


Top Important Computer Vision Papers for the Week from 12/08 to 18/08
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Third Week of August 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
Image Editing & Generation
Image Segmentation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs.
1. Diffusion Models
1.1. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer

We introduce CogVideoX, a large-scale diffusion transformer model designed for generating videos based on text prompts. To efficiently model video data, we propose to leverage a 3D Variational Autoencoder (VAE) to compress videos along both spatial and temporal dimensions.
To improve the text-video alignment, we propose an expert transformer with the expert adaptive LayerNorm to facilitate the deep fusion between the two modalities. By employing a progressive training technique, CogVideoX is adept at producing coherent, long-duration videos characterized by significant motions.
In addition, we develop an effective text-video data processing pipeline that includes various data preprocessing strategies and a video captioning method.
It significantly helps enhance the performance of CogVideoX, improving both generation quality and semantic alignment. Results show that CogVideoX demonstrates state-of-the-art performance across both multiple machine metrics and human evaluations.
1.2. DC3DO: Diffusion Classifier for 3D Objects

Inspired by Geoffrey Hinton's emphasis on generative modeling, To recognize shapes, and first learn to generate them, we explore the use of 3D diffusion models for object classification.
Leveraging the density estimates from these models, our approach, the Diffusion Classifier for 3D Objects (DC3DO), enables zero-shot classification of 3D shapes without additional training. On average, our method achieves a 12.5 percent improvement compared to its multiview counterparts, demonstrating superior multimodal reasoning over discriminative approaches.
DC3DO employs a class-conditional diffusion model trained on ShapeNet, and we run inferences on point clouds of chairs and cars. This work highlights the potential of generative models in 3D object classification.
2. Vision Language Models (VLMs)
2.1. mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models

Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in executing instructions for a variety of single-image tasks. Despite this progress, significant challenges remain in modeling long image sequences.
In this work, we introduce the versatile multi-modal large language model, mPLUG-Owl3, which enhances the capability for long image-sequence understanding in scenarios that incorporate retrieved image-text knowledge, interleaved image-text, and lengthy videos.
Specifically, we propose novel hyper-attention blocks to efficiently integrate vision and language into a common language-guided semantic space, thereby facilitating the processing of extended multi-image scenarios.
Extensive experimental results suggest that mPLUG-Owl3 achieves state-of-the-art performance among models with a similar size on single-image, multi-image, and video benchmarks.
Moreover, we propose a challenging long visual sequence evaluation named Distractor Resistance to assess the ability of models to maintain focus amidst distractions.
Finally, with the proposed architecture, mPLUG-Owl3 demonstrates outstanding performance on ultra-long visual sequence inputs. We hope that mPLUG-Owl3 can contribute to the development of more efficient and powerful multimodal large language models.
2.2. UniBench: Visual Reasoning Requires Rethinking Vision-Language Beyond Scaling
Significant research efforts have been made to scale and improve vision-language model (VLM) training approaches. Yet, with an ever-growing number of benchmarks, researchers are tasked with the heavy burden of implementing each protocol, bearing a non-trivial computational cost, and making sense of how all these benchmarks translate into meaningful axes of progress.
To facilitate a systematic evaluation of VLM progress, we introduce UniBench: a unified implementation of 50+ VLM benchmarks spanning a comprehensive range of carefully categorized capabilities from object recognition to spatial awareness, counting, and much more. We showcase the utility of UniBench for measuring progress by evaluating nearly 60 publicly available vision-language models, trained on scales of up to 12.8B samples.
We find that while scaling training data or model size can boost many vision-language model capabilities, scaling offers little benefit for reasoning or relations. Surprisingly, we also discover today’s best VLMs struggle with simple digit recognition and counting tasks, e.g. MNIST, which much simpler networks can solve.
Where scale falls short, we find that more precise interventions, such as data quality or tailored learning objectives offer more promise. For practitioners, we also offer guidance on selecting a suitable VLM for a given application. Finally, we release an easy-to-run UniBench code-base with the full set of 50+ benchmarks and comparisons across 59 models as well as a distilled, representative set of benchmarks that runs in 5 minutes on a single GPU.
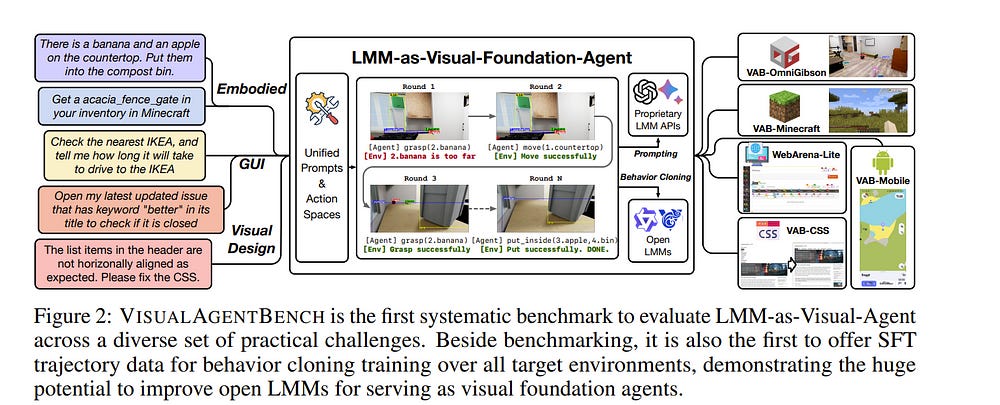
2.3. VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
Large Multimodal Models (LMMs) have ushered in a new era in artificial intelligence, merging capabilities in both language and vision to form highly capable Visual Foundation Agents.
These agents are postulated to excel across a myriad of tasks, potentially approaching general artificial intelligence. However, existing benchmarks fail to sufficiently challenge or showcase the full potential of LMMs in complex, real-world environments.
To address this gap, we introduce VisualAgentBench (VAB), a comprehensive and pioneering benchmark specifically designed to train and evaluate LMMs as visual foundation agents across diverse scenarios, including Embodied, Graphical User Interface, and Visual Design, with tasks formulated to probe the depth of LMMs’ understanding and interaction capabilities.
Through rigorous testing across nine proprietary LMM APIs and eight open models, we demonstrate the considerable yet still developing agent capabilities of these models.
Additionally, VAB constructs a trajectory training set constructed through hybrid methods including Program-based Solvers, LMM Agent Bootstrapping, and Human Demonstrations, promoting substantial performance improvements in LMMs through behavior cloning.
Our work not only aims to benchmark existing models but also provides a solid foundation for future development into visual foundation agents.
2.4. Imagen 3

We introduce Imagen 3, a latent diffusion model that generates high-quality images from text prompts. We describe our quality and responsibility evaluations.
Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
2.5. Generative Photomontage
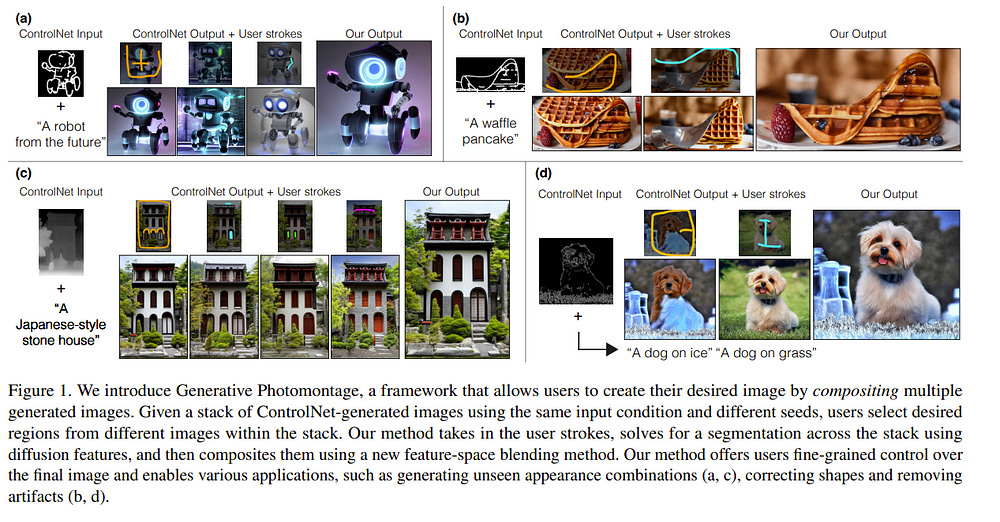
Text-to-image models are powerful tools for image creation. However, the generation process is akin to a dice roll and makes it difficult to achieve a single image that captures everything a user wants.
In this paper, we propose a framework for creating the desired image by compositing it from various parts of generated images, in essence forming a Generative Photomontage. Given a stack of images generated by ControlNet using the same input condition and different seeds, we let users select desired parts from the generated results using a brush stroke interface.
We introduce a novel technique that takes in the user’s brush strokes, segments the generated images using a graph-based optimization in diffusion feature space, and then composites the segmented regions via a new feature-space blending method.
Our method faithfully preserves the user-selected regions while compositing them harmoniously. We demonstrate that our flexible framework can be used for many applications, including generating new appearance combinations, fixing incorrect shapes and artifacts, and improving prompt alignment.
We show compelling results for each application and demonstrate that our method outperforms existing image-blending methods and various baselines.
2.6. Towards flexible perception with visual memory

Training a neural network is a monolithic endeavor, akin to carving knowledge into stone: once the process is completed, editing the knowledge in a network is nearly impossible, since all information is distributed across the network’s weights.
We here explore a simple, compelling alternative by marrying the representational power of deep neural networks with the flexibility of a database.
Decomposing the task of image classification into image similarity (from a pre-trained embedding) and search (via fast nearest neighbor retrieval from a knowledge database), we build a simple and flexible visual memory that has the following key capabilities:
The ability to flexibly add data across scales: from individual samples all the way to entire classes and billion-scale data.
The ability to remove data through unlearning and memory pruning.
An interpretable decision-mechanism on which we can intervene to control its behavior.
Taken together, these capabilities comprehensively demonstrate the benefits of an explicit visual memory. We hope that it might contribute to a conversation on how knowledge should be represented in deep vision models — beyond carving it in ``stone’’ weights.
3. Video Understanding & Generation
3.1. ControlNeXt: Powerful and Efficient Control for Image and Video Generation

Diffusion models have demonstrated remarkable and robust abilities in both image and video generation. To achieve greater control over generated results, researchers introduce additional architectures, such as ControlNet, Adapters, and ReferenceNet, to integrate conditioning controls.
However, current controllable generation methods often require substantial additional computational resources, especially for video generation, and face challenges in training or exhibit weak control. In this paper, we propose ControlNeXt: a powerful and efficient method for controllable image and video generation.
We first design a more straightforward and efficient architecture, replacing heavy additional branches with minimal additional cost compared to the base model. Such a concise structure also allows our method to seamlessly integrate with other LoRA weights, enabling style alteration without the need for additional training. As for training, we reduce up to 90% of learnable parameters compared to the alternatives.
Furthermore, we propose another method called Cross Normalization (CN) as a replacement for Zero-Convolution’ to achieve fast and stable training convergence. We have conducted various experiments with different base models across images and videos, demonstrating the robustness of our method.
3.2. FancyVideo: Towards Dynamic and Consistent Video Generation via Cross-frame Textual Guidance

Synthesizing motion-rich and temporally consistent videos remains a challenge in artificial intelligence, especially when dealing with extended durations. Existing text-to-video (T2V) models commonly employ spatial cross-attention for text control, equivalently guiding different frame generations without frame-specific textual guidance.
Thus, the model’s capacity to comprehend the temporal logic conveyed in prompts and generate videos with coherent motion is restricted. To tackle this limitation, we introduce FancyVideo, an innovative video generator that improves the existing text-control mechanism with the well-designed Cross-frame Textual Guidance Module (CTGM).
Specifically, CTGM incorporates the Temporal Information Injector (TII), Temporal Affinity Refiner (TAR), and Temporal Feature Booster (TFB) at the beginning, middle, and end of cross-attention, respectively, to achieve frame-specific textual guidance. Firstly, TII injects frame-specific information from latent features into text conditions, thereby obtaining cross-frame textual conditions.
Then, TAR refines the correlation matrix between cross-frame textual conditions and latent features along the time dimension. Lastly, TFB boosts the temporal consistency of latent features. Extensive experiments comprising both quantitative and qualitative evaluations demonstrate the effectiveness of FancyVideo.
Our approach achieves state-of-the-art T2V generation results on the EvalCrafter benchmark and facilitates the synthesis of dynamic and consistent videos.
4. Image Editing & Generation
4.1. HeadGAP: Few-shot 3D Head Avatar via Generalizable Gaussian Priors

In this paper, we present a novel 3D head avatar creation approach capable of generalizing from few-shot in-the-wild data with high-fidelity and animatable robustness. Given the underconstrained nature of this problem, incorporating prior knowledge is essential.
Therefore, we propose a framework comprising prior learning and avatar creation phases. The prior learning phase leverages 3D head priors derived from a large-scale multi-view dynamic dataset, and the avatar creation phase applies these priors for few-shot personalization.
Our approach effectively captures these priors by utilizing a Gaussian Splatting-based auto-decoder network with part-based dynamic modeling. Our method employs identity-shared encoding with personalized latent codes for individual identities to learn the attributes of Gaussian primitives.
During the avatar creation phase, we achieve fast head avatar personalization by leveraging inversion and fine-tuning strategies. Extensive experiments demonstrate that our model effectively exploits head priors and successfully generalizes them to few-shot personalization, achieving photo-realistic rendering quality, multi-view consistency, and stable animation.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
