


Top Important Computer Vision Papers for the Week from 03/06 to 09/06
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the First Week of June 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. Kaleido Diffusion: Improving Conditional Diffusion Models with Autoregressive Latent Modeling

Diffusion models have emerged as a powerful tool for generating high-quality images from textual descriptions. Despite their successes, these models often exhibit limited diversity in the sampled images, particularly when sampling with a high classifier-free guidance weight.
To address this issue, we present Kaleido, a novel approach that enhances the diversity of samples by incorporating autoregressive latent priors. Kaleido integrates an autoregressive language model that encodes the original caption and generates latent variables, serving as abstract and intermediary representations for guiding and facilitating the image generation process.
In this paper, we explore a variety of discrete latent representations, including textual descriptions, detection bounding boxes, object blobs, and visual tokens. These representations diversify and enrich the input conditions to the diffusion models, enabling more diverse outputs.
Our experimental results demonstrate that Kaleido effectively broadens the diversity of the generated image samples from a given textual description while maintaining high image quality.
Furthermore, we show that Kaleido adheres closely to the guidance provided by the generated latent variables, demonstrating its capability to effectively control and direct the image generation process.
1.2. 4Diffusion: Multi-view Video Diffusion Model for 4D Generation

Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers.
In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations.
After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF.
This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF.
Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
1.3. Guiding a Diffusion Model with a Bad Version of Itself

The primary axes of interest in image-generating diffusion models are image quality, the amount of variation in the results, and how well the results align with a given condition, e.g., a class label or a text prompt.
The popular classifier-free guidance approach uses an unconditional model to guide a conditional model, leading to simultaneously better prompt alignment and higher-quality images at the cost of reduced variation.
These effects seem inherently entangled, and thus hard to control. We make the surprising observation that it is possible to obtain disentangled control over image quality without compromising the amount of variation by guiding generation using a smaller, less-trained version of the model itself rather than an unconditional model.
This leads to significant improvements in ImageNet generation, setting record FIDs of 1.01 for 64x64 and 1.25 for 512x512, using publicly available networks. Furthermore, the method is also applicable to unconditional diffusion models, drastically improving their quality.
1.4. Learning Temporally Consistent Video Depth from Video Diffusion Priors
This work addresses the challenge of video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. Instead of directly developing a depth estimator from scratch, we reformulate the prediction task into a conditional generation problem.
This allows us to leverage the prior knowledge embedded in existing video generation models, thereby reducing learn- ing difficulty and enhancing generalizability. Concretely, we study how to tame the public Stable Video Diffusion (SVD) to predict reliable depth from input videos using a mixture of image depth and video depth datasets.
We empirically confirm that a procedural training strategy — first optimizing the spatial layers of SVD and then optimizing the temporal layers while keeping the spatial layers frozen — yields the best results in terms of both spatial accuracy and temporal consistency. We further examine the sliding window strategy for inference on arbitrarily long videos.
Our observations indicate a trade-off between efficiency and performance, with a one-frame overlap already producing favorable results. Extensive experimental results demonstrate the superiority of our approach, termed ChronoDepth, over existing alternatives, particularly in terms of the temporal consistency of the estimated depth.
Additionally, we highlight the benefits of more consistent video depth in two practical applications: depth-conditioned video generation and novel view synthesis.
1.5. pOps: Photo-Inspired Diffusion Operators

Text-guided image generation enables the creation of visual content from textual descriptions. However, certain visual concepts cannot be effectively conveyed through language alone.
This has sparked a renewed interest in utilizing the CLIP image embedding space for more visually oriented tasks through methods such as IP adapters. Interestingly, the CLIP image embedding space has been shown to be semantically meaningful, where linear operations within this space yield semantically meaningful results.
Yet, the specific meaning of these operations can vary unpredictably across different images. To harness this potential, we introduce pOps, a framework that trains specific semantic operators directly on CLIP image embeddings.
Each pOps operator is built upon a pretrained Diffusion prior model. While the Diffusion Prior model was originally trained to map between text embeddings and image embeddings, we demonstrate that it can be tuned to accommodate new input conditions, resulting in a diffusion operator.
Working directly over image embeddings not only improves our ability to learn semantic operations but also allows us to directly use a textual CLIP loss as additional supervision when needed.
We show that pOps can be used to learn a variety of photo-inspired operators with distinct semantic meanings, highlighting the semantic diversity and potential of our proposed approach.
1.6. ZeroSmooth: Training-free Diffuser Adaptation for High Frame Rate Video Generation

Video generation has made remarkable progress in recent years, especially since the advent of video diffusion models. Many video generation models can produce plausible synthetic videos, e.g., Stable Video Diffusion (SVD).
However, most video models can only generate low frame rate videos due to the limited GPU memory as well as the difficulty of modeling a large set of frames. The training videos are always uniformly sampled at a specified interval for temporal compression.
Previous methods promote the frame rate by either training a video interpolation model in pixel space as a postprocessing stage or training an interpolation model in latent space for a specific base video model. In this paper, we propose a training-free video interpolation method for generative video diffusion models, which is generalizable to different models in a plug-and-play manner.
We investigate the non-linearity in the feature space of video diffusion models and transform a video model into a self-cascaded video diffusion model by incorporating the designed hidden state correction modules.
The self-cascaded architecture and the correction module are proposed to retain the temporal consistency between keyframes and the interpolated frames.
Extensive evaluations are performed on multiple popular video models to demonstrate the effectiveness of the proposed method, especially since our training-free method is even comparable to trained interpolation models supported by huge compute resources and large-scale datasets.
1.7. BitsFusion: 1.99 bits Weight Quantization of Diffusion Model

Diffusion-based image generation models have achieved great success in recent years by showing the capability of synthesizing high-quality content. However, these models contain a huge number of parameters, resulting in a significantly large model size.
Saving and transferring them is a major bottleneck for various applications, especially those running on resource-constrained devices. In this work, we develop a novel weight quantization method that quantizes the UNet from Stable Diffusion v1.5 to 1.99 bits, achieving a model with a 7.9X smaller size while exhibiting even better generation quality than the original one.
Our approach includes several novel techniques, such as assigning optimal bits to each layer, initializing the quantized model for better performance, and improving the training strategy to reduce quantization error dramatically.
Furthermore, we extensively evaluate our quantized model across various benchmark datasets and through human evaluation to demonstrate its superior generation quality.
1.8. Step-aware Preference Optimization: Aligning Preference with Denoising Performance at Each Step

Recently, Direct Preference Optimization (DPO) has extended its success from aligning large language models (LLMs) to aligning text-to-image diffusion models with human preferences.
Unlike most existing DPO methods that assume all diffusion steps share a consistent preference order with the final generated images, we argue that this assumption neglects step-specific denoising performance and that preference labels should be tailored to each step’s contribution.
To address this limitation, we propose Step-aware Preference Optimization (SPO), a novel post-training approach that independently evaluates and adjusts the denoising performance at each step, using a step-aware preference model and a step-wise resampler to ensure accurate step-aware supervision.
Specifically, at each denoising step, we sample a pool of images, find a suitable win-lose pair, and, most importantly, randomly select a single image from the pool to initialize the next denoising step. This step-wise resampler process ensures the next win-lose image pair comes from the same image, making the win-lose comparison independent of the previous step.
To assess the preferences at each step, we train a separate step-aware preference model that can be applied to both noisy and clean images. Our experiments with Stable Diffusion v1.5 and SDXL demonstrate that SPO significantly outperforms the latest Diffusion-DPO in aligning generated images with complex, detailed prompts and enhancing aesthetics, while also achieving more than 20x times faster training efficiency.
2. Vision Language Models (VLMs)
2.1. Parrot: Multilingual Visual Instruction Tuning
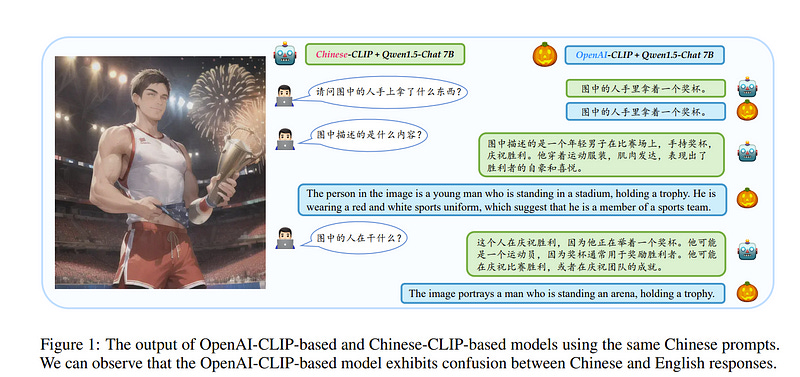
The rapid development of Multimodal Large Language Models (MLLMs) like GPT-4V has marked a significant step towards artificial general intelligence.
Existing methods mainly focus on aligning vision encoders with LLMs through supervised fine-tuning (SFT) to endow LLMs with multimodal abilities, making MLLMs’ inherent ability to react to multiple languages progressively deteriorate as the training process evolves.
We empirically find that the imbalanced SFT datasets, primarily composed of English-centric image-text pairs, lead to significantly reduced performance in non-English languages.
This is due to the failure to align the vision encoder and LLM with multilingual tokens during the SFT process. In this paper, we introduce Parrot, a novel method that utilizes textual guidance to drive visual token alignment at the language level. Parrot makes the visual tokens condition on diverse language inputs and uses a mixture of experts (MoE) to promote the alignment of multilingual tokens.
Specifically, to enhance non-English visual tokens alignment, we compute the cross-attention using the initial visual features and textual embeddings, the result of which is then fed into the MoE router to select the most relevant experts.
The selected experts subsequently convert the initial visual tokens into language-specific visual tokens. Moreover, considering the current lack of benchmarks for evaluating multilingual capabilities within the field, we collect and make available a Massive Multilingual Multimodal Benchmark which includes 6 languages, 15 categories, and 12,000 questions, named as MMMB.
Our method not only demonstrates state-of-the-art performance on multilingual MMBench and MMMB but also excels across a broad range of multimodal tasks. Both the source code and the training dataset of Parrot will be made publicly available.
3. Image Generation & Editing
3.1. Ouroboros3D: Image-to-3D Generation via 3D-aware Recursive Diffusion

Existing single image-to-3D creation methods typically involve a two-stage process, first generating multi-view images, and then using these images for 3D reconstruction.
However, training these two stages separately leads to significant data bias in the inference phase, thus affecting the quality of reconstructed results. We introduce a unified 3D generation framework, named Ouroboros3D, which integrates diffusion-based multi-view image generation and 3D reconstruction into a recursive diffusion process.
In our framework, these two modules are jointly trained through a self-conditioning mechanism, allowing them to adapt to each other’s characteristics for robust inference. During the multi-view denoising process, the multi-view diffusion model uses the 3D-aware maps rendered by the reconstruction module at the previous timestep as additional conditions.
The recursive diffusion framework with 3D-aware feedback unites the entire process and improves geometric consistency. Experiments show that our framework outperforms the separation of these two stages and existing methods that combine them at the inference phase.
4. Video Understanding & Generation
4.1. Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
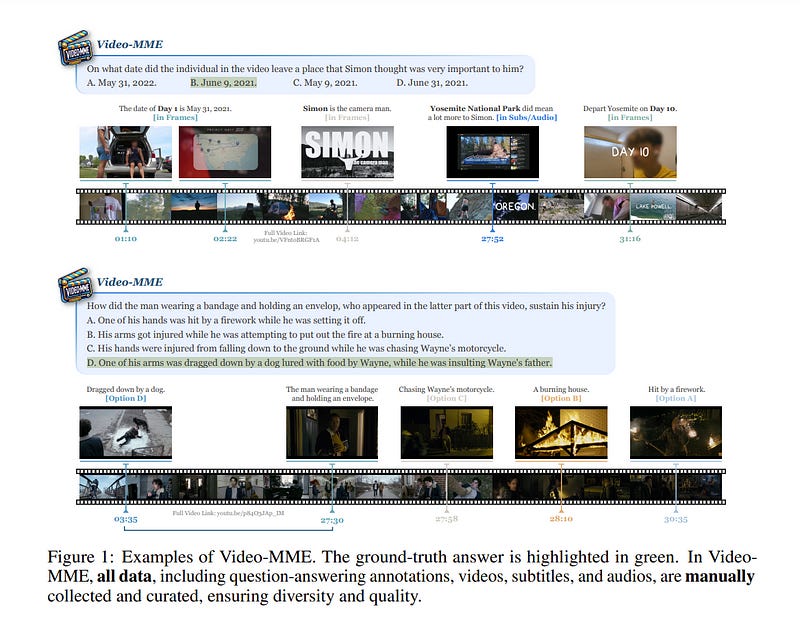
In the quest for artificial general intelligence, Multi-modal Large Language Models (MLLMs) have emerged as a focal point in recent advancements. However, the predominant focus remains on developing their capabilities in static image understanding.
The potential of MLLMs in processing sequential visual data is still insufficiently explored, highlighting the absence of a comprehensive, high-quality assessment of their performance. In this paper, we introduce Video-MME, the first-ever full-spectrum, Multi-Modal Evaluation benchmark of MLLMs in Video analysis.
Our work distinguishes from existing benchmarks through four key features:
Diversity in video types, spanning 6 primary visual domains with 30 subfields to ensure broad scenario generalizability.
Duration in temporal dimension, encompassing both short-, medium-, and long-term videos, ranging from 11 seconds to 1 hour, for robust contextual dynamics.
Breadth in data modalities, integrating multi-modal inputs besides video frames, including subtitles and audio, to unveil the all-around capabilities of MLLMs.
Quality in annotations, utilizing rigorous manual labeling by expert annotators to facilitate precise and reliable model assessment. 900 videos with a total of 256 hours are manually selected and annotated by repeatedly viewing all the video content, resulting in 2,700 question-answer pairs.
With Video-MME, we extensively evaluate various state-of-the-art MLLMs, including GPT-4 series and Gemini 1.5 Pro, as well as open-source image models like InternVL-Chat-V1.5 and video models like LLaVA-NeXT-Video.
Our experiments reveal that Gemini 1.5 Pro is the best-performing commercial model, significantly outperforming the open-source models. Our dataset along with these findings underscores the need for further improvements in handling longer sequences and multi-modal data.
4.2. Searching Priors Makes Text-to-Video Synthesis Better

Significant advancements in video diffusion models have brought substantial progress to the field of text-to-video (T2V) synthesis. However, the existing T2V synthesis model struggles to accurately generate complex motion dynamics, leading to a reduction in video realism.
One possible solution is to collect massive data and train the model on it, but this would be extremely expensive. To alleviate this problem, in this paper, we reformulate the typical T2V generation process as a search-based generation pipeline. Instead of scaling up the model training, we employ existing videos as the motion prior database.
Specifically, we divide the T2V generation process into two steps:
For a given prompt input, we search existing text-video datasets to find videos with text labels that closely match the prompt motions. We propose a tailored search algorithm that emphasizes object motion features.
Retrieved videos are processed and distilled into motion priors to fine-tune a pre-trained base T2V model, followed by generating desired videos using an input prompt.
By utilizing the priors gleaned from the searched videos, we enhance the realism of the generated videos’ motion. All operations can be finished on a single NVIDIA RTX 4090 GPU. We validate our method against state-of-the-art T2V models across diverse prompt inputs. The code will be public.
4.3. CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation

Recently video diffusion models have emerged as expressive generative tools for high-quality video content creation readily available to general users. However, these models often do not offer precise control over camera poses for video generation, limiting the expression of cinematic language and user control.
To address this issue, we introduce CamCo, which allows fine-grained Camera pose Control for image-to-video generation. We equip a pre-trained image-to-video generator with accurately parameterized camera pose input using Pl\ucker coordinates.
To enhance 3D consistency in the videos produced, we integrate an epipolar attention module in each attention block that enforces epipolar constraints to the feature maps. Additionally, we fine-tune CamCo on real-world videos with camera poses estimated through structure-from-motion algorithms to better synthesize object motion.
Our experiments show that CamCo significantly improves 3D consistency and camera control capabilities compared to previous models while effectively generating plausible object motion.
4.4. ShareGPT4Video: Improving Video Understanding and Generation with Better Captions

We present the ShareGPT4Video series, aiming to facilitate the video understanding of large video-language models (LVLMs) and the video generation of text-to-video models (T2VMs) via dense and precise captions.
The series comprises:
ShareGPT4Video, 40K GPT4V annotated dense captions of videos with various lengths and sources, developed through carefully designed data filtering and annotating strategy.
ShareCaptioner-Video, is an efficient and capable captioning model for arbitrary videos, with 4.8M high-quality aesthetic videos annotated by it.
ShareGPT4Video-8B, a simple yet superb LVLM that reached SOTA performance on three advancing video benchmarks.
To achieve this, taking aside the non-scalable costly human annotators, we find using GPT4V to caption video with a naive multi-frame or frame-concatenation input strategy leads to less detailed and sometimes temporal-confused results.
We argue the challenge of designing a high-quality video captioning strategy lies in three aspects:
Inter-frame precise temporal change understanding.
Intra-frame detailed content description.
Frame-number scalability for arbitrary-length videos.
To this end, we meticulously designed a differential video captioning strategy, which is stable, scalable, and efficient for generating captions for videos with arbitrary resolution, aspect ratios, and length.
Based on it, we construct ShareGPT4Video, which contains 40K high-quality videos spanning a wide range of categories, and the resulting captions encompass rich world knowledge, object attributes, camera movements, and crucially, detailed and precise temporal descriptions of events.
Based on ShareGPT4Video, we further develop ShareCaptioner-Video, a superior captioner capable of efficiently generating high-quality captions for arbitrary videos.
4.5. SF-V: Single Forward Video Generation Model

Diffusion-based video generation models have demonstrated remarkable success in obtaining high-fidelity videos through the iterative denoising process.
However, these models require multiple denoising steps during sampling, resulting in high computational costs. This work proposes a novel approach to obtain single-step video generation models by leveraging adversarial training to fine-tune pre-trained video diffusion models. We show that, through the adversarial training, the multi-step video diffusion model, i.e.,
Stable Video Diffusion (SVD), can be trained to perform a single forward pass to synthesize high-quality videos, capturing both temporal and spatial dependencies in the video data.
Extensive experiments demonstrate that our method achieves competitive generation quality of synthesized videos with significantly reduced computational overhead for the denoising process (i.e., around 23times speedup compared with SVD and 6times speedup compared with existing works, with even better generation quality), paving the way for real-time video synthesis and editing.
4.6. VideoTetris: Towards Compositional Text-to-Video Generation

Diffusion models have demonstrated great success in text-to-video (T2V) generation. However, existing methods may face challenges when handling complex (long) video generation scenarios that involve multiple objects or dynamic changes in object numbers.
To address these limitations, we propose VideoTetris, a novel framework that enables compositional T2V generation. Specifically, we propose spatio-temporal compositional diffusion to precisely follow complex textual semantics by manipulating and composing the attention maps of denoising networks spatially and temporally.
Moreover, we propose an enhanced video data preprocessing to enhance the training data regarding motion dynamics and prompt understanding, equipped with a new reference frame attention mechanism to improve the consistency of auto-regressive video generation.
Extensive experiments demonstrate that our VideoTetris achieves impressive qualitative and quantitative results in compositional T2V generation.
4.7. V-Express: Conditional Dropout for Progressive Training of Portrait Video Generation

In the field of portrait video generation, the use of single images to generate portrait videos has become increasingly prevalent. A common approach involves leveraging generative models to enhance adapters for controlled generation.
However, control signals (e.g., text, audio, reference image, pose, depth map, etc.) can vary in strength. Among these, weaker conditions often need help to be effective due to interference from stronger conditions, posing a challenge in balancing these conditions.
In our work on portrait video generation, we identified audio signals as particularly weak, often overshadowed by stronger signals such as facial pose and reference image.
However, direct training with weak signals often leads to difficulties in convergence. To address this, we propose V-Express, a simple method that balances different control signals through progressive training and the conditional dropout operation.
Our method gradually enables effective control by weak conditions, thereby achieving generation capabilities that simultaneously take into account the facial pose, reference image, and audio.
The experimental results demonstrate that our method can effectively generate portrait videos controlled by audio. Furthermore, a potential solution is provided for the simultaneous and effective use of conditions of varying strengths.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
