


Top Important Computer Vision Papers for the Week from 25/9 to 1/10
Stay Relevant to Recent Computer Vision Research

On a weekly basis, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
In this article, we will provide a comprehensive overview of the most significant papers published in the last week of September 2023, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of contents:
Image Recognition
Image & Video Generation
3D Computer Vision
Image Segmentation
Video Analysis
Are you looking to start a career in data science and AI and need to learn how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
All the resources and tools you need to teach yourself Data Science for free!
The best interactive roadmaps for Data Science roles. With links to free learning resources. Start here: https://aigents.co/learn/roadmaps/intro
The search engine for Data Science learning recourses. 100K handpicked articles and tutorials. With GPT-powered summaries and explanations. https://aigents.co/learn
Teach yourself Data Science with the help of an AI tutor (powered by GPT-4). https://community.aigents.co/spaces/10362739/
1. Image Recognition
1.1. DualToken-ViT: Position-aware Efficient Vision Transformer with Dual Token Fusion

Self-attention-based vision transformers (ViTs) have emerged as a highly competitive architecture in computer vision. Unlike convolutional neural networks (CNNs), ViTs are capable of global information sharing.
With the development of various structures of ViTs, ViTs are increasingly advantageous for many vision tasks. However, the quadratic complexity of self-attention renders ViTs computationally intensive, and their lack of inductive biases of locality and translation equivariance demands larger model sizes compared to CNNs to effectively learn visual features. In this paper, we propose a lightweight and efficient vision transformer model called DualToken-ViT that leverages the advantages of CNNs and ViTs.
DualToken-ViT effectively fuses the token with local information obtained by a convolution-based structure and the token with global information obtained by a self-attention-based structure to achieve an efficient attention structure. In addition, we use position-aware global tokens throughout all stages to enrich the global information, which further strengthens the effect of DualToken-ViT.
Position-aware global tokens also contain the position information of the image, which makes our model better for vision tasks. We conducted extensive experiments on image classification, object detection, and semantic segmentation tasks to demonstrate the effectiveness of DualToken-ViT. On the ImageNet-1K dataset, our models of different scales achieve accuracies of 75.4% and 79.4% with only 0.5G and 1.0G FLOPs, respectively, and our model with 1.0G FLOPs outperforms LightViT-T using global tokens by 0.7%.
2. Image & Video Generation
2.1. VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning

Although recent text-to-video (T2V) generation methods have seen significant advancements, most of these works focus on producing short video clips of a single event with a single background (i.e., single-scene videos).
Meanwhile, recent large language models (LLMs) have demonstrated their capability in generating layouts and programs to control downstream visual modules such as image generation models. This raises an important question: can we leverage the knowledge embedded in these LLMs for temporally consistent long video generation? In this paper, we propose VideoDirectorGPT, a novel framework for consistent multi-scene video generation that uses the knowledge of LLMs for video content planning and grounded video generation.
Specifically, given a single text prompt, we first ask our video planner LLM (GPT-4) to expand it into a ‘video plan’, which involves generating the scene descriptions, the entities with their respective layouts, the background for each scene, and consistency groupings of the entities and backgrounds. Next, guided by this output from the video planner, our video generator, Layout2Vid, has explicit control over spatial layouts and can maintain temporal consistency of entities/backgrounds across scenes, while only trained with image-level annotations.
Our experiments demonstrate that the VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation and can generate multi-scene videos with visual consistency across scenes while achieving competitive performance with SOTAs in open-domain single-scene T2V generation. We also demonstrate that our framework can dynamically control the strength for layout guidance and can generate videos with user-provided images. We hope our framework can inspire future work on better integrating the planning ability of LLMs into consistent long video generation.
2.2. LAVIE: High-Quality Video Generation with Cascaded Latent Diffusion Models

This work aims to learn a high-quality text-to-video (T2V) generative model by leveraging a pre-trained text-to-image (T2I) model as a basis. It is a highly desirable yet challenging task to simultaneously a) accomplish the synthesis of visually realistic and temporally coherent videos while b) preserve the strong creative generation nature of the pre-trained T2I model. To this end, we propose LaVie, an integrated video generation framework that operates on cascaded video latent diffusion models, comprising a base T2V model, a temporal interpolation model, and a video super-resolution model.
Our key insights are two-fold:
We reveal that the incorporation of simple temporal self-attentions, coupled with rotary positional encoding, adequately captures the temporal correlations inherent in video data.
Additionally, we validate that the process of joint image-video fine-tuning plays a pivotal role in producing high-quality and creative outcomes.
To enhance the performance of LaVie, we contribute a comprehensive and diverse video dataset named Vimeo25M, consisting of 25 million text-video pairs that prioritize quality, diversity, and aesthetic appeal. Extensive experiments demonstrate that LaVie achieves state-of-the-art performance both quantitatively and qualitatively. Furthermore, we showcase the versatility of pre-trained LaVie models in various long video generation and personalized video synthesis applications.
2.3. Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack

Training text-to-image models with web-scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images.
This creates the need for aesthetic alignment post-pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve generation quality. We pre-train a latent diffusion model on 1.1 billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images.
The resulting model, Emu, achieves a win rate of 82.9% compared with its pre-trained counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred 68.4% and 71.3% of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
2.4. Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation

Significant advancements have been achieved in the realm of large-scale pre-trained text-to-video Diffusion Models (VDMs). However, previous methods either rely solely on pixel-based VDMs, which come with high computational costs, or on latent-based VDMs, which often struggle with precise text-video alignment.
In this paper, we are the first to propose a hybrid model, dubbed as Show-1, which marries pixel-based and latent-based VDMs for text-to-video generation. Our model first uses pixel-based VDMs to produce a low-resolution video of strong text-video correlation.
After that, we propose a novel expert translation method that employs the latent-based VDMs to further upsample the low-resolution video to high resolution. Compared to latent VDMs, Show-1 can produce high-quality videos of precise text-video alignment; Compared to pixel VDMs, Show-1 is much more efficient (GPU memory usage during inference is 15G vs 72G). We also validate our model on standard video generation benchmarks.
3. 3D Computer Vision
3.1. DECO: Dense Estimation of 3D Human-Scene Contact In The Wild
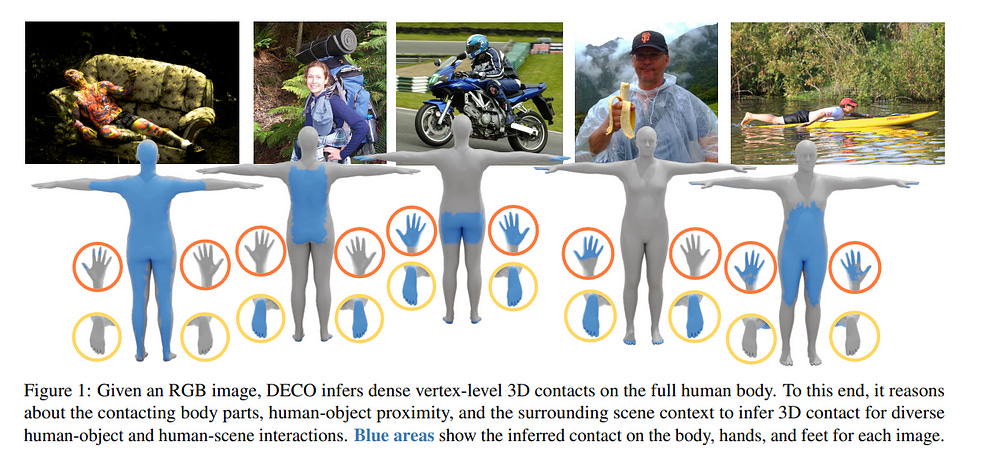
Understanding how humans use physical contact to interact with the world is key to enabling human-centric artificial intelligence. While inferring 3D contact is crucial for modeling realistic and physically plausible human-object interactions, existing methods either focus on 2D, consider body joints rather than the surface, use coarse 3D body regions, or do not generalize to in-the-wild images.
In contrast, we focus on inferring dense, 3D contact between the full body surface and objects in arbitrary images. To achieve this, we first collect DAMON, a new dataset containing dense vertex-level contact annotations paired with RGB images containing complex human-object and human-scene contact. Second, we train DECO, a novel 3D contact detector that uses both body-part-driven and scene-context-driven attention to estimate vertex-level contact on the SMPL body.
DECO builds on the insight that human observers recognize contact by reasoning about the contacting body parts, their proximity to scene objects, and the surrounding scene context. We perform extensive evaluations of our detector on DAMON as well as on the RICH and BEHAVE datasets. We significantly outperform existing SOTA methods across all benchmarks. We also show qualitatively that DECO generalizes well to diverse and challenging real-world human interactions in natural images.
4. Image Segmentation
4.1. MosaicFusion: Diffusion Models as Data Augmenters for Large Vocabulary Instance Segmentation
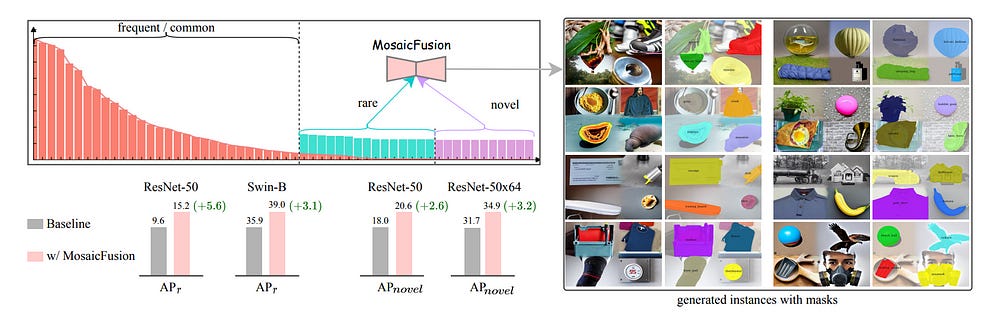
We present MosaicFusion, a simple yet effective diffusion-based data augmentation approach for large vocabulary instance segmentation. Our method is training-free and does not rely on any label supervision.
Two key designs enable us to employ an off-the-shelf text-to-image diffusion model as a useful dataset generator for object instances and mask annotations.
First, we divide an image canvas into several regions and perform a single round of diffusion process to generate multiple instances simultaneously, conditioning on different text prompts.
Second, we obtain corresponding instance masks by aggregating cross-attention maps associated with object prompts across layers and diffusion time steps, followed by simple thresholding and edge-aware refinement processing.
Without bells and whistles, our MosaicFusion can produce a significant amount of synthetic labeled data for both rare and novel categories. Experimental results on the challenging LVIS long-tailed and open-vocabulary benchmarks demonstrate that MosaicFusion can significantly improve the performance of existing instance segmentation models, especially for rare and novel categories.
5. Video Analysis
5.1. VidChapters-7M: Video Chapters at Scale

Segmenting long videos into chapters enables users to quickly navigate to the information of their interest. This important topic has been understudied due to the lack of publicly released datasets. To address this issue, we present VidChapters-7M, a dataset of 817K user-chaptered videos including 7M chapters in total. VidChapters-7M is automatically created from videos online in a scalable manner by scraping user-annotated chapters and hence without any additional manual annotation. We introduce the following three tasks based on this data. First, the video chapter generation task consists of temporally segmenting the video and generating a chapter title for each segment. To further dissect the problem, we also define two variants of this task: video chapter generation given ground-truth boundaries, which requires generating a chapter title given an annotated video segment, and video chapter grounding, which requires temporally localizing a chapter given its annotated title. We benchmark both simple baselines and state-of-the-art video-language models for these three tasks. We also show that pretraining on VidChapters-7M transfers well to dense video captioning tasks in both zero-shot and finetuning settings, largely improving the state of the art on the YouCook2 and ViTT benchmarks. Finally, our experiments reveal that downstream performance scales well with the size of the pretraining dataset.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Looking to start a career in data science and AI do not know how. I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM

Thanks for sharing youssef