


Top Important Computer Vision Papers for the Week from 16/10 to 22/10
Stay Relevant to Recent Computer Vision Research

On a weekly basis, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the third week of October 2023, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Vision Langauge Models
Video Analysis
Image & Video Generation
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
1. Vision Langauge Models
1.1. PaLI-3 Vision Language Models: Smaller, Faster, Stronger
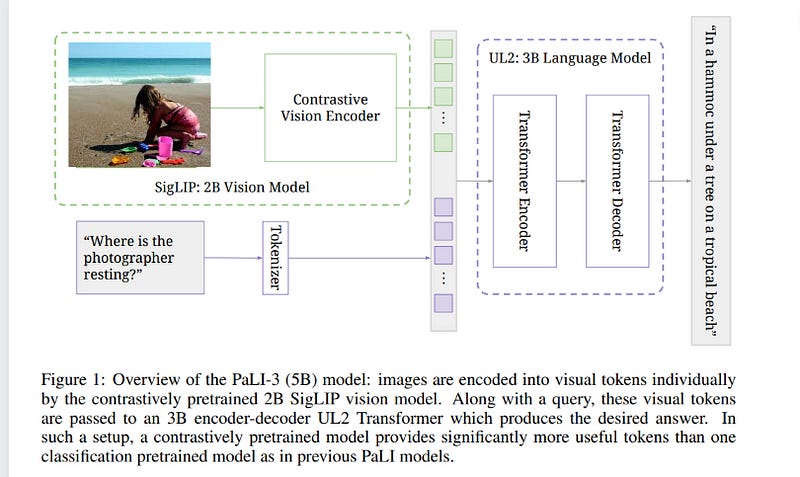
This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, the authors compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively (SigLIP) pretrained ones.
They find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and visually situated text understanding.
They scale the SigLIP image encoder up to 2 billion parameters and achieve a new state-of-the-art multilingual cross-modal retrieval. The authors hope that PaLI-3, at only 5B parameters, rekindles research on fundamental pieces of complex VLMs, and could fuel a new generation of scaled-up models.
1.2. Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning

Reinforcement learning (RL) requires either manually specifying a reward function, which is often infeasible, or learning a reward model from a large amount of human feedback, which is often very expensive.
The authors study a more sample-efficient alternative: using pretrained vision-language models (VLMs) as zero-shot reward models (RMs) to specify tasks via natural language. They propose a natural and general approach to using VLMs as reward models, which they call VLM-RMs.
We use VLM-RMs based on CLIP to train a MuJoCo humanoid to learn complex tasks without a manually specified reward function, such as kneeling, doing the splits, and sitting in a lotus position. For each of these tasks, we only provide a single-sentence text prompt describing the desired task with minimal prompt engineering. We provide videos of the trained agents at: https://sites.google.com/view/vlm-rm. We can improve performance by providing a second ``baseline’’ prompt and projecting out parts of the CLIP embedding space irrelevant to distinguish between goal and baseline.
Further, we find a strong scaling effect for VLM-RMs: larger VLMs trained with more computing and data are better reward models. The failure modes of VLM-RMs we encountered are all related to known capability limitations of current VLMs, such as limited spatial reasoning ability or visually unrealistic environments that are far off-distribution for the VLM. We find that VLM-RMs are remarkably robust as long as the VLM is large enough. This suggests that future VLMs will become more and more useful reward models for a wide range of RL applications.
1.3. An Image is Worth Multiple Words: Learning Object Level Concepts using Multi-Concept Prompt Learning

Textural Inversion, a prompt learning method, learns a singular embedding for a new “word” to represent image style and appearance, allowing it to be integrated into natural language sentences to generate novel synthesized images.
However, identifying and integrating multiple object-level concepts within one scene poses significant challenges even when embeddings for individual concepts are attainable. This is further confirmed by the empirical tests. To address this challenge, the authors introduce a framework for Multi-Concept Prompt Learning (MCPL), where multiple new “words” are simultaneously learned from a single sentence-image pair.
To enhance the accuracy of word-concept correlation, they propose three regularisation techniques: Attention Masking (AttnMask) to concentrate learning on relevant areas; Prompts Contrastive Loss (PromptCL) to separate the embeddings of different concepts; and Bind adjective (Bind adj.) to associate new “words” with known words.
They evaluate via image generation, editing, and attention visualization with diverse images. Extensive quantitative comparisons demonstrate that our method can learn more semantically disentangled concepts with enhanced word-concept correlation. Additionally, they introduce a novel dataset and evaluation protocol tailored for this new task of learning object-level concepts.
2. Video Analysis
2.1. Video Language Planning
The authors are interested in enabling visual planning for complex long-horizon tasks in the space of generated videos and language, leveraging recent advances in large generative models pretrained on Internet-scale data.
To this end, they present video language planning (VLP), an algorithm that consists of a tree search procedure, where they train
Vision-language models serve as both policies and value functions
Text-to-video models as dynamics models.
VLP takes as input a long-horizon task instruction and current image observation and outputs a long video plan that provides detailed multimodal (video and language) specifications that describe how to complete the final task. VLP scales with an increasing computation budget where more computation time results in improved video plans, and is able to synthesize long-horizon video plans across different robotics domains: from multi-object rearrangement to multi-camera bi-arm dexterous manipulation.
Generated video plans can be translated into real robot actions via goal-conditioned policies, conditioned on each intermediate frame of the generated video. Experiments show that VLP substantially improves long-horizon task success rates compared to prior methods on both simulated and real robots (across 3 hardware platforms).
3. Image & Video Generation
3.1. 4K4D: Real-Time 4D View Synthesis at 4K Resolution

This paper targets high-fidelity and real-time view synthesis of dynamic 3D scenes at 4K resolution. Recently, some methods of dynamic view synthesis have shown impressive rendering quality. However, their speed is still limited when rendering high-resolution images.
To overcome this problem, the authors propose 4K4D, a 4D point cloud representation that supports hardware rasterization and enables unprecedented rendering speed. This representation is built on a 4D feature grid so that the points are naturally regularized and can be robustly optimized. In addition, they designed a novel hybrid appearance model that significantly boosts the rendering quality while preserving efficiency. Moreover, they develop a differentiable depth peeling algorithm to effectively learn the proposed model from RGB videos.
Experiments show that our representation can be rendered at over 400 FPS on the DNA-Rendering dataset at 1080p resolution and 80 FPS on the ENeRF-Outdoor dataset at 4K resolution using an RTX 4090 GPU, which is 30x faster than previous methods and achieves the state-of-the-art rendering quality. We will release the code for reproducibility.
3.2. EvalCrafter: Benchmarking and Evaluating Large Video Generation Models
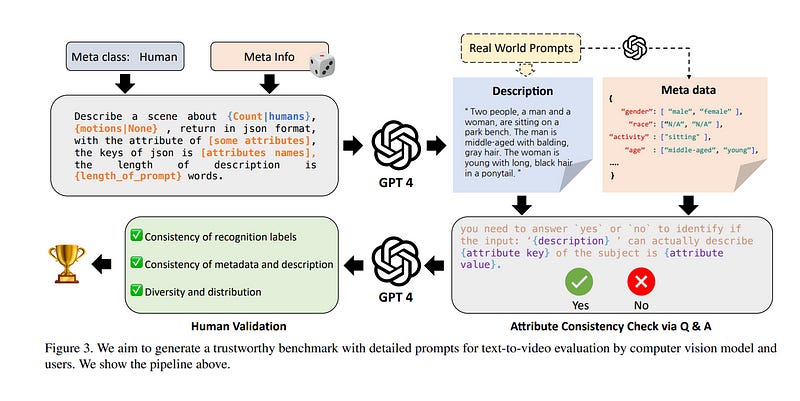
The vision and language generative models have been overgrown in recent years. For video generation, various open-sourced models and public-available services are released for generating high-visual quality videos. However, these methods often use a few academic metrics, for example, FVD or IS, to evaluate the performance.
The researchers argue that it is hard to judge the large conditional generative models from the simple metrics since these models are often trained on very large datasets with multi-aspect abilities. Thus, they propose a new framework and pipeline to exhaustively evaluate the performance of the generated videos. To achieve this, they first conduct a new prompt list for text-to-video generation by analyzing the real-world prompt list with the help of the large language model.
Then, they evaluate the state-of-the-art video generative models on our carefully designed benchmarks, in terms of visual qualities, content qualities, motion qualities, and text-caption alignment with around 18 objective metrics.
To obtain the final leaderboard of the models, they also fit a series of coefficients to align the objective metrics to the users’ opinions. Based on the proposed opinion alignment method, our final score shows a higher correlation than simply averaging the metrics, showing the effectiveness of the proposed evaluation method.
3.3. LAMP: Learn A Motion Pattern for Few-Shot-Based Video Generation

With the impressive progress in diffusion-based text-to-image generation, extending such powerful generative ability to text-to-video raises enormous attention. Existing methods either require large-scale text-video pairs and a large number of training resources or learn motions that are precisely aligned with template videos.
It is non-trivial to balance a trade-off between the degree of generation freedom and the resource costs for video generation. In this study, the authors present a few-shot-based tuning framework, LAMP, which enables text-to-image diffusion models to Learn A specific Motion Pattern with 8~16 videos on a single GPU.
Specifically, they design a first-frame-conditioned pipeline that uses an off-the-shelf text-to-image model for content generation so that the tuned video diffusion model mainly focuses on motion learning. The well-developed text-to-image techniques can provide visually pleasing and diverse content as generation conditions, which highly improves video quality and generation freedom.
To capture the features of temporal dimension, they expand the pretrained 2D convolution layers of the T2I model to our novel temporal-spatial motion learning layers and modify the attention blocks to the temporal level.
Additionally, they developed an effective inference trick, shared-noise sampling, which can improve the stability of videos with computational costs. Our method can also be flexibly applied to other tasks, e.g. real-world image animation and video editing. Extensive experiments demonstrate that LAMP can effectively learn the motion pattern on limited data and generate high-quality videos.
3.4. Progressive3D: Progressively Local Editing for Text-to-3D Content Creation with Complex Semantic Prompts

Recent text-to-3D generation methods achieve impressive 3D content creation capacity thanks to the advances in image diffusion models and optimizing strategies. However, current methods struggle to generate correct 3D content for a complex prompt in semantics, i.e., a prompt describing multiple interacted objects binding with different attributes.
In this work, the authors propose a general framework named Progressive3D, which decomposes the entire generation into a series of locally progressive editing steps to create precise 3D content for complex prompts, and they constrain the content change to only occur in regions determined by user-defined region prompts in each editing step.
Furthermore, they propose an overlapped semantic component suppression technique to encourage the optimization process to focus more on the semantic differences between prompts. Extensive experiments demonstrate that the proposed Progressive3D framework generates precise 3D content for prompts with complex semantics and is general for various text-to-3D methods driven by different 3D representations.
3.5. 3D-GPT: Procedural 3D Modeling with Large Language Models

In the pursuit of efficient automated content creation, procedural generation, leveraging modifiable parameters and rule-based systems, emerges as a promising approach. Nonetheless, it could be a demanding endeavor, given its intricate nature necessitating a deep understanding of rules, algorithms, and parameters.
To reduce workload, the authors introduce 3D-GPT, a framework utilizing large language models~(LLMs) for instruction-driven 3D modeling. 3D-GPT positions LLMs as proficient problem solvers, dissecting the procedural 3D modeling tasks into accessible segments and appointing the apt agent for each task. 3D-GPT integrates three core agents: the task dispatch agent, the conceptualization agent, and the modeling agent. They collaboratively achieve two objectives.
First, it enhances concise initial scene descriptions, evolving them into detailed forms while dynamically adapting the text based on subsequent instructions. Second, it integrates procedural generation, extracting parameter values from enriched text to effortlessly interface with 3D software for asset creation.
Our empirical investigations confirm that 3D-GPT not only interprets and executes instructions, delivering reliable results but also collaborates effectively with human designers. Furthermore, it seamlessly integrates with Blender, unlocking expanded manipulation possibilities. Our work highlights the potential of LLMs in 3D modeling, offering a basic framework for future advancements in scene generation and animation.
3.6. Enhancing High-Resolution 3D Generation through Pixel-wise Gradient Clipping

High-resolution 3D object generation remains a challenging task primarily due to the limited availability of comprehensive annotated training data. Recent advancements have aimed to overcome this constraint by harnessing image generative models, pretrained on extensively curated web datasets, and using knowledge transfer techniques like Score Distillation Sampling (SDS).
Efficiently addressing the requirements of high-resolution rendering often necessitates the adoption of latent representation-based models, such as the Latent Diffusion Model (LDM). In this framework, a significant challenge arises: To compute gradients for individual image pixels, it is necessary to backpropagate gradients from the designated latent space through the frozen components of the image model, such as the VAE encoder used within LDM.
However, this gradient propagation pathway has never been optimized, remaining uncontrolled during training. They find that the unregulated gradients adversely affect the 3D model’s capacity to acquire texture-related information from the image generative model, leading to poor quality appearance synthesis.
To address this overarching challenge, we propose an innovative operation termed Pixel-wise Gradient Clipping (PGC) designed for seamless integration into existing 3D generative models, thereby enhancing their synthesis quality.
Specifically, they control the magnitude of stochastic gradients by clipping the pixel-wise gradients efficiently, while preserving crucial texture-related gradient directions. Despite this simplicity and minimal extra cost, extensive experiments demonstrate the efficacy of our PGC in enhancing the performance of existing 3D generative models for high-resolution object rendering.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Thanks for sharing