


Top Important Computer Vision Papers for the Week from 19/02 to 25/02
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Fourth Week of February 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Image Generation & Editing
Video Generation & Editing
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion

In this work, we tackle the challenging problem of denoising hand-object interactions (HOI). Given an erroneous interaction sequence, the objective is to refine the incorrect hand trajectory to remove interaction artifacts for a perceptually realistic sequence.
This challenge involves intricate interaction noise, including unnatural hand poses and incorrect hand-object relations, alongside the necessity for robust generalization to new interactions and diverse noise patterns. We tackle those challenges through a novel approach, GeneOH Diffusion, incorporating two key designs: an innovative contact-centric HOI representation named GeneOH and a new domain-generalizable denoising scheme.
The contact-centric representation GeneOH informatively parameterizes the HOI process, facilitating enhanced generalization across various HOI scenarios. The new denoising scheme consists of a canonical denoising model trained to project noisy data samples from a whitened noise space to a clean data manifold and a “denoising via diffusion” strategy which can handle input trajectories with various noise patterns by first diffusing them to align with the whitened noise space and cleaning via the canonical denoiser.
Extensive experiments on four benchmarks with significant domain variations demonstrate the superior effectiveness of our method. GeneOH Diffusion also shows promise for various downstream applications.
1.2. T-Stitch: Accelerating Sampling in Pre-Trained Diffusion Models with Trajectory Stitching
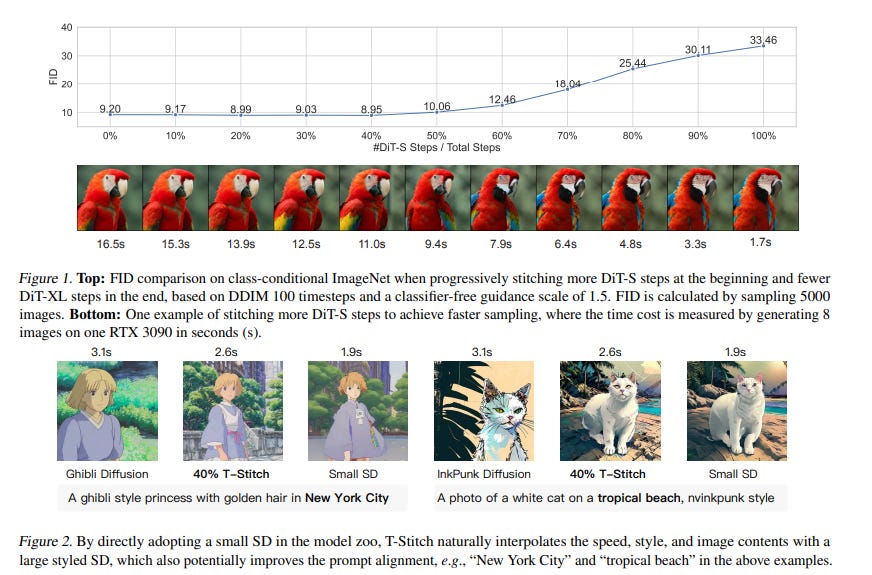
Sampling from diffusion probabilistic models (DPMs) is often expensive for high-quality image generation and typically requires many steps with a large model. In this paper, the authors introduce sampling Trajectory Stitching T-Stitch, a simple yet efficient technique to improve the sampling efficiency with little or no generation degradation.
Instead of solely using a large DPM for the entire sampling trajectory, T-Stitch first leverages a smaller DPM in the initial steps as a cheap drop-in replacement of the larger DPM and switches to the larger DPM at a later stage. Our key insight is that different diffusion models learn similar encodings under the same training data distribution and smaller models are capable of generating good global structures in the early steps.
Extensive experiments demonstrate that T-Stitch is training-free, generally applicable for different architectures, and complements most existing fast sampling techniques with flexible speed and quality trade-offs. On DiT-XL, for example, 40% of the early timesteps can be safely replaced with a 10x faster DiT-S without a performance drop on class-conditional ImageNet generation.
We further show that our method can also be used as a drop-in technique to not only accelerate the popular pretrained stable diffusion (SD) models but also improve the prompt alignment of stylized SD models from the public model zoo.
1.3. MVD$²$: Efficient Multiview 3D Reconstruction for Multiview Diffusion

As a promising 3D generation technique, multiview diffusion (MVD) has received a lot of attention due to its advantages in terms of generalizability, quality, and efficiency. By finetuning pretrained large image diffusion models with 3D data, the MVD methods first generate multiple views of a 3D object based on an image or text prompt and then reconstruct 3D shapes with multiview 3D reconstruction.
However, the sparse views and inconsistent details in the generated images make 3D reconstruction challenging. We present MVD², an efficient 3D reconstruction method for multiview diffusion (MVD) images. MVD² aggregates image features into a 3D feature volume by projection and convolution and then decodes volumetric features into a 3D mesh. We train MVD² with 3D shape collections and MVD images prompted by rendered views of 3D shapes.
To address the discrepancy between the generated multiview images and ground-truth views of the 3D shapes, we design an efficient view-dependent training scheme. MVD² improves the 3D generation quality of MVD and is fast and robust to various MVD methods. After training, it can efficiently decode 3D meshes from multiview images within one second.
We train MVD² with Zero-123++ and ObjectVerse-LVIS 3D dataset and demonstrate its superior performance in generating 3D models from multiview images generated by different MVD methods, using both synthetic and real images as prompts.
1.4. SDXL-Lightning: Progressive Adversarial Diffusion Distillation

We propose a diffusion distillation method that achieves new state-of-the-art in one-step/few-step 1024px text-to-image generation based on SDXL. Our method combines progressive and adversarial distillation to achieve a balance between quality and mode coverage.
In this paper, we discuss the theoretical analysis, discriminator design, model formulation, and training techniques. We open-source our distilled SDXL-Lightning models both as LoRA and full UNet weights.
1.5. Neural Network Diffusion

Diffusion models have achieved remarkable success in image and video generation. In this work, we demonstrate that diffusion models can also generate high-performing neural network parameters.
This approach is simple, utilizing an autoencoder and a standard latent diffusion model. The autoencoder extracts latent representations of a subset of the trained network parameters. A diffusion model is then trained to synthesize these latent parameter representations from random noise.
It then generates new representations that are passed through the autoencoder’s decoder, whose outputs are ready to use as new subsets of network parameters. Across various architectures and datasets, our diffusion process consistently generates models of comparable or improved performance over trained networks, with minimal additional cost.
Notably, we empirically find that the generated models perform differently with the trained networks. Our results encourage more exploration of the versatile use of diffusion models.
1.6. MVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction

This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses.
MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas:
A ``pose-free architecture’’ where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information.
A ``view dropout strategy’’ that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time.
We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.
1.7. DiLightNet: Fine-grained Lighting Control for Diffusion-based Image Generation

This paper presents a novel method for exerting fine-grained lighting control during text-driven diffusion-based image generation. While existing diffusion models already have the ability to generate images under any lighting condition, without additional guidance these models tend to correlate image content and lighting.
Moreover, text prompts lack the necessary expressional power to describe detailed lighting setups. To provide the content creator with fine-grained control over the lighting during image generation, we augment the text prompt with detailed lighting information in the form of radiance hints, i.e., visualizations of the scene geometry with a homogeneous canonical material under the target lighting. However, the scene geometry needed to produce the radiance hints is unknown.
Our key observation is that we only need to guide the diffusion process, hence exact radiance hints are not necessary; we only need to point the diffusion model in the right direction. Based on this observation, we introduce a three-stage method for controlling the lighting during image generation.
In the first stage, we leverage a standard pretrained diffusion model to generate a provisional image under uncontrolled lighting. Next, in the second stage, we resynthesize and refine the foreground object in the generated image by passing the target lighting to a refined diffusion model, named DiLightNet, using radiance hints computed on a coarse shape of the foreground object inferred from the provisional image.
To retain the texture details, we multiply the radiance hints with a neural encoding of the provisional synthesized image before passing it to DiLightNet. Finally, in the third stage, we resynthesize the background to be consistent with the lighting on the foreground object. We demonstrate and validate our lighting-controlled diffusion model on a variety of text prompts and lighting conditions.
1.8. Make a Cheap Scaling: A Self-Cascade Diffusion Model for Higher-Resolution Adaptation

Diffusion models have proven to be highly effective in image and video generation; however, they still face composition challenges when generating images of varying sizes due to single-scale training data. Adapting large pre-trained diffusion models for higher resolution demands substantial computational and optimization resources, yet achieving a generation capability comparable to low-resolution models remains elusive.
This paper proposes a novel self-cascade diffusion model that leverages the rich knowledge gained from a well-trained low-resolution model for rapid adaptation to higher-resolution image and video generation, employing either tuning-free or cheap upsampler tuning paradigms. Integrating a sequence of multi-scale upsampler modules, the self-cascade diffusion model can efficiently adapt to a higher resolution, preserving the original composition and generation capabilities.
We further propose a pivot-guided noise re-schedule strategy to speed up the inference process and improve local structural details. Compared to full fine-tuning, our approach achieves a 5X training speed-up and requires only an additional 0.002M tuning parameters. Extensive experiments demonstrate that our approach can quickly adapt to higher-resolution image and video synthesis by fine-tuning for just 10k steps, with virtually no additional inference time.
2. Vision Language Models
2.1. PaLM2-VAdapter: Progressively Aligned Language Model Makes a Strong Vision-language Adapter

This paper demonstrates that a progressively aligned language model can effectively bridge frozen vision encoders and large language models (LLMs). While the fundamental architecture and pre-training methods of vision encoders and LLMs have been extensively studied, the architecture and training strategy of vision-language adapters varies significantly across recent works.
Our research undertakes a thorough exploration of the state-of-the-art perceiver resampler architecture and builds a strong baseline. However, we observe that the vision-language alignment with the perceiver resampler exhibits slow convergence and limited scalability with a lack of direct supervision. To address this issue, we propose a PaLM2-VAdapter, employing a progressively aligned language model as the vision-language adapter. Compared to the strong baseline with perceiver resampler, our method empirically shows faster convergence, higher performance, and stronger scalability.
Extensive experiments across various Visual Questioning (VQA) and captioning tasks on both images and videos demonstrate that our model exhibits state-of-the-art visual understanding and multi-modal reasoning capabilities. Notably, our method achieves these advancements with 30~70% fewer parameters than the state-of-the-art large vision-language models, marking a significant efficiency improvement.
2.2. BBA: Bi-Modal Behavioral Alignment for Reasoning with Large Vision-Language Models

Multimodal reasoning stands as a pivotal capability for large vision-language models (LVLMs). The integration with Domain-Specific Languages (DSL), offering precise visual representations, equips these models with the opportunity to execute more accurate reasoning in complex and professional domains.
However, the vanilla Chain-of-Thought (CoT) prompting method faces challenges in effectively leveraging the unique strengths of visual and DSL representations, primarily due to their differing reasoning mechanisms. Additionally, it often falls short in addressing critical steps in multi-step reasoning tasks. To mitigate these challenges, we introduce the Bi-Modal Behavioral Alignment (BBA) prompting method, designed to maximize the potential of DSL in augmenting complex multi-modal reasoning tasks.
This method initiates by guiding LVLMs to create separate reasoning chains for visual and DSL representations. Subsequently, it aligns these chains by addressing any inconsistencies, thus achieving a cohesive integration of behaviors from different modalities.
Our experiments demonstrate that BBA substantially improves the performance of GPT-4V(ision) on geometry problem solving (28.34% to 34.22%), chess positional advantage prediction (42.08% to 46.99%), and molecular property prediction (77.47% to 83.52%).
2.3. Vision-Flan: Scaling Human-Labeled Tasks in Visual Instruction Tuning

Despite vision-language models’ (VLMs) remarkable capabilities as versatile visual assistants, two substantial challenges persist within the existing VLM frameworks:
Lacking task diversity in pretraining and visual instruction tuning,
Annotation error and bias in GPT-4 synthesized instruction tuning data.
Both challenges lead to issues such as poor generalizability, hallucination, and catastrophic forgetting. To address these challenges, we construct Vision-Flan, the most diverse publicly available visual instruction tuning dataset to date, comprising 187 diverse tasks and 1,664,261 instances sourced from academic datasets, and each task is accompanied by an expert-written instruction.
In addition, we propose a two-stage instruction tuning framework, in which VLMs are firstly finetuned on Vision-Flan and further tuned on GPT-4 synthesized data. We find this two-stage tuning framework significantly outperforms the traditional single-stage visual instruction tuning framework and achieves state-of-the-art performance across a wide range of multi-modal evaluation benchmarks.
Finally, we conduct in-depth analyses to understand visual instruction tuning and our findings reveal that:
GPT-4 synthesized data does not substantially enhance VLMs’ capabilities but rather modulates the model’s responses to human-preferred formats.
A minimal quantity (e.g., 1,000) of GPT-4 synthesized data can effectively align VLM responses with human preference.
Visual instruction tuning mainly helps large-language models (LLMs) to understand visual features.
2.4. CoLLaVO: Crayon Large Language and Vision mOdel

The remarkable success of Large Language Models (LLMs) and instruction tuning drives the evolution of Vision Language Models (VLMs) towards a versatile general-purpose model.
Yet, it remains unexplored whether current VLMs genuinely possess quality object-level image understanding capabilities determined from ‘what objects are in the image?’ or ‘which object corresponds to a specified bounding box?’. Our findings reveal that the image understanding capabilities of current VLMs are strongly correlated with their zero-shot performance on Vision Language (VL) tasks.
This suggests that prioritizing basic image understanding is crucial for VLMs to excel at VL tasks. To enhance object-level image understanding, we propose Crayon Large Language and Vision mOdel (CoLLaVO), which incorporates instruction tuning with a crayon prompt as a new visual prompt tuning scheme based on panoptic color maps.
Furthermore, we present a learning strategy of Dual QLoRA to preserve object-level image understanding without forgetting it during visual instruction tuning, thereby achieving a significant leap in zero-shot numerous VL benchmarks.
3. Image Generation & Editing
3.1. Consolidating Attention Features for Multi-view Image Editing

Large-scale text-to-image models enable a wide range of image editing techniques, using text prompts or even spatial controls. However, applying these editing methods to multi-view images depicting a single scene leads to 3D-inconsistent results. In this work, we focus on spatial control-based geometric manipulations and introduce a method to consolidate the editing process across various views.
We build on two insights:
Maintaining consistent features throughout the generative process helps attain consistency in multi-view editing.
The queries in self-attention layers significantly influence the image structure. Hence, we propose to improve the geometric consistency of the edited images by enforcing the consistency of the queries.
To do so, we introduce QNeRF, a neural radiance field trained on the internal query features of the edited images. Once trained, QNeRF can render 3D-consistent queries, which are then softly injected back into the self-attention layers during generation, greatly improving multi-view consistency. We refine the process through a progressive, iterative method that better consolidates queries across the diffusion timesteps.
We compare our method to a range of existing techniques and demonstrate that it can achieve better multi-view consistency and higher fidelity to the input scene. These advantages allow us to train NeRFs with fewer visual artifacts, that are better aligned with the target geometry.
4. Video Understanding, Generation & Editing
4.1. Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis

Contemporary models for generating images show remarkable quality and versatility. Swayed by these advantages, the research community repurposes them to generate videos. Since video content is highly redundant, we argue that naively bringing advances of image models to the video generation domain reduces motion fidelity, and visual quality and impairs scalability.
In this work, we build Snap Video, a video-first model that systematically addresses these challenges. To do that, we first extend the EDM framework to take into account spatially and temporally redundant pixels and naturally support video generation. Second, we show that a U-Net — a workhorse behind image generation — scales poorly when generating videos, requiring significant computational overhead.
Hence, we propose a new transformer-based architecture that trains 3.31 times faster than U-Nets (and is ~4.5 faster at inference). This allows us to efficiently train a text-to-video model with billions of parameters for the first time, reach state-of-the-art results on several benchmarks, and generate videos with substantially higher quality, temporal consistency, and motion complexity. The user studies showed that our model was favored by a large margin over the most recent methods.
4.2. GaussianPro: 3D Gaussian Splatting with Progressive Propagation

The advent of 3D Gaussian Splatting (3DGS) has recently brought about a revolution in the field of neural rendering, facilitating high-quality renderings at real-time speed. However, 3DGS heavily depends on the initialized point cloud produced by Structure-from-Motion (SfM) techniques.
When tackling large-scale scenes that unavoidably contain texture-less surfaces, the SfM techniques always fail to produce enough points in these surfaces and cannot provide good initialization for 3DGS. As a result, 3DGS suffers from difficult optimization and low-quality renderings.
In this paper, inspired by classical multi-view stereo (MVS) techniques, we propose GaussianPro, a novel method that applies a progressive propagation strategy to guide the densification of the 3D Gaussians.
Compared to the simple split and clone strategies used in 3DGS, our method leverages the priors of the existing reconstructed geometries of the scene and patch-matching techniques to produce new Gaussians with accurate positions and orientations.
Experiments on both large-scale and small-scale scenes validate the effectiveness of our method, where our method significantly surpasses 3DGS on the Waymo dataset, exhibiting an improvement of 1.15dB in terms of PSNR.
4.3. Video Recap: Recursive Captioning of Hour-Long Videos
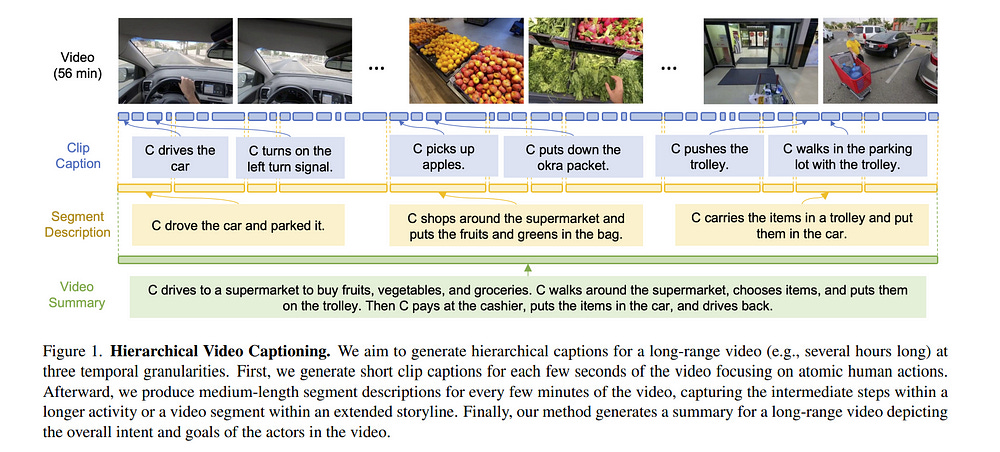
Most video captioning models are designed to process short video clips of a few seconds and output text describing low-level visual concepts (e.g., objects, scenes, atomic actions).
However, most real-world videos last for minutes or hours and have a complex hierarchical structure spanning different temporal granularities. We propose Video ReCap, a recursive video captioning model that can process video inputs of dramatically different lengths (from 1 second to 2 hours) and output video captions at multiple hierarchy levels. The recursive video-language architecture exploits the synergy between different video hierarchies and can process hour-long videos efficiently.
We utilize a curriculum learning training scheme to learn the hierarchical structure of videos, starting from clip-level captions describing atomic actions, then focusing on segment-level descriptions, and concluding with generating summaries for hour-long videos.
Furthermore, we introduce the Ego4D-HCap dataset by augmenting Ego4D with 8,267 manually collected long-range video summaries. Our recursive model can flexibly generate captions at different hierarchy levels while also being useful for other complex video understanding tasks, such as VideoQA on EgoSchema.
4.4. VideoPrism: A Foundational Visual Encoder for Video Understanding

We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pre-train VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts).
The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos.
We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 30 out of 33 video understanding benchmarks.
4.5. LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing
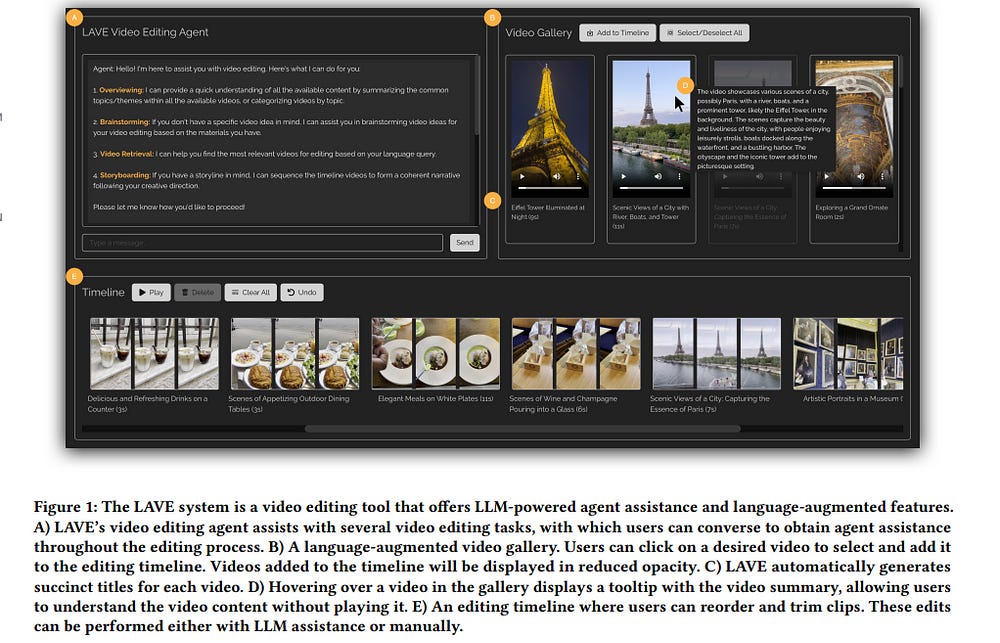
Video creation has become increasingly popular, yet the expertise and effort required for editing often pose barriers to beginners. In this paper, we explore the integration of large language models (LLMs) into the video editing workflow to reduce these barriers.
Our design vision is embodied in LAVE, a novel system that provides LLM-powered agent assistance and language-augmented editing features. LAVE automatically generates language descriptions for the user’s footage, serving as the foundation for enabling the LLM to process videos and assist in editing tasks. When the user provides editing objectives, the agent plans and executes relevant actions to fulfill them.
Moreover, LAVE allows users to edit videos through either the agent or direct UI manipulation, providing flexibility and enabling manual refinement of agent actions. Our user study, which included eight participants ranging from novices to proficient editors, demonstrated LAVE’s effectiveness.
The results also shed light on user perceptions of the proposed LLM-assisted editing paradigm and its impact on users’ creativity and sense of co-creation. Based on these findings, we propose design implications to inform the future development of agent-assisted content editing.
5. Image Recognition & Object Detection
5.1. Subobject-level Image Tokenization

Transformer-based vision models typically tokenize images into fixed-size square patches as input units, which lacks the adaptability to image content and overlooks the inherent pixel grouping structure.
Inspired by the subword tokenization widely adopted in language models, we propose an image tokenizer at a subobject level, where the subobjects are represented by semantically meaningful image segments obtained by segmentation models (e.g., segment anything models).
To implement a learning system based on subobject tokenization, we first introduced a Sequence-to-sequence AutoEncoder (SeqAE) to compress subobject segments of varying sizes and shapes into compact embedding vectors, then fed the subobject embeddings into a large language model for vision language learning.
Empirical results demonstrated that our subobject-level tokenization significantly facilitates efficient learning of translating images into object and attribute descriptions compared to the traditional patch-level tokenization.
5.2. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
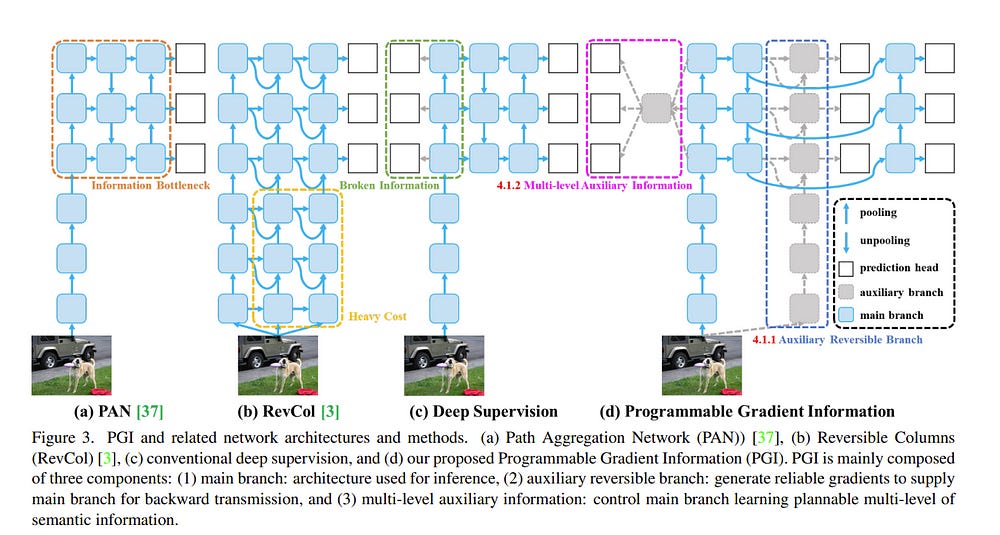
Today’s deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth.
Meanwhile, an appropriate architecture that can facilitate the acquisition of enough information for prediction has to be designed. Existing methods ignore the fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, a large amount of information will be lost.
This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives.
PGI can provide complete input information for the target task to calculate objective functions so that reliable gradient information can be obtained to update network weights. In addition, a new lightweight network architecture — Generalized Efficient Layer Aggregation Network (GELAN), based on gradient path planning is designed.
GELAN’s architecture confirms that PGI has gained superior results on lightweight models. We verified the proposed GELAN and PGI on MS COCO dataset-based object detection.
The results show that GELAN only uses conventional convolution operators to achieve better parameter utilization than the state-of-the-art methods developed based on depth-wise convolution. PGI can be used for a variety of models from lightweight to large.
It can be used to obtain complete information so that train-from-scratch models can achieve better results than state-of-the-art models pre-trained using large datasets.
5.3. FiT: Flexible Vision Transformer for Diffusion Model

Nature is infinitely resolution-free. In the context of this reality, existing diffusion models, such as Diffusion Transformers, often face challenges when processing image resolutions outside of their trained domain. To overcome this limitation, we present the Flexible Vision Transformer (FiT), a transformer architecture specifically designed for generating images with unrestricted resolutions and aspect ratios.
Unlike traditional methods that perceive images as static-resolution grids, FiT conceptualizes images as sequences of dynamically sized tokens. This perspective enables a flexible training strategy that effortlessly adapts to diverse aspect ratios during both training and inference phases, thus promoting resolution generalization and eliminating biases induced by image cropping.
Enhanced by a meticulously adjusted network structure and the integration of training-free extrapolation techniques, FiT exhibits remarkable flexibility in resolution extrapolation generation. Comprehensive experiments demonstrate the exceptional performance of FiT across a broad range of resolutions, showcasing its effectiveness both within and beyond its training resolution distribution.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
