


Top Important Computer Vision Papers for the Week from 29/04 to 05/05
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the First Week of May 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. Stylus: Automatic Adapter Selection for Diffusion Models

Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high-fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters-most of which are highly customized with insufficient descriptions.
This paper explores the problem of matching the prompt to a set of relevant adapters, built on recent work that highlight the performance gains of composing adapters. We introduce Stylus, which efficiently selects and automatically composes task-specific adapters based on a prompt’s keywords.
Stylus outlines a three-stage approach that first summarizes adapters with improved descriptions and embeddings, retrieves relevant adapters, and then further assembles adapters based on prompts’ keywords by checking how well they fit the prompt. To evaluate Stylus, we developed StylusDocs, a curated dataset featuring 75K adapters with pre-computed adapter embeddings.
In our evaluation of popular Stable Diffusion checkpoints, Stylus achieves greater CLIP-FID Pareto efficiency and is twice as preferred, with humans and multimodal models as evaluators, over the base model.
1.2. StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation

For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge.
In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pretrained diffusion-based text-to-image models in a zero-shot manner.
To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces.
This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation.
By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a wide variety of contents.
The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications.
2. Vision Language Models (VLMs)
2.1. BlenderAlchemy: Editing 3D Graphics with Vision-Language Models
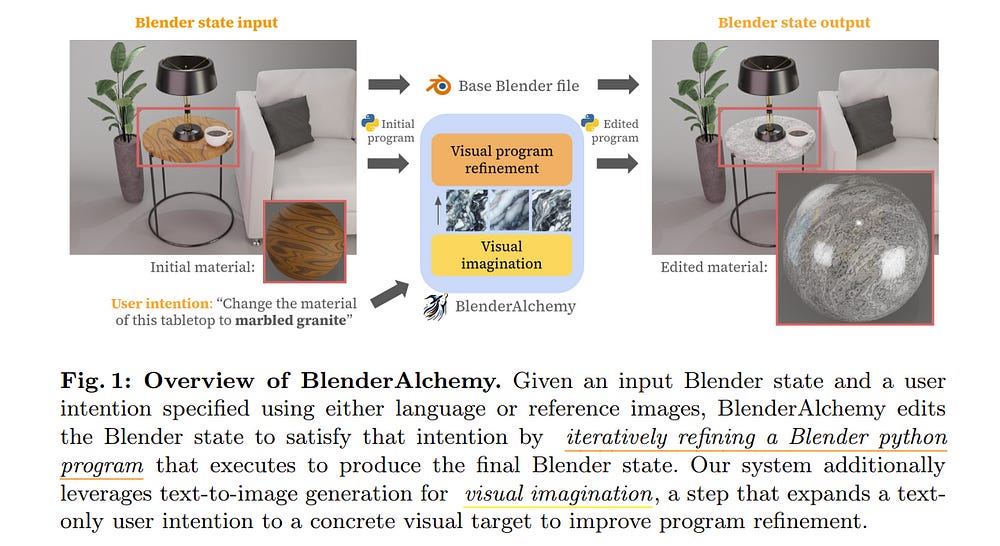
Graphics design is important for various applications, including movie production and game design. To create a high-quality scene, designers usually need to spend hours in software like Blender, in which they might need to interleave and repeat operations, such as connecting material nodes, hundreds of times.
Moreover, slightly different design goals may require completely different sequences, making automation difficult. In this paper, we propose a system that leverages Vision-Language Models (VLMs), like GPT-4V, to intelligently search the design action space to arrive at an answer that can satisfy a user’s intent.
Specifically, we design a vision-based edit generator and state evaluator to work together to find the correct sequence of actions to achieve the goal. Inspired by the role of visual imagination in the human design process, we supplement the visual reasoning capabilities of VLMs with “imagined” reference images from image-generation models, providing visual grounding of abstract language descriptions.
In this paper, we provide empirical evidence suggesting our system can produce simple but tedious Blender editing sequences for tasks such as editing procedural materials from text and/or reference images, as well as adjusting lighting configurations for product renderings in complex scenes.
2.2. Visual Fact Checker: Enabling High-Fidelity Detailed Caption Generation

Existing automatic captioning methods for visual content face challenges such as lack of detail, content hallucination, and poor instruction.
In this work, we propose VisualFactChecker (VFC), a flexible training-free pipeline that generates high-fidelity and detailed captions for both 2D images and 3D objects.
VFC consists of three steps:
Proposal: where image-to-text captioning models propose multiple initial captions
Verification: where a large language model (LLM) utilizes tools such as object detection and VQA models to fact-check proposed captions;
Captioning: where an LLM generates the final caption by summarizing caption proposals and the fact check verification results.
In this step, VFC can flexibly generate captions in various styles following complex instructions. We conduct comprehensive captioning evaluations using four metrics:
CLIP-Score for image-text similarity
CLIP-Image-Score for measuring the image-image similarity between the original and the reconstructed image generated by a text-to-image model using the caption
Human Study on Amazon Mechanical Turk
GPT-4V for fine-grained evaluation. Evaluation results show that VFC outperforms state-of-the-art open-sourced captioning methods for 2D images on the COCO dataset and 3D assets on the Objaverse dataset
Our study demonstrates that by combining open-source models into a pipeline, we can attain captioning capability comparable to proprietary models such as GPT-4V, despite being over 10x smaller in model size.
2.3. DOCCI: Descriptions of Connected and Contrasting Images

Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models.
To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated, and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more.
We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges.
Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation — a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B.
Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
3. Image Generation & Editing
3.1. MaPa: Text-driven Photorealistic Material Painting for 3D Shapes

This paper aims to generate materials for 3D meshes from text descriptions. Unlike existing methods that synthesize texture maps, we propose to generate segment-wise procedural material graphs as the appearance representation, which supports high-quality rendering and provides substantial flexibility in editing.
Instead of relying on extensive paired data, i.e., 3D meshes with material graphs and corresponding text descriptions, to train a material graph generative model, we propose to leverage the pre-trained 2D diffusion model as a bridge to connect the text and material graphs.
Specifically, our approach decomposes a shape into a set of segments and designs a segment-controlled diffusion model to synthesize 2D images that are aligned with mesh parts. Based on generated images, we initialize the parameters of material graphs and fine-tune them through the differentiable rendering module to produce materials in accordance with the textual description.
Extensive experiments demonstrate the superior performance of our framework in photorealism, resolution, and editability over existing methods.
3.2. Customizing Text-to-Image Models with a Single Image Pair
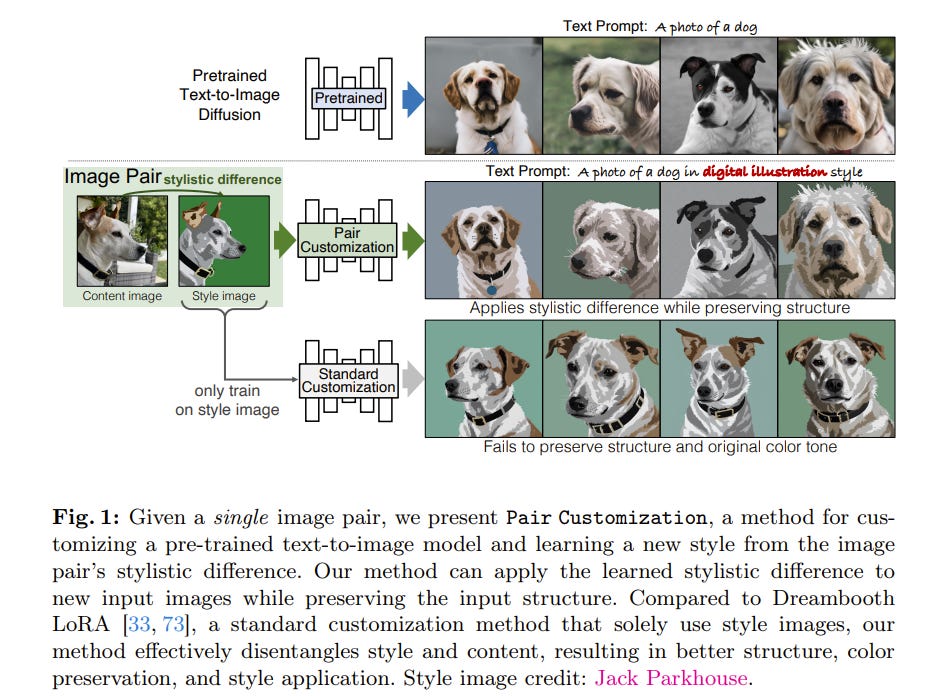
Art reinterpretation is the practice of creating a variation of a reference work, making a paired artwork that exhibits a distinct artistic style. We ask if such an image pair can be used to customize a generative model to capture the demonstrated stylistic difference.
We propose Pair Customization, a new customization method that learns stylistic differences from a single image pair and then applies the acquired style to the generation process. Unlike existing methods that learn to mimic a single concept from a collection of images, our method captures the stylistic difference between paired images.
This allows us to apply a stylistic change without overfitting the specific image content in the examples. To address this new task, we employ a joint optimization method that explicitly separates the style and content into distinct LoRA weight spaces.
We optimize these style and content weights to reproduce the style and content images while encouraging their orthogonality. During inference, we modify the diffusion process via a new style of guidance based on our learned weights.
Both qualitative and quantitative experiments show that our method can effectively learn style while avoiding overfitting to image content, highlighting the potential of modeling such stylistic differences from a single image pair.
3.3. Paint by Inpaint: Learning to Add Image Objects by Removing Them First

Image editing has advanced significantly with the introduction of text-conditioned diffusion models. Despite this progress, seamlessly adding objects to images based on textual instructions without requiring user-provided input masks remains a challenge.
We address this by leveraging the insight that removing objects (Inpaint) is significantly simpler than its inverse process of adding them (Paint), attributed to the utilization of segmentation mask datasets alongside inpainting models that in paint within these masks.
Capitalizing on this realization, by implementing an automated and extensive pipeline, we curate a filtered large-scale image dataset containing pairs of images and their corresponding object-removed versions.
Using these pairs, we train a diffusion model to inverse the inpainting process, effectively adding objects into images. Unlike other editing datasets, ours features natural target images instead of synthetic ones; moreover, it maintains consistency between source and target by construction.
Additionally, we utilize a large Vision-Language Model to provide detailed descriptions of the removed objects and a Large Language Model to convert these descriptions into diverse, natural-language instructions. We show that the trained model surpasses existing ones both qualitatively and quantitatively, and release the large-scale dataset alongside the trained models for the community.
3.4. InstantFamily: Masked Attention for Zero-shot Multi-ID Image Generation

In the field of personalized image generation, the ability to create image-preserving concepts has significantly improved. Creating an image that naturally integrates multiple concepts in a cohesive and visually appealing composition can indeed be challenging.
This paper introduces “InstantFamily,” an approach that employs a novel masked cross-attention mechanism and a multimodal embedding stack to achieve zero-shot multi-ID image generation. Our method effectively preserves ID as it utilizes global and local features from a pre-trained face recognition model integrated with text conditions.
Additionally, our masked cross-attention mechanism enables the precise control of multi-ID and composition in the generated images. We demonstrate the effectiveness of InstantFamily through experiments showing its dominance in generating images with multi-ID while resolving well-known multi-ID generation problems.
Additionally, our model achieves state-of-the-art performance in both single-ID and multi-ID preservation. Furthermore, our model exhibits remarkable scalability with a greater number of ID preservations than it was originally trained with.
3.5. DressCode: Autoregressively Sewing and Generating Garments from Text Guidance

Apparel’s significant role in human appearance underscores the importance of garment digitalization for digital human creation. Recent advances in 3D content creation are pivotal for digital human creation. Nonetheless, garment generation from text guidance is still nascent.
We introduce a text-driven 3D garment generation framework, DressCode, which aims to democratize design for novices and offer immense potential in fashion design, virtual try-ons, and digital human creation. For our framework, we first introduce SewingGPT, a GPT-based architecture integrating cross-attention with text-conditioned embedding to generate sewing patterns with text guidance.
We also tailored a pre-trained Stable Diffusion for high-quality, tile-based PBR texture generation. By leveraging a large language model, our framework generates CG-friendly garments through natural language interaction. Our method also facilitates pattern completion and texture editing, simplifying the process for designers by user-friendly interaction.
With comprehensive evaluations and comparisons with other state-of-the-art methods, our method showcases the best quality and alignment with input prompts. User studies further validate our high-quality rendering results, highlighting its practical utility and potential in production settings.
4. Video Understanding & Generation
4.1. PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning

Vision-language pre-training has significantly elevated performance across a wide range of image-language applications. Yet, the pre-training process for video-related tasks demands exceptionally large computational and data resources, which hinders the progress of video-language models.
This paper investigates a straightforward, highly efficient, and resource-light approach to adapting an existing image-language pre-trained model for dense video understanding.
Our preliminary experiments reveal that directly fine-tuning pre-trained image-language models with multiple frames as inputs on video datasets leads to performance saturation or even a drop.
Our further investigation reveals that it is largely attributed to the bias of learned high-norm visual features. Motivated by this finding, we propose a simple but effective pooling strategy to smooth the feature distribution along the temporal dimension and thus reduce the dominant impacts from the extreme features.
The new model is termed Pooling LLaVA, or in short. achieves new state-of-the-art performance on modern benchmark datasets for both video question-answer and captioning tasks.
Notably, on the recent popular Video ChatGPT benchmark, PLLaVA achieves a score of 3.48 out of 5 on average of five evaluated dimensions, exceeding the previous SOTA results from GPT4V (IG-VLM) by 9\%. On the latest multi-choice benchmark MVBench, PLLaVA achieves 58.1\% accuracy on average across 20 sub-tasks, 14.5\% higher than GPT4V (IG-VLM).
4.2. MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model

This work introduces MotionLCM, extending controllable motion generation to a real-time level. Existing methods for spatial control in text-conditioned motion generation suffer from significant runtime inefficiency.
To address this issue, we first propose the motion latent consistency model (MotionLCM) for motion generation, building upon the latent diffusion model (MLD). By employing one-step (or few-step) inference, we further improve the runtime efficiency of the motion latent diffusion model for motion generation.
To ensure effective controllability, we incorporate a motion ControlNet within the latent space of MotionLCM and enable explicit control signals (e.g., pelvis trajectory) in the vanilla motion space to control the generation process directly, similar to controlling other latent-free diffusion models for motion generation.
By employing these techniques, our approach can generate human motions with text and control signals in real time. Experimental results demonstrate the remarkable generation and controlling capabilities of MotionLCM while maintaining real-time runtime efficiency.
4.3. STT: Stateful Tracking with Transformers for Autonomous Driving
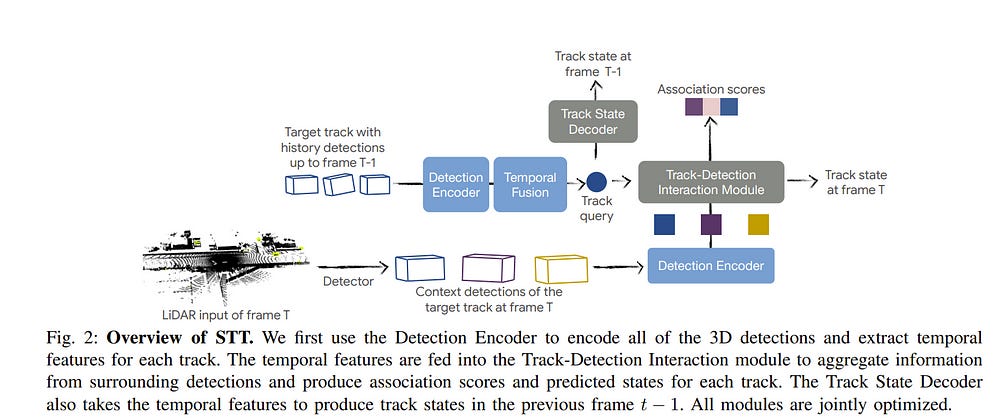
Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present.
Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately.
STT consumes rich appearance, geometry, and motion signals through long-term history of detections and is jointly optimized for both data association and state estimation tasks.
Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
