


Top Important Computer Vision Papers for the Week from 08/07 to 14/07
Stay Updated with Recent Computer Vision Research

Every week, researchers from top research labs, companies, and universities publish exciting breakthroughs in various topics such as diffusion models, vision language models, image editing and generation, video processing and generation, and image recognition.
This article provides a comprehensive overview of the most significant papers published in the Second Week of July 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Video Understanding & Generation
Text to Image Generation
My New E-Book: LLM Roadmap from Beginner to Advanced Level

I am pleased to announce that I have published my new ebook LLM Roadmap from Beginner to Advanced Level. This ebook will provide all the resources you need to start your journey towards mastering LLMs. The content of the book covers the following topics:
1. Diffusion Models
1.1. Video Diffusion Alignment via Reward Gradients

We have made significant progress towards building foundational video diffusion models. As these models are trained using large-scale unsupervised data, it has become crucial to adapt these models to specific downstream tasks.
Adapting these models via supervised fine-tuning requires collecting target datasets of videos, which is challenging and tedious. In this work, we utilize pre-trained reward models that are learned via preferences on top of powerful vision discriminative models to adapt video diffusion models.
These models contain dense gradient information with respect to generated RGB pixels, which is critical to efficient learning in complex search spaces, such as videos.
We show that backpropagating gradients from these reward models to a video diffusion model can allow for compute and sample efficient alignment of the video diffusion model.
We show results across a variety of reward models and video diffusion models, demonstrating that our approach can learn much more efficiently in terms of reward queries and computation than prior gradient-free approaches.
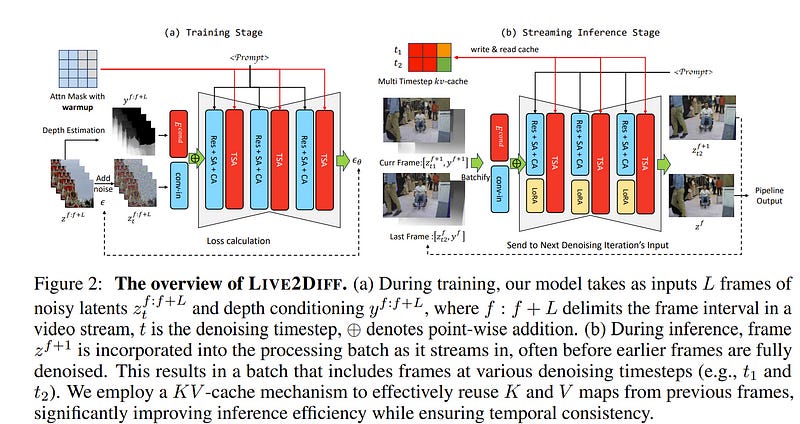
1.2. Live2Diff: Live Stream Translation via Uni-directional Attention in Video Diffusion Models
Large Language Models have shown remarkable efficacy in generating streaming data such as text and audio, thanks to their temporally uni-directional attention mechanism, which models correlations between the current token and previous tokens.
However, video streaming remains much less explored, despite a growing need for live video processing. State-of-the-art video diffusion models leverage bi-directional temporal attention to model the correlations between the current frame and all the surrounding (i.e. including future) frames, which hinders them from processing streaming videos.
To address this problem, we present Live2Diff, the first attempt at designing a video diffusion model with uni-directional temporal attention, specifically targeting live-streaming video translation. Compared to previous works, our approach ensures temporal consistency and smoothness by correlating the current frame with its predecessors and a few initial warmup frames, without any future frames.
Additionally, we use a highly efficient denoising scheme featuring a KV-cache mechanism and pipelining, to facilitate streaming video translation at interactive framerates. Extensive experiments demonstrate the effectiveness of the proposed attention mechanism and pipeline, outperforming previous methods in terms of temporal smoothness and/or efficiency.
2. Vision Language Models (VLMs)
2.1. Unveiling Encoder-Free Vision-Language Models

Existing vision-language models (VLMs) mostly rely on vision encoders to extract visual features followed by large language models (LLMs) for visual-language tasks.
However, the vision encoders set a strong inductive bias in abstracting visual representation, e.g., resolution, aspect ratio, and semantic priors, which could impede the flexibility and efficiency of the VLMs.
Training pure VLMs that accept the seamless vision and language inputs, i.e., without vision encoders, remains challenging and rarely explored. Empirical observations reveal that direct training without encoders results in slow convergence and large performance gaps.
In this work, we bridge the gap between encoder-based and encoder-free models and present a simple yet effective training recipe for pure VLMs. Specifically, we unveil the key aspects of training encoder-free VLMs efficiently via thorough experiments:
Bridging vision-language representation inside one unified decoder.
Enhancing visual recognition capability via extra supervision. With these strategies, we launch EVE, an encoder-free vision-language model that can be trained and forwarded efficiently.
Notably, solely utilizing 35M publicly accessible data, EVE can impressively rival the encoder-based VLMs of similar capacities across multiple vision-language benchmarks.
It significantly outperforms the counterpart Fuyu-8B with mysterious training procedures and undisclosed training data. We believe that EVE provides a transparent and efficient route for developing a pure decoder-only architecture across modalities.
2.2. Multi-Object Hallucination in Vision-Language Models

Large vision language models (LVLMs) often suffer from object hallucination, producing objects not present in the given images. While current benchmarks for object hallucination primarily concentrate on the presence of a single object class rather than individual entities, this work systematically investigates multi-object hallucination, examining how models misperceive (e.g., invent nonexistent objects or become distracted) when tasked with focusing on multiple objects simultaneously.
We introduce Recognition-based Object Probing Evaluation (ROPE), an automated evaluation protocol that considers the distribution of object classes within a single image during testing and uses visual referring prompts to eliminate ambiguity.
With comprehensive empirical studies and analysis of potential factors leading to multi-object hallucination, we found that :
LVLMs suffer more hallucinations when focusing on multiple objects compared to a single object.
The tested object class distribution affects hallucination behaviors, indicating that LVLMs may follow shortcuts and spurious correlations.
Hallucinatory behaviors are influenced by data-specific factors, salience and frequency, and model intrinsic behaviors.
We hope to enable LVLMs to recognize and reason about multiple objects that often occur in realistic visual scenes, provide insights and quantify our progress toward mitigating the issues.
2.3. Vision language models are blind

Large language models with vision capabilities (VLMs), e.g., GPT-4o and Gemini 1.5 Pro are powering countless image-text applications and scoring high on many vision-understanding benchmarks.
Yet, we find that VLMs fail on 7 visual tasks absurdly easy for humans such as identifying
Whether two circles overlap
Whether two lines intersect
Which letter is being circled in a word
Counting the number of circles in an Olympic-like logo.
The shockingly poor performance of four state-of-the-art VLMs suggests their vision is, at best, like of a person with myopia seeing fine details as blurry and at worst, like an intelligent person who is blind making educated guesses.
2.4. Do Vision and Language Models Share Concepts? A Vector Space Alignment Study

Large-scale pretrained language models (LMs) are said to ``lack the ability to connect utterances to the world’’ (Bender and Koller, 2020), because they do not have ``mental models of the world’ ‘(Mitchell and Krakauer, 2023).
If so, one would expect LM representations to be unrelated to representations induced by vision models. We present an empirical evaluation across four families of LMs (BERT, GPT-2, OPT, and LLaMA-2) and three vision model architectures (ResNet, SegFormer, and MAE).
Our experiments show that LMs partially converge towards representations isomorphic to those of vision models, subject to dispersion, polysemy, and frequency. This has important implications for both multi-modal processing and the LM understanding debate (Mitchell and Krakauer, 2023).
3. Video Understanding & Generation
3.1. Flash-VStream: Memory-Based Real-Time Understanding for Long Video Streams

320Benefiting from the advancements in large language models and cross-modal alignment, existing multi-modal video understanding methods have achieved prominent performance in offline scenarios.
However, online video streams, as one of the most common media forms in the real world, have seldom received attention. Compared to offline videos, the ‘dynamic’ nature of online video streams poses challenges for the direct application of existing models and introduces new problems, such as the storage of extremely long-term information, and interaction between continuous visual content and ‘asynchronous’ user questions.
Therefore, in this paper, we present Flash-VStream, a video-language model that simulates the memory mechanism of humans. Our model is able to process extremely long video streams in real time and respond to user queries simultaneously. Compared to existing models, Flash-VStream achieves significant reductions in inference latency and VRAM consumption, which is intimately related to performing an understanding of online streaming video.
In addition, given that existing video understanding benchmarks predominantly concentrate on offline scenarios, we propose VStream-QA, a novel question-answering benchmark specifically designed for online video streaming understanding.
Comparisons with popular existing methods on the proposed benchmark demonstrate the superiority of our method for such a challenging setting. To verify the generalizability of our approach, we further evaluate it on existing video understanding benchmarks and achieve state-of-the-art performance in offline scenarios as well.
3.2. Learning Action and Reasoning-Centric Image Editing from Videos and Simulations

An image editing model should be able to perform diverse edits, ranging from object replacement, and changing attributes or style, to performing actions or movement, which require many forms of reasoning. Current general instruction-guided editing models have significant shortcomings with action and reasoning-centric edits.
Object, attribute, or stylistic changes can be learned from visually static datasets. On the other hand, high-quality data for action and reasoning-centric edits is scarce and has to come from entirely different sources that cover e.g. physical dynamics, temporality, and spatial reasoning.
To this end, we meticulously curate the AURORA Dataset (Action-Reasoning-Object-Attribute), a collection of high-quality training data, human-annotated and curated from videos and simulation engines.
We focus on a key aspect of quality training data: triplets (source image, prompt, target image) contain a single meaningful visual change described by the prompt, i.e., truly minimal changes between source and target images.
To demonstrate the value of our dataset, we evaluate an AURORA-finetuned model on a new expert-curated benchmark (AURORA-Bench) covering 8 diverse editing tasks. Our model significantly outperforms previous editing models as judged by human raters.
For automatic evaluations, we find important flaws in previous metrics and caution against their use for semantically hard editing tasks. Instead, we propose a new automatic metric that focuses on discriminative understanding.
3.3. Video-STaR: Self-Training Enables Video Instruction Tuning with Any Supervision
The performance of Large Vision Language Models (LVLMs) is dependent on the size and quality of their training datasets. Existing video instruction tuning datasets lack diversity as they are derived by prompting large language models with video captions to generate question-answer pairs, and are therefore mostly descriptive.
Meanwhile, many labeled video datasets with diverse labels and supervision exist — however, we find that their integration into LVLMs is non-trivial. Herein, we present Video Self-Training with augmented Reasoning (Video-STaR), the first video self-training approach.
Video-STaR allows the utilization of any labeled video dataset for video instruction tuning. In Video-STaR, an LVLM cycles between instruction generation and finetuning, which we show
Improves general video understanding and
Adapts LVLMs to novel downstream tasks with existing supervision.
During generation, an LVLM is prompted to propose an answer. The answers are then filtered only to those that contain the original video labels, and the LVLM is then re-trained on the generated dataset.
By only training on generated answers that contain the correct video labels, Video-STaR utilizes these existing video labels as weak supervision for video instruction tuning.
Our results demonstrate that Video-STaR-enhanced LVLMs exhibit improved performance in (I) general video QA, where TempCompass performance improved by 10%, and (II) on downstream tasks, where Video-STaR improved Kinetics700-QA accuracy by 20% and action quality assessment on FineDiving by 15%.
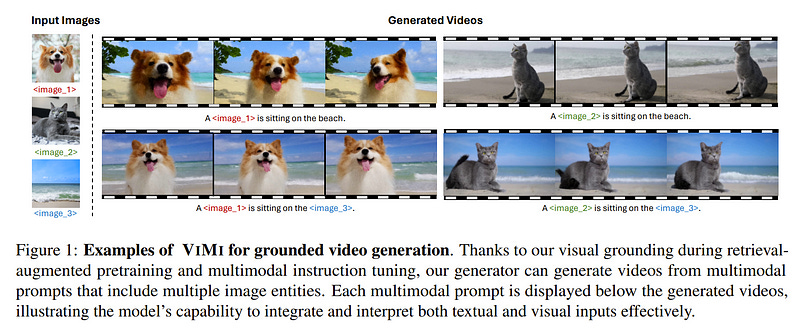
3.4. VIMI: Grounding Video Generation through Multi-modal Instruction
Existing text-to-video diffusion models rely solely on text-only encoders for their pretraining. This limitation stems from the absence of large-scale multimodal prompt video datasets, resulting in a lack of visual grounding and restricting their versatility and application in multimodal integration.
To address this, we construct a large-scale multimodal prompt dataset by employing retrieval methods to pair in-context examples with the given text prompts and then utilize a two-stage training strategy to enable diverse video generation tasks within the same model.
In the first stage, we propose a multimodal conditional video generation framework for pretraining on these augmented datasets, establishing a foundational model for grounded video generation.
Secondly, we finetune the model from the first stage on three video generation tasks, incorporating multi-modal instructions. This process further refines the model’s ability to handle diverse inputs and tasks, ensuring seamless integration of multi-modal information.
After this two-stage training process, VIMI demonstrates multimodal understanding capabilities, producing contextually rich and personalized videos grounded in the provided inputs, as shown in Figure 1.
Compared to previous visual-grounded video generation methods, VIMI can synthesize consistent and temporally coherent videos with large motion while retaining semantic control. Lastly, VIMI also achieves state-of-the-art text-to-video generation results on the UCF101 benchmark.
3.5. Generalizable Implicit Motion Modeling for Video Frame Interpolation

Motion modeling is critical in flow-based Video Frame Interpolation (VFI). Existing paradigms either consider linear combinations of bidirectional flows or directly predict bilateral flows for given timestamps without exploring favorable motion priors, thus lacking the capability of effectively modeling spatiotemporal dynamics in real-world videos.
To address this limitation, in this study, we introduce Generalizable Implicit Motion Modeling (GIMM), a novel and effective approach to motion modeling for VFI. Specifically, to enable GIMM as an effective motion modeling paradigm, we design a motion encoding pipeline to model spatiotemporal motion latent from bidirectional flows extracted from pre-trained flow estimators, effectively representing input-specific motion priors.
Then, we implicitly predict arbitrary-timestep optical flows within two adjacent input frames via an adaptive coordinate-based neural network, with spatiotemporal coordinates and motion latent as inputs. Our GIMM can be smoothly integrated with existing flow-based VFI works without further modifications. We show that GIMM performs better than the current state of the art on the VFI benchmarks.
4. Text to Image Generation
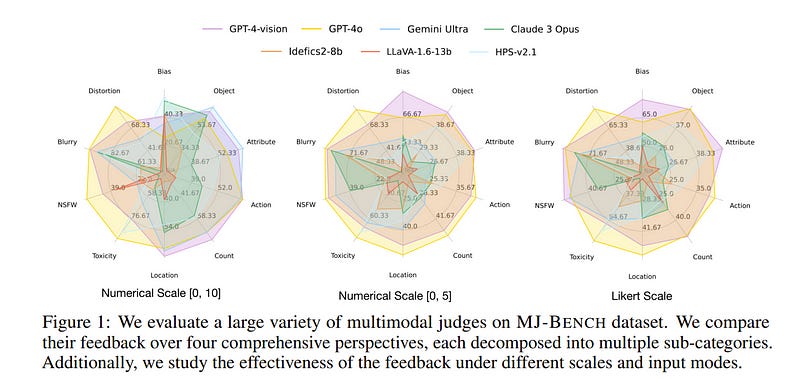
4.1. MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output.
To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes.
To address this issue, we introduce MJ-Bench, a novel benchmark that incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias.
Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset.
Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges on average. Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities.
Further studies in feedback scales reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales. Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-Bench.
4.2. Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model

Although most current large multimodal models (LMMs) can already understand photos of natural scenes and portraits, their understanding of abstract images, e.g., charts, maps, or layouts, and visual reasoning capabilities remains quite rudimentary.
They often struggle with simple daily tasks, such as reading time from a clock, understanding a flowchart, or planning a route using a road map. In light of this, we design a multi-modal self-instruct, utilizing large language models and their code capabilities to synthesize massive abstract images and visual reasoning instructions across daily scenarios.
Our strategy effortlessly creates a multimodal benchmark with 11,193 instructions for eight visual scenarios: charts, tables, simulated maps, dashboards, flowcharts, relation graphs, floor plans, and visual puzzles. This benchmark, constructed with simple lines and geometric elements, exposes the shortcomings of most advanced LMMs like Claude-3.5-Sonnet and GPT-4o in abstract image understanding, spatial relations reasoning, and visual element induction.
Besides, to verify the quality of our synthetic data, we fine-tune an LMM using 62,476 synthetic charts, tables, and road map instructions. The results demonstrate improved chart understanding and map navigation performance and also demonstrate potential benefits for other visual reasoning tasks.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
