


Top Important Computer Vision Papers for the Week from 08/04 to 14/04
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Second Week of April 2024, highlighting the latest research and advancements in computer vision.
Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models (VLMs)
Image Generation & Editing
Video Understanding & Generation
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1.1. Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models

Guidance is a crucial technique for extracting the best performance out of image-generating diffusion models. Traditionally, a constant guidance weight has been applied throughout the sampling chain of an image.
We show that guidance is harmful toward the beginning of the chain (high noise levels), largely unnecessary toward the end (low noise levels), and only beneficial in the middle. We thus restrict it to a specific range of noise levels, improving both the inference speed and result quality.
This limited guidance interval improves the record FID in ImageNet-512 significantly, from 1.81 to 1.40. We show that it is quantitatively and qualitatively beneficial across different sampler parameters, network architectures, and datasets, including the large-scale setting of Stable Diffusion XL. We thus suggest exposing the guidance interval as a hyperparameter in all diffusion models that use guidance.
1.2. RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion

We introduce RealmDreamer, a technique for the generation of general forward-facing 3D scenes from text descriptions. Our technique optimizes a 3D Gaussian Splatting representation to match complex text prompts.
We initialize these splats by utilizing the state-of-the-art text-to-image generators, lifting their samples into 3D, and computing the occlusion volume.
We optimize this representation across multiple views as a 3D inpainting task with image-conditional diffusion models. To learn the correct geometric structure, we incorporate a depth diffusion model by conditioning the samples from the inpainting model, giving a rich geometric structure.
Finally, we finetuned the model using sharpened samples from image generators. Notably, our technique does not require video or multi-view data and can synthesize a variety of high-quality 3D scenes in different styles, consisting of multiple objects. Its generality additionally allows 3D synthesis from a single image.
1.3. Aligning Diffusion Models by Optimizing Human Utility

We present Diffusion-KTO, a novel approach for aligning text-to-image diffusion models by formulating the alignment objective as the maximization of expected human utility.
Since this objective applies to each generation independently, Diffusion-KTO does not require collecting costly pairwise preference data or training a complex reward model. Instead, our objective requires simple per-image binary feedback signals, e.g. likes or dislikes, which are abundantly available.
After fine-tuning using Diffusion-KTO, text-to-image diffusion models exhibit superior performance compared to existing techniques, including supervised fine-tuning and Diffusion-DPO, both in terms of human judgment and automatic evaluation metrics such as PickScore and ImageReward.
Overall, Diffusion-KTO unlocks the potential of leveraging readily available per-image binary signals and broadens the applicability of aligning text-to-image diffusion models with human preferences.
1.4. UniFL: Improve Stable Diffusion via Unified Feedback Learning

Diffusion models have revolutionized the field of image generation, leading to the proliferation of high-quality models and diverse downstream applications.
However, despite these significant advancements, the current competitive solutions still suffer from several limitations, including inferior visual quality, a lack of aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present UniFL, a unified framework that leverages feedback learning to enhance diffusion models comprehensively.
UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL. Notably, UniFL incorporates three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which optimizes inference speed.
In-depth experiments and extensive user studies validate the superior performance of our proposed method in enhancing both the quality of generated models and their acceleration. For instance, UniFL surpasses ImageReward by 17% in user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57% and 20% in 4-step inference. Moreover, we have verified the efficacy of our approach in downstream tasks, including Lora, ControlNet, and AnimateDiff.
1.5. Magic-Boost: Boost 3D Generation with Multi-View Conditioned Diffusion

Benefiting from the rapid development of 2D diffusion models, 3D content creation has made significant progress recently. One promising solution involves the fine-tuning of pre-trained 2D diffusion models to harness their capacity for producing multi-view images, which are then lifted into accurate 3D models via methods like fast-NeRFs or large reconstruction models.
However, as inconsistency still exists and limited generated resolution, the generation results of such methods still lack intricate textures and complex geometries. To solve this problem, we propose Magic-Boost, a multi-view conditioned diffusion model that significantly refines coarse generative results through a brief period of SDS optimization (sim15min). Compared to the previous text or single image-based diffusion models, Magic-Boost exhibits a robust capability to generate images with high consistency from pseudo-synthesized multi-view images.
It provides precise SDS guidance that well aligns with the identity of the input images, enriching the local detail in both the geometry and texture of the initial generative results. Extensive experiments show that Magic-Boost greatly enhances the coarse inputs and generates high-quality 3D assets with rich geometric and textural details.
1.6. Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models

Transformers have catalyzed advancements in computer vision and natural language processing (NLP) fields. However, substantial computational complexity poses limitations for their application in long-context tasks, such as high-resolution image generation.
This paper introduces a series of architectures adapted from the RWKV model used in the NLP, with requisite modifications tailored for the diffusion model applied to image generation tasks, referred to as diffusion-RWKV.
Similar to the diffusion with Transformers, our model is designed to efficiently handle patchnified inputs in a sequence with extra conditions, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets.
Its distinctive advantage manifests in its reduced spatial aggregation complexity, rendering it exceptionally adept at processing high-resolution images, thereby eliminating the necessity for windowing or group cached operations.
Experimental results on both condition and unconditional image generation tasks demonstrate that Diffison-RWKV achieves performance on par with or surpasses existing CNN or Transformer-based diffusion models in FID and IS metrics while significantly reducing total computation FLOP usage.
1.7. BeyondScene: Higher-Resolution Human-Centric Scene Generation With Pretrained Diffusion

Generating higher-resolution human-centric scenes with details and controls remains a challenge for existing text-to-image diffusion models. This challenge stems from limited training image size, text encoder capacity (limited tokens), and the inherent difficulty of generating complex scenes involving multiple humans.
While current methods attempted to address training size limit only, they often yielded human-centric scenes with severe artifacts. We propose BeyondScene, a novel framework that overcomes prior limitations, generating exquisite higher-resolution (over 8K) human-centric scenes with exceptional text-image correspondence and naturalness using existing pretrained diffusion models.
BeyondScene employs a staged and hierarchical approach to initially generate a detailed base image focusing on crucial elements in instance creation for multiple humans and detailed descriptions beyond the token limit of diffusion model and then to seamlessly convert the base image to a higher-resolution output, exceeding training image size and incorporating details aware of text and instances via our novel instance-aware hierarchical enlargement process that consists of our proposed high-frequency injected forward diffusion and adaptive joint diffusion.
BeyondScene surpasses existing methods in terms of correspondence with detailed text descriptions and naturalness, paving the way for advanced applications in higher-resolution human-centric scene creation beyond the capacity of pretrained diffusion models without costly retraining.
2. Vision Language Models (VLMs)
2.1. BRAVE: Broadening the visual encoding of vision-language models

Vision-language models (VLMs) are typically composed of a vision encoder, e.g. CLIP, and a language model (LM) that interprets the encoded features to solve downstream tasks. Despite remarkable progress, VLMs are subject to several shortcomings due to the limited capabilities of vision encoders, e.g. “blindness” to certain image features, visual hallucination, etc.
To address these issues, we study broadening the visual encoding capabilities of VLMs. We first comprehensively benchmark several vision encoders with different inductive biases for solving VLM tasks. We observe that there is no single encoding configuration that consistently achieves top performance across different tasks, and encoders with different biases can perform surprisingly similarly.
Motivated by this, we introduce a method, named BRAVE, that consolidates features from multiple frozen encoders into a more versatile representation that can be directly fed as the input to a frozen LM.
BRAVE achieves state-of-the-art performance on a broad range of captioning and VQA benchmarks and significantly reduces the aforementioned issues of VLMs, while requiring a smaller number of trainable parameters than existing methods and having a more compressed representation.
Our results highlight the potential of incorporating different visual biases for a more broad and contextualized visual understanding of VLMs.
3. Image Generation & Editing
3.1. RL for Consistency Models: Faster Reward Guided Text-to-Image Generation

Reinforcement learning (RL) has improved guided image generation with diffusion models by directly optimizing rewards that capture image quality, aesthetics, and instruction following capabilities. However, the resulting generative policies inherit the same iterative sampling process of diffusion models that causes slow generation.
To overcome this limitation, consistency models proposed learning a new class of generative models that directly map noise to data, resulting in a model that can generate an image in as few as one sampling iterations. In this work, to optimize text-to-image generative models for task-specific rewards and enable fast training and inference, we propose a framework for fine-tuning consistency models via RL.
Our framework, called Reinforcement Learning for Consistency Model (RLCM), frames the iterative inference process of a consistency model as an RL procedure. RLCM improves upon RL fine-tuned diffusion models on text-to-image generation capabilities and trades computation during inference time for sample quality.
Experimentally, we show that RLCM can adapt text-to-image consistency models to objectives that are challenging to express with prompting, such as image compressibility, and those derived from human feedback, such as aesthetic quality.
Compared to RL finetuned diffusion models, RLCM trains significantly faster, improves the quality of the generation measured under the reward objectives, and speeds up the inference procedure by generating high-quality images with as few as two inference steps.
3.2. Hash3D: Training-free Acceleration for 3D Generation

The evolution of 3D generative modeling has been notably propelled by the adoption of 2D diffusion models. Despite this progress, the cumbersome optimization process per se presents a critical hurdle to efficiency.
In this paper, we introduce Hash3D, a universal acceleration for 3D generation without model training. Central to Hash3D is the insight that feature-map redundancy is prevalent in images rendered from camera positions and diffusion time steps nearby.
By effectively hashing and reusing these feature maps across neighboring timesteps and camera angles, Hash3D substantially prevents redundant calculations, thus accelerating the diffusion model’s inference in 3D generation tasks.
We achieve this through adaptive grid-based hashing. Surprisingly, this feature-sharing mechanism not only speeds up the generation but also enhances the smoothness and view consistency of the synthesized 3D objects.
Our experiments covering 5 text-to-3D and 3 image-to-3D models demonstrate Hash3D’s versatility to speed up optimization, enhancing efficiency by 1.3 to 4 times. Additionally, Hash3D’s integration with 3D Gaussian splatting largely speeds up 3D model creation, reducing text-to-3D processing to about 10 minutes and image-to-3D conversion to roughly 30 seconds.
3.3. DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting

The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360-degree scene generation pipeline that facilitates the creation of comprehensive 360-degree scenes for in-the-wild environments in a matter of minutes.
Our approach utilizes the generative power of a 2D diffusion model and prompts self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary “flat” (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration.
To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians.
To address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions.
In summary, our method offers a globally consistent 3D scene within a 360-degree perspective, providing an enhanced immersive experience over existing techniques. Project website at:
http://dreamscene360.github.io/
3.4. SwapAnything: Enabling Arbitrary Object Swapping in Personalized Visual Editing

Effective editing of personal content holds a pivotal role in enabling individuals to express their creativity, weaving captivating narratives within their visual stories, and elevating the overall quality and impact of their visual content.
Therefore, in this work, we introduce SwapAnything, a novel framework that can swap any objects in an image with personalized concepts given by the reference, while keeping the context unchanged.
Compared with existing methods for personalized subject swapping, SwapAnything has three unique advantages: (1) precise control of arbitrary objects and parts rather than the main subject, (2) more faithful preservation of context pixels, (3) better adaptation of the personalized concept to the image.
First, we propose targeted variable swapping to apply region control over latent feature maps and swap masked variables for faithful context preservation and initial semantic concept swapping. Then, we introduce appearance adaptation, to seamlessly adapt the semantic concept into the original image in terms of target location, shape, style, and content during the image generation process.
Extensive results on both human and automatic evaluation demonstrate significant improvements in our approach over baseline methods on personalized swapping.
Furthermore, SwapAnything shows its precise and faithful swapping abilities across single objects, multiple objects, partial objects, and cross-domain swapping tasks. SwapAnything also achieves great performance on text-based swapping and tasks beyond swapping such as object insertion.
3.5. MoMA: Multimodal LLM Adapter for Fast Personalized Image Generation

In this paper, we present MoMA: an open-vocabulary, training-free personalized image model that boasts flexible zero-shot capabilities. As foundational text-to-image models rapidly evolve, the demand for robust image-to-image translation grows.
Addressing this need, MoMA specializes in subject-driven personalized image generation. Utilizing an open-source, Multimodal Large Language Model (MLLM), we train MoMA to serve a dual role as both a feature extractor and a generator.
This approach effectively synergizes reference image and text prompt information to produce valuable image features, facilitating an image diffusion model. To better leverage the generated features, we further introduce a novel self-attention shortcut method that efficiently transfers image features to an image diffusion model, improving the resemblance of the target object in generated images.
Remarkably, as a tuning-free plug-and-play module, our model requires only a single reference image and outperforms existing methods in generating images with high detail fidelity, enhanced identity preservation, and prompt faithfulness. Our work is open-source, thereby providing universal access to these advancements.
3.6. ByteEdit: Boost, Comply and Accelerate Generative Image Editing

Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including
Inferior quality
Poor consistency
Insufficient instruction adherence
Suboptimal generation efficiency.
To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks.
ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output.
Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model’s inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including
Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verified that our acceleration models maintain excellent performance results in terms of quality and consistency.
3.7. Urban Architect: Steerable 3D Urban Scene Generation with Layout Prior

Text-to-3D generation has achieved remarkable success via large-scale text-to-image diffusion models. Nevertheless, there is no paradigm for scaling up the methodology to urban scale.
Urban scenes, characterized by numerous elements, intricate arrangement relationships, and vast scale, present a formidable barrier to the interpretability of ambiguous textual descriptions for effective model optimization.
In this work, we surmount the limitations by introducing a compositional 3D layout representation into a text-to-3D paradigm, serving as an additional prior. It comprises a set of semantic primitives with simple geometric structures and explicit arrangement relationships, complementing textual descriptions and enabling steerable generation.
Upon this, we propose two modifications — (1) We introduce Layout-Guided Variational Score Distillation to address model optimization inadequacies. It conditions the score distillation sampling process with geometric and semantic constraints of 3D layouts. (2) To handle the unbounded nature of urban scenes, we represent a 3D scene with a Scalable Hash Grid structure, incrementally adapting to the growing scale of urban scenes.
Extensive experiments substantiate the capability of our framework to scale text-to-3D generation to large-scale urban scenes that cover over 1000m driving distance for the first time. We also present various scene editing demonstrations, showing the powers of steerable urban scene generation.
4. Video Understanding & Generation
4.1. MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators

Recent advances in Text-to-Video generation (T2V) have achieved remarkable success in synthesizing high-quality general videos from textual descriptions.
A largely overlooked problem in T2V is that existing models have not adequately encoded physical knowledge of the real world, thus generated videos tend to have limited motion and poor variations.
In this paper, we propose MagicTime, a metamorphic time-lapse video generation model, which learns real-world physics knowledge from time-lapse videos and implements metamorphic generation.
First, we design a MagicAdapter scheme to decouple spatial and temporal training, encode more physical knowledge from metamorphic videos, and transform pre-trained T2V models to generate metamorphic videos.
Second, we introduce a Dynamic Frames Extraction strategy to adapt to metamorphic time-lapse videos, which have a wider variation range and cover dramatic object metamorphic processes, thus embodying more physical knowledge than general videos.
Finally, we introduce a Magic Text-Encoder to improve the understanding of metamorphic video prompts. Furthermore, we create a time-lapse video-text dataset called ChronoMagic, specifically curated to unlock the metamorphic video generation ability.
Extensive experiments demonstrate the superiority and effectiveness of MagicTime for generating high-quality and dynamic metamorphic videos, suggesting time-lapse video generation is a promising path toward building metamorphic simulators of the physical world.
4.2. MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding

With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, video chat) can only take in a limited number of frames for short video understanding.
In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs’ context length constraints or GPU memory limits.
Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets.
4.3. Koala: Key frame-conditioned long video-LLM

Long video question answering is a challenging task that involves recognizing short-term activities and reasoning about their fine-grained relationships.
State-of-the-art video Large Language Models (vLLMs) hold promise as a viable solution due to their demonstrated emergent capabilities on new tasks. However, despite being trained on millions of short seconds-long videos, vLLMs are unable to understand minutes-long videos and accurately answer questions about them.
To address this limitation, we propose a lightweight and self-supervised approach, Key frame-conditioned long video-LLM (Koala), that introduces learnable spatiotemporal queries to adapt pretrained vLLMs for generalizing to longer videos.
Our approach introduces two new tokenizers that condition visual tokens computed from sparse video keyframes for understanding short and long video moments.
We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks, where it outperforms state-of-the-art large models by 3–6% in absolute accuracy across all tasks. Surprisingly, we also empirically show that our approach not only helps a pretrained vLLM to understand long videos but also improves its accuracy on short-term action recognition.
5. Image Recognition
5.1. Adapting LLaMA Decoder to Vision Transformer
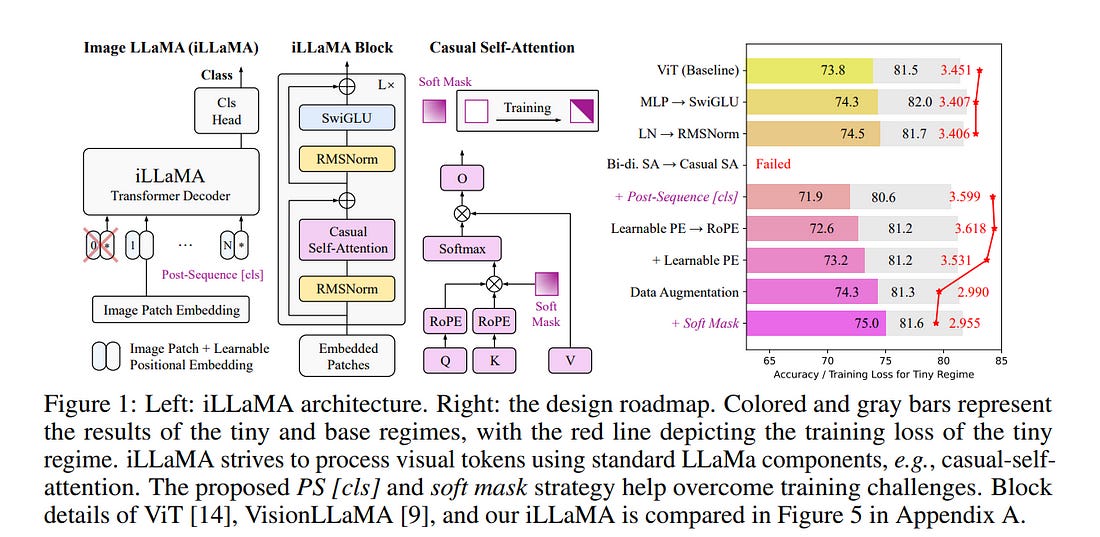
This work examines whether decoder-only Transformers such as LLaMA, which were originally designed for large language models (LLMs), can be adapted to the computer vision field.
We first “LLaMAfy” a standard ViT step-by-step to align with LLaMA’s architecture, and find that directly applying a casual mask to the self-attention brings an attention collapse issue, failing the network training.
We suggest repositioning the class token behind the image tokens with a post-sequence class token technique to overcome this challenge, enabling causal self-attention to efficiently capture the entire image’s information.
Additionally, we develop a soft mask strategy that gradually introduces a casual mask to self-attention at the onset of training to facilitate the optimization behavior. The tailored model, dubbed as image LLaMA (iLLaMA), is akin to LLaMA in architecture and enables direct supervised learning.
Its causal self-attention boosts computational efficiency and learns complex representations by elevating attention map ranks. iLLaMA rivals the performance of its encoder-only counterparts, achieving 75.1% ImageNet top-1 accuracy with only 5.7M parameters.
Scaling the model to ~310M and pre-training on ImageNet-21K further enhances the accuracy to 86.0%. Extensive experiments demonstrate iLLaMA’s reliable properties: calibration, shape-texture bias, quantization compatibility, ADE20K segmentation, and CIFAR transfer learning.
We hope our study can kindle fresh views of visual model design in the wave of LLMs. Pre-trained models and codes are available here.
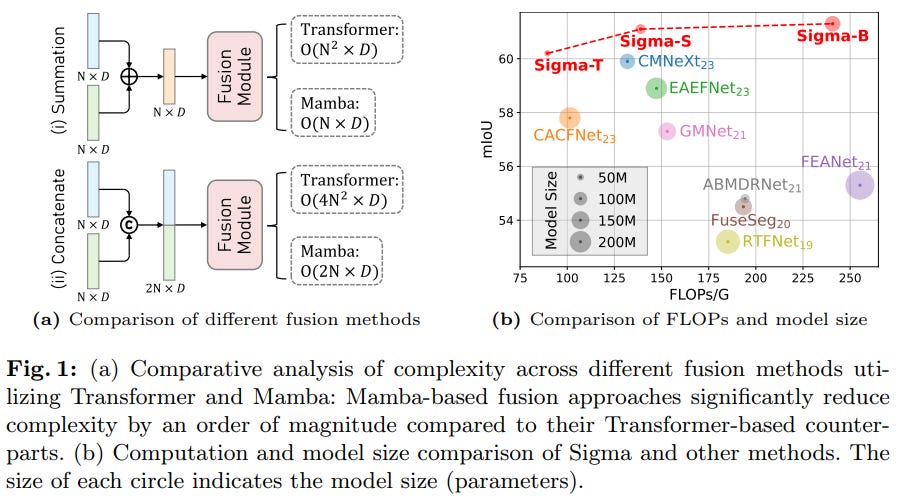
5.2. Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation
Multi-modal semantic segmentation significantly enhances AI agents’ perception and scene understanding, especially under adverse conditions like low-light or overexposed environments.
Leveraging additional modalities (X-modality) like thermal and depth alongside traditional RGB provides complementary information, enabling more robust and reliable segmentation. In this work, we introduce Sigma, a Siamese Mamba network for multi-modal semantic segmentation, utilizing the Selective Structured State Space Model, Mamba.
Unlike conventional methods that rely on CNNs, with their limited local receptive fields, or Vision Transformers (ViTs), which offer global receptive fields at the cost of quadratic complexity, our model achieves global receptive field coverage with linear complexity. By employing a Siamese encoder and innovating a Mamba fusion mechanism, we effectively select essential information from different modalities.
A decoder is then developed to enhance the channel-wise modeling ability of the model. Our method, Sigma, is rigorously evaluated on both RGB-Thermal and RGB-Depth segmentation tasks, demonstrating its superiority and marking the first successful application of State Space Models (SSMs) in multi-modal perception tasks.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
