


Top Important Computer Vision Papers for the Week from 04/03 to 10/03
Stay Updated with Recent Computer Vision Research

Every week, several top-tier academic conferences and journals showcased innovative research in computer vision, presenting exciting breakthroughs in various subfields such as image recognition, vision model optimization, generative adversarial networks (GANs), image segmentation, video analysis, and more.
This article provides a comprehensive overview of the most significant papers published in the Second Week of March 2024, highlighting the latest research and advancements in computer vision. Whether you’re a researcher, practitioner, or enthusiast, this article will provide valuable insights into the state-of-the-art techniques and tools in computer vision.

Table of Contents:
Diffusion Models
Vision Language Models
Image Generation & Editing
Video Generation & Editing
Image Recognition
My E-book: Data Science Portfolio for Success Is Out!

I recently published my first e-book Data Science Portfolio for Success which is a practical guide on how to build your data science portfolio. The book covers the following topics: The Importance of Having a Portfolio as a Data Scientist How to Build a Data Science Portfolio That Will Land You a Job?
1. Diffusion Models
1. OOTDiffusion: Outfitting Fusion-based Latent Diffusion for Controllable Virtual Try-on

Image-based virtual try-on (VTON), which aims to generate an outfitted image of a target human wearing an in-shop garment, is a challenging image-synthesis task calling for not only high fidelity of the outfitted human but also full preservation of garment details.
To tackle this issue, we propose Outfitting over Try-on Diffusion (OOTDiffusion), leveraging the power of pretrained latent diffusion models and designing a novel network architecture for realistic and controllable virtual try-on. Without an explicit warping process, we propose an outfitting UNet to learn the garment detail features and merge them with the target human body via our proposed outfitting fusion in the denoising process of diffusion models.
To further enhance the controllability of our outfitting UNet, we introduce outfitting dropout to the training process, which enables us to adjust the strength of garment features through classifier-free guidance. Our comprehensive experiments on the VITON-HD and Dress Code datasets demonstrate that OOTDiffusion efficiently generates high-quality outfitted images for arbitrary human and garment images, which outperforms other VTON methods in both fidelity and controllability, indicating an impressive breakthrough in virtual try-on.
2. ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models
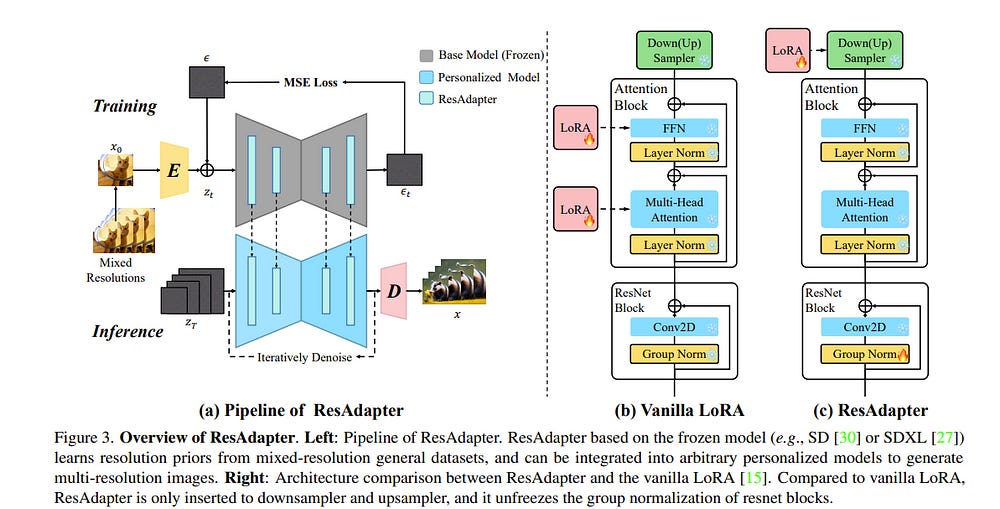
Recent advancement in text-to-image models (e.g., Stable Diffusion) and corresponding personalized technologies (e.g., DreamBooth and LoRA) enables individuals to generate high-quality and imaginative images. However, they often suffer from limitations when generating images with resolutions outside of their trained domain.
To overcome this limitation, we present the Resolution Adapter (ResAdapter), a domain-consistent adapter designed for diffusion models to generate images with unrestricted resolutions and aspect ratios. Unlike other multi-resolution generation methods that process images of static resolution with complex post-process operations, ResAdapter directly generates images with a dynamical resolution.
Especially, after learning a deep understanding of pure resolution priors, ResAdapter trained on the general dataset, generates resolution-free images with personalized diffusion models while preserving their original style domain.
Comprehensive experiments demonstrate that ResAdapter with only 0.5M can process images with flexible resolutions for arbitrary diffusion models. More extended experiments demonstrate that ResAdapter is compatible with other modules (e.g., ControlNet, IP-Adapter, and LCM-LoRA) for image generation across a broad range of resolutions, and can be integrated into another multi-resolution model (e.g., ElasticDiffusion) for efficiently generating higher-resolution images.
3. PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation

In this paper, we introduce PixArt-\Sigma, a Diffusion Transformer model~(DiT) capable of directly generating images at 4K resolution. PixArt-\Sigma represents a significant advancement over its predecessor, PixArt-\alpha, offering images of markedly higher fidelity and improved alignment with text prompts.
A key feature of PixArt-\Sigma is its training efficiency. Leveraging the foundational pre-training of PixArt-\alpha, it evolves from the `weaker’ baseline to a `stronger’ model via incorporating higher quality data, a process we term “weak-to-strong training”.
The advancements in PixArt-\Sigma are twofold:
High-Quality Training Data: PixArt-\Sigma incorporates superior-quality image data, paired with more precise and detailed image captions.
Efficient Token Compression: we propose a novel attention module within the DiT framework that compresses both keys and values, significantly improving efficiency and facilitating ultra-high-resolution image generation.
Thanks to these improvements, PixArt-\Sigma achieves superior image quality and user prompt adherence capabilities with significantly smaller model size (0.6B parameters) than existing text-to-image diffusion models, such as SDXL (2.6B parameters) and SD Cascade (5.1B parameters). Moreover, PixArt-\Sigma’s capability to generate 4K images supports the creation of high-resolution posters and wallpapers, efficiently bolstering the production of high-quality visual content in industries such as film and gaming.
4. Pix2Gif: Motion-Guided Diffusion for GIF Generation

We present Pix2Gif, a motion-guided diffusion model for image-to-GIF (video) generation. We tackle this problem differently by formulating the task as an image translation problem steered by text and motion magnitude prompts.
To ensure that the model adheres to motion guidance, we propose a new motion-guided warping module to spatially transform the features of the source image conditioned on the two types of prompts. Furthermore, we introduce a perceptual loss to ensure the transformed feature map remains within the same space as the target image, ensuring content consistency and coherence.
In preparation for the model training, we meticulously curated data by extracting coherent image frames from the TGIF video-caption dataset, which provides rich information about the temporal changes of subjects. After pretraining, we apply our model in a zero-shot manner to several video datasets.
Extensive qualitative and quantitative experiments demonstrate the effectiveness of our model — it not only captures the semantic prompt from text but also the spatial ones from motion guidance. We train all our models using a single node of 16xV100 GPUs.
2. Vision Language Models
2.1. Enhancing Vision-Language Pre-training with Rich Supervisions

We propose Strongly Supervised pre-training with ScreenShots (S4) — a novel pre-training paradigm for Vision-Language Models using data from large-scale web screenshot rendering.
Using web screenshots unlocks a treasure trove of visual and textual cues that are not present in using image-text pairs. In S4, we leverage the inherent tree-structured hierarchy of HTML elements and the spatial localization to carefully design 10 pre-training tasks with large-scale annotated data.
These tasks resemble downstream tasks across different domains and the annotations are cheap to obtain. We demonstrate that, compared to current screenshot pre-training objectives, our innovative pre-training method significantly enhances the performance of the image-to-text model in nine varied and popular downstream tasks — up to 76.1% improvements in Table Detection, and at least 1% on Widget Captioning.
3. Image Generation & Editing
3.1. RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization

Text-to-image customization, which aims to synthesize text-driven images for the given subjects, has recently revolutionized content creation. Existing works follow the pseudo-word paradigm, i.e., represent the given subjects as pseudo-words and then compose them with the given text.
However, the inherent entangled influence scope of pseudo-words with the given text results in a dual-optimum paradox, i.e., the similarity of the given subjects and the controllability of the given text could not be optimal simultaneously.
We present RealCustom that, for the first time, disentangles similarity from controllability by precisely limiting subject influence to relevant parts only, achieved by gradually narrowing real text word from its general connotation to the specific subject and using its cross-attention to distinguish relevance.
Specifically, RealCustom introduces a novel “train-inference” decoupled framework: (1) during training, RealCustom learns general alignment between visual conditions to original textual conditions by a novel adaptive scoring module to adaptively modulate influence quantity; (2) during inference, a novel adaptive mask guidance strategy is proposed to iteratively update the influence scope and influence quantity of the given subjects to gradually narrow the generation of the real text word.
Comprehensive experiments demonstrate the superior real-time customization ability of RealCustom in the open domain, achieving both unprecedented similarity of the given subjects and controllability of the given text for the first time.
3.2. TripoSR: Fast 3D Object Reconstruction from a Single Image

This technical report introduces TripoSR, a 3D reconstruction model leveraging transformer architecture for fast feed-forward 3D generation, producing 3D mesh from a single image in under 0.5 seconds.
Building upon the LRM network architecture, TripoSR integrates substantial improvements in data processing, model design, and training techniques.
Evaluations of public datasets show that TripoSR exhibits superior performance, both quantitatively and qualitatively, compared to other open-source alternatives. Released under the MIT license, TripoSR is intended to empower researchers, developers, and creatives with the latest advancements in 3D generative AI.
3.3. ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models

3D asset generation is getting massive amounts of attention, inspired by the recent success of text-guided 2D content creation. Existing text-to-3D methods use pretrained text-to-image diffusion models in an optimization problem or fine-tune them on synthetic data, which often results in non-photorealistic 3D objects without backgrounds.
In this paper, we present a method that leverages pretrained text-to-image models as a prior and learns to generate multi-view images in a single denoising process from real-world data. Concretely, we propose to integrate 3D volume-rendering and cross-frame-attention layers into each block of the existing U-Net network of the text-to-image model.
Moreover, we design an autoregressive generation that renders more 3D-consistent images from any viewpoint. We train our model on real-world datasets of objects and showcase its capabilities to generate instances with a variety of high-quality shapes and textures in authentic surroundings. Compared to the existing methods, the results generated by our method are consistent and have favorable visual quality (-30% FID, -37% KID).
3.4. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis

Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line.
Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis.
Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings.
We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models, and we will make our experimental data, code, and model weights publicly available.
3.5. StableDrag: Stable Dragging for Point-based Image Editing

Point-based image editing has attracted remarkable attention since the emergence of DragGAN. Recently, DragDiffusion further pushes forward the generative quality by adapting this dragging technique to diffusion models.
Despite this great success, this dragging scheme exhibits two major drawbacks, namely inaccurate point tracking and incomplete motion supervision, which may result in unsatisfactory dragging outcomes. To tackle these issues, we build a stable and precise drag-based editing framework, coined as StableDrag, by designing a discriminative point tracking method and a confidence-based latent enhancement strategy for motion supervision.
The former allows us to precisely locate the updated handle points, thereby boosting the stability of long-range manipulation, while the latter is responsible for guaranteeing the optimized latent as high-quality as possible across all the manipulation steps. Thanks to these unique designs, we instantiate two types of image editing models including StableDrag-GAN and StableDrag-Diff, which attain more stable dragging performance, through extensive qualitative experiments and quantitative assessment on DragBench.
4. Video Generation & Editing
4.1. AtomoVideo: High-Fidelity Image-to-Video Generation

Recently, video generation has achieved significant rapid development based on superior text-to-image generation techniques. In this work, we propose a high-fidelity framework for image-to-video generation, named AtomoVideo.
Based on multi-granularity image injection, we achieve higher fidelity of the generated video to the given image. In addition, thanks to high-quality datasets and training strategies, we achieve greater motion intensity while maintaining superior temporal consistency and stability. Our architecture extends flexibly to the video frame prediction task, enabling long sequence prediction through iterative generation.
Furthermore, due to the design of adapter training, our approach can be well combined with existing personalized models and controllable modules. By quantitatively and qualitatively evaluation, AtomoVideo achieves superior results compared to popular methods, more examples can be found on our project website:
https://atomo-
video.github.io/.
4.2. MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies
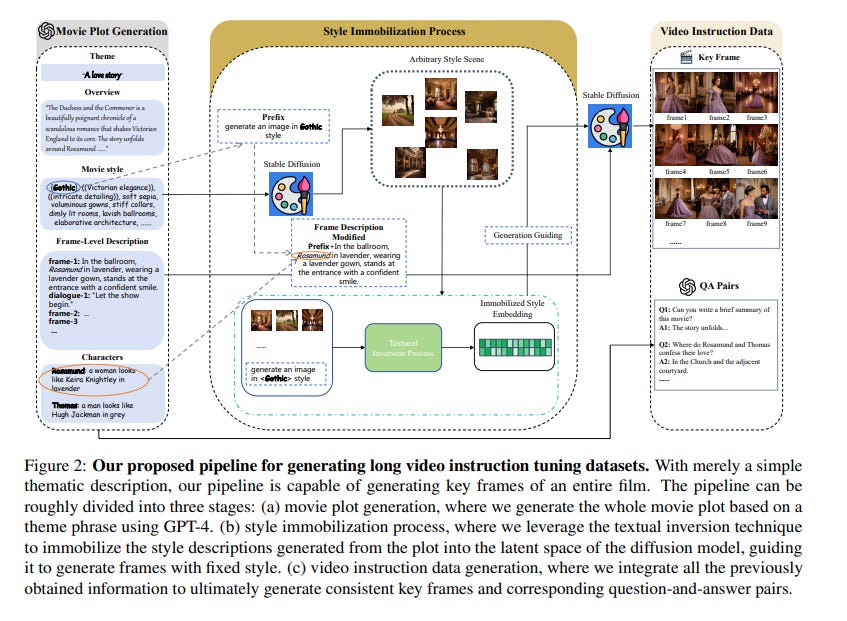
The development of multimodal models has marked a significant step forward in how machines understand videos. These models have shown promise in analyzing short video clips. However, when it comes to longer formats like movies, they often fall short.
The main hurdles are the lack of high-quality, diverse video data and the intensive work required to collect or annotate such data. In the face of these challenges, we propose MovieLLM, a novel framework designed to create synthetic, high-quality data for long videos.
This framework leverages the power of GPT-4 and text-to-image models to generate detailed scripts and corresponding visuals. Our approach stands out for its flexibility and scalability, making it a superior alternative to traditional data collection methods.
Our extensive experiments validate that the data produced by MovieLLM significantly improves the performance of multimodal models in understanding complex video narratives, overcoming the limitations of existing datasets regarding scarcity and bias.
4.3. Tuning-Free Noise Rectification for High-Fidelity Image-to-Video Generation
Image-to-video (I2V) generation tasks always suffer from keeping high fidelity in the open domains. Traditional image animation techniques primarily focus on specific domains such as faces or human poses, making them difficult to generalize to open domains.
Several recent I2V frameworks based on diffusion models can generate dynamic content for open-domain images but fail to maintain fidelity. We found that two main factors of low fidelity are the loss of image details and the noise prediction biases during the denoising process. To this end, we propose an effective method that can be applied to mainstream video diffusion models.
This method achieves high fidelity based on supplementing more precise image information and noise rectification. Specifically, given a specified image, our method first adds noise to the input image latent to keep more details, then denoises the noisy latent with proper rectification to alleviate the noise prediction biases.
Our method is tuning-free and plug-and-play. The experimental results demonstrate the effectiveness of our approach in improving the fidelity of generated videos.
5. Image Recognition
5.1. VisionLLaMA: A Unified LLaMA Interface for Vision Tasks

Large language models are built on top of a transformer-based architecture to process textual inputs. For example, the LLaMA stands out among many open-source implementations. Can the same transformer be used to process 2D images?
In this paper, we answer this question by unveiling an LLaMA-like vision transformer in plain and pyramid forms, termed VisionLLaMA, which is tailored for this purpose. VisionLLaMA is a unified and generic modeling framework for solving most vision tasks. We extensively evaluate its effectiveness using typical pre-training paradigms in a good portion of downstream tasks of image perception and especially image generation.
In many cases, VisionLLaMA has exhibited substantial gains over the previous state-of-the-art vision transformers. We believe that VisionLLaMA can serve as a strong new baseline model for vision generation and understanding.
5.2. Learning and Leveraging World Models in Visual Representation Learning
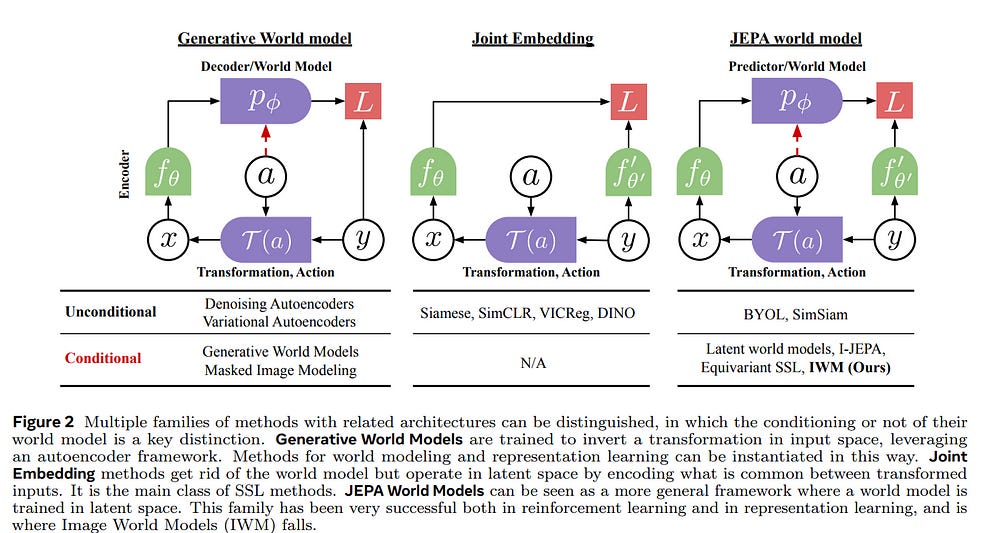
Joint-Embedding Predictive Architecture (JEPA) has emerged as a promising self-supervised approach that learns by leveraging a world model. While previously limited to predicting missing parts of the input, we explore how to generalize the JEPA prediction task to a broader set of corruptions. We introduce Image World Models, an approach that goes beyond masked image modeling and learns to predict the effect of global photometric transformations in latent space.
We study the recipe for learning performant IWMs and show that it relies on three key aspects: conditioning, prediction difficulty, and capacity. Additionally, we show that the predictive world model learned by IWM can be adapted through finetuning to solve diverse tasks; a fine-tuned IWM world model matches or surpasses the performance of previous self-supervised methods.
Finally, we show that learning with an IWM allows one to control the abstraction level of the learned representations, learning invariant representations such as contrastive methods, or equivariant representations such as masked image modeling.
5.3. How Far Are We from Intelligent Visual Deductive Reasoning?
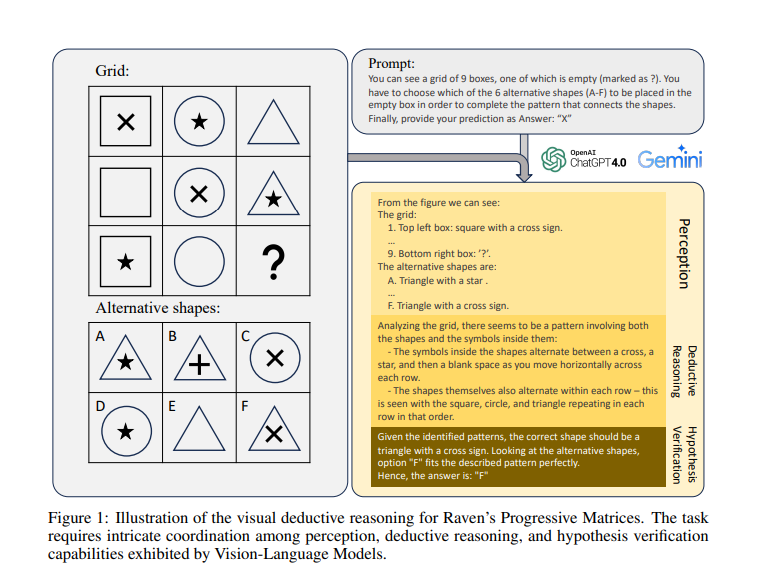
Vision-language models (VLMs) such as GPT-4V have recently demonstrated incredible strides on diverse vision language tasks. We dig into vision-based deductive reasoning, a more sophisticated but less explored realm, and find previously unexposed blindspots in the current SOTA VLMs.
Specifically, we leverage Raven’s Progressive Matrices (RPMs), to assess VLMs’ abilities to perform multi-hop relational and deductive reasoning relying solely on visual clues. We perform comprehensive evaluations of several popular VLMs employing standard strategies such as in-context learning, self-consistency, and Chain-of-thoughts (CoT) on three diverse datasets, including the Mensa IQ test, IntelligenceTest, and RAVEN.
The results reveal that despite the impressive capabilities of LLMs in text-based reasoning, we are still far from achieving comparable proficiency in visual deductive reasoning. We found that certain standard strategies that are effective when applied to LLMs do not seamlessly translate to the challenges presented by visual reasoning tasks.
Moreover, a detailed analysis reveals that VLMs struggle to solve these tasks mainly because they are unable to perceive and comprehend multiple, confounding abstract patterns in RPM examples.
Are you looking to start a career in data science and AI and do not know how? I offer data science mentoring sessions and long-term career mentoring:
Mentoring sessions: https://lnkd.in/dXeg3KPW
Long-term mentoring: https://lnkd.in/dtdUYBrM
