


Top Important Computer Vision Papers for the Week from 01/01 to 07/01
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the first week of January 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Stable Diffusion
Vision Language Models
Image Generation & Editing
Video Generation & Editing
Image Recognition
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Stable Diffusion
1.1. TrailBlazer: Trajectory Control for Diffusion-Based Video Generation

Within recent approaches to text-to-video (T2V) generation, achieving controllability in the synthesized video is often a challenge. Typically, this issue is addressed by providing low-level per-frame guidance in the form of edge maps, depth maps, or an existing video to be altered.
However, the process of obtaining such guidance can be labor-intensive. This paper focuses on enhancing controllability in video synthesis by employing straightforward bounding boxes to guide the subject in various ways, all without the need for neural network training, finetuning, optimization at inference time, or the use of pre-existing videos. Our algorithm, TrailBlazer, is constructed upon a pre-trained (T2V) model and is easy to implement.
The subject is directed by a bounding box through the proposed spatial and temporal attention map editing. Moreover, the authors introduce the concept of keyframing, allowing the subject trajectory and overall appearance to be guided by both a moving bounding box and corresponding prompts, without the need to provide a detailed mask.
The method is efficient, with negligible additional computation relative to the underlying pre-trained model. Despite the simplicity of the bounding box guidance, the resulting motion is surprisingly natural, with emergent effects including perspective and movement toward the virtual camera as the box size increases.
1.2. Improving Diffusion-Based Image Synthesis with Context Prediction

Diffusion models are a new class of generative models and have dramatically promoted image generation with unprecedented quality and diversity. Existing diffusion models mainly try to reconstruct an input image from a corrupted one with a pixel-wise or feature-wise constraint along spatial axes. However, such point-based reconstruction may fail to make each predicted pixel/feature fully preserve its neighborhood context, impairing diffusion-based image synthesis.
As a powerful source of automatic supervisory signals, the context has been well-studied for learning representations. Inspired by this, the authors for the first time propose ConPreDiff to improve diffusion-based image synthesis with context prediction. They explicitly reinforce each point to predict its neighborhood context (i.e., multi-stride features/tokens/pixels) with a context decoder at the end of diffusion denoising blocks in the training stage, and remove the decoder for inference.
In this way, each point can better reconstruct itself by preserving its semantic connections with the neighborhood context. This new paradigm of ConPreDiff can generalize to arbitrary discrete and continuous diffusion backbones without introducing extra parameters in the sampling procedure. Extensive experiments are conducted on unconditional image generation, text-to-image generation, and image inpainting tasks. Our ConPreDiff consistently outperforms previous methods and achieves new SOTA text-to-image generation results on MS-COCO, with a zero-shot FID score of 6.21.
2. Vision Language Models
2.1. GPT-4V(ision) is a Generalist Web Agent if Grounded
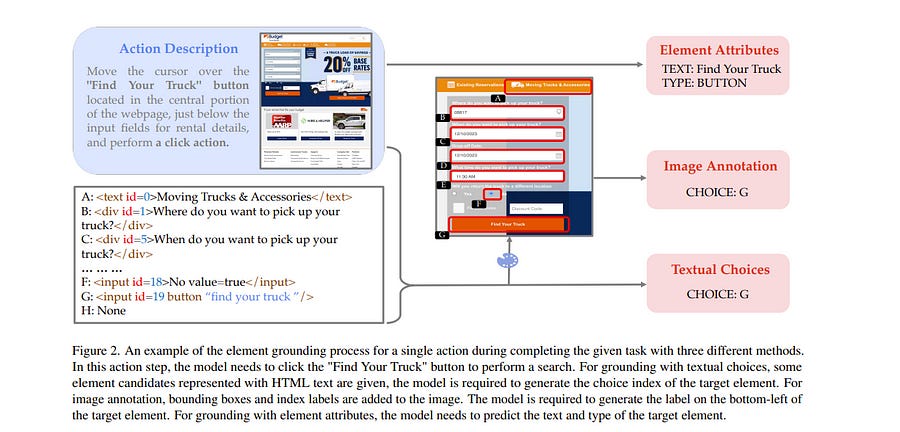
The recent development of large multimodal models (LMMs), especially GPT-4V(ision) and Gemini, has been quickly expanding the capability boundaries of multimodal models beyond traditional tasks like image captioning and visual question answering.
In this work, the authors explore the potential of LMMs like GPT-4V as a generalist web agent that can follow natural language instructions to complete tasks on any given website. They propose SEEACT, a generalist web agent that harnesses the power of LMMs for integrated visual understanding and acting on the web.
They evaluate the recent MIND2WEB benchmark. In addition to standard offline evaluation on cached websites, they enable a new online evaluation setting by developing a tool that allows running web agents on live websites. They show that GPT-4V presents great potential for web agents — it can complete 50% of the tasks on live websites if we manually ground its textual plans into actions on the websites.
This substantially outperforms text-only LLMs like GPT-4 or smaller models (FLAN-T5 and BLIP-2) specifically fine-tuned for web agents. However, grounding remains a major challenge. Existing LMM grounding strategies like set-of-mark prompting turn out not ineffective for web agents, and the best grounding strategy we develop in this paper leverages both the HTML text and visuals. Yet, there is still a substantial gap with oracle grounding, leaving ample room for further improvement.
2.2. A Vision Check-up for Language Models

What does learning to model relationships between strings teach large language models (LLMs) about the visual world? The authors systematically evaluate LLMs’ abilities to generate and recognize an assortment of visual concepts of increasing complexity and then demonstrate how a preliminary visual representation learning system can be trained using models of text.
As language models cannot consume or output visual information as pixels, they use code to represent images in this study. Although LLM-generated images do not look like natural images, results on image generation and the ability of models to correct these generated images indicate that precise modeling of strings can teach language models about numerous aspects of the visual world.
Furthermore, experiments on self-supervised visual representation learning, utilizing images generated with text models, highlight the potential to train vision models capable of making semantic assessments of natural images using just LLMs.
3. Image Generation & Editing
3.1. SteinDreamer: Variance Reduction for Text-to-3D Score Distillation via Stein Identity

Score distillation has emerged as one of the most prevalent approaches for text-to-3D asset synthesis. Essentially, score distillation updates 3D parameters by lifting and back-propagating scores averaged over different views. In this paper, we reveal that the gradient estimation in score distillation is inherent to high variance.
Through the lens of variance reduction, the effectiveness of SDS and VSD can be interpreted as applications of various control variates to the Monte Carlo estimator of the distilled score. Motivated by this rethinking and based on Stein’s identity, we propose a more general solution to reduce variance for score distillation, termed Stein Score Distillation (SSD). SSD incorporates control variates constructed by Stein identity, allowing for arbitrary baseline functions.
This enables us to include flexible guidance priors and network architectures to explicitly optimize for variance reduction. In these experiments, the overall pipeline, dubbed SteinDreamer, is implemented by instantiating the control variate with a monocular depth estimator. The results suggest that SSD can effectively reduce the distillation variance and consistently improve visual quality for both object- and scene-level generation. Moreover, they demonstrate that SteinDreamer achieves faster convergence than existing methods due to more stable gradient updates.
3.2. Taming Mode Collapse in Score Distillation for Text-to-3D Generation

Despite the remarkable performance of score distillation in text-to-3D generation, such techniques notoriously suffer from view inconsistency issues, also known as the “Janus” artifact, where the generated objects fake each view with multiple front faces.
Although empirically effective methods have approached this problem via score debiasing or prompt engineering, a more rigorous perspective to explain and tackle this problem remains elusive. In this paper, the authors reveal that the existing score distillation-based text-to-3D generation frameworks degenerate to maximal likelihood seeking on each view independently and thus suffer from the mode collapse problem, manifesting as the Janus artifact in practice.
To tame mode collapse, the authors improve score distillation by re-establishing in entropy term in the corresponding variational objective, which is applied to the distribution of rendered images. Maximizing the entropy encourages diversity among different views in generated 3D assets, thereby mitigating the Janus problem. Based on this new objective, we derive a new update rule for 3D score distillation, dubbed Entropic Score Distillation (ESD).
They theoretically reveal that ESD can be simplified and implemented by just adopting the classifier-free guidance trick upon variational score distillation. Although embarrassingly straightforward, these extensive experiments successfully demonstrate that ESD can be an effective treatment for Janus artifacts in score distillation.
3.3. En3D: An Enhanced Generative Model for Sculpting 3D Humans from 2D Synthetic Data

This paper presents an En3D, an enhanced generative scheme for sculpting high-quality 3D human avatars. Unlike previous works that rely on scarce 3D datasets or limited 2D collections with imbalanced viewing angles and imprecise pose priors, this approach aims to develop a zero-shot 3D generative scheme capable of producing visually realistic, geometrically accurate and content-wise diverse 3D humans without relying on pre-existing 3D or 2D assets.
To address this challenge, the authors introduce a meticulously crafted workflow that implements accurate physical modeling to learn the enhanced 3D generative model from synthetic 2D data. During inference, they integrate optimization modules to bridge the gap between realistic appearances and coarse 3D shapes.
Specifically, En3D comprises three modules: a 3D generator that accurately models generalizable 3D humans with realistic appearance from synthesized balanced, diverse, and structured human images; a geometry sculptor that enhances shape quality using multi-view normal constraints for intricate human anatomy; and a texturing module that disentangles explicit texture maps with fidelity and editability, leveraging semantical UV partitioning and a differentiable rasterizer.
Experimental results show that our approach significantly outperforms prior works in terms of image quality, geometry accuracy, and content diversity. We also showcase the applicability of our generated avatars for animation and editing, as well as the scalability of our approach for content-style free adaptation.
3.4. Image Sculpting: Precise Object Editing with 3D Geometry Control

This paper presents Image Sculpting, a new framework for editing 2D images by incorporating tools from 3D geometry and graphics. This approach differs markedly from existing methods, which are confined to 2D spaces and typically rely on textual instructions, leading to ambiguity and limited control. Image Sculpting converts 2D objects into 3D, enabling direct interaction with their 3D geometry.
Post-editing, these objects are re-rendered into 2D, merging into the original image to produce high-fidelity results through a coarse-to-fine enhancement process. The framework supports precise, quantifiable, and physically plausible editing options such as pose editing, rotation, translation, 3D composition, carving, and serial addition. It marks an initial step towards combining the creative freedom of generative models with the precision of graphics pipelines.
3.5. Instruct-Imagen: Image Generation with Multi-modal Instruction
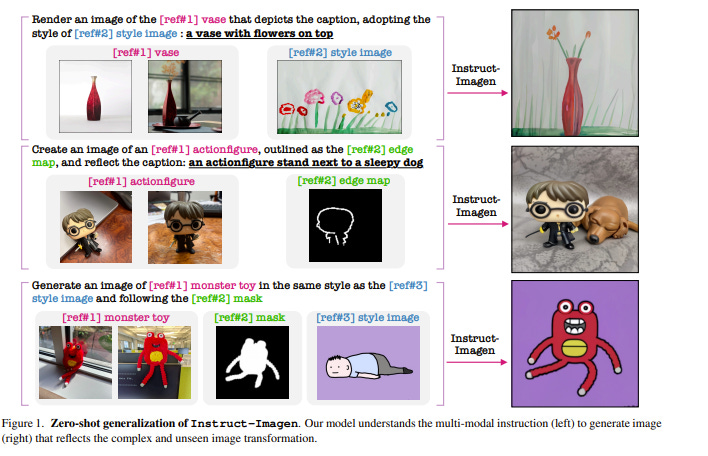
This paper presents instruct-imagen, a model that tackles heterogeneous image generation tasks and generalizes across unseen tasks. They introduce multi-modal instruction for image generation, a task representation articulating a range of generation intents with precision. It uses natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.), such that abundant generation intents can be standardized in a uniform format.
They then build instruct-imagen by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework. First, they adapt the model using the retrieval-augmented training, to enhance the model’s capabilities to ground its generation on an external multimodal context. Subsequently, they fine-tune the adapted model on diverse image generation tasks that require vision-language understanding (e.g., subject-driven generation, etc.), each paired with a multi-modal instruction encapsulating the task’s essence.
Human evaluation of various image generation datasets reveals that instruct-imagen matches or surpasses prior task-specific models in-domain and demonstrates promising generalization to unseen and more complex tasks.
3.6. FMGS: Foundation Model Embedded 3D Gaussian Splatting for Holistic 3D Scene Understanding

Precisely perceiving the geometric and semantic properties of real-world 3D objects is crucial for the continued evolution of augmented reality and robotic applications. To this end, the authors present this paper, which incorporates vision-language embeddings of foundation models into 3D Gaussian Splatting (GS).
The key contribution of this work is an efficient method to reconstruct and represent 3D vision-language models. This is achieved by distilling feature maps generated from image-based foundation models into those rendered from the 3D model. To ensure high-quality rendering and fast training, they introduce a novel scene representation by integrating strengths from both GS and multi-resolution hash encodings (MHE).
This effective training procedure also introduces a pixel alignment loss that makes the rendered feature distance of the same semantic entities close, following the pixel-level semantic boundaries. These results demonstrate remarkable multi-view semantic consistency, facilitating diverse downstream tasks, beating state-of-the-art methods by 10.2 percent on open-vocabulary language-based object detection, despite that we are 851 times faster for inference.
This research explores the intersection of vision, language, and 3D scene representation, paving the way for enhanced scene understanding in uncontrolled real-world environments. The authors plan to release the code upon paper acceptance.
3.7. Q-Refine: A Perceptual Quality Refiner for AI-Generated Image

With the rapid evolution of the Text-to-Image (T2I) model in recent years, their unsatisfactory generation result has become a challenge. However, uniformly refining AI-generated images (AIGIs) of different qualities not only limited optimization capabilities for low-quality AIGIs but also brought negative optimization to high-quality AIGIs. To address this issue, a quality-award refiner named Q-Refine is proposed.
Based on the preference of the Human Visual System (HVS), Q-Refine uses the Image Quality Assessment (IQA) metric to guide the refining process for the first time and modify images of different qualities through three adaptive pipelines.
Experimental shows that for mainstream T2I models, Q-Refine can perform effective optimization to AIGIs of different qualities. It can be a general refiner to optimize AIGIs from both fidelity and aesthetic quality levels, thus expanding the application of the T2I generation models.
3.8. What You See is What You GAN: Rendering Every Pixel for High-Fidelity Geometry in 3D GANs

3D-aware Generative Adversarial Networks (GANs) have shown remarkable progress in learning to generate multi-view-consistent images and 3D geometries of scenes from collections of 2D images via neural volume rendering. Yet, the significant memory and computational costs of dense sampling in volume rendering have forced 3D GANs to adopt patch-based training or employ low-resolution rendering with post-processing 2D super-resolution, which sacrifices multiview consistency and the quality of resolved geometry.
Consequently, 3D GANs have not yet been able to fully resolve the rich 3D geometry present in 2D images. In this work, the authors propose techniques to scale neural volume rendering to the much higher resolution of native 2D images, thereby resolving fine-grained 3D geometry with unprecedented detail. This approach employs learning-based samplers for accelerating neural rendering for 3D GAN training using up to 5 times fewer depth samples.
This enables them to explicitly “render every pixel” of the full-resolution image during training and inference without post-processing superresolution in 2D. Together with this strategy to learn high-quality surface geometry, this method synthesizes high-resolution 3D geometry and strictly view-consistent images while maintaining image quality on par with baselines relying on post-processing super-resolution. The authors demonstrate state-of-the-art 3D geometric quality on FFHQ and AFHQ, setting a new standard for unsupervised learning of 3D shapes in 3D GANs.
4. Video Generation & Editing
4.1. FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis

Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video.
Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables the model for video synthesis by editing the first frame with any prevalent I2I models and then propagating edits to successive frames.
The V2V model, FlowVid, demonstrates remarkable properties:
Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits.
Efficiency: Generation of a 4-second video with 30 FPS and 512x512 resolution takes only 1.5 minutes, which is 3.1x, 7.2x, and 10.5x faster than CoDeF, Rerender, and TokenFlow, respectively.
High-quality: In user studies, our FlowVid is preferred 45.7% of the time, outperforming CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
4.2. VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM

The recent innovations and breakthroughs in diffusion models have significantly expanded the possibilities of generating high-quality videos for the given prompts. Most existing works tackle the single-scene scenario with only one video event occurring in a single background. Extending to generate multi-scene videos nevertheless is not trivial and necessitates nicely managing the logic in between while preserving the consistent visual appearance of key content across video scenes.
In this paper, we propose a novel framework, namely VideoDrafter, for content-consistent multi-scene video generation. Technically, VideoDrafter leverages Large Language Models (LLM) to convert the input prompt into a comprehensive multi-scene script that benefits from the logical knowledge learned by LLM. The script for each scene includes a prompt describing the event, the foreground/background entities, as well as camera movement. VideoDrafter identifies the common entities throughout the script and asks LLM to detail each entity.
The resultant entity description is then fed into a text-to-image model to generate a reference image for each entity. Finally, VideoDrafter outputs a multi-scene video by generating each scene video via a diffusion process that takes the reference images, the descriptive prompt of the event, and camera movement into account.
The diffusion model incorporates the reference images as the condition and alignment to strengthen the content consistency of multi-scene videos. Extensive experiments demonstrate that VideoDrafter outperforms the SOTA video generation models regarding visual quality, content consistency, and user preference.
4.3. Moonshot: Towards Controllable Video Generation and Editing with Multimodal Conditions

Most existing video diffusion models (VDMs) are limited to text conditions. Thereby, they usually lack control over the visual appearance and geometry structure of the generated videos. This work presents Moonshot, a new video generation model that conditions simultaneously on multimodal image and text inputs.
The model builds upon a core module called multimodal video block (MVB), which consists of conventional spatiotemporal layers for representing video features, and a decoupled cross-attention layer to address image and text inputs for appearance conditioning. In addition, we carefully design the model architecture such that it can optionally integrate with pre-trained image ControlNet modules for geometry visual conditions, without needing extra training overhead as opposed to prior methods.
Experiments show that with versatile multimodal conditioning mechanisms, Moonshot demonstrates significant improvement in visual quality and temporal consistency compared to existing models. In addition, the model can be easily repurposed for a variety of generative applications, such as personalized video generation, image animation, and video editing, unveiling its potential to serve as a fundamental architecture for controllable video generation.
5. Image Recognition
5.1. Learning Vision from Models Rivals Learning Vision from Data

We introduce SynCLR, a novel approach for learning visual representations exclusively from synthetic images and synthetic captions, without any real data. We synthesize a large dataset of image captions using LLMs, then use an off-the-shelf text-to-image model to generate multiple images corresponding to each synthetic caption.
We perform visual representation learning on these synthetic images via contrastive learning, treating images sharing the same caption as positive pairs. The resulting representations transfer well to many downstream tasks, competing favorably with other general-purpose visual representation learners such as CLIP and DINO v2 in image classification tasks.
Furthermore, in dense prediction tasks such as semantic segmentation, SynCLR outperforms previous self-supervised methods by a significant margin, e.g., improving over MAE and iBOT by 6.2 and 4.3 mIoU on ADE20k for ViT-B/16.
5.2. ODIN: A Single Model for 2D and 3D Perception

State-of-the-art models on contemporary 3D perception benchmarks like ScanNet consume and label dataset-provided 3D point clouds, obtained through post-processing of sensed multiview RGB-D images. They are typically trained in-domain, forego large-scale 2D pre-training, and outperform alternatives that feature the posed RGB-D multiview images instead.
The gap in performance between methods that consume posed images versus post-processed 3D point clouds has fueled the belief that 2D and 3D perception require distinct model architectures. In this paper, we challenge this view and propose ODIN (Omni-Dimensional INstance segmentation), a model that can segment and label both 2D RGB images and 3D point clouds, using a transformer architecture that alternates between 2D within-view and 3D cross-view information fusion.
Our model differentiates 2D and 3D feature operations through the positional encodings of the tokens involved, which capture pixel coordinates for 2D patch tokens and 3D coordinates for 3D feature tokens. ODIN achieves state-of-the-art performance on ScanNet200, Matterport3D, and AI2THOR 3D instance segmentation benchmarks, and competitive performance on ScanNet, S3DIS, and COCO.
It outperforms all previous works by a wide margin when the sensed 3D point cloud is used in place of the point cloud sampled from the 3D mesh. When used as the 3D perception engine in an instructable embodied agent architecture, it sets a new state-of-the-art on the TEACh action-from-dialogue benchmark.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
