodal LLM (MLLM) benchmarks, and robotic manipulation.
Notably, S² achieves state-of-the-art performance in a detailed understanding of MLLM on the V* benchmark, surpassing models such as GPT-4V. We examine the conditions under which S² is a preferred scaling approach compared to scaling on model size.
While larger models have the advantage of better generalization on hard examples, we show that those of multi-scale smaller models can well approximate features of larger vision models.
This suggests most, if not all, of the representations learned by current large pre-trained models can also be obtained from multi-scale smaller models. Our results show that a multi-scale smaller model has comparable learning capacity to a larger model, and pre-training smaller models with S² can match or even exceed the advantage of larger models.
2.3. MyVLM: Personalizing VLMs for User-Specific Queries
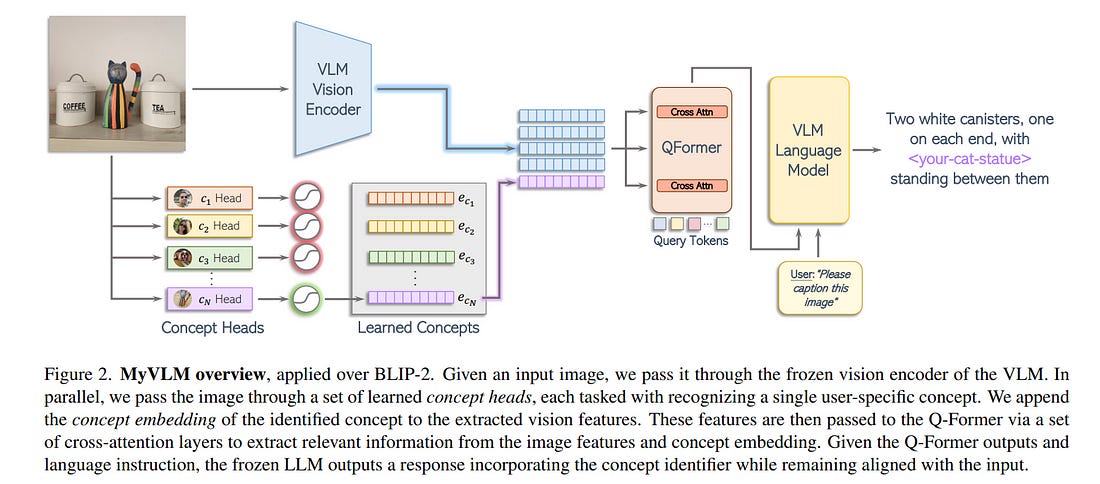
Recent large-scale vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and generating textual descriptions for visual content.
However, these models lack an understanding of user-specific concepts. In this work, we take a first step toward the personalization of VLMs, enabling them to learn and reason over user-provided concepts. For example, we explore whether these models can learn to recognize you in an image and communicate what you are doing, tailoring the model to reflect your personal experiences and relationships.
To effectively recognize a variety of user-specific concepts, we augment the VLM with external concept heads that function as toggles for the model, enabling the VLM to identify the presence of specific target concepts in a given image. Having recognized the concept, we learn a new concept embedding in the intermediate feature space of the VLM.
This embedding is tasked with guiding the language model to naturally integrate the target concept in its generated response. We apply our technique to BLIP-2 and LLaVA for personalized image captioning and further show its applicability for personalized visual question-answering. Our experiments demonstrate our ability to generalize to unseen images of learned concepts while preserving the model behavior on unrelated inputs.
2.4. IDAdapter: Learning Mixed Features for Tuning-Free Personalization of Text-to-Image Models

Leveraging Stable Diffusion for the generation of personalized portraits has emerged as a powerful and noteworthy tool, enabling users to create high-fidelity, custom character avatars based on their specific prompts.
However, existing personalization methods face challenges, including test-time fine-tuning, the requirement of multiple input images, low preservation of identity, and limited diversity in generated outcomes.
To overcome these challenges, we introduce IDAdapter, a tuning-free approach that enhances diversity and identity preservation in personalized image generation from a single-face image.
IDAdapter integrates a personalized concept into the generation process through a combination of textual and visual injections and a face identity loss.
During the training phase, we incorporate mixed features from multiple reference images of a specific identity to enrich identity-related content details, guiding the model to generate images with more diverse styles, expressions, and angles compared to previous works. Extensive evaluations demonstrate the effectiveness of our method, achieving both diversity and identity fidelity in generated images.
2.5. HyperLLaVA: Dynamic Visual and Language Expert Tuning for Multimodal Large Language Models

Recent advancements indicate that scaling up Multimodal Large Language Models (MLLMs) effectively enhances performance on downstream multimodal tasks.
The prevailing MLLM paradigm, e.g., LLaVA, transforms visual features into text-like tokens using a static vision-language mapper, thereby enabling static LLMs to develop the capability to comprehend visual information through visual instruction tuning.
Although promising, the static tuning strategy~The static tuning refers to the trained model with static parameters. that share the same parameters may constrain performance across different downstream multimodal tasks. In light of this, we introduce HyperLLaVA, which involves adaptive tuning of the projector and LLM parameters, in conjunction with a dynamic visual expert and language expert, respectively.
These experts are derived from HyperNetworks, which generates adaptive parameter shifts through visual and language guidance, enabling dynamic projector and LLM modeling in two-stage training. Our experiments demonstrate that our solution significantly surpasses LLaVA on existing MLLM benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench.
3. Image Generation & Editing
3.1. Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding

Encouraged by the growing availability of pre-trained 2D diffusion models, image-to-3D generation by leveraging Score Distillation Sampling (SDS) is making remarkable progress.
Most existing methods combine novel-view lifting from 2D diffusion models which usually take the reference image as a condition while applying hard L2 image supervision at the reference view. Yet heavily adhering to the image is prone to corrupting the inductive knowledge of the 2D diffusion model leading to flat or distorted 3D generation frequently.
In this work, we reexamine image-to-3D in a novel perspective and present Isotropic3D, an image-to-3D generation pipeline that takes only an image CLIP embedding as input. Isotropic3D allows the optimization to be isotropic w.r.t. the azimuth angle by solely resting on the SDS loss. The core of our framework lies in a two-stage diffusion model fine-tuning.
Firstly, we fine-tune a text-to-3D diffusion model by substituting its text encoder with an image encoder, by which the model preliminarily acquires image-to-image capabilities. Secondly, we perform fine-tuning using our Explicit Multi-view Attention (EMA) which combines noisy multi-view images with the noise-free reference image as an explicit condition.
CLIP embedding is sent to the diffusion model throughout the whole process while reference images are discarded once after fine-tuning. As a result, with a single image CLIP embedding, Isotropic3D is capable of generating multi-view mutually consistent images and also a 3D model with more symmetrical and neat content, well-proportioned geometry, rich colored texture, and less distortion compared with existing image-to-3D methods while still preserving the similarity to the reference image to a large extent.
3.2. Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting

While text-to-3D and image-to-3D generation tasks have received considerable attention, one important but under-explored field between them is controllable text-to-3D generation, which we mainly focus on in this work.
To address this task, 1) we introduce Multi-view ControlNet (MVControl), a novel neural network architecture designed to enhance existing pre-trained multi-view diffusion models by integrating additional input conditions, such as edge, depth, normal, and scribble maps.
Our innovation lies in the introduction of a conditioning module that controls the base diffusion model using both local and global embeddings, which are computed from the input condition images and camera poses. Once trained, MVControl can offer 3D diffusion guidance for optimization-based 3D generation. And, 2) we propose an efficient multi-stage 3D generation pipeline that leverages the benefits of recent large reconstruction models and scores distillation algorithms.
Building upon our MVControl architecture, we employ a unique hybrid diffusion guidance method to direct the optimization process. In pursuit of efficiency, we adopt 3D Gaussians as our representation instead of the commonly used implicit representations.
We also pioneer the use of SuGaR, a hybrid representation that binds Gaussians to mesh triangle faces. This approach alleviates the issue of poor geometry in 3D Gaussians and enables the direct sculpting of fine-grained geometry on the mesh.
Extensive experiments demonstrate that our method achieves robust generalization and enables the controllable generation of high-quality 3D content.
3.3. StyleCineGAN: Landscape Cinemagraph Generation using a Pre-trained StyleGAN

We propose a method that can generate cinemagraphs automatically from a still landscape image using a pre-trained StyleGAN. Inspired by the success of recent unconditional video generation, we leverage a powerful pre-trained image generator to synthesize high-quality cinemagraphs.
Unlike previous approaches that mainly utilize the latent space of a pre-trained StyleGAN, our approach utilizes its deep feature space for both GAN inversion and cinemagraph generation. Specifically, we propose multi-scale deep feature warping (MSDFW), which warps the intermediate features of a pre-trained StyleGAN at different resolutions.
By using MSDFW, the generated cinemagraphs are of high resolution and exhibit plausible looping animation. We demonstrate the superiority of our method through user studies and quantitative comparisons with state-of-the-art cinema-graph generation methods and a video generation method that uses a pre-trained StyleGAN.
3.4. GaussianFlow: Splatting Gaussian Dynamics for 4D Content Creation

Creating 4D fields of Gaussian Splatting from images or videos is a challenging task due to its under-constrained nature. While the optimization can draw photometric reference from the input videos or be regulated by generative models, directly supervising Gaussian motions remains underexplored.
In this paper, we introduce a novel concept, Gaussian flow, which connects the dynamics of 3D Gaussians and pixel velocities between consecutive frames. The Gaussian flow can be efficiently obtained by splatting Gaussian dynamics into the image space. This differentiable process enables direct dynamic supervision from optical flow.
Our method significantly benefits 4D dynamic content generation and 4D novel view synthesis with Gaussian Splatting, especially for contents with rich motions that are hard to handle by existing methods. The common color drifting issue that happens in a 4D generation is also resolved with improved Gaussian dynamics.
Superior visual quality in extensive experiments demonstrates our method’s effectiveness. Quantitative and qualitative evaluations show that our method achieves state-of-the-art results on both tasks of 4D generation and 4D novel view synthesis.
3.5. FouriScale: A Frequency Perspective on Training-Free High-Resolution Image Synthesis
In this study, we delve into the generation of high-resolution images from pre-trained diffusion models, addressing persistent challenges, such as repetitive patterns and structural distortions, that emerge when models are applied beyond their trained resolutions.
To address this issue, we introduce an innovative, training-free approach FouriScale from the perspective of frequency domain analysis. We replace the original convolutional layers in pre-trained diffusion models by incorporating a dilation technique along with a low-pass operation, intending to achieve structural consistency and scale consistency across resolutions, respectively.
Further enhanced by a padding-then-crop strategy, our method can flexibly handle text-to-image generation of various aspect ratios. By using the FouriScale as guidance, our method successfully balances the structural integrity and fidelity of generated images, achieving an astonishing capacity of arbitrary size, high-resolution, and high-quality generation.
With its simplicity and compatibility, our method can provide valuable insights for future explorations into the synthesis of ultra-high-resolution images.
3.6. DreamReward: Text-to-3D Generation with Human Preference

3D content creation from text prompts has shown remarkable success recently. However, current text-to-3D methods often generate 3D results that do not align well with human preferences. In this paper, we present a comprehensive framework, coined by DreamReward, to learn and improve text-to-3D models from human preference feedback.
To begin with, we collect 25k expert comparisons based on a systematic annotation pipeline including rating and ranking. Then, we build Reward3D — the first general-purpose text-to-3D human preference reward model to effectively encode human preferences.
Building upon the 3D reward model, we finally perform theoretical analysis and present the Reward3D Feedback Learning (DreamFL), a direct tuning algorithm to optimize the multi-view diffusion models with a redefined scorer.
Grounded by theoretical proof and extensive experiment comparisons, our DreamReward successfully generates high-fidelity and 3D consistent results with significant boosts in prompt alignment with human intention. Our results demonstrate the great potential for learning from human feedback to improve text-to-3D models.
3.7. GVGEN: Text-to-3D Generation with Volumetric Representation

In recent years, 3D Gaussian splatting has emerged as a powerful technique for 3D reconstruction and generation, known for its fast and high-quality rendering capabilities.
To address these shortcomings, this paper introduces a novel diffusion-based framework, GVGEN, designed to efficiently generate 3D Gaussian representations from text input. We propose two innovative techniques:(1) Structured Volumetric Representation. We first arrange disorganized 3D Gaussian points as a structured form of GaussianVolume.
This transformation allows the capture of intricate texture details within a volume composed of a fixed number of Gaussians. To better optimize the representation of these details, we propose a unique pruning and densifying method named the Candidate Pool Strategy, enhancing detail fidelity through selective optimization. (2) Coarse-to-fine Generation Pipeline. To simplify the generation of Gaussian volume and empower the model to generate instances with detailed 3D geometry, we propose a coarse-to-fine pipeline.
It initially constructs a basic geometric structure, followed by the prediction of complete Gaussian attributes. Our framework, GVGEN, demonstrates superior performance in qualitative and quantitative assessments compared to existing 3D generation methods. Simultaneously, it maintains a fast generation speed (sim7 seconds), effectively striking a balance between quality and efficiency.
3.8. Magic Fixup: Streamlining Photo Editing by Watching Dynamic Videos

We propose a generative model that, given a coarsely edited image, synthesizes a photorealistic output that follows the prescribed layout. Our method transfers fine details from the original image and preserves the identity of its parts. Yet, it adapts it to the lighting and context defined by the new layout.
Our key insight is that videos are a powerful source of supervision for this task: objects and camera motions provide many observations of how the world changes with viewpoint, lighting, and physical interactions. We construct an image dataset in which each sample is a pair of source and target frames extracted from the same video at randomly chosen time intervals.
We warp the source frame toward the target using two motion models that mimic the expected test-time user edits. We supervise our model to translate the warped image into the ground truth, starting from a pretrained diffusion model.
Our model design explicitly enables fine detail transfer from the source frame to the generated image, while closely following the user-specified layout. We show that by using simple segmentations and coarse 2D manipulations, we can synthesize a photorealistic edit faithful to the user’s input while addressing second-order effects like harmonizing the lighting and physical interactions between edited objects.
3.9. Compress3D: a Compressed Latent Space for 3D Generation from a Single Image

3D generation has witnessed significant advancements, yet efficiently producing high-quality 3D assets from a single image remains challenging. In this paper, we present a triplane autoencoder, which encodes 3D models into a compact triplane latent space to effectively compress both the 3D geometry and texture information.
Within the autoencoder framework, we introduce a 3D-aware cross-attention mechanism, which utilizes low-resolution latent representations to query features from a high-resolution 3D feature volume, thereby enhancing the representation capacity of the latent space. Subsequently, we train a diffusion model on this refined latent space.
In contrast to solely relying on image embedding for 3D generation, our proposed method advocates for the simultaneous utilization of both image embedding and shape embedding as conditions. Specifically, the shape embedding is estimated via a diffusion prior model conditioned on the image embedding.
Through comprehensive experiments, we demonstrate that our method outperforms state-of-the-art algorithms, achieving superior performance while requiring less training data and time. Our approach enables the generation of high-quality 3D assets in merely 7 seconds on a single A100 GPU.
4. Video Generation & Editing
4.1. VideoAgent: Long-form Video Understanding with Large Language Model as Agent

Long-form video understanding represents a significant challenge within computer vision, demanding a model capable of reasoning over long multi-modal sequences.
Motivated by the human cognitive process for long-form video understanding, we emphasize interactive reasoning and planning over the ability to process lengthy visual inputs. We introduce a novel agent-based system, VideoAgent, that employs a large language model as a central agent to iteratively identify and compile crucial information to answer a question, with vision-language foundation models serving as tools to translate and retrieve visual information.
Evaluated on the challenging EgoSchema and NExT-QA benchmarks, VideoAgent achieves 54.1% and 71.3% zero-shot accuracy with only 8.4 and 8.2 frames used on average.
These results demonstrate the superior effectiveness and efficiency of our method over the current state-of-the-art methods, highlighting the potential of agent-based approaches in advancing long-form video understanding.
4.2. SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion

We present Stable Video 3D (SV3D) — a latent video diffusion model for high-resolution, image-to-multi-view generation of orbital videos around a 3D object. Recent work on 3D generation proposes techniques to adapt 2D generative models for novel view synthesis (NVS) and 3D optimization.
However, these methods have several disadvantages due to either limited views or inconsistent NVS, thereby affecting the performance of 3D object generation. In this work, we propose SV3D that adapts an image-to-video diffusion model for novel multi-view synthesis and 3D generation, thereby leveraging the generalization and multi-view consistency of the video models, while further adding explicit camera control for NVS.
We also propose improved 3D optimization techniques to use SV3D and its NVS outputs for image-to-3D generation. Extensive experimental results on multiple datasets with 2D and 3D metrics as well as user studies demonstrate SV3D’s state-of-the-art performance on NVS as well as 3D reconstruction compared to prior works.
4.3. Vid2Robot: End-to-end Video-conditioned Policy Learning with Cross-Attention Transformers

While large-scale robotic systems typically rely on textual instructions for tasks, this work explores a different approach: can robots infer the task directly from observing humans? This shift necessitates the robot’s ability to decode human intent and translate it into executable actions within its physical constraints and environment.
We introduce Vid2Robot, a novel end-to-end video-based learning framework for robots. Given a video demonstration of a manipulation task and current visual observations, Vid2Robot directly produces robot actions. This is achieved through a unified representation model trained on a large dataset of human video and robot trajectory.
The model leverages cross-attention mechanisms to fuse prompt video features to the robot’s current state and generate appropriate actions that mimic the observed task. To further improve policy performance, we propose auxiliary contrastive losses that enhance the alignment between human and robot video representations.
We evaluate Vid2Robot on real-world robots, demonstrating a 20% improvement in performance compared to other video-conditioned policies when using human demonstration videos.
Additionally, our model exhibits emergent capabilities, such as successfully transferring observed motions from one object to another, and long-horizon composition, thus showcasing its potential for real-world applications. Project website: vid2robot.github.io
4.4. VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding

We explore how reconciling several foundation models (large language models and vision-language models) with a novel unified memory mechanism could tackle the challenging video understanding problem, especially capturing the long-term temporal relations in lengthy videos.
In particular, the proposed multimodal agent VideoAgent: 1) constructs a structured memory to store both the generic temporal event descriptions and object-centric tracking states of the video; 2) given an input task query, it employs tools including video segment localization and object memory querying along with other visual foundation models to interactively solve the task, utilizing the zero-shot tool-use ability of LLMs.
VideoAgent demonstrates impressive performances on several long-horizon video understanding benchmarks, an average increase of 6.6% on NExT-QA and 26.0% on EgoSchema over baselines, closing the gap between open-sourced models and private counterparts including Gemini 1.5 Pro.
4.5. FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation

The remarkable efficacy of text-to-image diffusion models has motivated extensive exploration of their potential application in video domains. Zero-shot methods seek to extend image diffusion models to videos without necessitating model training.
Recent methods mainly focus on incorporating inter-frame correspondence into attention mechanisms. However, the soft constraint imposed on determining where to attend to valid features can sometimes be insufficient, resulting in temporal inconsistency.
In this paper, we introduce FRESCO, intra-frame correspondence alongside inter-frame correspondence to establish a more robust spatial-temporal constraint. This enhancement ensures a more consistent transformation of semantically similar content across frames.
Beyond mere attention guidance, our approach involves an explicit update of features to achieve high spatial-temporal consistency with the input video, significantly improving the visual coherence of the resulting translated videos.
Extensive experiments demonstrate the effectiveness of our proposed framework in producing high-quality, coherent videos, marking a notable improvement over existing zero-shot methods.
4.5. Mora: Enabling Generalist Video Generation via A Multi-Agent Framework

Sora is the first large-scale generalist video generation model that garnered significant attention across society. Since its launch by OpenAI in February 2024, no other video generation models have paralleled {Sora}’s performance or its capacity to support a broad spectrum of video generation tasks.
Additionally, there are only a few fully published video generation models, with the majority being closed-source. To address this gap, this paper proposes a new multi-agent framework Mora, which incorporates several advanced visual AI agents to replicate generalist video generation demonstrated by Sora.
In particular, Mora can utilize multiple visual agents and successfully mimic Sora’s video generation capabilities in various tasks, such as (1) text-to-video generation, (2) text-conditional image-to-video generation, (3) extend-generated videos, (4) video-to-video editing, (5) connect videos and (6) simulate digital worlds.
Our extensive experimental results show that Mora achieves performance that is proximate to that of Sora in various tasks. However, there exists an obvious performance gap between our work and Sora when assessed holistically. In summary, we hope this project can guide the future trajectory of video generation through collaborative AI agents.
4.6. AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks

Video-to-video editing involves editing a source video along with additional control (such as text prompts, subjects, or styles) to generate a new video that aligns with the source video and the provided control. Traditional methods have been constrained to certain editing types, limiting their ability to meet the wide range of user demands.
In this paper, we introduce AnyV2V, a novel training-free framework designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model (e.g. InstructPix2Pix, InstantID, etc) to modify the first frame, (2) utilizing an existing image-to-video generation model (e.g. I2VGen-XL) for DDIM inversion and feature injection.
In the first stage, AnyV2V can plug in any existing image editing tools to support an extensive array of video editing tasks. Beyond the traditional prompt-based editing methods, AnyV2V also can support novel video editing tasks, including reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods.
In the second stage, AnyV2V can plug in any existing image-to-video models to perform DDIM inversion and intermediate feature injection to maintain the appearance and motion consistency with the source video. On the prompt-based editing, we show that AnyV2V can outperform the previous best approach by 35\% on prompt alignment, and 25\% on human preference.
On the three novel tasks, we show that AnyV2V also achieves a high success rate. We believe AnyV2V will continue to thrive due to its ability to seamlessly integrate fast-evolving image editing methods. Such compatibility can help AnyV2V to increase its versatility to cater to diverse user demands.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
